注意事项:以下bigdata100均记得更换为bigdata1即可
确保本地电脑已经安装好了VMware Workstation Pro
下载地址:下载 VMware Workstation Pro | CN
清华大学镜像源:
https://mirrors.tuna.tsinghua.edu.cn/centos/7/isos/x86_64/



以下的bigdata100记得改成bigdata1就好了

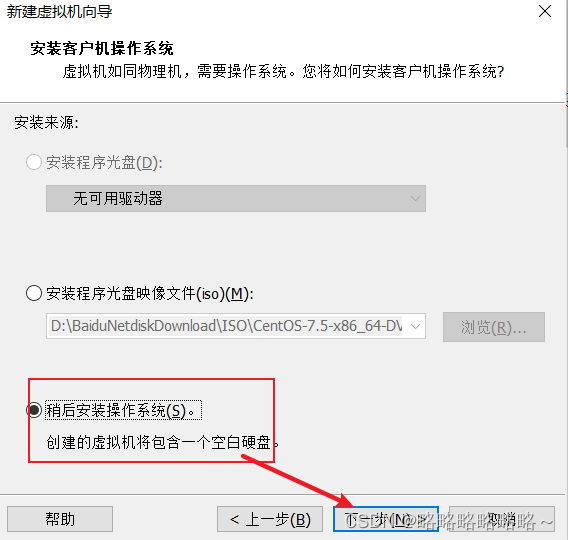
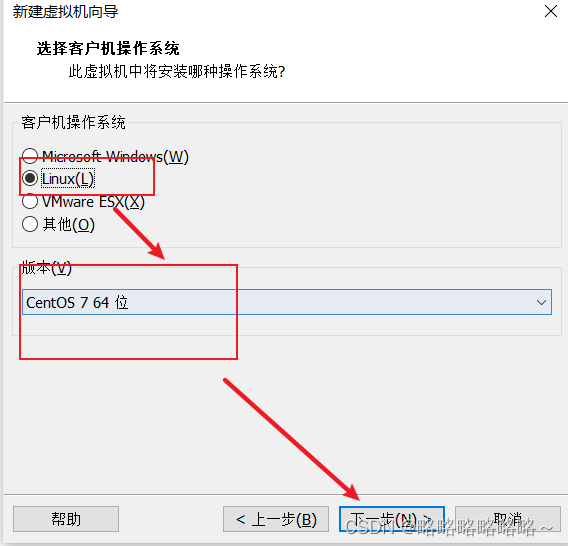

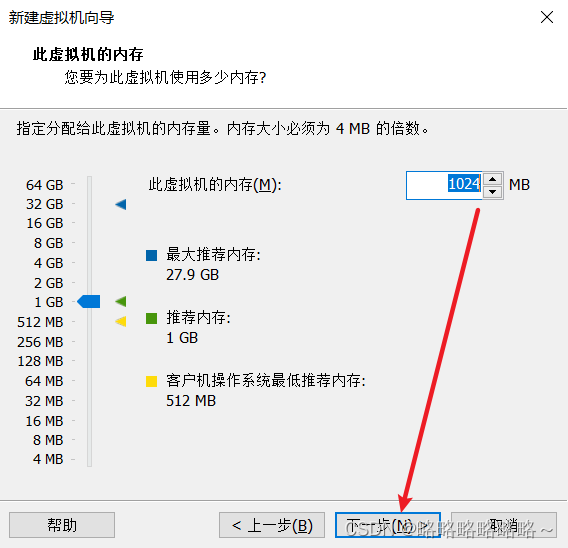
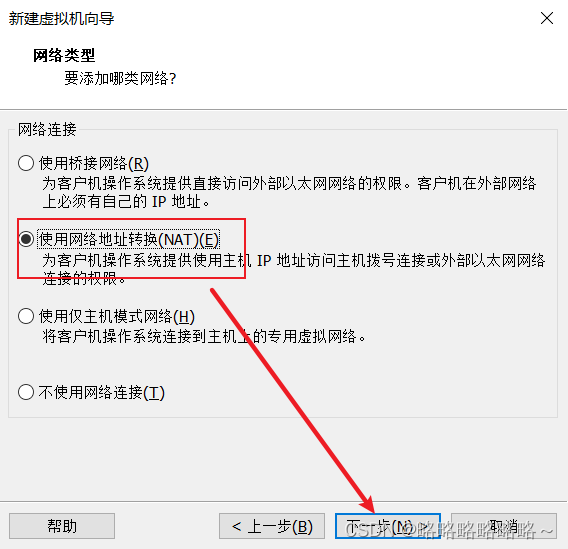


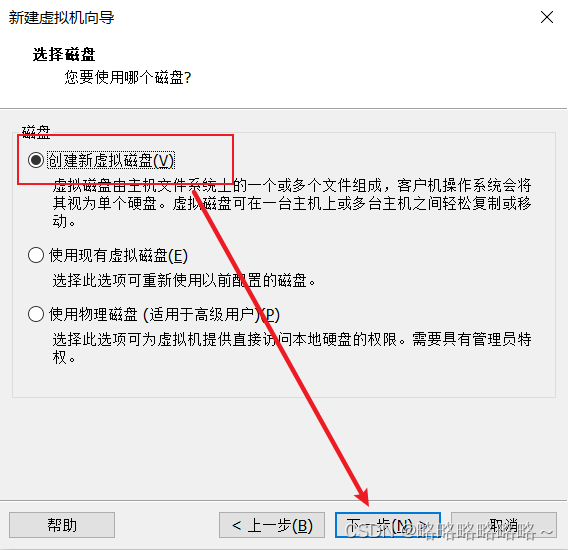
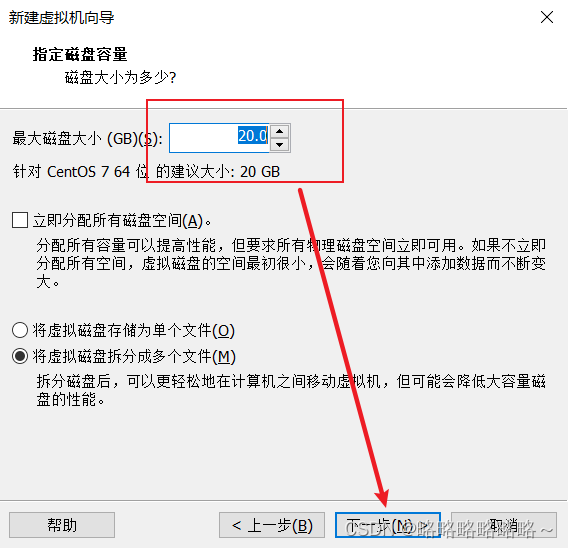
请将下面bigdata100改为bigdata1即可
安装好以后,如下即可

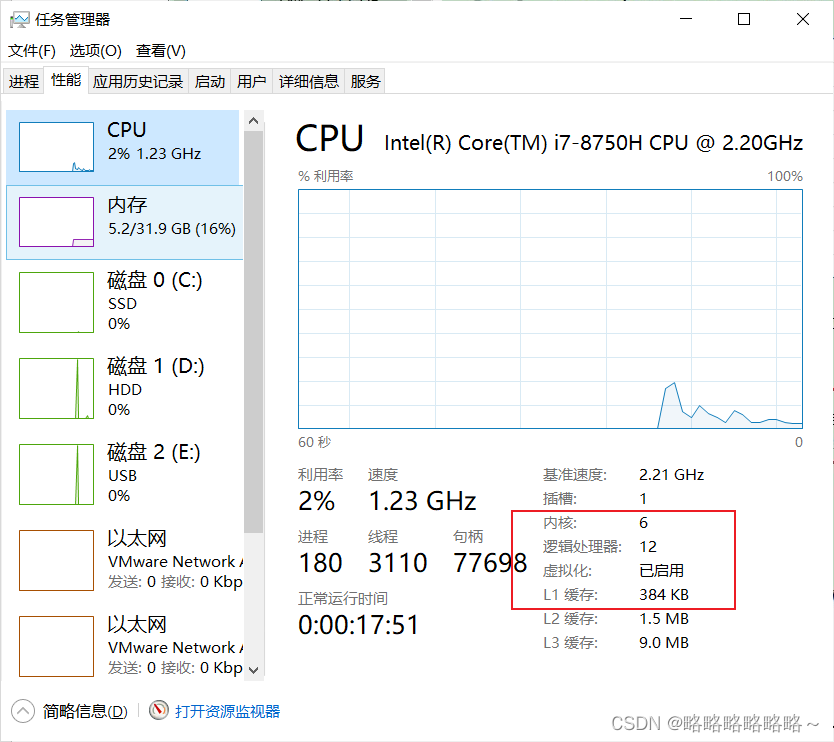
确保系统虚拟化已经打开(如果没打开还要打开虚拟化,百度)

接着选中ISO镜像即可
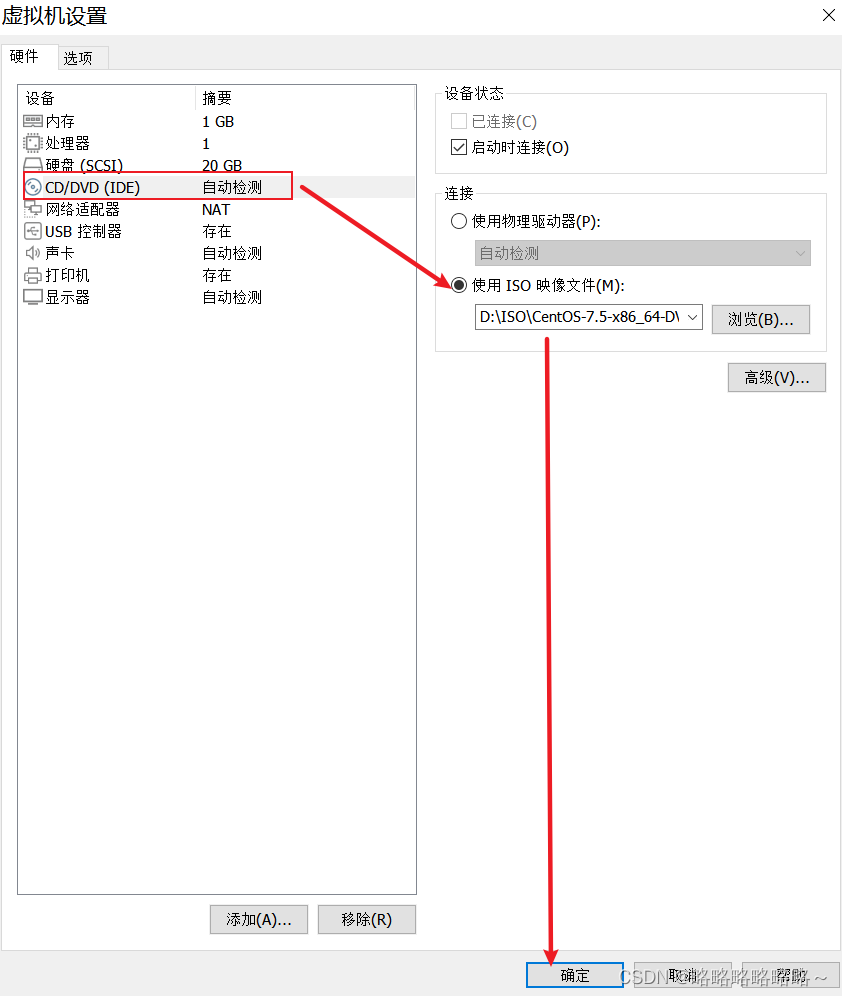
确定以后,我们在主界面需要看到ISO已经被使用

然后启动虚拟机即可,等待片刻,出现如下画面
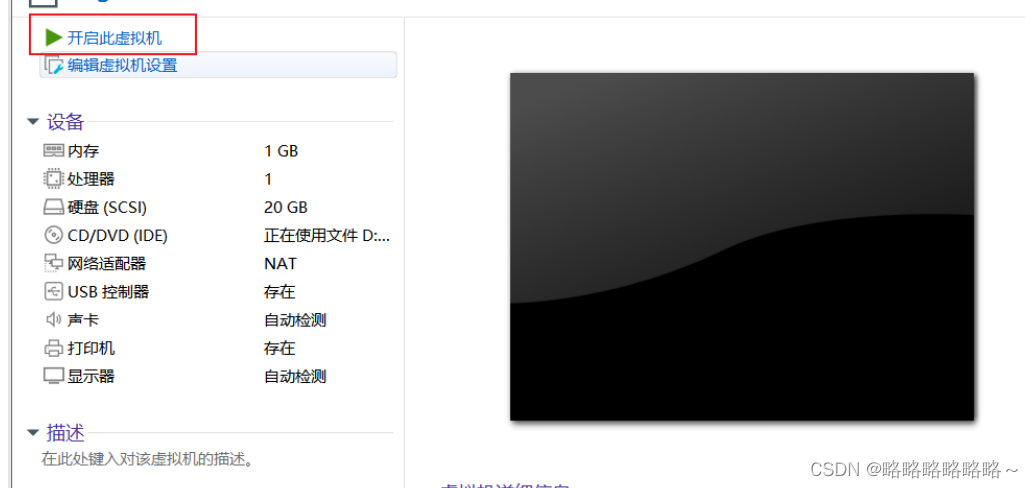
以下界面鼠标左键进入,然后回车即可
稍等片刻选择语言

选择好语言之后,就直接进入下一步
接着设置好时间,和当前时间保持一致即可

接着我们选择软件按照模式,选择最小化按照即可


然后是系统分区,这个我们简单设置一下即可
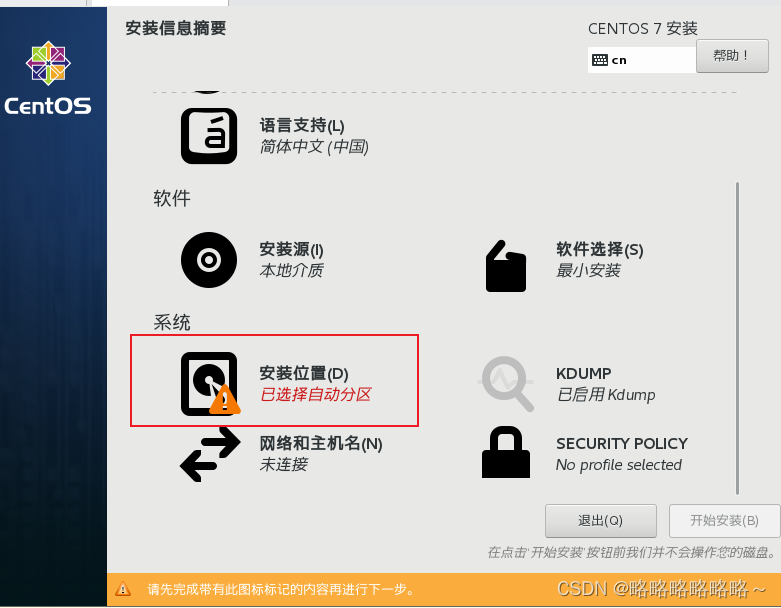
选择自定义分区
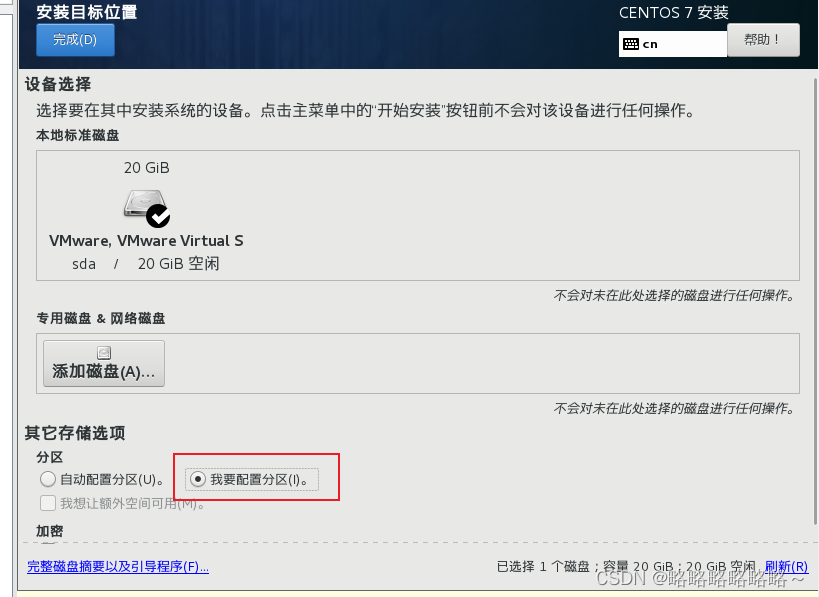
分区的情况参考如下


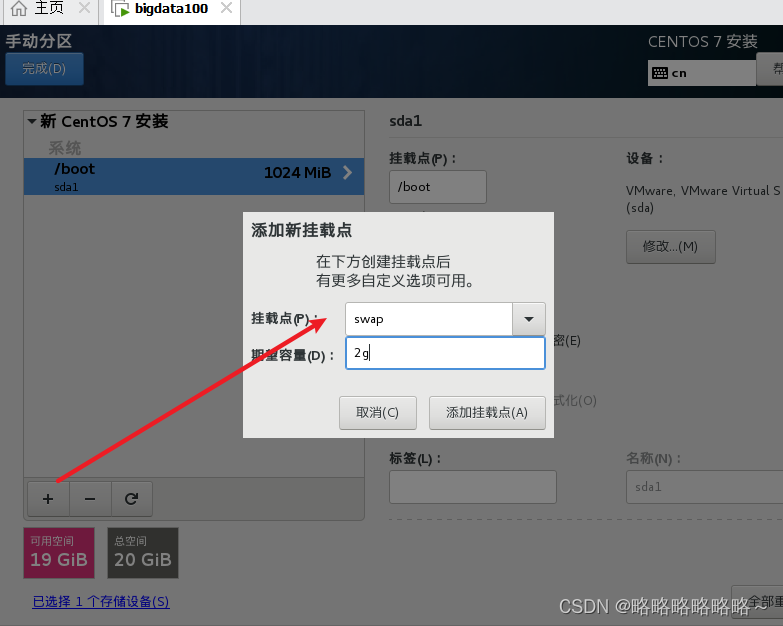

最后点击完成即可
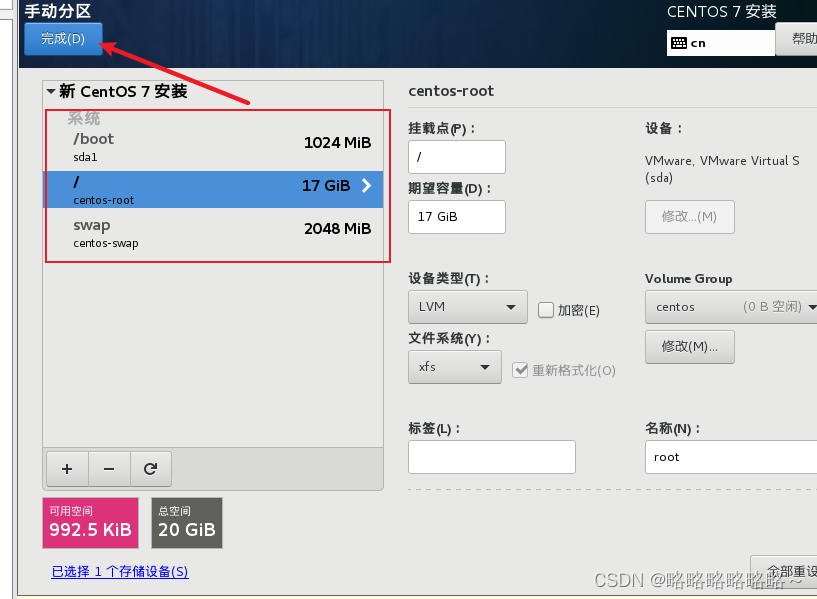
然后接收更改
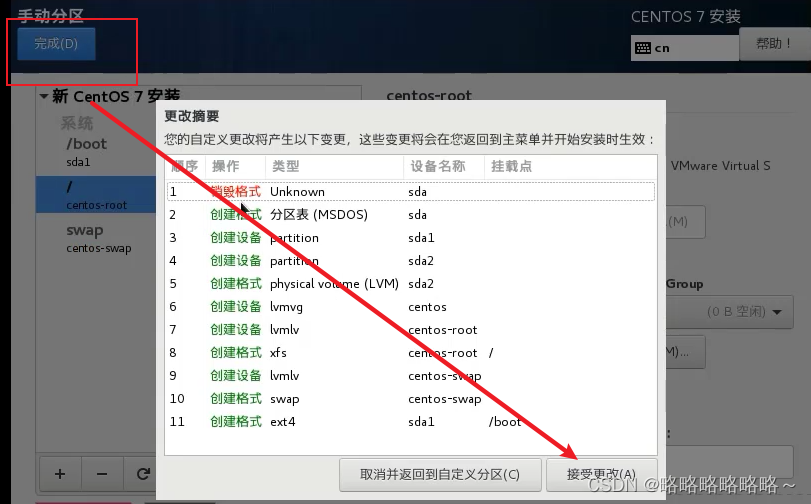

建议不要启用kdump,因为我们虚拟机内存太小了
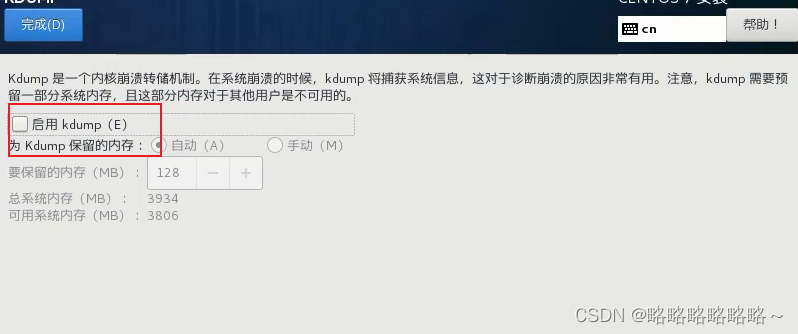
下图的hadoop100记得改成bigdata1!

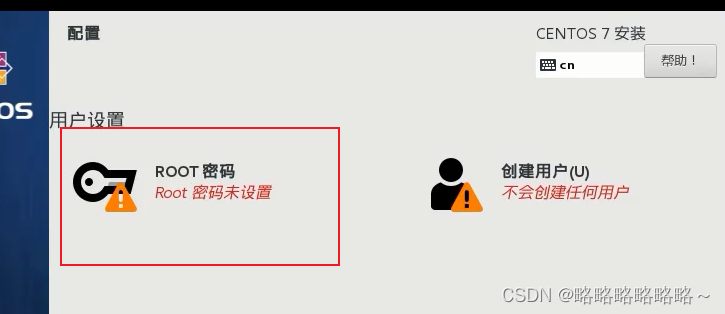
然后设置一下root用户密码,123456即可
最后重启即可
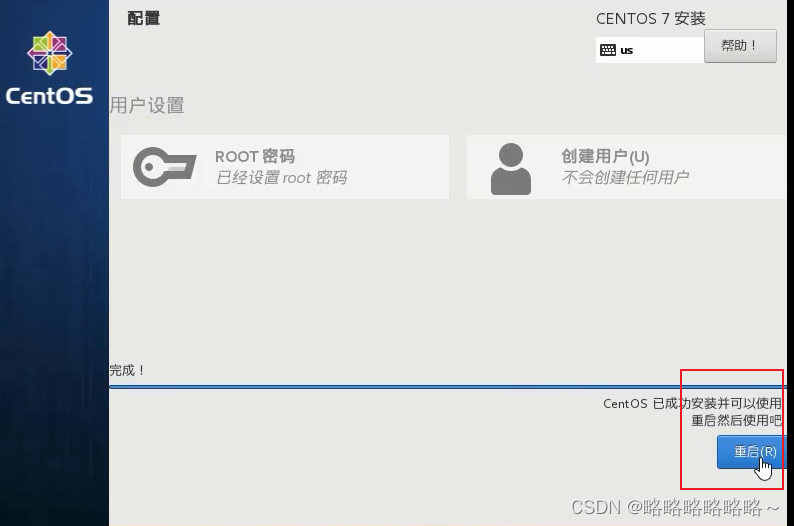

出现以上界面表示成功!
关机命令:shutdown -h now,输入即可关机
建议大家关机以后做一个快照!
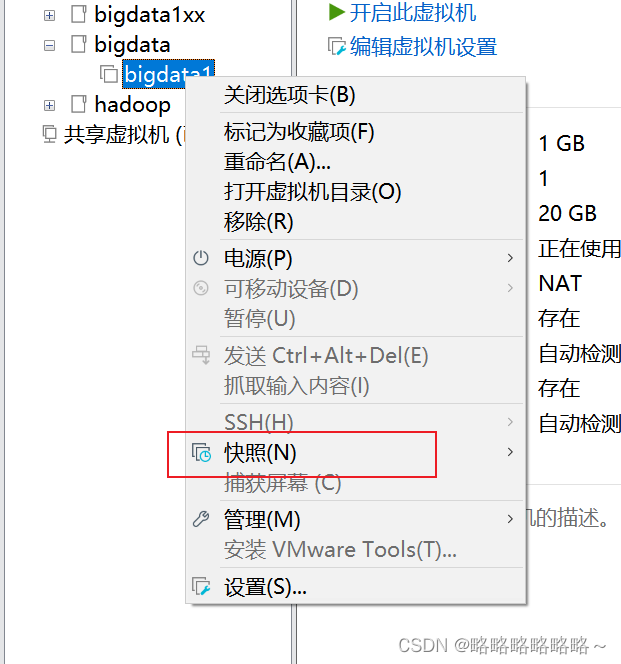
然后新建快照即可
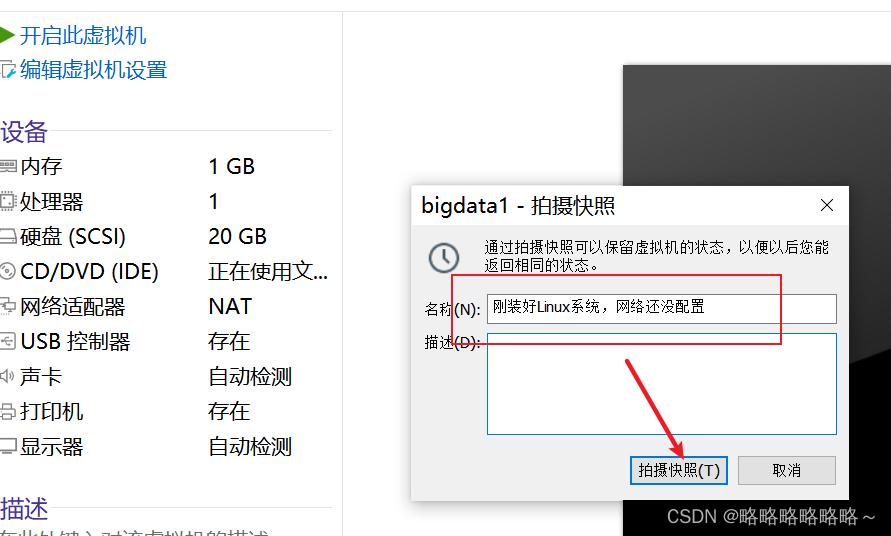
首先编辑VMware Workstation Pro的虚拟网络编辑器

接着更改NAT网络的设置

设置子网IP
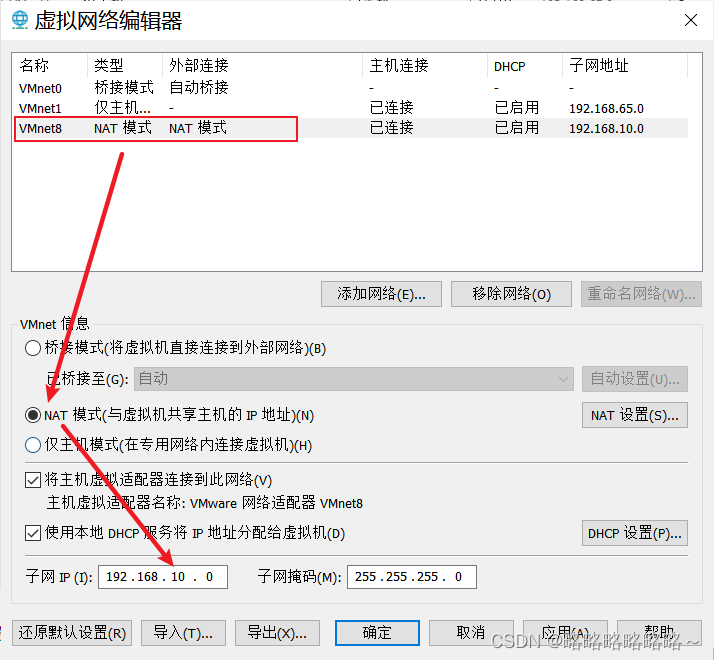
然后确定网关
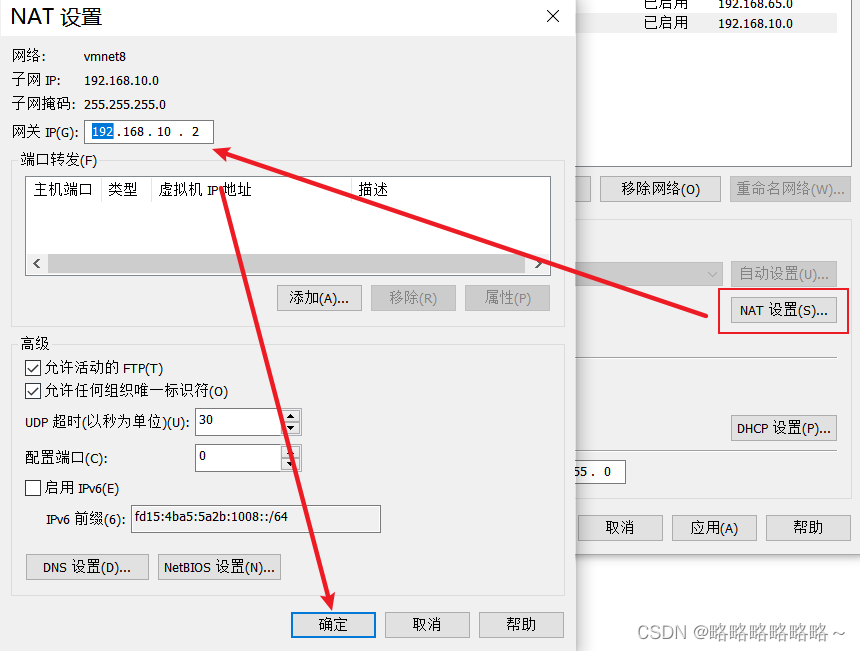
以上就是VMware Workstation Pro的网络设置
接下来我们还要完成Windows上面的网络配置
选择net8网卡

照着如下进行修改即可
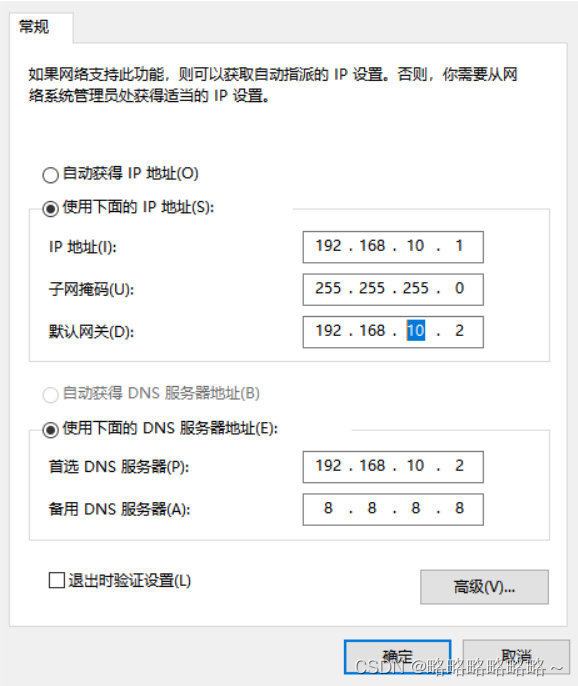
接着我们需要修改bigdata1的这个主机的网络信息

修改如下

改好了之后,我们还需要修改一下主机名(如果安装系统的时候改了的那么就不用再改了)

修改如下

最后我们做一下域名映射

修改如下
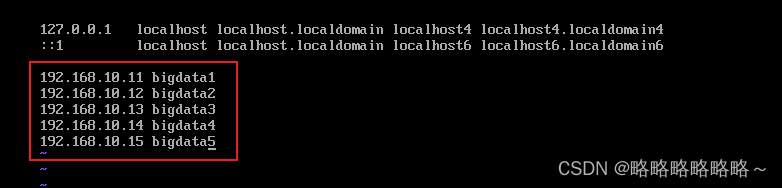
修改完以后,我们重启网络服务
service network restart

验证如下:
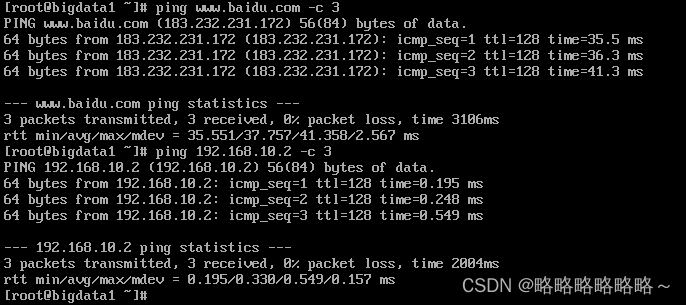
还需要配置Windows上面的域名映射
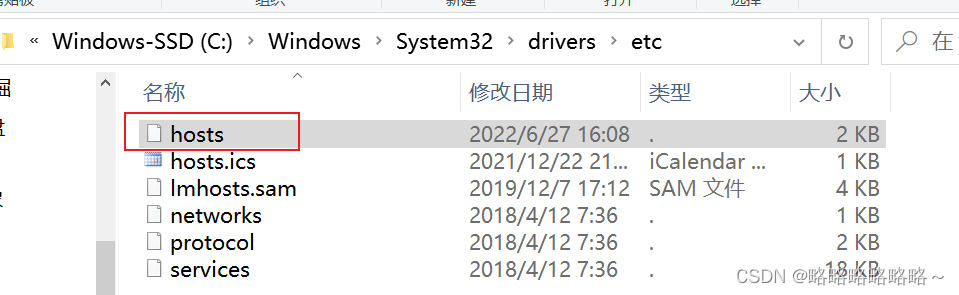
修改如下,新增如下内容

修改hosts为了立即生效,我们需要将修改刷新到缓存中
打开cmd窗口

做好之后,我们还需要稍微改一下bigdata1
使用yum安装额外的软件升级包
yum install -y epel-release
最后我们再安装一下网络包
yum install -y net-tools

测试:使用ifconfig命令

安装vim
yum install -y vim

测试:使用vim命令
以上步骤做完以后,我们最好进行快照备份!!!
先关机,再快照!!!
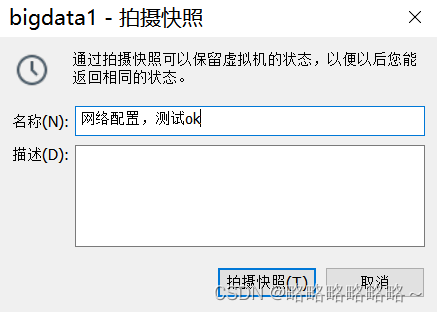
至此,母机bigdata1就搞定了!
远程连接工具使用
这里使用的是xshell和xftp,如果之前用的是其他的也可以使用其他的。
打开xshell,可以新建一个文件夹专门管理会话
然后新建一个会话

然后设置会话属性
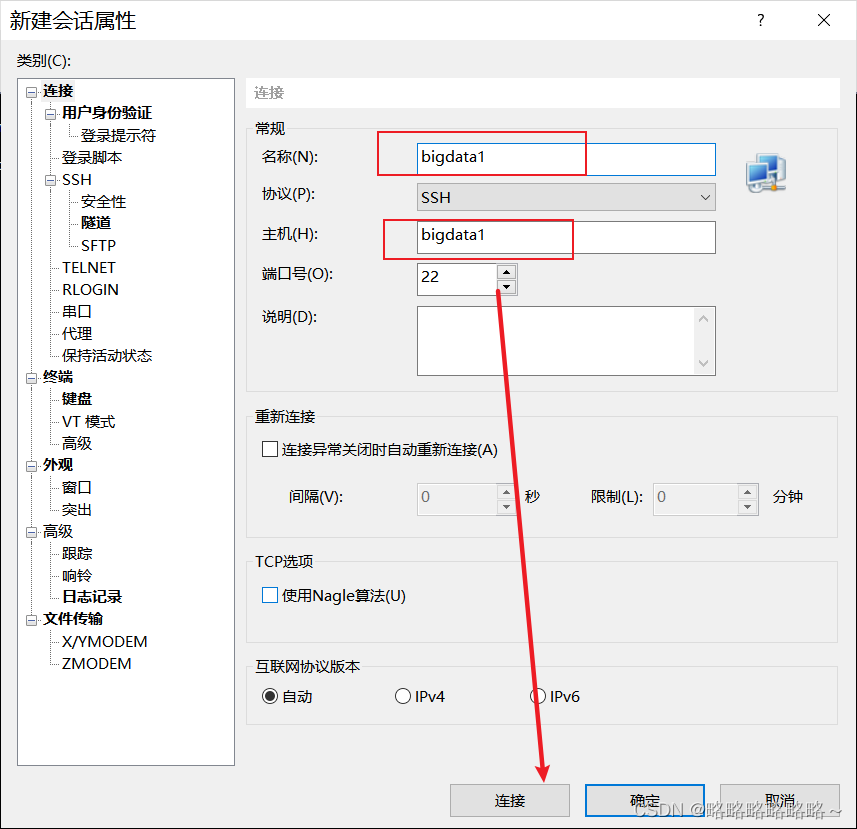
接收并保持密钥

输入用户名和密码即可

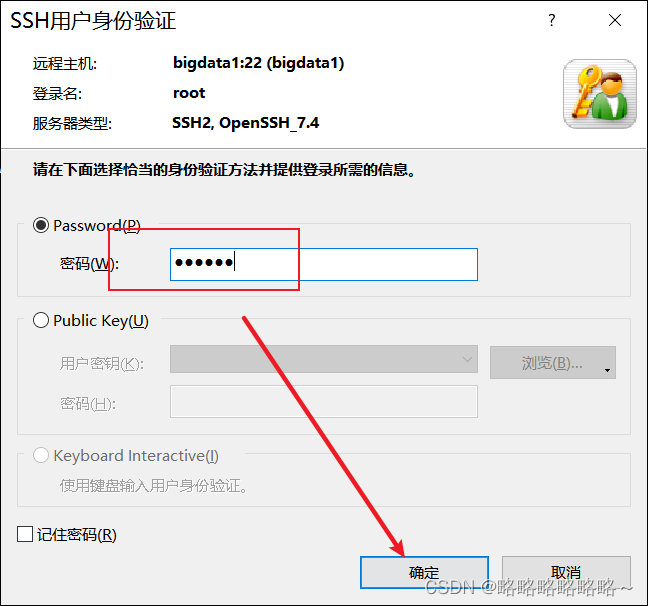
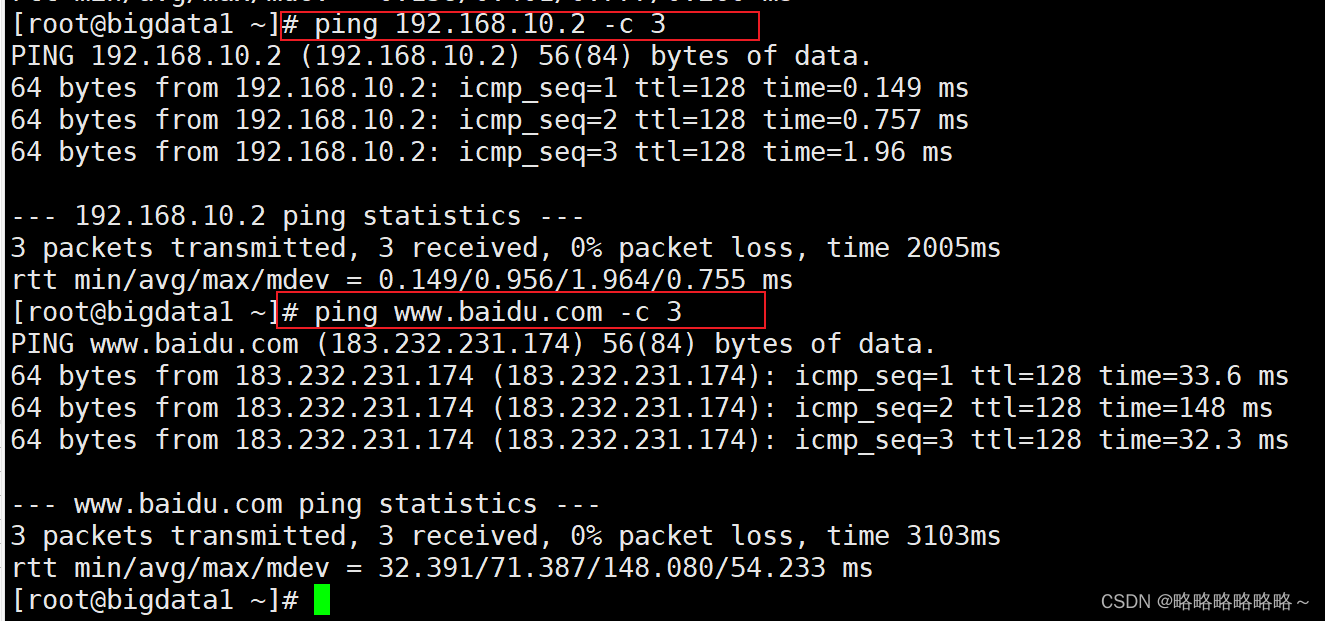
连接成功以后,我们就可以在xshell中进行bigdata1的访问了
测试如下
如果需要使用xftp,可以直接点击
四、环境配置
我们接着关闭bigdata1上面的防火墙服务

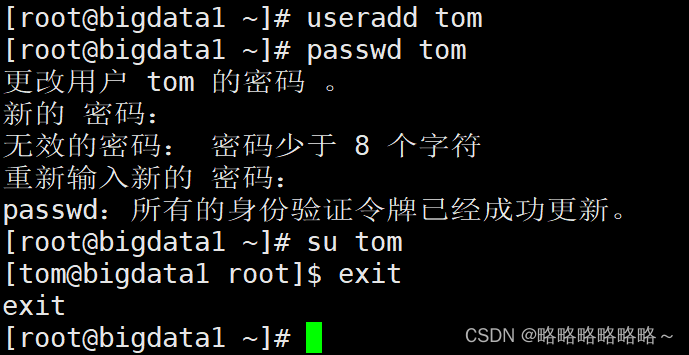
完成之后,我们建立一个普通用户tom,密码是:123456 用于后续的所有操作
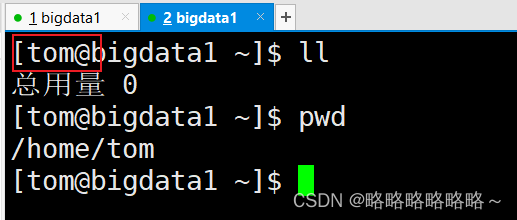
设置完成以后,我们最好使用tom这个用户登录测试
测试ok以后,我们需要给tom添加管理员的权限

进入 sudoers文件,进行如下修改即可

注意事项:保存需要使用 :wq! 强制保存退出!
接着我们创建两个目录,一个叫software,用来存放上传的软件和压缩包,一个叫module,用来存放解压后的文件
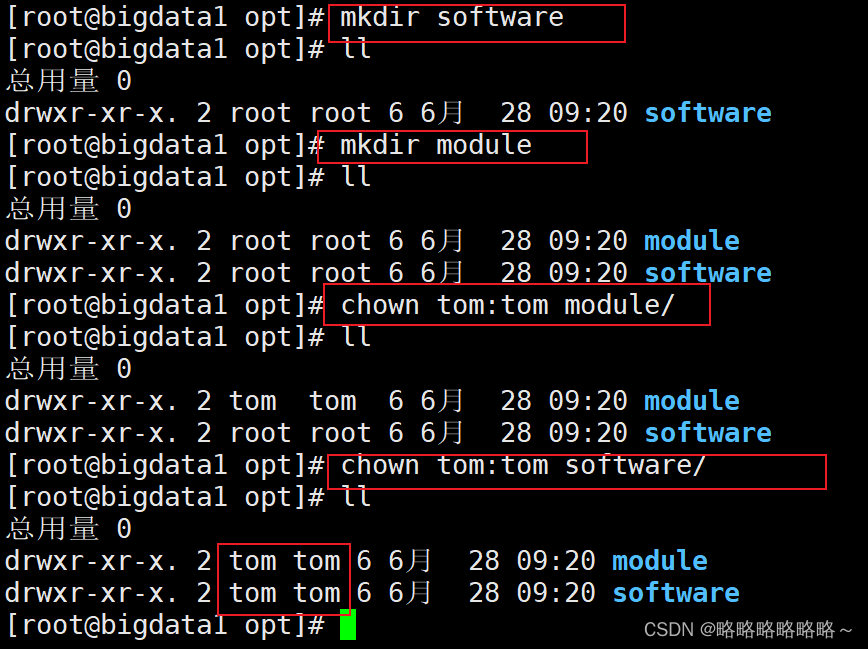
接着上传文件
使用tom登录,在tom的家目录下上传软件,一个是jdk的包,一个是Hadoop的包
使用xftp进行上传
上传成功以后,将压缩包移动到 /opt/software 目录下

然后解压即可
| [tom@bigdata1 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ [tom@bigdata1 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ |
最后可以删除掉压缩包,节省磁盘
| [tom@bigdata1 software]$ rm hadoop-3.1.3.tar.gz [tom@bigdata1 software]$ rm jdk-8u212-linux-x64.tar.gz |
接着我们需要配置jdk的环境变量和Hadoop的环境变量
在/etc/profile.d目录下新建一个自己的环境变量脚本
| [tom@bigdata1 module]$ sudo vim /etc/profile.d/my_env.sh |
打开之后,将下面内容粘贴到脚本中即可
| #配置jdk的环境变量 export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin |
如下所示

最后 :wq 保存退出即可
然后刷新环境变量
| [tom@bigdata1 module]$ source /etc/profile |
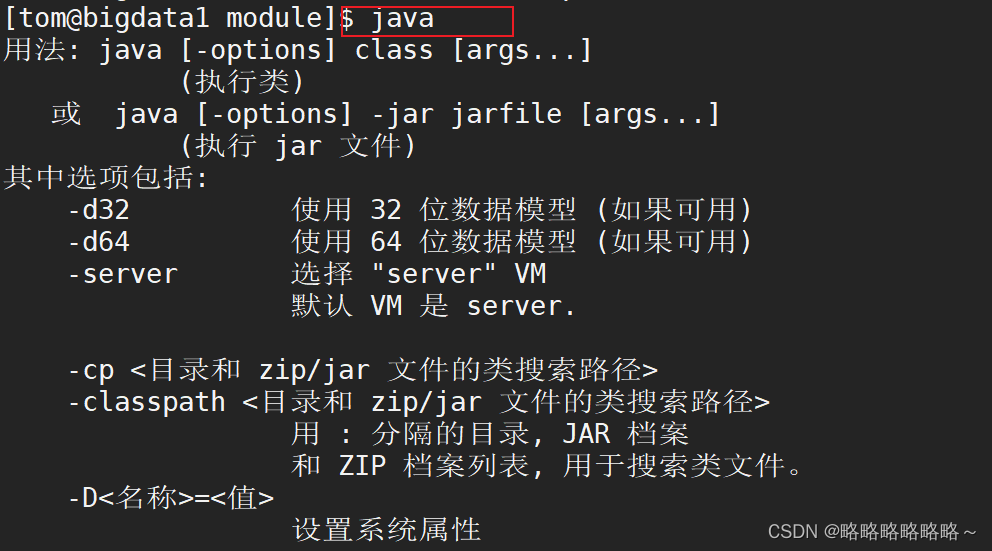
接着输入java,出现下图表示jdk环境配置成功!
复制粘贴的办法
要么复制文本内容,要么就复制文件,复制文件可以使用xftp进行文件传输,或者使用小工具进行文件的上传和下载
| [tom@bigdata1 profile.d]$ sudo yum -y install lrzsz |
安装成功以后,就可以通过sz 命令进行文件的下载

如果要进行文件的上传,直接输入rz然后回车即可(如果传输失败,可能是权限不足,需要在 rz前面加上sudo )

完成jdk的环境变量配置后,没有问题我们再继续完成Hadoop的环境变量配置
还是打开自定义的配置文件
| [tom@bigdata1 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh |
然后进行如下修改
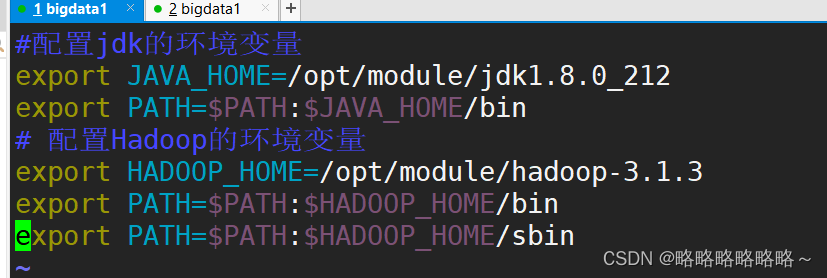
保存退出后,刷新环境变量
| [tom@bigdata1 module]$ source /etc/profile |
测试Hadoop的环境变量配置

测试wordcount
在指定目录下新建输入文件路径
| [tom@bigdata1 hadoop-3.1.3]$ pwd /opt/module/hadoop-3.1.3 [tom@bigdata1 hadoop-3.1.3]$ mkdir wcinput |
然后进入wcinput目录下,编写输入文件

编辑内容如下
| james durant curry kobe james james |
然后保存退出
接着我们在hadoop目录下,输入wordcount的命令即可
| [tom@bigdata1 wcinput]$ cd .. [tom@bigdata1 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ wcoutput |
执行成功后,验证如下图所示

最后我们关机快照!!!

五、集群配置
首先需要关机bigta1,然后以bigdata1作为母机进行克隆,我们这里采用的是链接克隆(类似于超链接)
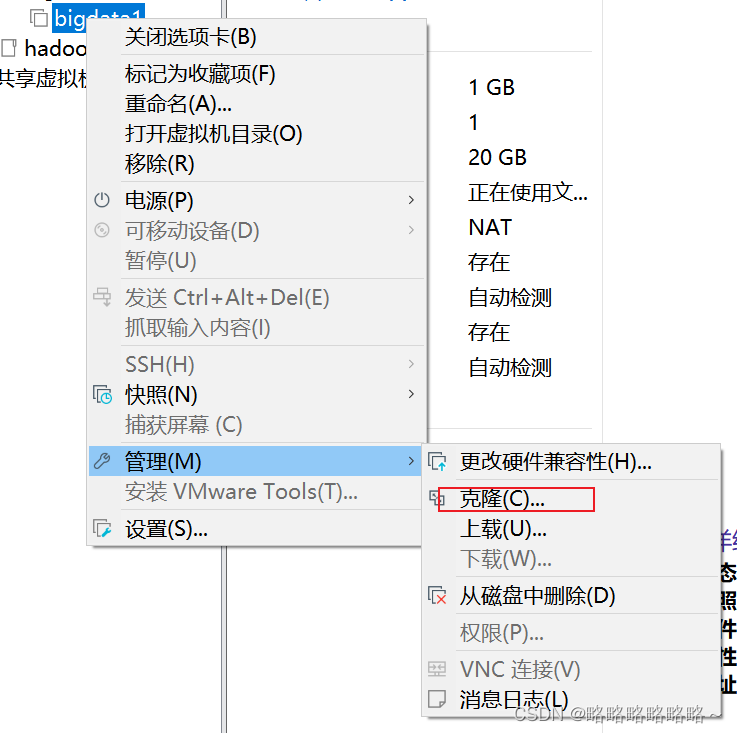
接着选择快照的位置

选择链接克隆

然后修改名字和存放路径(不必跟我保持一致)
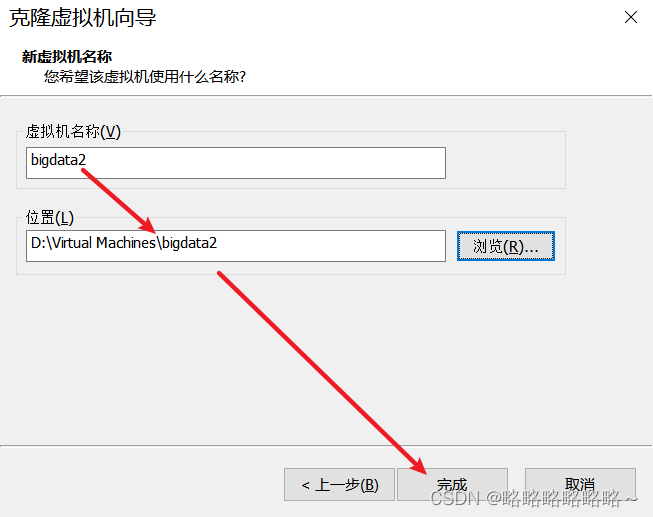
接着我们依葫芦画瓢,完成bigdata3的克隆,最后结果如下

对克隆后的虚拟机,我们还需要稍作修改
首先打开2和3,然后修改主机名和ip(以bigdata2为例)
修改主机名为 bigdata2即可
然后修改ip

将ip改为192.168.10.12

改完后使用 reboot命令重启即可
测试如下
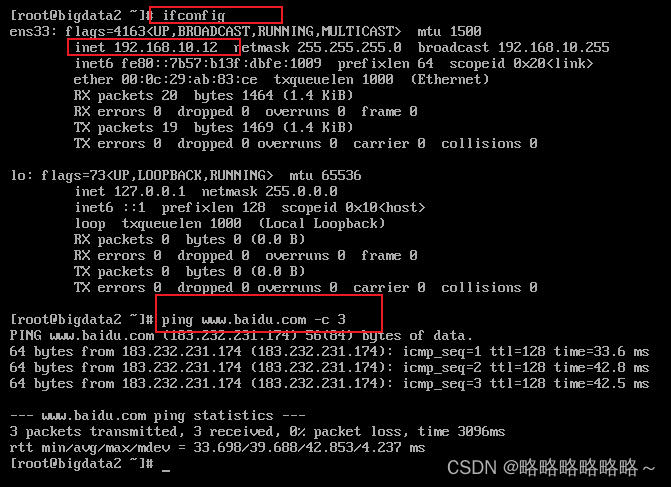
改完之后,同理对bigdata3进行相同的修改即可
都改完之后,对2和3都要进行关机快照!

接着打开三台虚拟机,bigdata1,bigdata2,bigdata3,然后使用xshell进行连接,连接成功后我们最好三台虚拟机互pnig

然后我们写一个同步文件的命令xsync
在 /home/tom/目录下新建一个bin目录,然后进入bin目录,使用 vim xsync创建一个xsync文件
在xsync文件里面输入
| #!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有的机器 for host in bigdata1 bigdata2 bigdata3 do echo =========================== $host ================ #3. 遍历所有目录,发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done |
然后赋予执行的权限
| [tom@bigdata1 bin]$ chmod u+x xsync |
然后可以测试xsync
| [tom@bigdata1 ~]$ xsync bin |
输入yes和密码123456,就可以在2和3上面看见从1同步过来的的bin目录和bin目录里面的文件

为了更加方便后续的操作,我们最好还做一下免密登录
进入 /home/tom/.ssh 目录下(如果没有 .ssh 目录可以使用mkdir 创建一下)
然后使用指定的命令生成免密登录需要的公钥和私钥
| [tom@bigdata1 .ssh]$ ssh-keygen -t rsa |
一直回车,就可以发现生成成功

做完之后,将公钥发给其他虚拟机
| [tom@bigdata1 .ssh]$ ssh-copy-id bigdata1 [tom@bigdata1 .ssh]$ ssh-copy-id bigdata2 [tom@bigdata1 .ssh]$ ssh-copy-id bigdata3 |
每次执行命令输入123456密码即可
最后测验免密登录
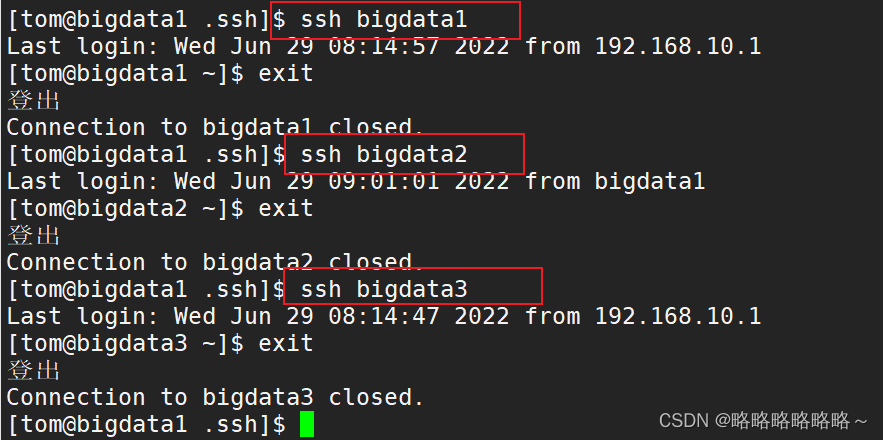
如果没问题就完成2和3的免密操作,和1同理
在bigdata2上演示免密登录
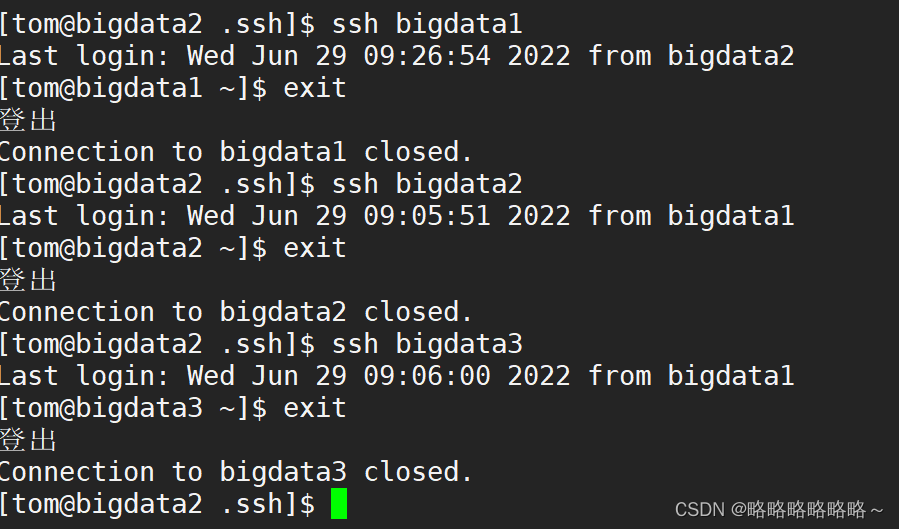
在bigdata3上演示免密登录
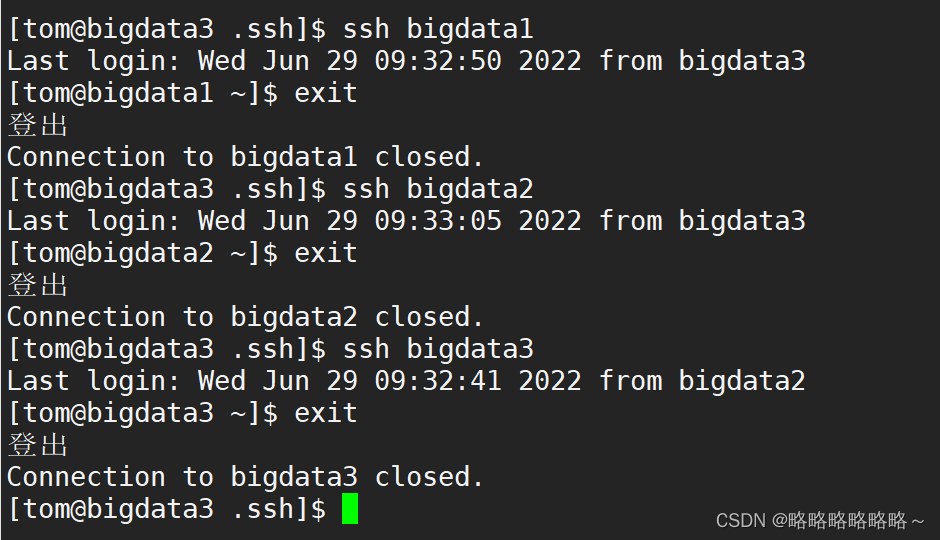
做完之后,我们需要关机快照,关机可以使用一个简单的脚本完成群关机。
在 /home/tom/bin 目录下,上传群关机的脚本 gj ,然后赋予一个执行的权限即可
| [tom@bigdata1 bin]$ chmod u+x gj |
然后就可以直接输入 gj 进行1,2,3的同时关机了,比较方便
关机以后,我们再对1,2,3进行快照,如下

完成快照后,打开1,2,3,我们接下来就要完成Hadoop的分布式环境搭建
首先是配置文件的修改,在 /opt/module/hadoop-3.1.3/etc/hadoop 目录下,针对五个配置文件(mapred-site.xml,yarn-site.xml,hdfs-site.xml,core-site.xml,workers)进行修改,直接使用我改好的即可
替换成群里改好的配置文件以后,做配置文件的分发,如下图所示

测试
首先格式化nanenode服务
| [tom@bigdata1 hadoop-3.1.3]$ hdfs namenode -format |
格式化成功以后,需要启动Hadoop试试
在bigdata1上面启动HDFS
| [tom@bigdata1 hadoop-3.1.3]$ start-dfs.sh |
启动成功后,使用jps命令查看1,2,3上面的进程,如下图



然后还要启动Yarn服务
在bigdata2上面启动!!
| [tom@bigdata2 hadoop-3.1.3]$ start-yarn.sh |
然后启动Yarn如下图
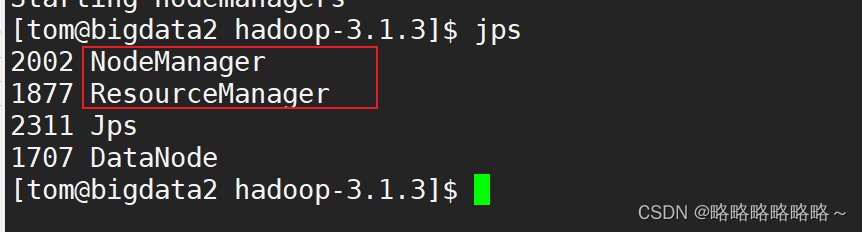
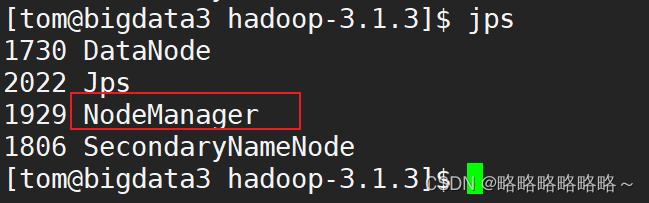

最后,我们还可以通过浏览器来查看验证HDFS和Yarn服务是否正常启动

Yarn服务的界面如下

如果执行过程中出现问题,或者配置修改文件重新改过,那么第二次格式化namenode的时候,就需要删除掉1,2,3上面的 logs和data
然后再对bigdata1上面重新进行namenode的格式化
关闭Hadoop集群的命令如下
在bigdata1上面执行如下命令
| [tom@bigdata1 hadoop-3.1.3]$ stop-dfs.sh |
然后在bigdata2上面执行如下命令
| [tom@bigdata2 hadoop-3.1.3]$ stop-yarn.sh |
然后关机快照即可
开机以后,为了更加方便的在1号机的终端查看所有的Java进程,我们可以执行一个脚本 jpsall 来查看
在bigdata1的 /home/tom/bin 目录下,将我写好的文件jpsall上传,上传以后赋予执行的权限
| [tom@bigdata1 bin]$ chmod u+x jpsall |
然后启动hadoop,在1上面执行 start-dfs.sh ,然后在2号机上面执行 start-yarn.sh 即可,然后在1号机上面输入 jpsall命令即可进行查看

然后我们为了更加方便的启动Hadoop集群和关闭Hadoop集群,我们还可以使用一个脚本去群起和群关
首先关闭1上面的HDFS和2上面的Yarn进程,然后将我改好的脚本文件上传到1的 /home/tom/bin 目录下
然后赋予脚本执行的权限
| [tom@bigdata1 bin]$ chmod u+x myhadoop |
接着我们就可以输入以下命令进行启动和关闭了
| [tom@bigdata1 bin]$ myhadoop start |
启动后,使用jpsall命令记得查看一下进程是否都启动成功
如果想要关闭,那么使用以下命令进行关闭
| [tom@bigdata1 bin]$ myhadoop stop |
关闭后记得也用jpsall 命令查看一下进程是否都关闭成功
MySQL的安装
首先删除bigdata1上面自带的数据库
| [tom@bigdata1 ~]$ rpm -qa|grep mariadb mariadb-libs-5.5.56-2.el7.x86_64 [tom@bigdata1 ~]$ sudo rpm -e --nodeps mariadb-libs [tom@bigdata1 ~]$ rpm -qa|grep mariadb |
然后将群里的MySQL安装包上传到bigdata1的 /opt/software 目录下,上传成功后进行解压
| [tom@bigdata1 software]$ tar -xvf mysql-5.7.38-1.el7.x86_64.rpm-bundle.tar |
通过yum安装缺少的依赖
| [tom@bigdata1 software]$ sudo yum install -y libaio |
然后再进行安装了
| [tom@bigdata1 software]$ sudo rpm -ivh mysql-community-common-5.7.38-1.el7.x86_64.rpm [tom@bigdata1 software]$ sudo rpm -ivh mysql-community-libs-5.7.38-1.el7.x86_64.rpm [tom@bigdata1 software]$ sudo rpm -ivh mysql-community-libs-compat-5.7.38-1.el7.x86_64.rpm [tom@bigdata1 software]$ sudo rpm -ivh mysql-community-client-5.7.38-1.el7.x86_64.rpm [tom@bigdata1 software]$ sudo rpm -ivh mysql-community-server-5.7.38-1.el7.x86_64.rpm |
注意顺序一定不要错!
安装成功以后,我们进入 /var/lib/mysql 路径下,查看当前路径下有没有多余的文件,如果有,记得删除
| [tom@bigdata1 mysql]$ pwd /var/lib/mysql [tom@bigdata1 mysql]$ sudo rm -rf ./* |
上述红色命令一定不要自己手写
接着我们初始化MySQL
| [tom@bigdata1 software]$ sudo mysqld --initialize --user=mysql |
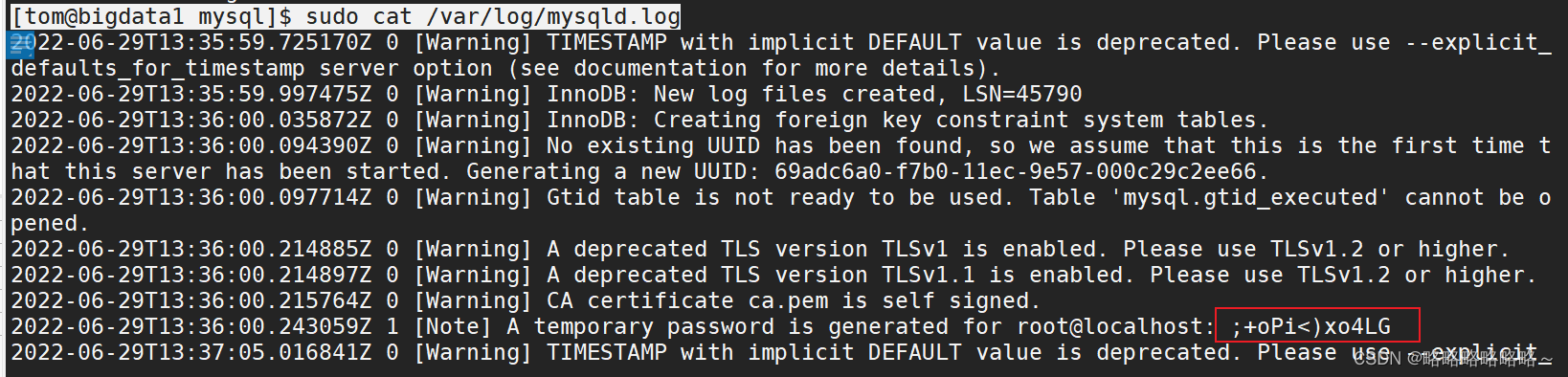
完成后我们可以查看随机生成的密码
| [tom@bigdata1 mysql]$ sudo cat /var/log/mysqld.log |
临时生成的密码如下(随机生成)
启动MySQL服务
| [tom@bigdata1 mysql]$ sudo systemctl start mysqld |
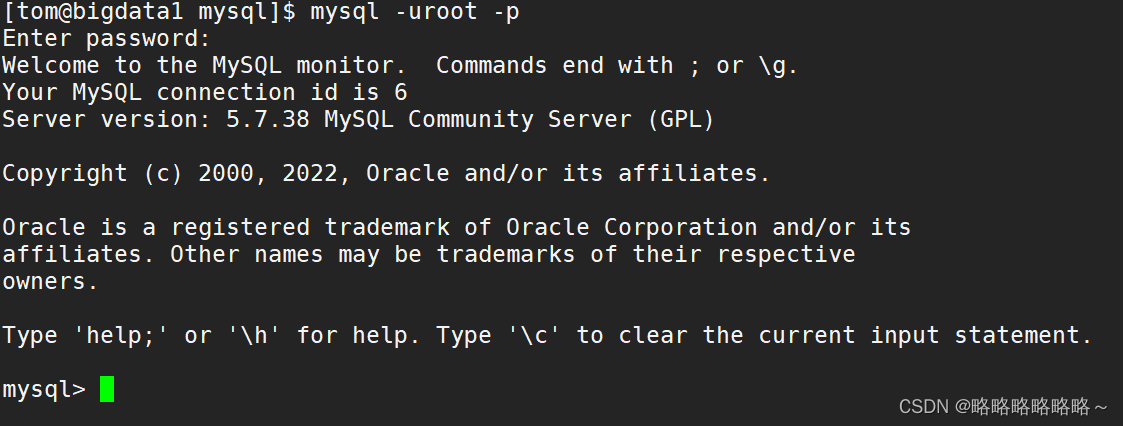
启动成功以后,我们需要输入上面临时生成的密码登录
| [tom@bigdata1 mysql]$ mysql -uroot -p Enter password: |
登录成功以后,如下图所示
然后我们将MySQL的登录密码设置为123456
| mysql> set password = password("123456"); |
然后我们需要设置一下MySQL允许任意ip连接
| mysql> update mysql.user set host='%' where user='root'; mysql> flush privileges; |
接着在Windows上远程连接bigdata1的 MySQL进行测试

最后我们进行Hive的配置和测试
首先将Hive和MySQL驱动的压缩包进行上传,上传到 /opt/software 目录下进行解压
| [tom@bigdata1 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/ [tom@bigdata1 software]$ tar -zxvf mysql-connector-java-5.1.27.tar.gz |
然后对Hive进行重命令
| [tom@bigdata1 module]$ mv apache-hive-3.1.2-bin hive-3.1.2 |
然后配置Hive的环境变量,这里直接将我的拿去替换即可
| [tom@bigdata1 module]$ sudo vim /etc/profile.d/my_env.sh |
| #配置jdk的环境变量 export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin # 配置Hadoop的环境变量 export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin #HIVE_HOME export HIVE_HOME=/opt/module/hive-3.1.2 export PATH=$PATH:$HIVE_HOME/bin |
做完之后,记得刷新环境变量
| [tom@bigdata1 module]$ source /etc/profile |
然后解决日志冲突的问题
| [tom@bigdata1 module]$ mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak |
初始化Hive的元数据库
| [tom@bigdata1 hive-3.1.2]$ pwd /opt/module/hive-3.1.2 [tom@bigdata1 hive-3.1.2]$ bin/schematool -dbType derby -initSchema |
尝试启动连接Hive(提前启动Hadoop集群)
| [tom@bigdata1 hive-3.1.2]$ bin/hive |
启动连接成功如下
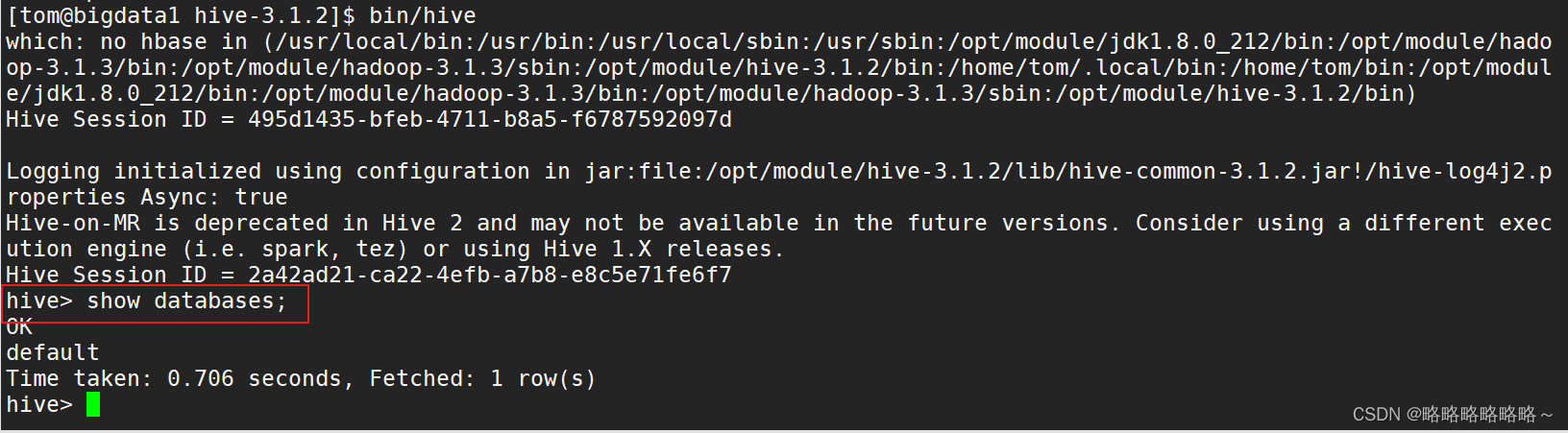
退出Hive
接着我们将Hive的元数据数据库修改为MySQL即可
首先将MySQL的驱动放入到Hive的lib路径下
| cp /opt/software/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar $HIVE_HOME/lib |
然后修改Hive的配置文件
| [tom@bigdata1 hive-3.1.2]$ vim $HIVE_HOME/conf/hive-site.xml |
新增内容如下
| <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- jdbc 连接的 URL --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://bigdata1:3306/metastore?useSSL=false</value> </property> <!-- jdbc 连接的 Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- jdbc 连接的 username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- jdbc 连接的 password --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!-- Hive 元数据存储版本的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!--元数据存储授权--> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!-- Hive 默认在 HDFS 的工作目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> </configuration> |
然后登录MySQL,创建一个叫 metastore的数据库
| [tom@bigdata1 hive-3.1.2]$ mysql -uroot -p123456 mysql> create database metastore; mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | metastore | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.01 sec) mysql> quit; |
最后重新初始化Hive的元数据库
| [tom@bigdata1 hive-3.1.2]$ schematool -initSchema -dbType mysql -verbose |
再次启动Hive进行连接测试
| [tom@bigdata1 hive-3.1.2]$ bin/hive hive> show databases; hive> show tables; hive> create table test(id int); hive> show tables; OK test Time taken: 0.073 seconds, Fetched: 1 row(s) hive> insert into test values(1); hive> select id from test; OK 1 Time taken: 0.377 seconds, Fetched: 1 row(s) hive> quit; |
最后关闭Hadoop集群,做关机快照!!!
使用加入的superset.sh文件快速启动和关闭superset。
脚本记得放在 /home/tom/bin 目录下,赋予脚本执行权限
[tom@bigdata1 bin]$ chmod u+x superset.sh
然后测试能否通过脚本启动和停止superset(通过浏览器去测试!)
[tom@bigdata1 bin]$ superset.sh status
superset is not run.
[tom@bigdata1 bin]$ superset.sh start
start superset...
[tom@bigdata1 bin]$ superset.sh status
superset is running.
[tom@bigdata1 bin]$ superset.sh stop
stop superset...
[tom@bigdata1 bin]$ superset.sh status
superset is not run.


此处使用我上传的ads_order_by_province文件
使用conda安装MySQL客户端
[tom@bigdata1 bin]$ conda activate superset
(superset) [tom@bigdata1 bin]$ conda install mysqlclient
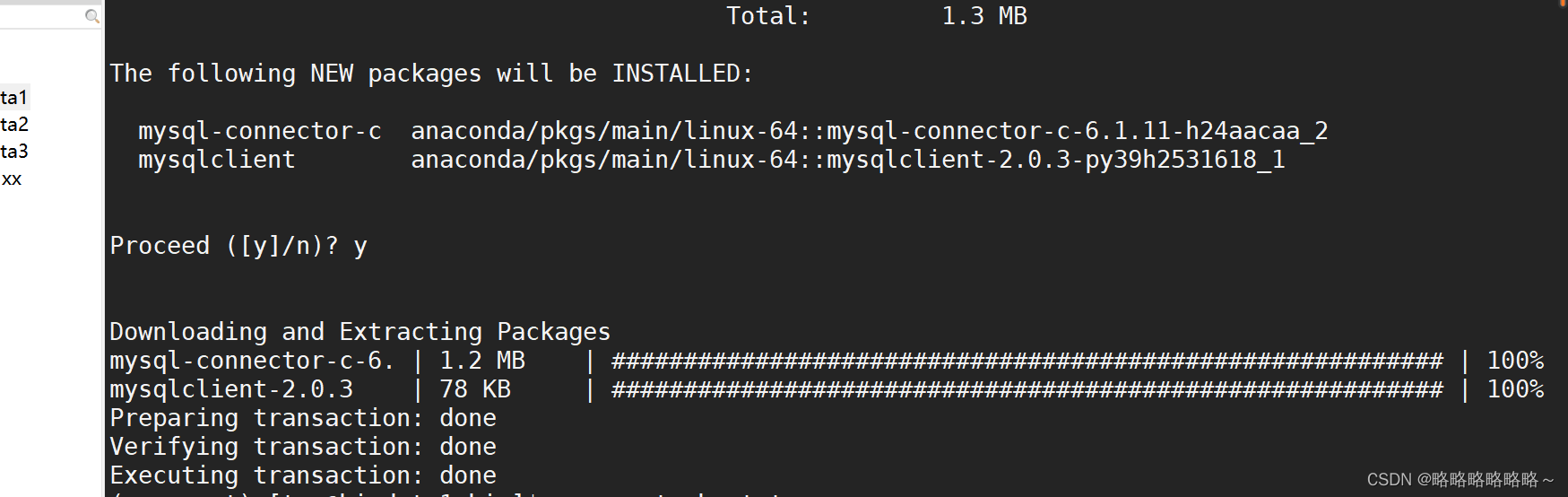
安装成功后重启superset框架
(superset) [tom@bigdata1 bin]$ superset.sh status
superset is running.
(superset) [tom@bigdata1 bin]$ superset.sh restart
restart superset...
(superset) [tom@bigdata1 bin]$ superset.sh status
superset is running.
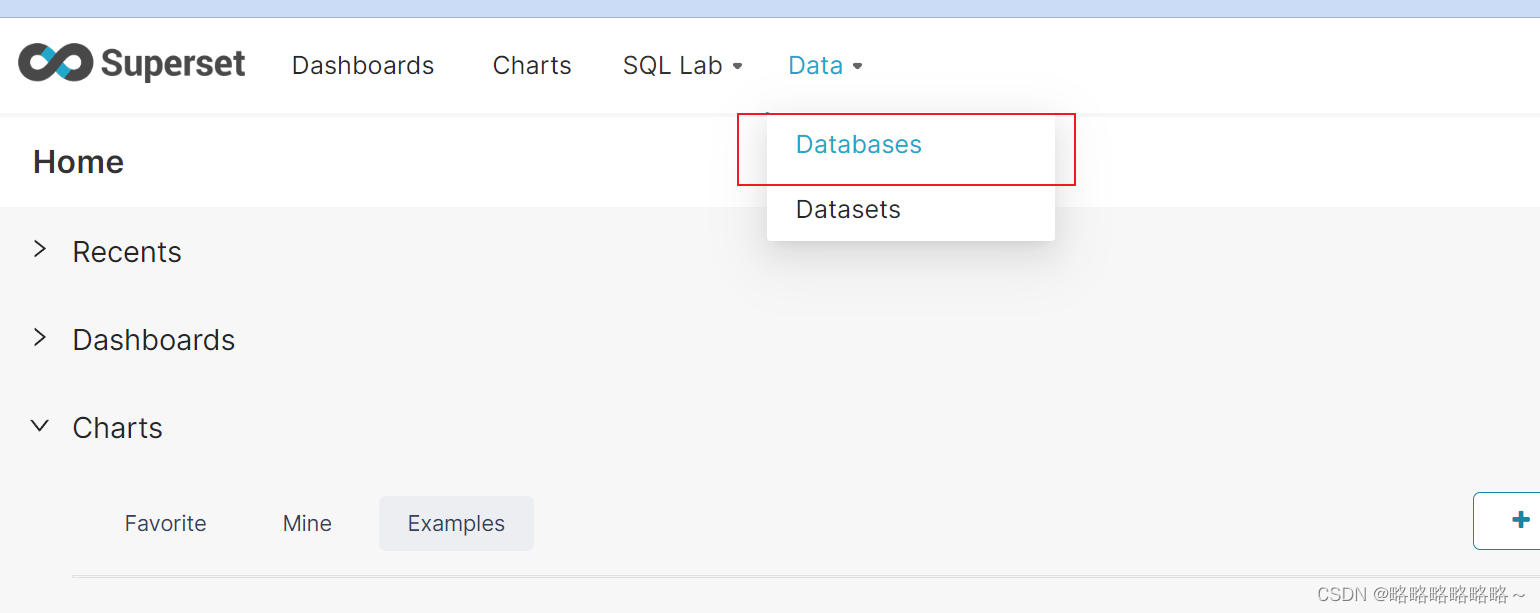
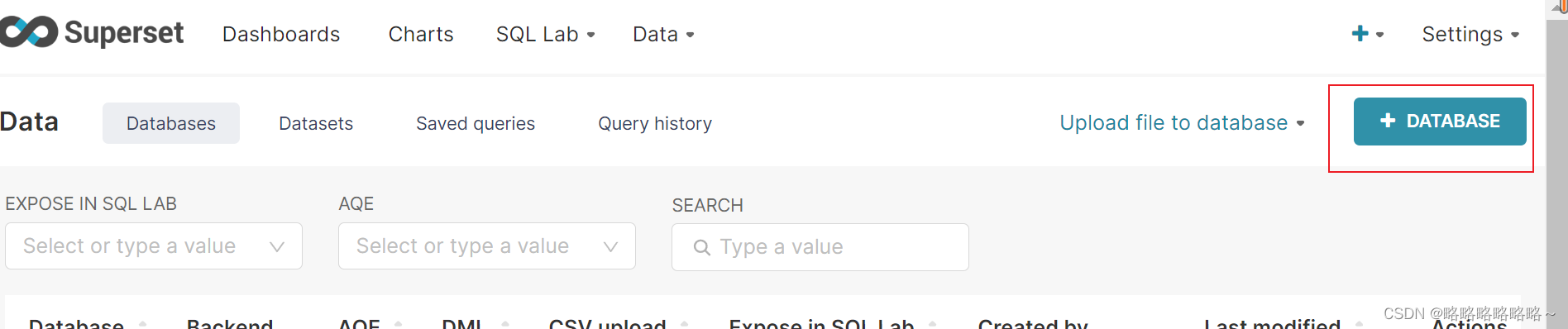
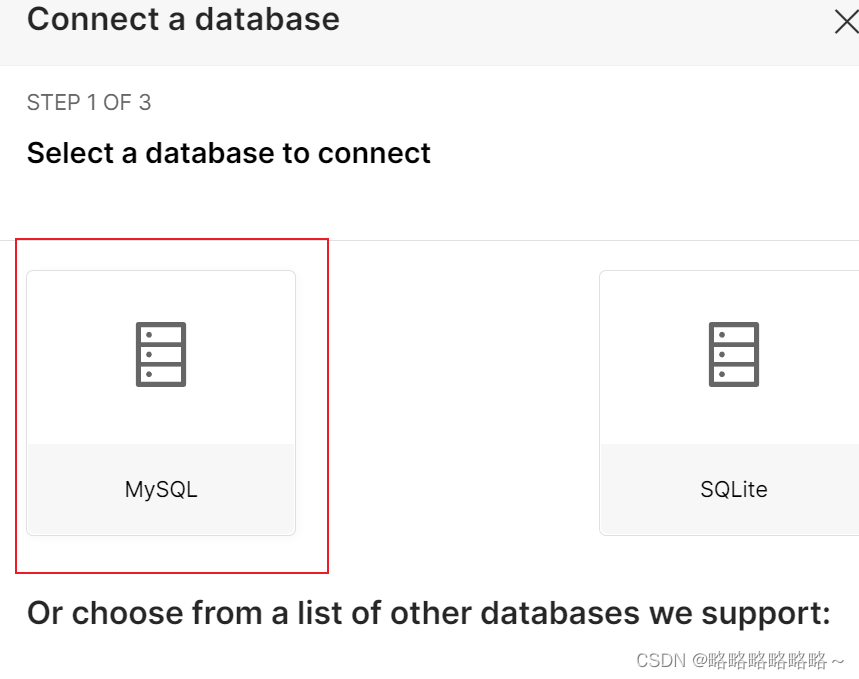
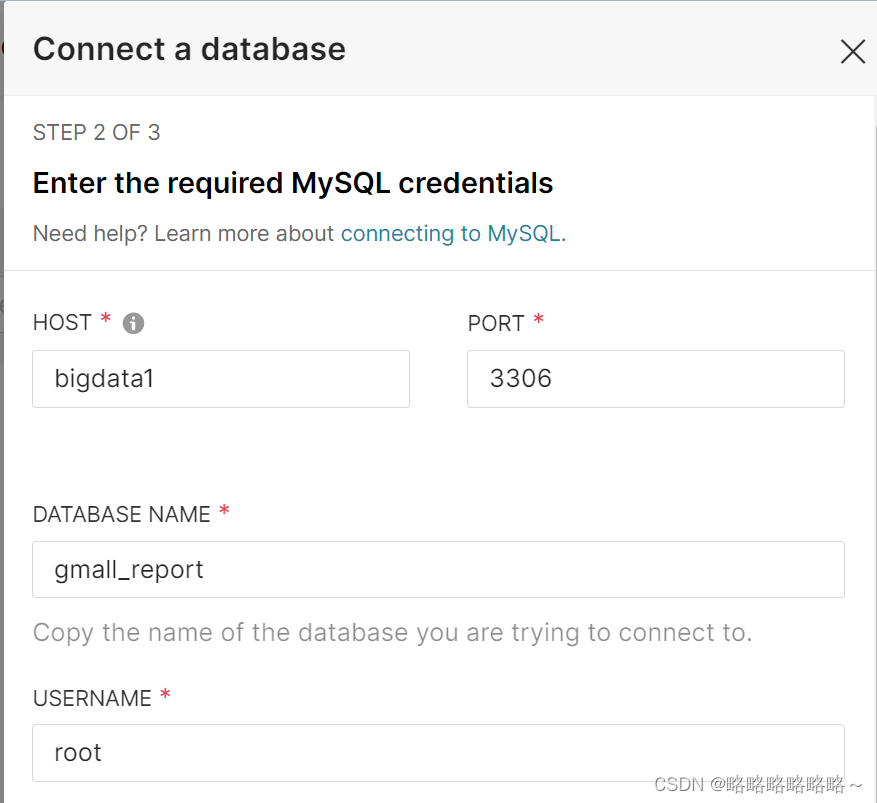

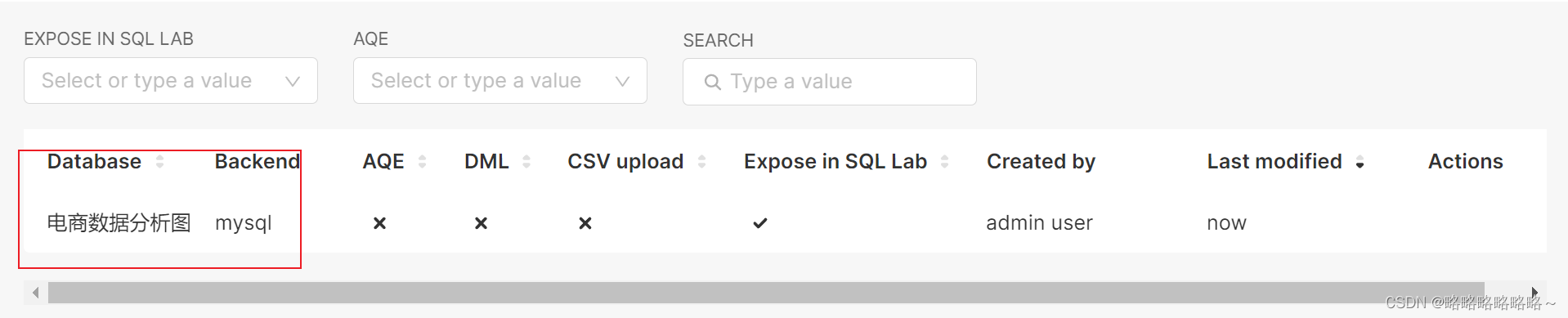
以上是superset数据库的创建流程
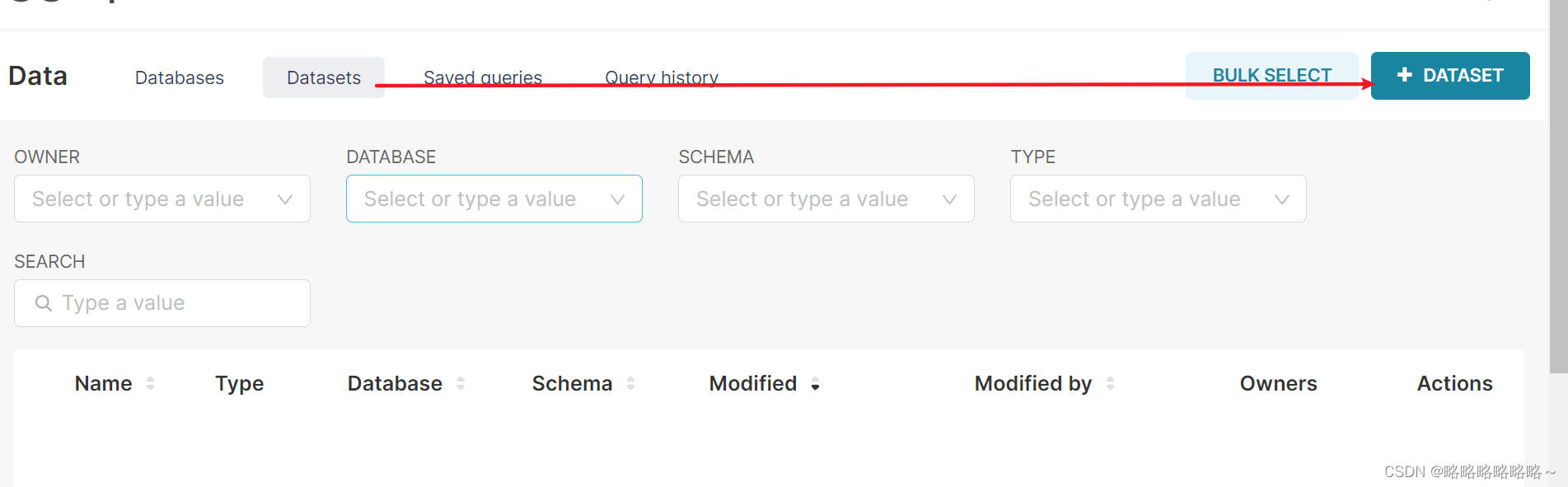
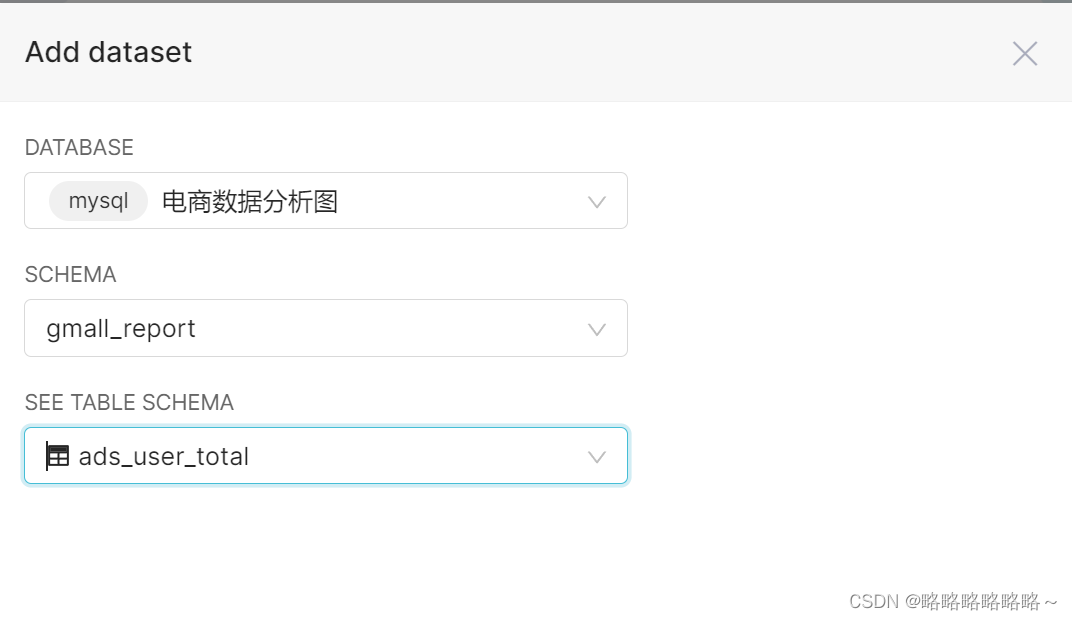
以下是数据表的创建流程



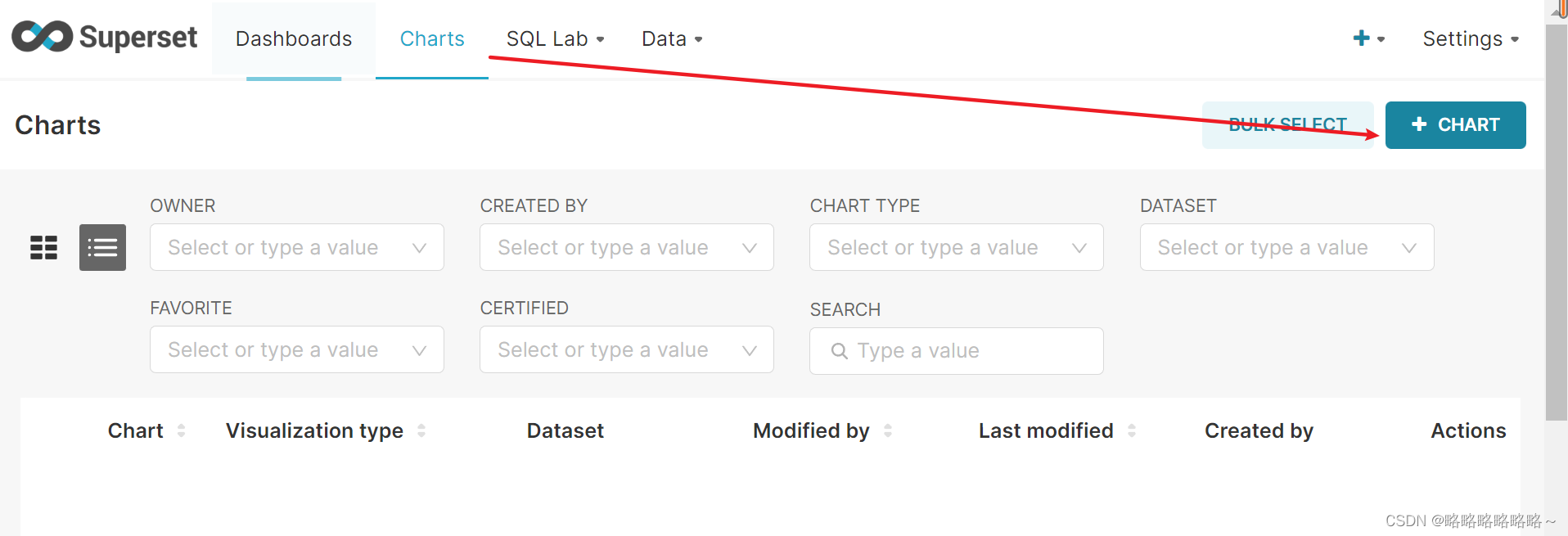

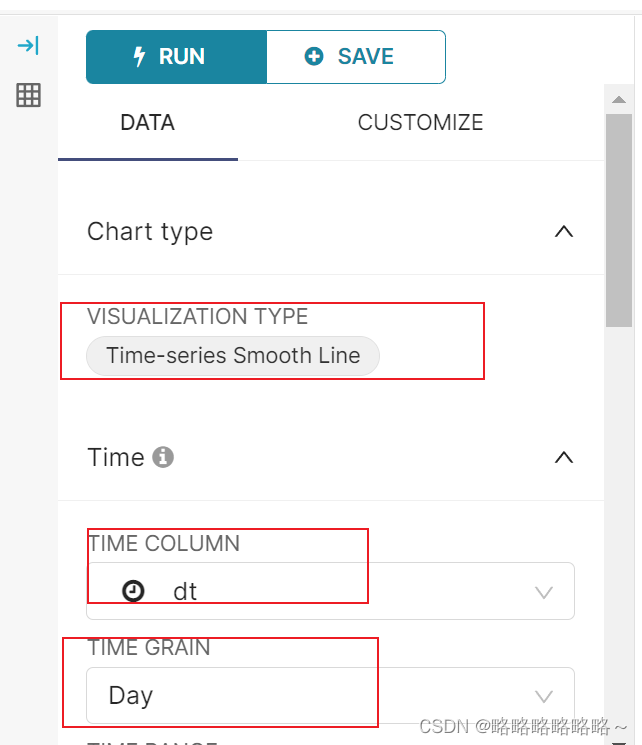
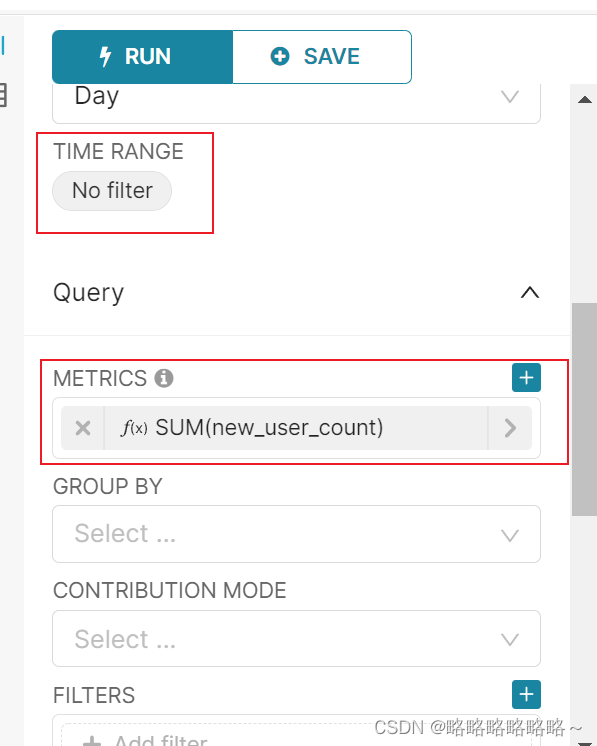
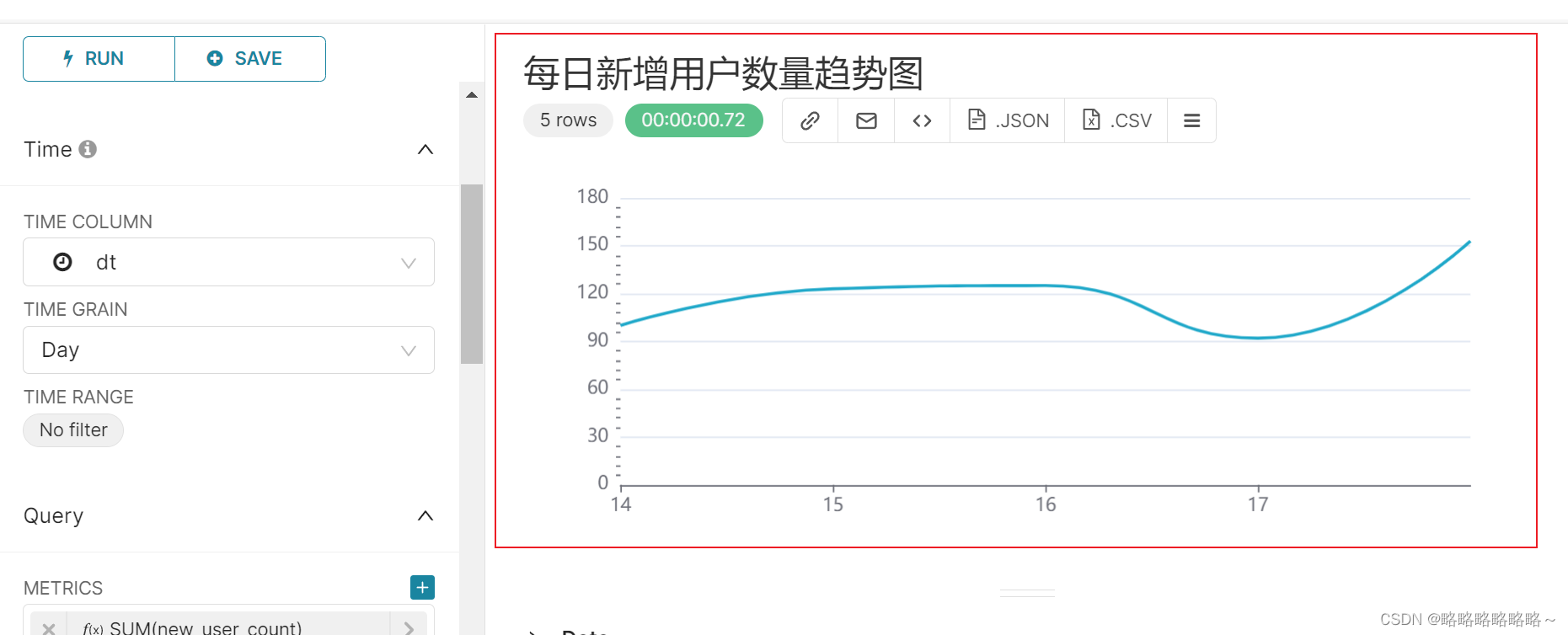
最后的组件展示图

新建地图组件chart


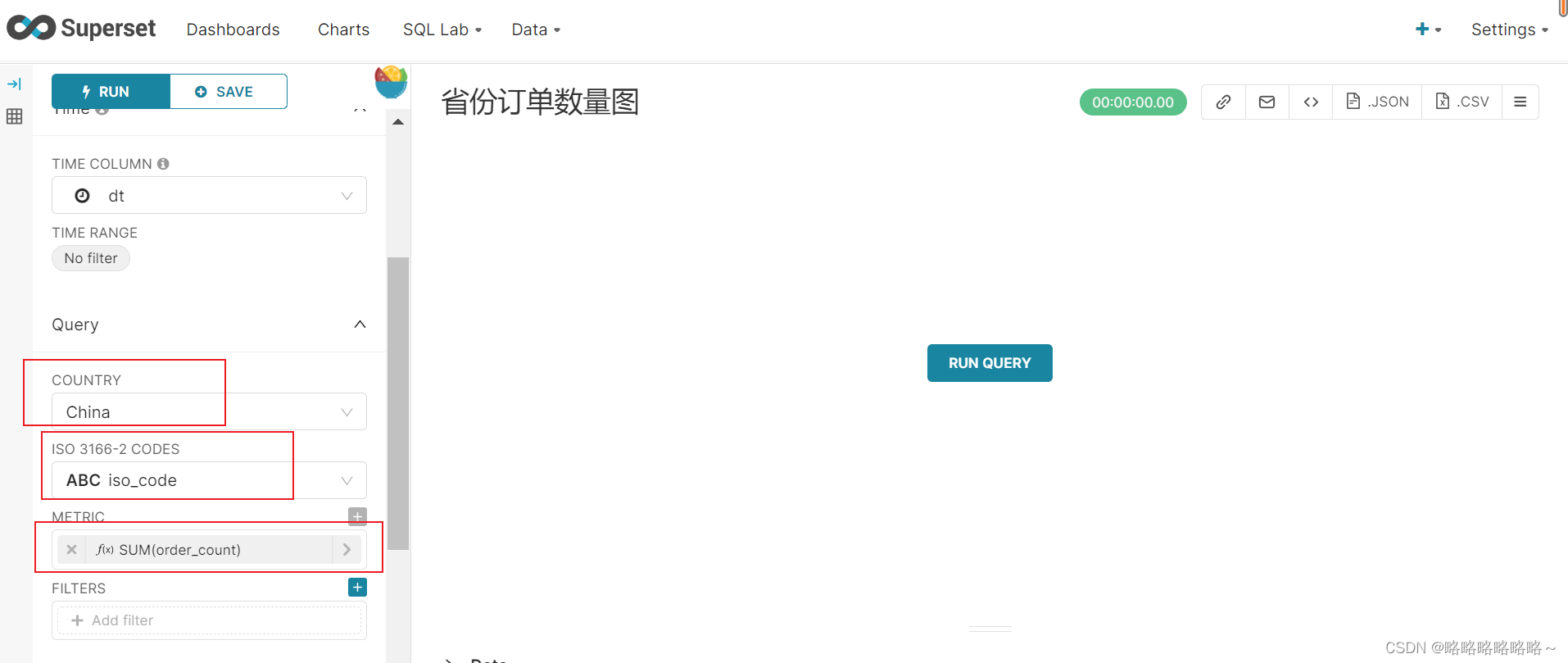

配置dashboard面板

模拟二行二列的排列规则

设置dashboard自动刷新数据
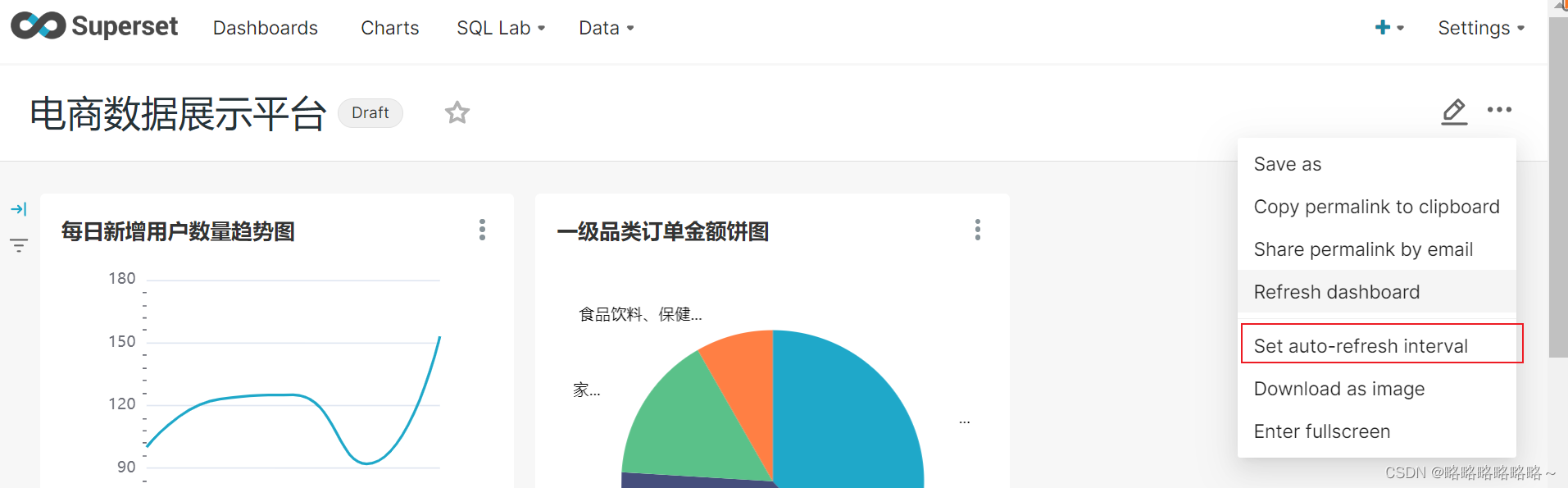
superset连接Hive步骤如下
1. 首先来到Hive配置文件目录
[tom@bigdata1 ~]$ cd /opt/module/hive-3.1.2/conf
[tom@bigdata1 hive-3.1.2]$ pwd
/opt/module/hive-3.1.2/conf
2. 然后修改Hive配置文件 hive-site.xml(使用我上传修改好的直接替换)
3. 然后在指定目录下修改Hadoop的配置文件 core-site(使用我上传修改好的直接替换)
[tom@bigdata1 hadoop]$ pwd
/opt/module/hadoop-3.1.3/etc/hadoop
4. 然后进行superset环境,执行以下命令
(superset) [tom@bigdata1 conf]$ pip install sasl
(superset) [tom@bigdata1 conf]$ pip install thrift
(superset) [tom@bigdata1 conf]$ pip install thrift-sasl
(superset) [tom@bigdata1 conf]$ pip install PyHive
(superset) [tom@bigdata1 conf]$ sudo yum install cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapi
5. 然后重启superset
(superset) [tom@bigdata1 conf]$ superset.sh restart
6. 启动Hadoop
myhadoop start
7. 启动Hive的server2服务
[tom@bigdata1 hive-3.1.2]$ bin/hive --service hiveserver2
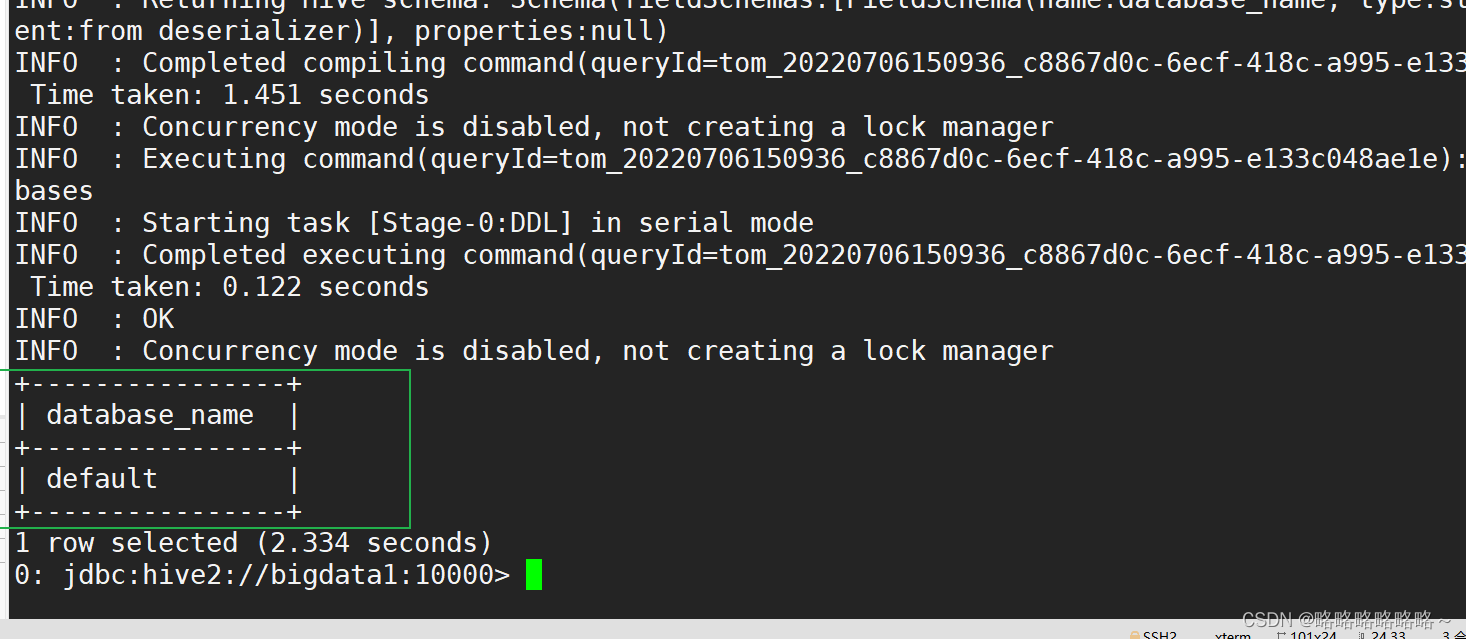
8. 使用beeline连接hive 并测试
[tom@bigdata1 hive-3.1.2]$ bin/beeline -u jdbc:hive2://bigdata1:10000 -n tom

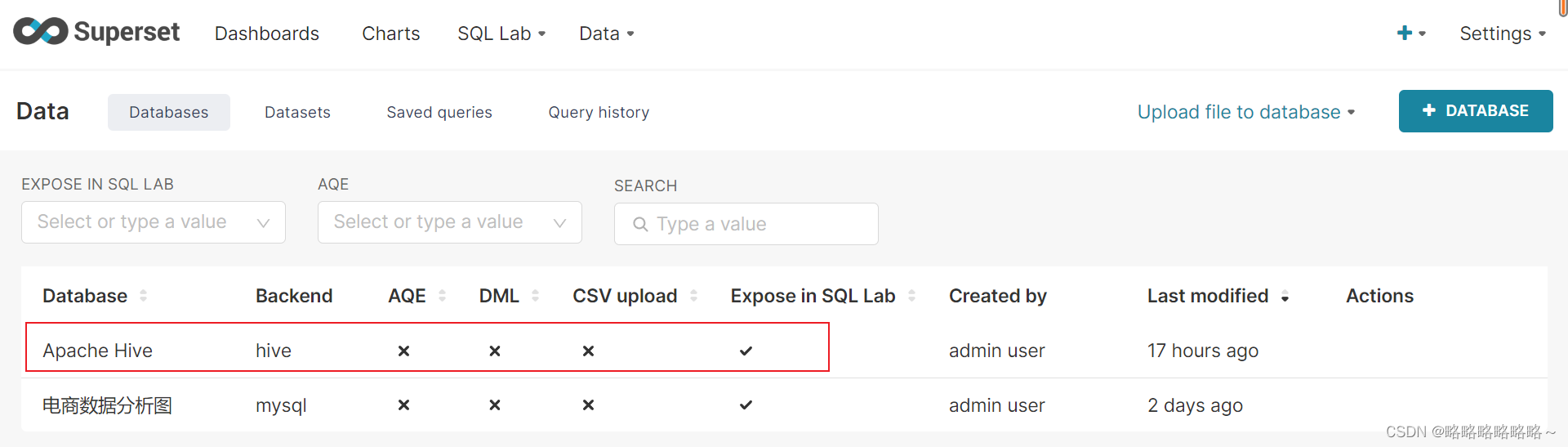
对于图像出不来的情况,看如下
Superset连接卡住

Bigdata123里的core-site.xml全部更改
Superset网页超时报错解决方法



Superset绘制又双报错

修改Yarn-site.xml文件

运行即可