PPO算法是一类Policy Gradient强化学习方法,经典的Policy Gradient通过一个参数化决策模型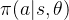 来根据状态
来根据状态 确定动作,其参数更新是通过下式进行的:
确定动作,其参数更新是通过下式进行的:

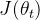 用于衡量决策模型的优劣目标,决策模型的优化目标为寻找最优决策,使得该决策下整体价值最大。
用于衡量决策模型的优劣目标,决策模型的优化目标为寻找最优决策,使得该决策下整体价值最大。
![\text{max}_{\pi}\ J(\theta) = E_{s,a\sim \pi}[\pi(a|s,\theta)Q_{\pi}(s,a)]](https://latex.csdn.net/eq?%5Ctext%7Bmax%7D_%7B%5Cpi%7D%5C%20J%28%5Ctheta%29%20%3D%20E_%7Bs%2Ca%5Csim%20%5Cpi%7D%5B%5Cpi%28a%7Cs%2C%5Ctheta%29Q_%7B%5Cpi%7D%28s%2Ca%29%5D)
因为最优决策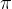 是未知的,一种简单思路是直接当前参数模型
是未知的,一种简单思路是直接当前参数模型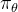 进行寻优。称为Vanilla Policy Gradient。
进行寻优。称为Vanilla Policy Gradient。
1. Vanilla Policy Gradient
Vanilla Policy Gradient定义优化目标为:
![\text{max}_{\theta }\ J(\theta) \\= E_{s,a\sim {\pi_{\theta }}}[\pi(a|s,\theta)A(s,a)]\\=\sum_\tau \sum_{t=0}^T \sum_a\pi(a|s_t,\theta)A(s_t,a)](https://latex.csdn.net/eq?%5Ctext%7Bmax%7D_%7B%5Ctheta%20%7D%5C%20J%28%5Ctheta%29%20%5C%5C%3D%20E_%7Bs%2Ca%5Csim%20%7B%5Cpi_%7B%5Ctheta%20%7D%7D%7D%5B%5Cpi%28a%7Cs%2C%5Ctheta%29A%28s%2Ca%29%5D%5C%5C%3D%5Csum_%5Ctau%20%5Csum_%7Bt%3D0%7D%5ET%20%5Csum_a%5Cpi%28a%7Cs_t%2C%5Ctheta%29A%28s_t%2Ca%29)
-
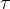 表示一轮episode,
表示一轮episode, 表示episode中的某个时刻,
表示episode中的某个时刻,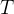 表示一轮episode的终态。
表示一轮episode的终态。
-
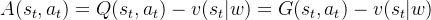 称为Advantages estimates,其在原来预估
称为Advantages estimates,其在原来预估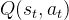 基础上减去了平均状态价值估计
基础上减去了平均状态价值估计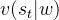 ,这么做好处是扭正不同状态价值间偏差,可以加快模型收敛,具体可以参考这篇。
,这么做好处是扭正不同状态价值间偏差,可以加快模型收敛,具体可以参考这篇。
梯度计算式子:
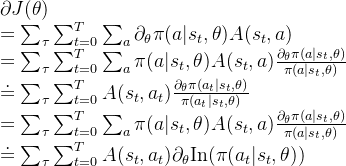
参数更新式子:

此外平均状态价值估计通过VE损失进行优化,其同Policy Gradient更新按照AC的框架进行两步迭代更新。

2. Trust Region Policy Optimization
前面我们所提到的Vanilla Policy Gradient算法是将训练分为多个epoch,每个epoch会根据当前决策模型采样多个episode组合成一个batch,并在该epoch中针对于该batch进行多轮训练。
由于该轮epoch的训练数据是根据上轮epoch的模型进行采样的,此时就可能出现更新的决策模型同采样决策模型不一致,这个不一致同off-policy所带来的问题是类似的,可能会导致模型训练有偏差。
虽然Vanilla Policy Gradient算法是on-policy的,但是由于对batch进行多轮训练,在实际上造成了target policy和behavior policy不一致的问题。因此Trust Region Policy Optimization(TRPO)根据off-policy在原来优化目标上添加了重要性采样。
![J(\theta) = E_{s,a\sim {\pi_{\theta^k }}}[\frac{\pi(a|s,\theta)}{\pi(a|s,\theta^k)}A^{\theta^k}(s,a)]](https://latex.csdn.net/eq?J%28%5Ctheta%29%20%3D%20E_%7Bs%2Ca%5Csim%20%7B%5Cpi_%7B%5Ctheta%5Ek%20%7D%7D%7D%5B%5Cfrac%7B%5Cpi%28a%7Cs%2C%5Ctheta%29%7D%7B%5Cpi%28a%7Cs%2C%5Ctheta%5Ek%29%7DA%5E%7B%5Ctheta%5Ek%7D%28s%2Ca%29%5D)
上式中的 表示上轮模型参数,同时为了避免target policy 和behavior policy
表示上轮模型参数,同时为了避免target policy 和behavior policy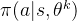 变化太大,导致优化目标方差增大,因此还需要通过KL散度约束相比于变动不大,其约束了的变化区域,故称为Trust Region
变化太大,导致优化目标方差增大,因此还需要通过KL散度约束相比于变动不大,其约束了的变化区域,故称为Trust Region
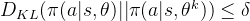
直接根据上面目标以及约束很难进行优化,因此TRPO做了一定式子简化:
![\text{max}_{\theta}\ J(\theta) \approx E_{s,a\sim {\pi_{\theta^k }}}[\pi(a|s,\theta)A^{\theta^k}(s,a)][\theta - \theta^k]=g[\theta - \theta^k] \\ s.t. \ D_{KL} \approx \frac{1}{2}[\theta - \theta^k]^T H[\theta - \theta^k] \leq \delta](https://latex.csdn.net/eq?%5Ctext%7Bmax%7D_%7B%5Ctheta%7D%5C%20J%28%5Ctheta%29%20%5Capprox%20E_%7Bs%2Ca%5Csim%20%7B%5Cpi_%7B%5Ctheta%5Ek%20%7D%7D%7D%5B%5Cpi%28a%7Cs%2C%5Ctheta%29A%5E%7B%5Ctheta%5Ek%7D%28s%2Ca%29%5D%5B%5Ctheta%20-%20%5Ctheta%5Ek%5D%3Dg%5B%5Ctheta%20-%20%5Ctheta%5Ek%5D%20%5C%5C%20s.t.%20%5C%20D_%7BKL%7D%20%5Capprox%20%5Cfrac%7B1%7D%7B2%7D%5B%5Ctheta%20-%20%5Ctheta%5Ek%5D%5ET%20H%5B%5Ctheta%20-%20%5Ctheta%5Ek%5D%20%5Cleq%20%5Cdelta)
同时其给出决策参数的更新式子,式子中的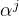 用于控制KL散度约束,此处采用了Backtracking line search技术,其通过设置多个因子,并在训练中不断从中选择一个因子使得约束满足同时梯度更新最大。
用于控制KL散度约束,此处采用了Backtracking line search技术,其通过设置多个因子,并在训练中不断从中选择一个因子使得约束满足同时梯度更新最大。


3. Proximal Policy Optimization
TRPO有一个很大问题,在于其KL约束是通过惩罚项加到优化目标上去的,因此惩罚项的权重参数是一个超参数,其设置影响整体训练效果,虽然TRPO采用了Backtracking line search技术,可以自适应的去选择超参数,但是对于整体训练效果仍是有损的。
因此PPO认为KL约束既然是为了约束相比于变动不大,而优化目标已经包含了这两项,为什么不把这个约束添加到优化目标中。通过截断来约束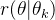 变动在一定范围内,从而到达同KL散度约束类似的效果。
变动在一定范围内,从而到达同KL散度约束类似的效果。
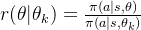
![J(\theta) = E_{s,a\sim {\pi_{\theta^k }}}(min[r(\theta|\theta_k)A^{\theta^k}(s,a), clip(r(\theta|\theta_k),1-\epsilon, 1+\epsilon)A^{\theta^k}(s,a)])](https://latex.csdn.net/eq?J%28%5Ctheta%29%20%3D%20E_%7Bs%2Ca%5Csim%20%7B%5Cpi_%7B%5Ctheta%5Ek%20%7D%7D%7D%28min%5Br%28%5Ctheta%7C%5Ctheta_k%29A%5E%7B%5Ctheta%5Ek%7D%28s%2Ca%29%2C%20clip%28r%28%5Ctheta%7C%5Ctheta_k%29%2C1-%5Cepsilon%2C%201+%5Cepsilon%29A%5E%7B%5Ctheta%5Ek%7D%28s%2Ca%29%5D%29)

论文中也通过实验表明了PPO算法采样这种clip方式其效果比固定KL约束参数、自适应KL约束参数的方法都要好。