在文章 生成一定相关性的二元正态分布 中我们有提到,如果二元随机变量
(
X
,
Y
)
(X, \, Y)
(X,Y) 服从二元正态分布 (bivariate normal distribution) ,那么其概率密度函数为
f
(
x
,
y
)
=
1
2
π
σ
x
σ
Y
1
−
ρ
2
×
exp
(
−
1
2
(
1
−
ρ
2
)
(
(
x
−
μ
x
σ
x
)
2
−
2
ρ
(
x
−
μ
X
σ
x
)
(
y
−
μ
y
σ
y
)
+
(
y
−
μ
y
σ
y
)
2
)
)
(
∗
)
\begin{aligned} f(x, \, y) &= \frac{1}{2\pi \sigma_x \sigma_Y \sqrt{1 - \rho^2}} \times \\ & \exp \left( -\frac{1}{2(1 - \rho^2)} \Big( \big( \frac{x - \mu_x}{\sigma_x} \big)^2 - 2 \rho (\frac{x - \mu_X}{\sigma_x}) (\frac{y - \mu_y}{\sigma_y}) + (\frac{y - \mu_y}{\sigma_y})^2 \Big) \right) (*) \end{aligned}
f(x,y)=2πσxσY1−ρ21×exp(−2(1−ρ2)1((σxx−μx)2−2ρ(σxx−μX)(σyy−μy)+(σyy−μy)2))(∗)
上式中的
ρ
\rho
ρ 即为
X
X
X 与
Y
Y
Y 的相关性系数 (correlation coefficient)。
μ
x
\mu_x
μx 为
X
X
X 的期望,
μ
y
\mu_y
μy 为
Y
Y
Y 的期望;
σ
x
2
\sigma_x^2
σx2 为
X
X
X 的方差,
σ
y
2
\sigma_y^2
σy2 为
Y
Y
Y 的方差。
回顾了二元正态分布的概念之后,我们可以定义二元对数正态分布如下:
定义:如果两个随机变量
(
X
,
Y
)
(X, \, Y)
(X,Y) 服从二元正态分布,且另外两个随机变量
(
U
,
V
)
(U, \, V)
(U,V),我们有
U
=
exp
(
X
)
,
V
=
exp
(
Y
)
U = \exp(X), \, V = \exp(Y)
U=exp(X),V=exp(Y)。我们称
(
U
,
V
)
(U, \, V)
(U,V) 服从二元对数正态分布。
对数正态分布的期望与方差
在看二元对数正态分布的性质之前,我们先来看一元对数正态分布的期望与方差。
假设我们有随机变量
X
∼
N
(
μ
x
,
σ
x
2
)
X \sim N(\mu_x, \sigma_x^2)
X∼N(μx,σx2),
U
=
exp
(
X
)
U = \exp(X)
U=exp(X)。那么我们可以直接用定义求出
U
U
U 的期望。
E
(
U
)
=
∫
−
∞
∞
e
x
⋅
1
2
π
σ
x
e
−
(
x
−
μ
x
)
2
2
σ
x
2
d
x
=
∫
−
∞
∞
1
2
π
σ
x
e
−
1
2
σ
x
2
(
(
x
−
μ
x
)
2
−
2
σ
x
2
x
)
d
x
=
∫
−
∞
∞
1
2
π
σ
x
e
−
1
2
σ
x
2
(
x
2
−
2
(
μ
x
+
σ
x
2
)
x
+
μ
x
2
)
d
x
=
∫
−
∞
∞
1
2
π
σ
x
e
−
1
2
σ
x
2
(
(
x
−
(
μ
x
+
σ
x
2
)
)
2
−
σ
x
4
−
2
μ
x
σ
x
2
)
d
x
=
(
∫
−
∞
∞
1
2
π
σ
x
e
−
1
2
σ
x
2
(
x
−
(
μ
x
+
σ
x
2
)
)
2
d
x
)
⋅
e
−
1
2
σ
x
2
(
−
σ
x
4
−
2
μ
x
σ
x
2
)
\begin{aligned} \displaystyle \mathbb{E}(U) &= \int_{-\infty}^{\infty} e^x \cdot \frac{1}{\sqrt{2 \pi} \sigma_x} e^{- \frac{(x - \mu_x)^2}{2 \sigma_x^2}} dx \\ &= \int_{-\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma_x} e^{-\frac{1}{2 \sigma_x^2} \big( (x - \mu_x)^2 - 2 \sigma_x^2 x \big)} dx \\ &= \int_{-\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma_x} e^{-\frac{1}{2 \sigma_x^2} \big( x^2 - 2 (\mu_x + \sigma_x^2) x + \mu_x^2 \big) } dx \\ &= \int_{-\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma_x} e^{-\frac{1}{2 \sigma_x^2} \big( (x - (\mu_x + \sigma_x^2) )^2 - \sigma_x^4 - 2 \mu_x \sigma_x^2 \big)} dx \\ &= \Big( \int_{-\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma_x} e^{-\frac{1}{2 \sigma_x^2} (x - (\mu_x + \sigma_x^2) )^2 } dx \Big) \cdot e^{-\frac{1}{2 \sigma_x^2} (- \sigma_x^4 - 2 \mu_x \sigma_x^2) } \end{aligned}
E(U)=∫−∞∞ex⋅2πσx1e−2σx2(x−μx)2dx=∫−∞∞2πσx1e−2σx21((x−μx)2−2σx2x)dx=∫−∞∞2πσx1e−2σx21(x2−2(μx+σx2)x+μx2)dx=∫−∞∞2πσx1e−2σx21((x−(μx+σx2))2−σx4−2μxσx2)dx=(∫−∞∞2πσx1e−2σx21(x−(μx+σx2))2dx)⋅e−2σx21(−σx4−2μxσx2)
注意到,
∫
−
∞
∞
1
2
π
σ
x
e
−
1
2
σ
x
2
(
x
−
(
μ
x
+
σ
x
2
)
)
2
d
x
\displaystyle \int_{-\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma_x} e^{-\frac{1}{2 \sigma_x^2} (x - (\mu_x + \sigma_x^2) )^2 } dx
∫−∞∞2πσx1e−2σx21(x−(μx+σx2))2dx 这一项正是
N
(
μ
x
+
σ
x
2
,
σ
x
)
N(\mu_x + \sigma_x^2, \sigma_x)
N(μx+σx2,σx) 的概率密度函数在
R
\mathbb{R}
R 上的积分,故其值等于 1。于是
E
[
U
]
=
e
−
1
2
σ
x
2
(
−
σ
x
4
−
2
μ
x
σ
x
2
)
=
exp
(
μ
x
+
1
2
σ
x
2
)
\displaystyle \mathbb{E} [U] = e^{-\frac{1}{2 \sigma_x^2} (- \sigma_x^4 - 2 \mu_x \sigma_x^2)} = \exp {(\mu_x + \frac{1}{2} \sigma_x^2 )}
E[U]=e−2σx21(−σx4−2μxσx2)=exp(μx+21σx2) 。
如果读者熟悉距生成函数 (moment-generating function) 的概念,我们就可以直接得到
E
[
U
]
=
E
[
e
X
]
\displaystyle \mathbb{E} [U] = \mathbb{E} [e^{X}]
E[U]=E[eX]。
我们先来回忆一下距生成函数的定义。
定义: 随机变量
X
X
X 的距生成函数
M
X
(
t
)
M_X (t)
MX(t) 定义为
M
X
(
t
)
=
E
[
e
t
X
]
\displaystyle M_X (t) = \mathbb{E} [e^{tX}]
MX(t)=E[etX],其中须要
E
[
e
t
X
]
\mathbb{E} [e^{tX}]
E[etX] 在
t
=
0
t = 0
t=0 附近是存在的。
对于服从正态分布
N
(
μ
x
,
σ
x
2
)
N(\mu_x, \, \sigma_x^2)
N(μx,σx2) 的随机变量
X
X
X,可以计算其距生成函数是
exp
(
μ
x
t
+
1
2
σ
x
2
t
2
)
\displaystyle \exp \big( \mu_x t + \dfrac{1}{2} \sigma_x^2 t^2 \big)
exp(μxt+21σx2t2)。令
t
=
1
t = 1
t=1,我们就直接得到
E
[
e
X
]
=
exp
(
μ
x
+
1
2
σ
x
2
)
\mathbb{E} [e^X] = \exp(\mu_x + \frac{1}{2} \sigma_x^2)
E[eX]=exp(μx+21σx2)。这与我们上面得到的结果是一样的。
有了对数正态分布的期望,其方差的计算可以根据定义
Var
(
U
)
=
E
[
U
2
]
−
(
E
[
U
]
)
2
\displaystyle \textrm{Var}(U) = \mathbb{E}[U^2] -(\mathbb{E}[U])^2
Var(U)=E[U2]−(E[U])2,
于是
Var
(
U
)
=
exp
(
2
μ
x
+
2
σ
x
2
)
−
exp
(
2
μ
x
+
σ
x
2
)
=
exp
(
2
μ
x
+
σ
x
2
)
⋅
(
exp
(
σ
x
2
)
−
1
)
)
\displaystyle \textrm{Var}(U) = \exp(2 \mu_x +2 \sigma_x^2) - \exp(2 \mu_x + \sigma_x^2) = \exp(2 \mu_x + \sigma_x^2) \cdot (\exp(\sigma_x^2) - 1))
Var(U)=exp(2μx+2σx2)−exp(2μx+σx2)=exp(2μx+σx2)⋅(exp(σx2)−1))。
二元对数正态分布的协方差
现在我们来看二元对数正态分布的协方差。根据协方差的定义,我们有
C
o
v
(
U
,
V
)
=
E
(
U
V
)
−
E
(
U
)
E
(
V
)
\displaystyle Cov(U, \, V) = \mathbb{E} (UV) - \mathbb{E}(U) \mathbb{E}(V)
Cov(U,V)=E(UV)−E(U)E(V)。假设
U
=
exp
(
X
)
,
V
=
exp
(
Y
)
U = \exp(X), \, V = \exp(Y)
U=exp(X),V=exp(Y),其中
X
∼
N
(
μ
x
,
σ
x
2
)
,
Y
∼
N
(
μ
y
,
σ
y
2
)
\displaystyle X \sim N(\mu_x, \, \sigma_x^2), \, Y \sim N(\mu_y, \, \sigma_y^2)
X∼N(μx,σx2),Y∼N(μy,σy2)。根据上一节的介绍,我们知道
E
(
U
)
=
exp
(
μ
x
+
1
2
σ
x
2
)
\displaystyle \mathbb{E} (U) = \exp \big( \mu_x + \frac{1}{2} \sigma_x^2 \big)
E(U)=exp(μx+21σx2),
E
(
V
)
=
exp
(
μ
y
+
1
2
σ
y
2
)
\displaystyle \mathbb{E} (V) = \exp \big( \mu_y + \frac{1}{2} \sigma_y^2 \big)
E(V)=exp(μy+21σy2)。
而对于
E
(
U
V
)
=
E
(
e
X
+
Y
)
\mathbb{E} (UV) = \mathbb{E} (e^{X + Y})
E(UV)=E(eX+Y),我们知道
X
+
Y
X + Y
X+Y 仍然服从正态分布。这是因为,如果
(
X
,
Y
)
(X, \, Y)
(X,Y) 服从二元正态分布,即
(
X
,
Y
)
(X, \, Y)
(X,Y) 的概率密度函数是 (*) 式,那么我们有如下的定理:
定理: 如果二元随机变量
(
X
,
Y
)
(X, \, Y)
(X,Y) 服从二元正态分布,即
(
X
,
Y
)
(X, \, Y)
(X,Y) 的概率密度函数是
(
∗
)
(*)
(∗) 式。那么对于任意的常数
a
,
b
a, \, b
a,b, 我们有随机变量
a
X
+
b
Y
a X + b Y
aX+bY 服从正态分布,其均值为
a
μ
x
+
b
μ
y
a \mu_x + b \mu_y
aμx+bμy,方差是
a
2
σ
x
2
+
b
2
σ
y
2
+
2
a
b
σ
x
σ
y
ρ
a^2 \sigma_x^2 + b^2 \sigma_y^2 + 2 a b \sigma_x \sigma_y \rho
a2σx2+b2σy2+2abσxσyρ。
根据上述定理,我们有
X
+
Y
∼
N
(
μ
x
+
μ
y
,
σ
x
2
+
σ
y
2
+
2
ρ
σ
x
σ
y
)
X + Y \sim N(\mu_x + \mu_y, \sigma_x^2 + \sigma_y^2 + 2 \rho \sigma_x \sigma_y)
X+Y∼N(μx+μy,σx2+σy2+2ρσxσy)。
从而
E
(
U
V
)
=
E
(
e
X
+
Y
)
=
exp
(
μ
x
+
μ
y
+
1
2
(
σ
x
2
+
σ
y
2
+
2
ρ
σ
x
σ
y
)
)
\displaystyle \mathbb{E} (UV) = \mathbb{E} (e^{X + Y}) = \exp \big( \mu_x + \mu_y + \frac{1}{2} (\sigma_x^2 + \sigma_y^2 + 2 \rho \sigma_x \sigma_y) \big)
E(UV)=E(eX+Y)=exp(μx+μy+21(σx2+σy2+2ρσxσy))。
现在,我们就可以计算
Cov
(
U
,
V
)
\displaystyle \textrm{Cov}(U, \, V)
Cov(U,V)。代入上述计算,我们有
Cov
(
U
,
V
)
=
exp
(
μ
x
+
μ
y
+
1
2
(
σ
x
2
+
σ
y
2
+
2
ρ
σ
x
σ
y
)
)
−
exp
(
μ
x
+
1
2
σ
x
2
)
⋅
exp
(
μ
y
+
1
2
σ
y
2
)
=
exp
(
μ
x
+
μ
y
+
1
2
(
σ
x
2
+
σ
y
2
)
)
⋅
(
exp
(
ρ
σ
x
σ
y
)
−
1
)
\displaystyle \textrm{Cov}(U, \, V) =\exp \big( \mu_x + \mu_y + \frac{1}{2} (\sigma_x^2 + \sigma_y^2 + 2 \rho \sigma_x \sigma_y) \big) - \exp \big( \mu_x + \frac{1}{2} \sigma_x^2 \big) \cdot \exp \big( \mu_y + \frac{1}{2} \sigma_y^2 \big) = \exp \big(\mu_x + \mu_y + \frac{1}{2} (\sigma_x^2 + \sigma_y^2) \big) \cdot \big( \exp(\rho \sigma_x \sigma_y) - 1 \big)
Cov(U,V)=exp(μx+μy+21(σx2+σy2+2ρσxσy))−exp(μx+21σx2)⋅exp(μy+21σy2)=exp(μx+μy+21(σx2+σy2))⋅(exp(ρσxσy)−1)。
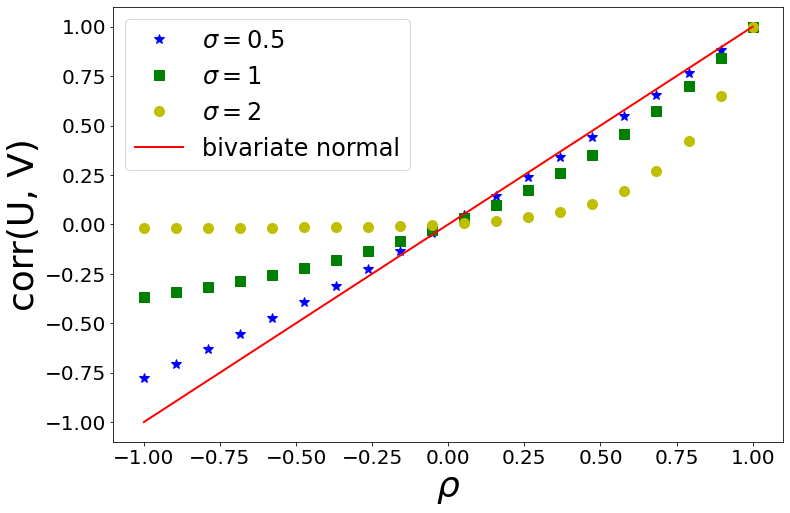
二元对数正态分布的相关系数
那么,
U
,
V
U, V
U,V 的相关系数即为:
corr
(
U
,
V
)
=
Cov
(
U
,
V
)
Var
(
U
)
⋅
Var
(
V
)
\displaystyle \textrm{corr}(U, \, V) = \frac{\textrm{Cov}(U, \, V)}{\sqrt{ \textrm{Var}(U) \cdot \textrm{Var}(V) }}
corr(U,V)=Var(U)⋅Var(V)Cov(U,V)
将
Cov
(
U
,
V
)
,
Var
(
U
)
,
Var
(
V
)
\textrm{Cov}(U, \, V), \, \textrm{Var}(U), \, \textrm{Var}(V)
Cov(U,V),Var(U),Var(V) 代入,我们有
corr
(
U
,
V
)
=
e
(
ρ
σ
x
σ
y
)
−
1
(
e
σ
x
2
−
1
)
(
e
σ
y
2
−
1
)
(
∗
∗
)
\displaystyle \textrm{corr}(U, \, V) = \frac{e^{ (\rho \sigma_x \sigma_y)} - 1}{\sqrt{(e^{\sigma_x^2} - 1) (e^{\sigma_y^2} - 1) }} \hspace{2cm} (**)
corr(U,V)=(eσx2−1)(eσy2−1)e(ρσxσy)−1(∗∗)
模拟验证
下面我们用代码快速检验下上面的相关系数的公式。 我们根据文章 生成一定相关性的二元正态分布 中的代码,生产 $N $ 对服从二元正态分布的随机数
(
X
,
Y
)
(X, \, Y)
(X,Y),然后取
U
=
exp
(
X
)
,
V
=
exp
(
V
)
U = \exp(X), \, V = \exp(V)
U=exp(X),V=exp(V),计算
U
,
V
U, V
U,V 的相关系数,然后与用公式计算得到的数值相比较。
import numpy as np
import matplotlib.pyplot as plt
classbivariateNormal:def__init__(self, rho:'float', m:int):"""
Suppose we want to generate a pair of
random variables X, Y, with X ~ N(0, 1),
Y ~ N(0, 1), and Cor(X, Y) = rho. m is
the number of data pairs we want to generate.
"""
self.rho = rho
self.m = m
defgenerateBivariate(self)->'tuple(np.array, np.array)':"""
Generate two random variables X, Y, with X ~ N(0, 1),
Y ~ N(0, 1), and Cor(X, Y) = rho.
self.m is the number of sample points we generated.
We return a tuple (X, Y).
"""
theta = np.arcsin(self.rho)/2
A = np.random.normal(0,1, self.m)
B = np.random.normal(0,1, self.m)
X = np.cos(theta)* A + np.sin(theta)* B
Y = np.sin(theta)* A + np.cos(theta)* B
return X, Y
我们取
μ
x
=
μ
y
=
0
,
σ
x
=
σ
y
=
1
\mu_x = \mu_y = 0, \, \sigma_x = \sigma_y = 1
μx=μy=0,σx=σy=1,生成
N
N
N 对服从二元正态分布的随机变量取值
(
X
,
Y
)
(X, \, Y)
(X,Y) 。这里取
N
=
1
0
4
N = 10^4
N=104。
N =10**4
exp_corr =0# 记录要模拟的二元对数正态分布的相关系数
rho =-0.9
m =10**4
a = bivariateNormal(rho, m)for i inrange(N):
x, y = a.generateBivariate()
x_exp = np.exp(x)
y_exp = np.exp(y)
exp_corr += np.corrcoef(x_exp, y_exp)[0][1]print(exp_corr / N)
输出结果如下:
-0.3475984850891084
而根据上述的分析,其解析值应该为
e
−
0.9
−
1
e
−
1
=
−
0.34536263518051
\displaystyle \frac{e^{-0.9} - 1}{e - 1} = -0.34536263518051
e−1e−0.9−1=−0.34536263518051。