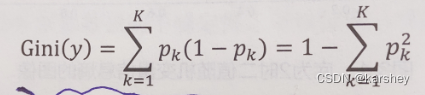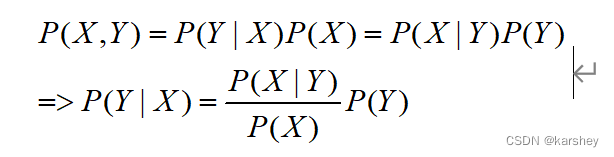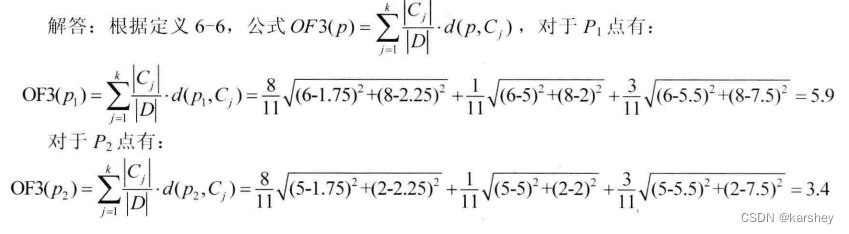数据挖掘的定义 :从大量的、不完全的、有噪声的、模糊的、随机的 实际应用数据中,提取隐含在其中、人们事先不知道的、但又潜在有用的 信息的过程。
商业层面:数据挖掘是一种新的商业信息处理技术,其主要特点是对商业业务数据进行抽取、转换、分析和其他模型化处理 ,从中提取辅助商业决策的关键性数据。
记法:
区分分类和聚类 :
以图搜图——聚类
人脸识别、垃圾邮件检测、扑克牌按花色分组——分类
余弦相似度 :两个向量相乘,再除以它们的模。相关系数 :标准化后的余弦相似度。相关系数越接近1或-1,则两特征相关性越强,越接近0,相关性越弱。
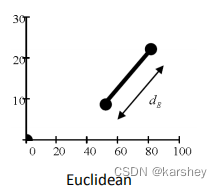
欧几里得距离 :
d
=
(
p
1
x
−
p
2
x
)
2
+
(
p
1
y
−
p
2
y
)
2
d=\sqrt{(p1_x-p2_x)^2+(p1_y-p2_y)^2}
d = ( p 1 x − p 2 x ) 2 + ( p 1 y − p 2 y ) 2
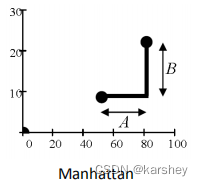
曼哈顿距离 :
d
=
∣
(
p
1
x
−
p
2
x
)
∣
+
∣
(
p
1
y
−
p
2
y
)
∣
d=|(p1_x-p2_x)|+|(p1_y-p2_y)|
d = ∣ ( p 1 x − p 2 x ) ∣ + ∣ ( p 1 y − p 2 y ) ∣ 截断均值:
指定0~100间的百分位数p,丢弃高端和低端(p/2 )%的数据,然后用常规方法计算均值,所得结果即是截断均值。标准均值是对应于p=0%的截断均值。
例题:计算{1,2,3,4,5,90}值集的p=40%的截断均值。
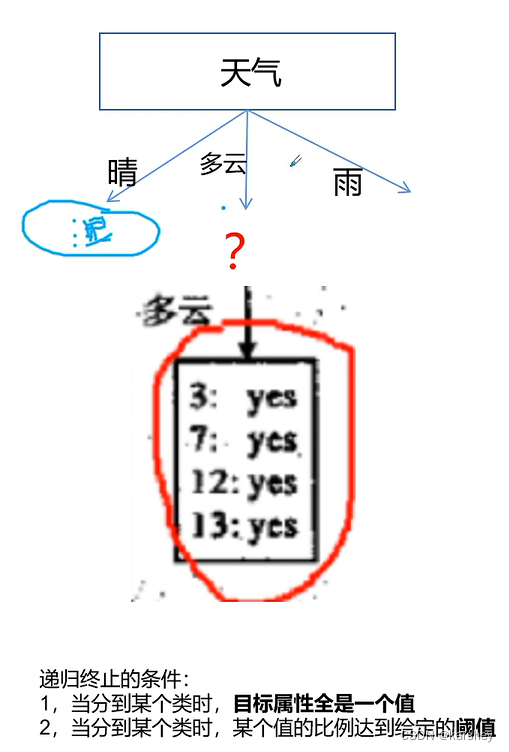
递归终止的条件:
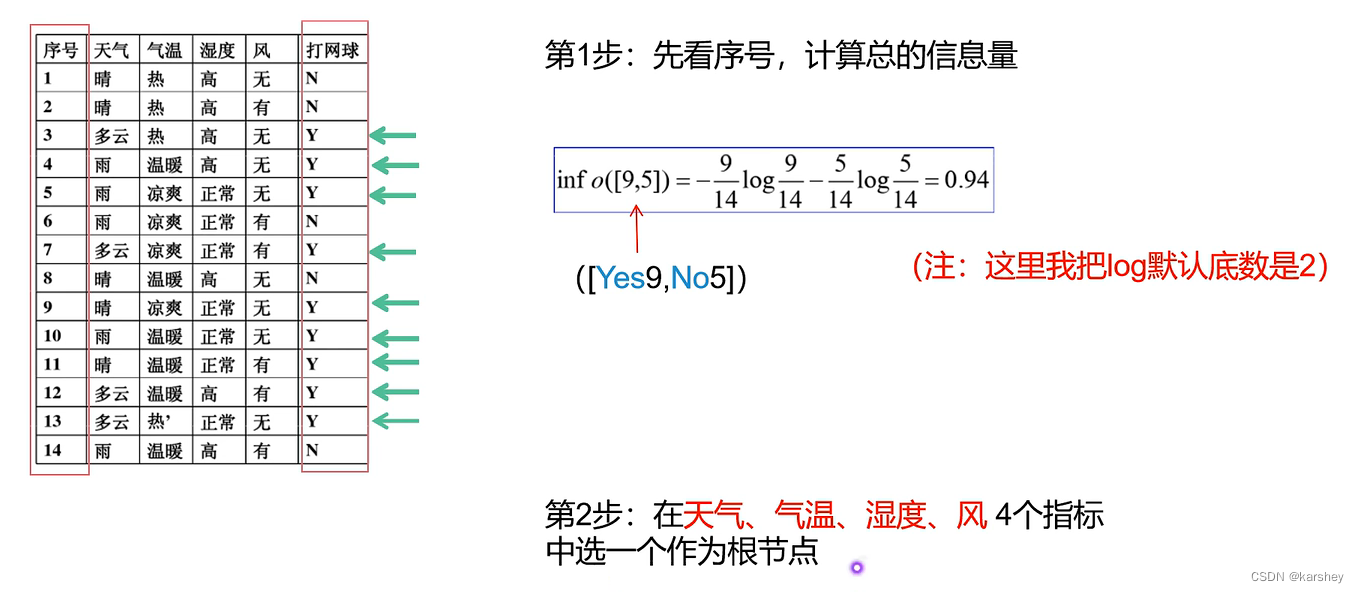
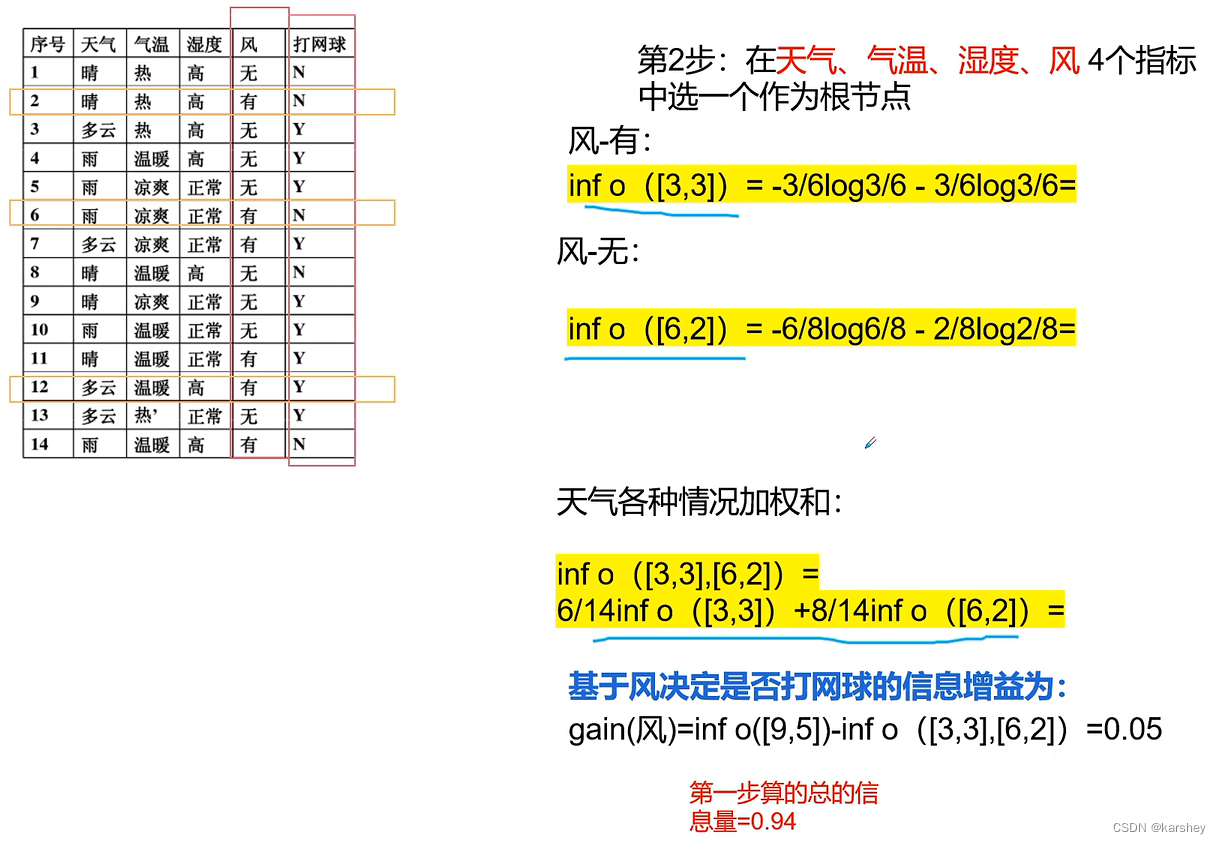
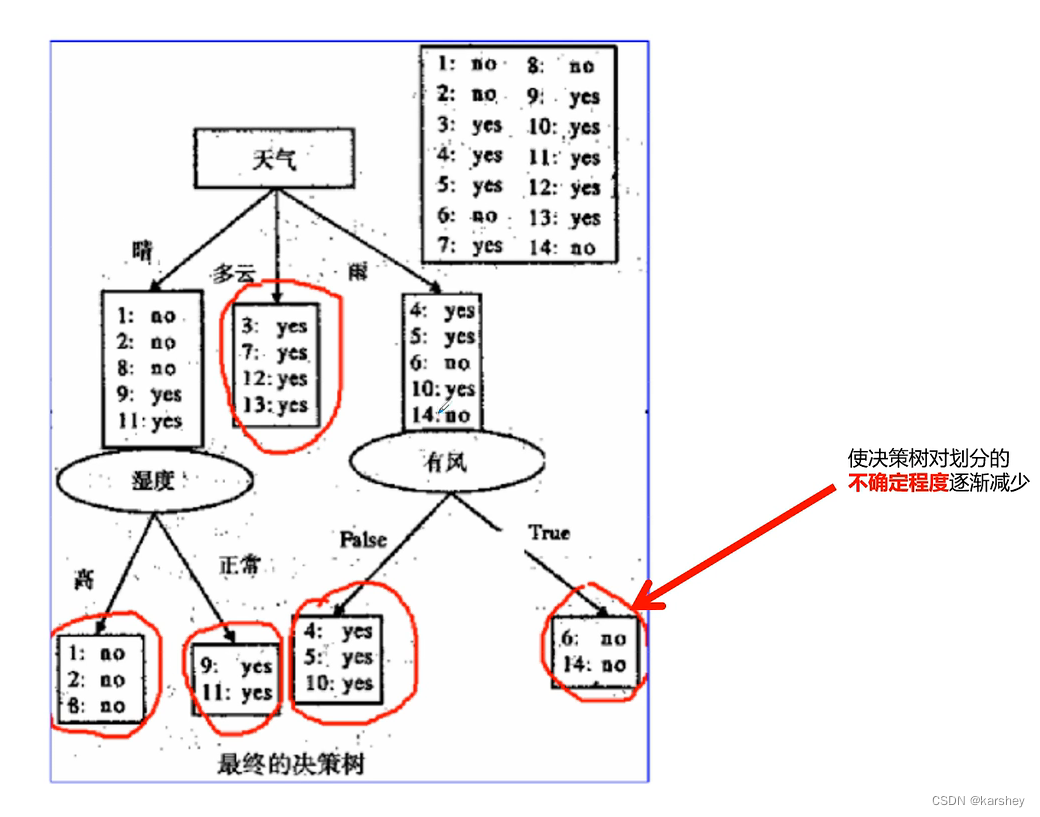
第一步:计算总的信息量(标签) 第二步:选一个做根节点。
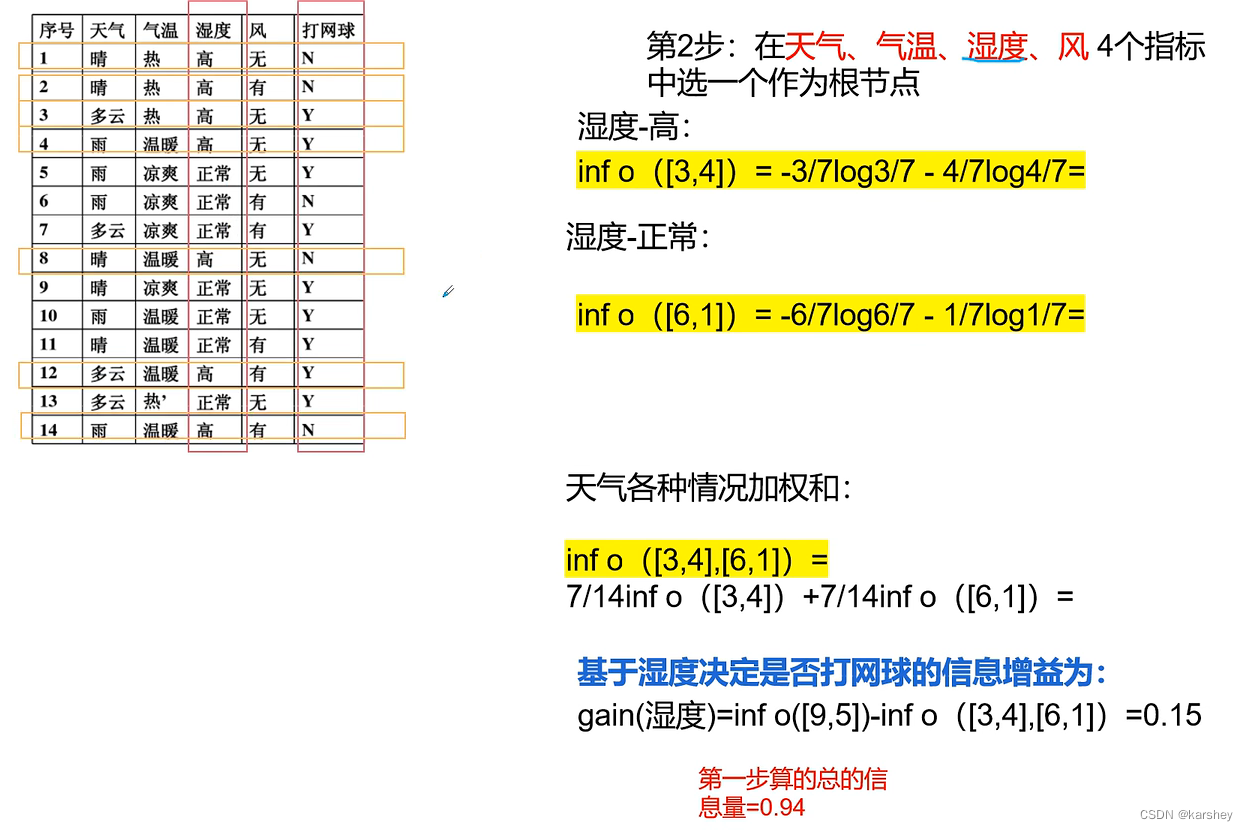
若选天气做根节点:选择信息增益gain最大的作为根节点。 天气 作为根节点。
第三步:
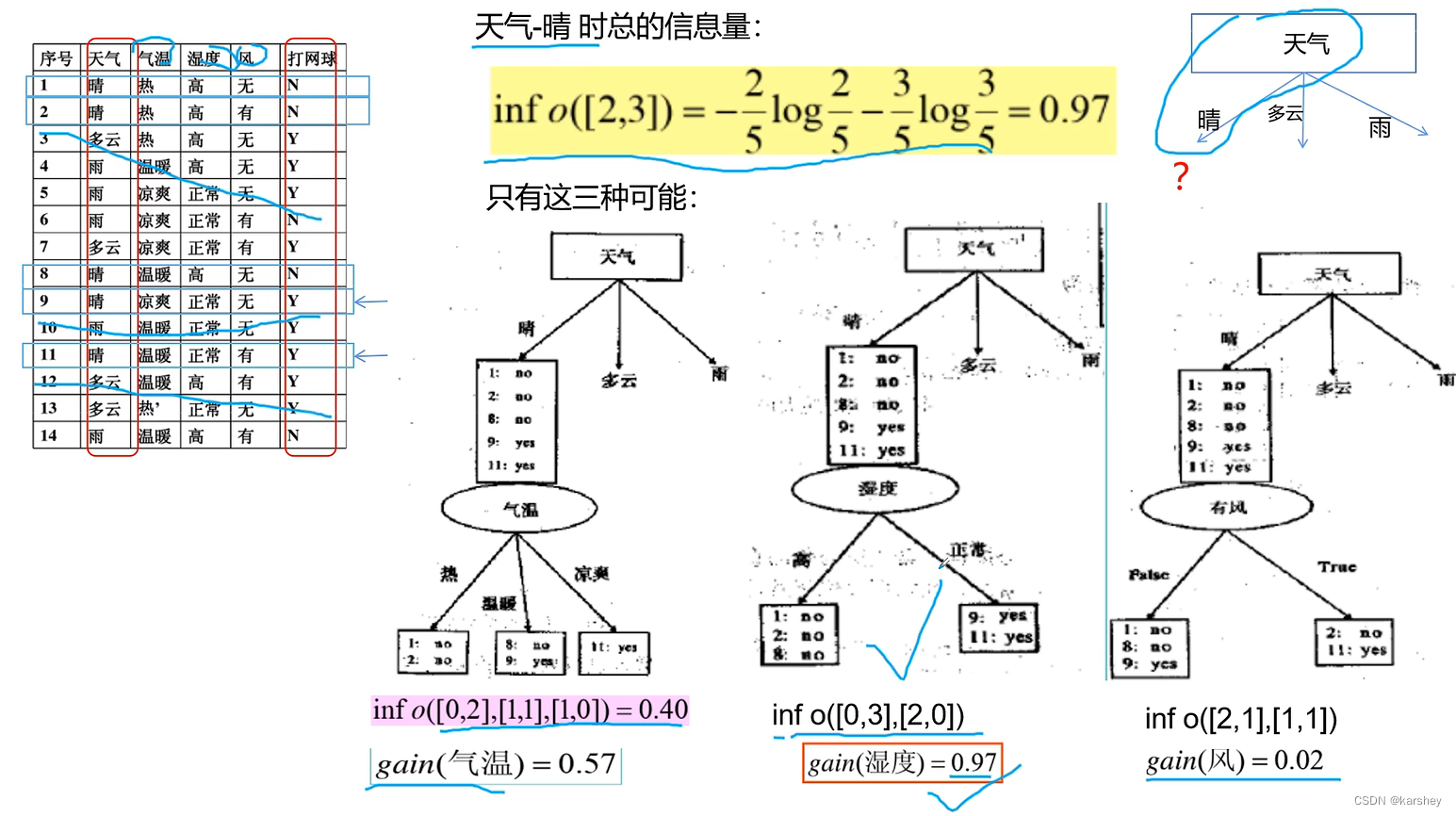
计算天气为晴的时候的信息增益。
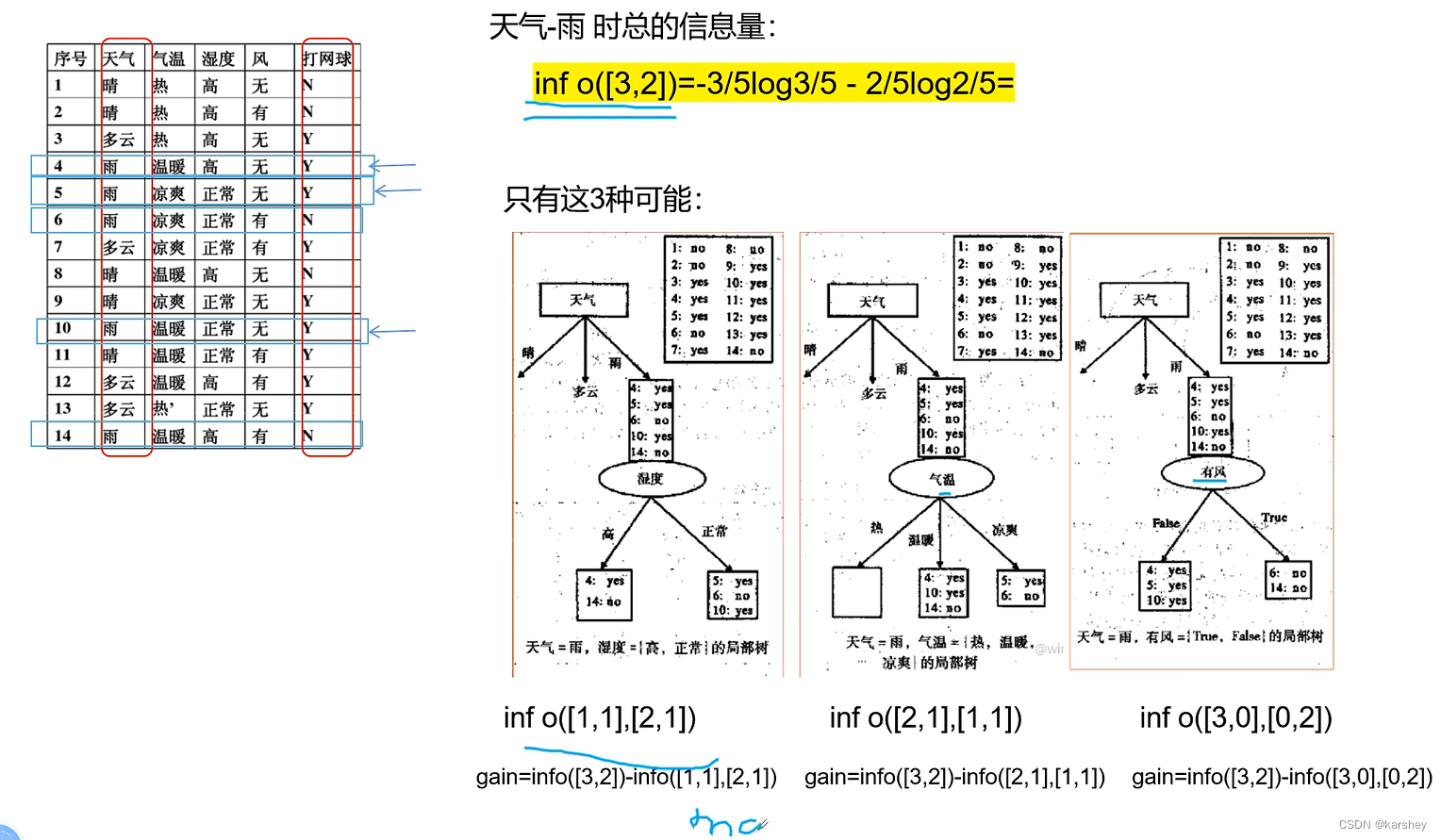
第四步:算天气为多云时的信息增益。
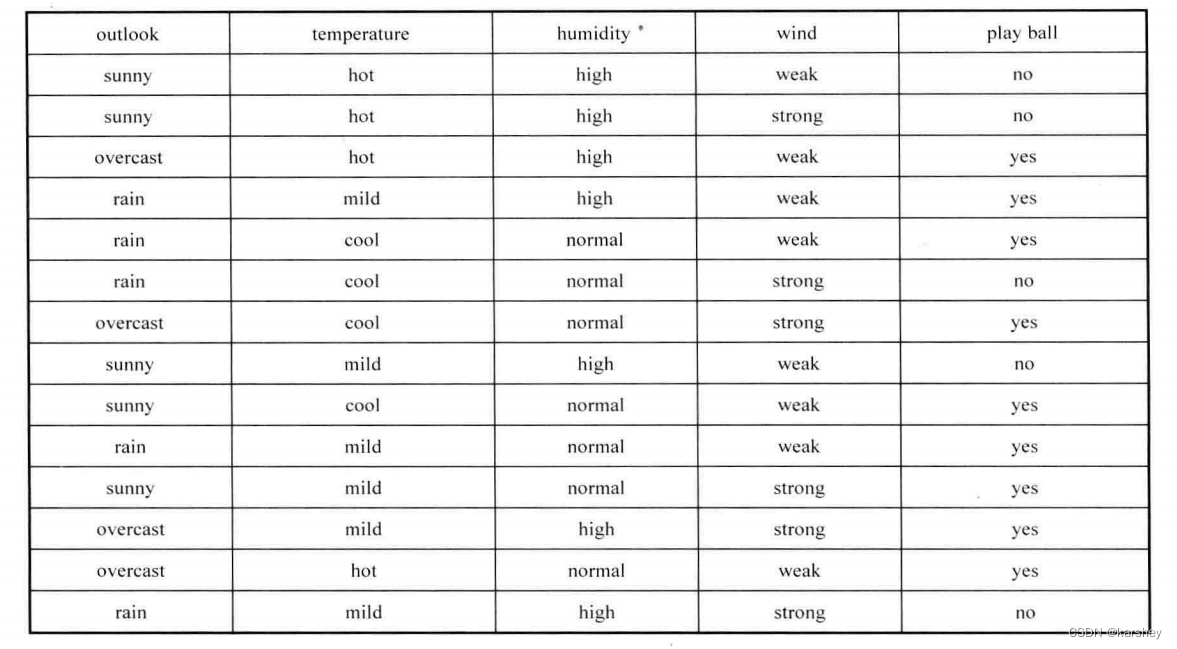
一个练习:Entropy(信息熵) ;Gain(S,wind) ;(字太丑了,将就看一下吧) :
信息增益率=信息增益/分裂信息。
代价 ”。
关于信息增益率怎么算:
CART算法使用Gini系数 来度量对某个属性变量测试输出的两组取值的差异性 。理想的分组应该尽量使两组中样本输出变量取值的差异性总和达到最小,即“纯度”最大,也就是使两组输出变量取值的差异性下降最快,“纯度”增加最快。
例1:
label1= 5 ,
label2= 5 ;
则:
p ( 1 ) = 0.5 ;
p ( 2 ) = 0.5 ;
Gini= 1 - p ( 1 ) * p ( 1 ) - p ( 2 ) * p ( 2 ) = 0.5 ;
例2:
label1= 8 ,
label2= 2 ;
则:
p ( 1 ) = 0.8 ;
p ( 2 ) = 0.2 ;
Gini= 1 - p ( 1 ) * p ( 1 ) - p ( 2 ) * p ( 2 ) = 0.32 ;
例3:
label1= 0 ,
label2= 1 ;
则:
p ( 1 ) = 0 ;
p ( 2 ) = 1 ;
Gini= 1 - p ( 1 ) * p ( 1 ) - p ( 2 ) * p ( 2 ) = 0 ;
由上面3个例子可知,当Gini系数是0.5时,说明这个属性的分类处于一个非常混乱的状态,当Gini系数为0时,说明这个属性分类分的纯度很高。
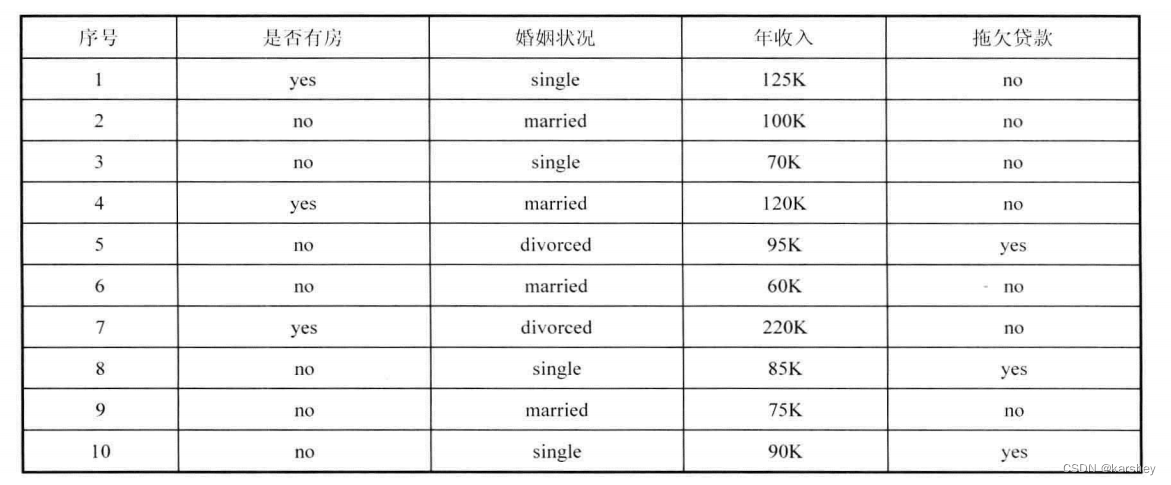
基尼加权 的计算:
对于有房的,有3个人不拖欠,0个人拖欠。则Gini=1-1=0
因此,加权基尼系数为:3/10 x 0+7/10 x 24/49 =12/35
关于基尼系数增益,看这里:决策树:什么是基尼系数(“杂质 增益 指数 系数”辨析)
分类准确率
计算复杂性
可解释性
可伸缩性
稳定性
强壮性
假设样本特征彼此独立,没有相关关系。而这在现实中不存在。
怎么用它分类——看这个,瞬间会了:【决策树算法4】朴素贝叶斯算法 数据挖掘 期末考试 计算题 详细步骤讲解
书p112
快速理解:
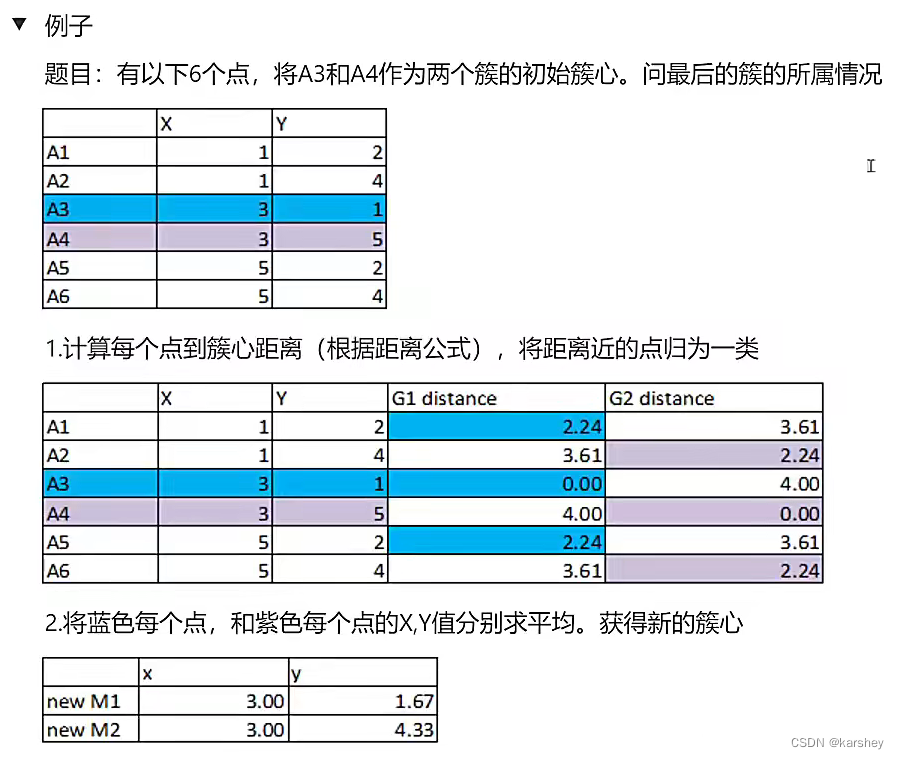
从数据中选择k个对象作为初始聚类中心;
计算每个聚类对象到聚类中心的距离来划分;
再次计算每个聚类中心
计算标准测度函数,之道达到最大迭代次数,则停止,否则,继续操作。
例子:
k-means算法的优缺点 :描述容易、实现简单、快速 。簇的个数 k难以确定 ;对初始簇中心 的选择较敏感 ;对噪音和异常数据敏感 ;不能 用于发现非凸形状 的簇,或具有各种不同大小 的簇。
书p127-130
一个非常直观的DBSCAN算法演示:DBSCAN聚类 动画演示
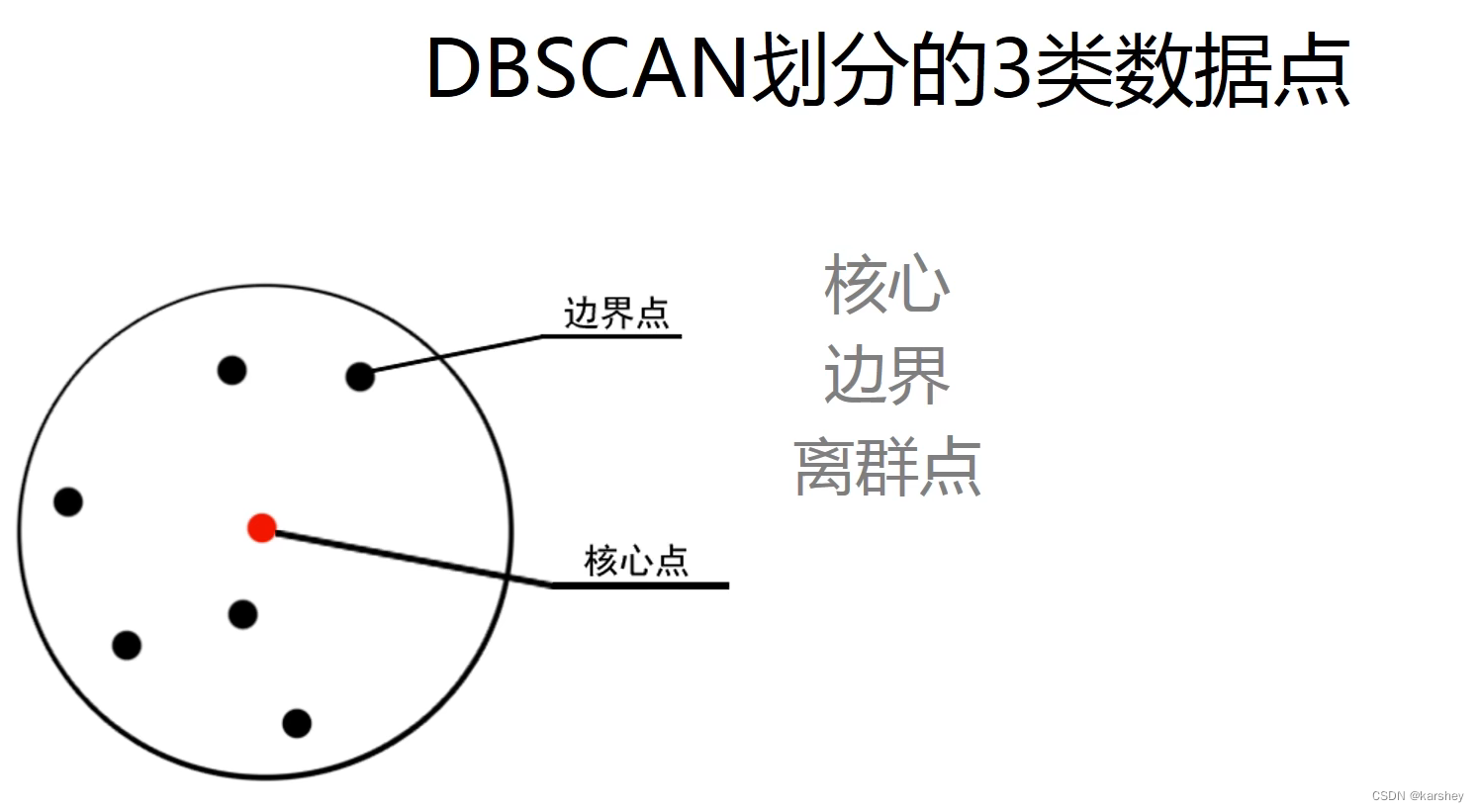
相关概念:
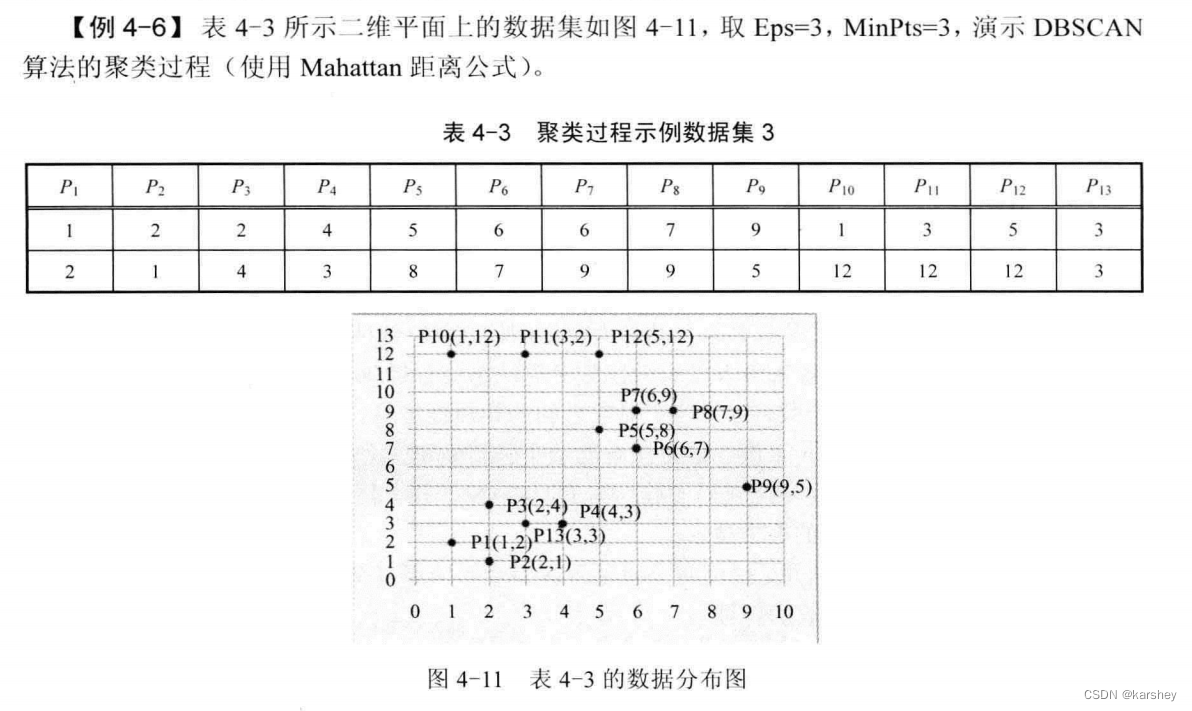
例题:
解:
DBSCAN算法的优点:**可以识别具有任意形状和不同大小的簇,自动确定簇的数目,分离簇和环境噪声,一次扫描数据即可完成聚类。**如果使用空间索引,DBSCAN 的计算复杂度是O(N log N),否则计算复杂度是O(N2 )。
书p138-140.省流:
不省流:近似线性时间复杂度 ,类似于 k-means算法,其本质上是将数据划分为大小几乎相同的超球体,不能用于发现非凸形状的簇,或具有各种不同大小的簇。
对于具有任意形状簇的数据集,算法可能将一个大的自然簇划分成几个小的簇,而难以得到理想的聚类结果。与k-means 算法不同,一趟聚类算法对数据样本的顺序比较敏感 ,通过聚类阈值的改变来影响聚类得到的簇个数。大规模数据集的聚类可以采用类似 BIRCH算法的两阶段聚类思想,结合一趟聚类算法的高效性及其他可识别任意形状簇的聚类算法的优点得到混合聚类算法。如选取较小的阈值,利用一趟聚类算法产生初始聚类,将得到的簇作为整体看成对象,再利用DBSCAN、Chameleon、SNN 等可以识别任意形状数据的算法进行聚类,可以得到很好的效果。
书p121.
层次聚类方法可分为自顶向下和自下而上 两种。
自下而上 聚合层次聚类方法(或凝聚 层次聚类)。这种自下而上策略就是最初 将每个对象 (自身)作为一个簇 ,然后将这些簇进行聚合以构造越来越大的簇 ,直到所有对象均聚合为一个簇,或满足一定终止条件为止。绝大多数层次聚类方法属于这一类,只是簇间相似度的定义有所不同。
自顶向下 分解层次聚类方法(或分裂 层次聚类)。这种方法的策略与自下而上的凝聚层次聚类方法相反。它首先将所有对象置于同一个簇,然后将其不断分解 ,而得到规模越来越小但个数越来越多的小簇,直到所有对象均独自构成一个簇,或满足一定终止条件为止。
例题如下:
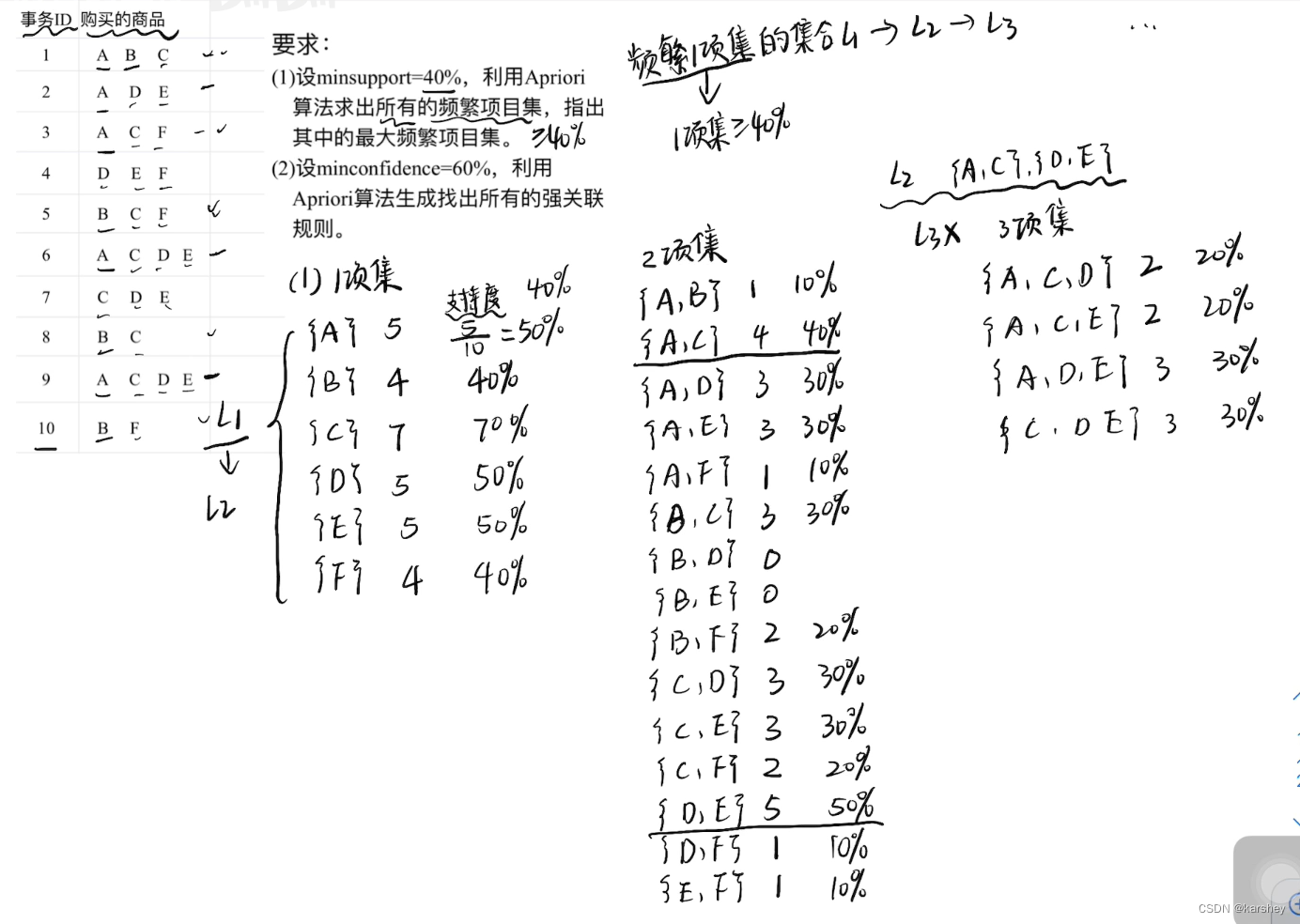
求最大频繁项目集
{B}{F}怎么来的:L1中的不能出现在L2中,L2中的不能出现在L3中的频繁项集也是最大频繁项目集。
注意:对于频繁2项集,如果第一项相同,则合并组合生成候选3项集。 所以这里{AC}{DE}是没法合并成候选3项集的。
找出所有的强关联规则
强关联规则:同时满足最小支持度和置信度。
置信度:P(A->C)即A发生的情况下C也发生,即P(AC)/P(A)。
Apriori算法利用以上性质,逐层生成关联规则。先产生后件只包含一项的关联规则,然后两两合并这些关联规则的后件,生成后件包含两项的候选关联规则,从这些候选关联规则中再找出强关联规则 ,以此类推。如果{a c d}→{(b}和{a b d}→{c}是两个高置信度的规则 ,则通过合并这两个规则的后件{b c} ,候选规则的前件 为{a b c d)-{b c}={a d} ,得到候选规则{a d}→{b c} 。
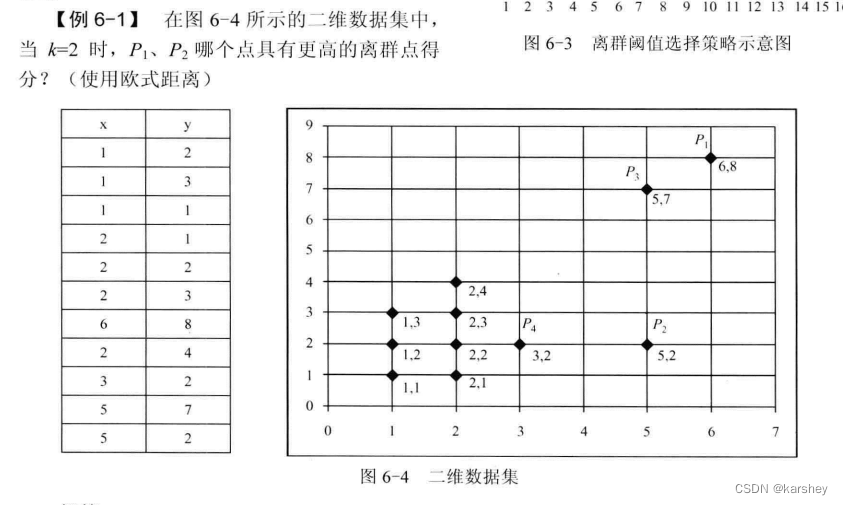
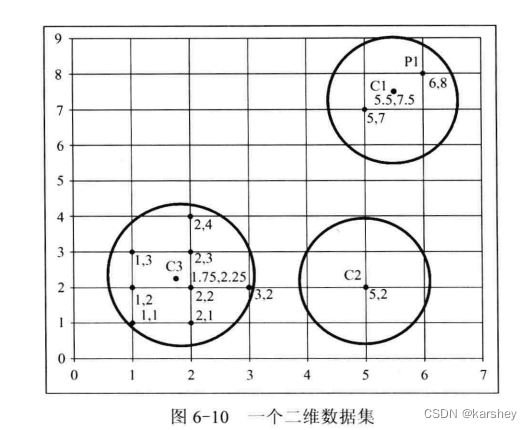
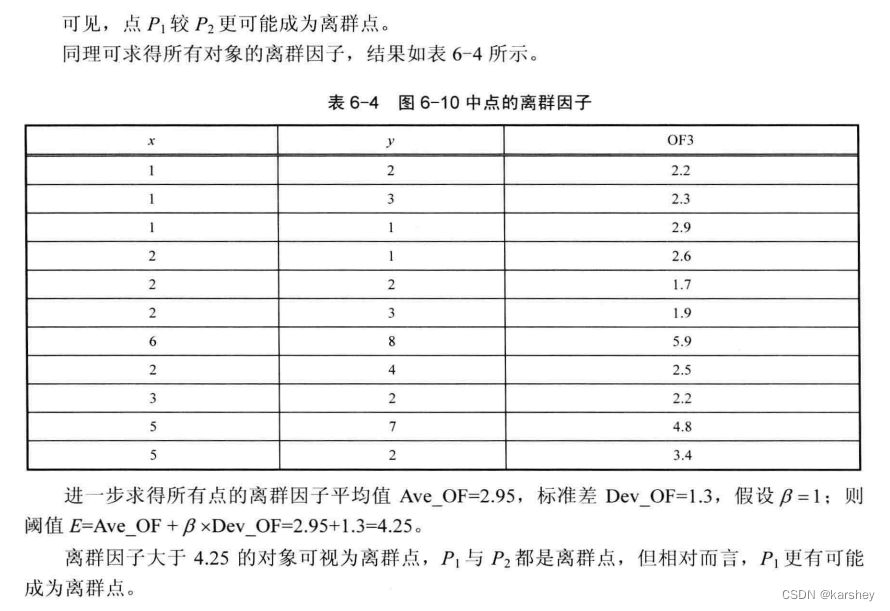
合理的异常点是允许存在的。超过k 。
OF1 大的是离群点 (毕竟大的更远)。
OF3 质心 。欧式距离 。加权 后的距离长度——如一共有N个点,这个簇有n个点,则这个簇的距离就是 P点到质心的欧式距离 x n/N (详情看解答,一看就懂)。OF3值大的是离群点 ,因为距离远。
解答:
后面这个了解一下:
评估分类模型准确率 的方法包括:保持、随即子抽样、交叉验证和自助法等。
关联规则 挖掘算法可分为两个步骤:
产生频繁项集:发现满足最小支持度阈值的所有项集、即频繁项集
产生规则:从上一步发现的频繁项集中提取大于置信度阈值的规则,即强规则。
聚类 算法:
K-means 算法的流程:
随机选择k个对象,每个对象代表一个簇的初始均值或中心
对剩余的每个对象,根据其与各簇中心的距离,将它指派到最近的簇,然后计算每个簇的新均值,得到更新后的簇中心
不断重复,直到准则函数收敛
《数据挖掘原理与实践》-电子工业出版社评定数据之间的相似度指标----距离 【决策树算法1】ID3算法 数据挖掘 期末考试 计算题 详细步骤讲解 【数据挖掘】决策树零基础入门教程,手把手教你学决策树! 机器学习:信息熵,基尼系数,条件熵,条件基尼系数,信息增益,信息增益比,基尼增益,决策树代码实现(一) Apriori算法原理 期末数据挖掘关联规则的apriori 算法计算大题 一个非常直观的DBSCAN算法演示:DBSCAN聚类 动画演示 【帅器学习/星辰】DBSCAN算法 【10分钟算法】K均值聚类算法-带例子/K-Means Clustering Algorithm 【期末划重点】数据挖掘 什么是KNN(K近邻算法)?【知多少】 【决策树算法4】朴素贝叶斯算法 数据挖掘 期末考试 计算题 详细步骤讲解