1 前言
此题来自攻防世界高手进阶区的一道逆向题目 crackme,通过对可执行程序进行脱壳,该壳为北斗的壳,涉及到ESP定律,大体流程是找到call处的ESp,在数据窗口中跟随,下个硬件访问断点,就到了OEP处,用ODdump脱壳就行了。脱壳完成之后使用IDA打开查看main函数里面的伪代码写脚本,最后得到flag,这里面涉及到三个常用逆向工具的使用,exeinfope,onllydbg ida;
2 工具介绍
OllyDug
OLLYDBG是一个新的动态追踪工具,将IDA与SoftICE结合起来的思想,Ring 3级调试器,非常容易上手,己代替SoftICE成为当今最为流行的调试解密工具了。同时还支持插件扩展功能,是目前最强大的调试工具。
Ollydbg基本功能快捷键:
F2:设置断点 说明:在一条指令上设置断点,再按一次就取消断点。
F4:执行到当前光标所在的指令 说明:在遇到循环时可以使用F4执行到循环结束后的指令。
F7:单步步入 说明:遇到函数调用就跟入。
F8:单步步过 说明:遇到函数调用不跟入。
F9:继续执行 说明:运行程序直到下一个断点处。
IDA
交互式反汇编器专业版(Interactive Disassembler Professional),人们常称其为IDA Pro,或简称为IDA,是总部位于比利时列日市(Liège)的Hex-Rayd公司的一款产品。
IDA基本功能快捷键:
Enter 跟进函数实现,查看标号对应的地址
Esc 返回跟进处
A 解释光标处的地址为一个字符串的首地址
B 十六进制数与二进制数转换
C 解释光标处的地址为一条指令
D 解释光标处的地址为数据
G 快速查找到对应地址
H 十六进制数与十进制数转换
PEID
PEID是一款著名的查壳工具,其功能强大,几乎可以侦测出所有的壳,其数量已超过470 种PE 文档的加壳类型和签名。
3 实验过程
3.1 实验分析
从网站下载出可执行程序之后,首先先按照流程用PEID打开观察程序是否加壳,如下图所示:

从图中显示的结果我们可以看到,该程序存在nsPack壳,程序是32位的,这个壳的名字叫做北斗压缩壳(nsPack),下面还提示用Quick unpack工具去壳,但是这道题使用的是ESP定律手工去壳,当然,直接使用万能的脱壳工具也可以实现,但这并不是目的;
3.2 实验原理
ESP定律的原理就是“堆栈平衡”原理。
对于RETN我们可以这样来理解:
1.将当前的ESP中指向的地址出栈;
2.JMP到这个地址。
这个就完成了一次调用子程序的过程。在这里关键的地方是:如果我们要返回父程序,则当我们在堆栈中进行堆栈的操作的时候,一定要保证在RETN这条指令之前,ESP指向的是我们压入栈中的地址。这也就是著名的“堆栈平衡”原理!
所以我们可以把壳假设为一个子程序,当壳把代码解压前和解压后,他必须要做的是遵循堆栈平衡的原理。ESP定律一般理解可以为:
1、在命令行下断hr esp-4(此时的ESP就是OD载入后当前显示的值)
2、hr ESP(关键标志下一行代码所指示的ESP值(单步通过))
ESP定律的适用范围:几乎全部的压缩壳,部分加密壳。只要是在JMP到OEP后,ESP=0012FFC4的壳,理论上我们都可以使用。但是在何时下断点避开校验,何时下断OD才能断下来,这还需要多多总结和多多积累。
内存断点寻找OEP的原理:首先,在OD中内存断点和普通断点(F2下断)是有本质区别的。内存断点等效于命令bpm,他的中断要用到DR0-DR7的调试寄存器,也就是说OD通过这些DR0-DR7的调试寄存器来判断是否断下普通断点(F2下 断)等效于bpx,他是在所执行的代码的当前地址的一个字节修改为CC(int3)。当程序运行到int3的时候就会产生一个异常,而这个异常将交给OD 处理,把这个异常给EIP-1以后,就正好停在了需要的中断的地方(这个根据系统不同会不一样),同时OD在把上面的int3修改回原来的代码。内存断点分为:内存访问断点,内存写入断点。
3.3 操作流程
将程序拖到ollydbg中打开,如下图所示:

可以看到pushfd 和 pushad 是北斗壳的特征,前两个pushfd和pushad压入所有EFlags寄存器和通用寄存器。call执行后压入下一指令地址并跳转。
这三个指令执行后的ESP值分别0019FF74,0019FF70、0019FF50,0019FF4C,call指令是壳内代码,解压缩用的,短跳转到下一条的004061B2
两次F8执行到call语句后,然后就是在ESP处数据窗口跟踪,再在数据窗口中右键设置word级或Dword级的硬件访问断点,如图所示:
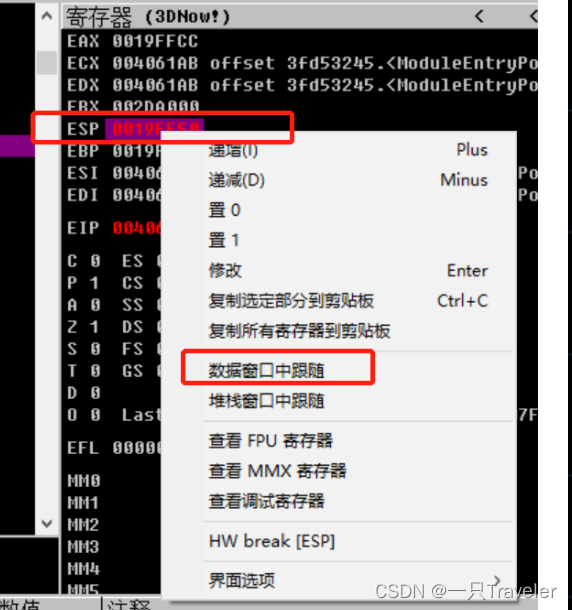
然后再点击AB所在位置设置硬件访问断点:
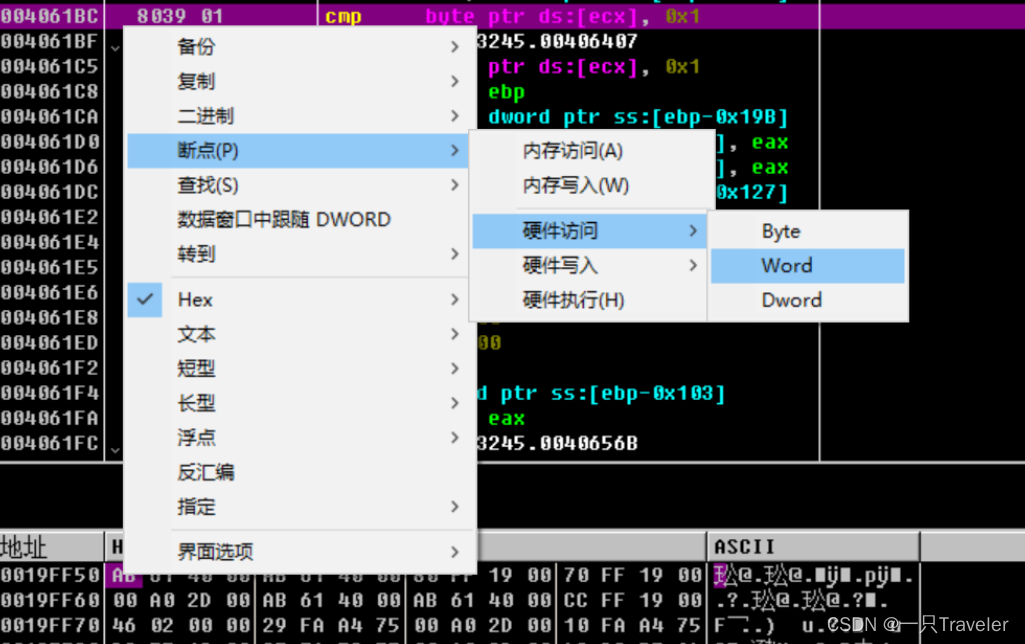
为什么设置断点是word级别:
除了为硬件断点指定一种模式外,还必须指定一个大小。执行类断点的大小必须为1字节,写入类或读取/写入类断点的大小可以设置为1、2或4字节。如果将大小设置为2字节,则断点的地址必须为字对齐(2字节的整数倍)。同样,4字节断点的地址必须为双字对齐(4字节的整数倍)。硬件断点的大小和它的地址共同构成了触发这类断点的地址范围。下面举例说明。以在地址0804C834h处设置的一个4字节写入式断点为例,这个断点将由1字节写入0804C837h、2字节写入0804C836h、4字节写入0804C832h等操作触发。
断点设置好之后,shift+F9运行程序,
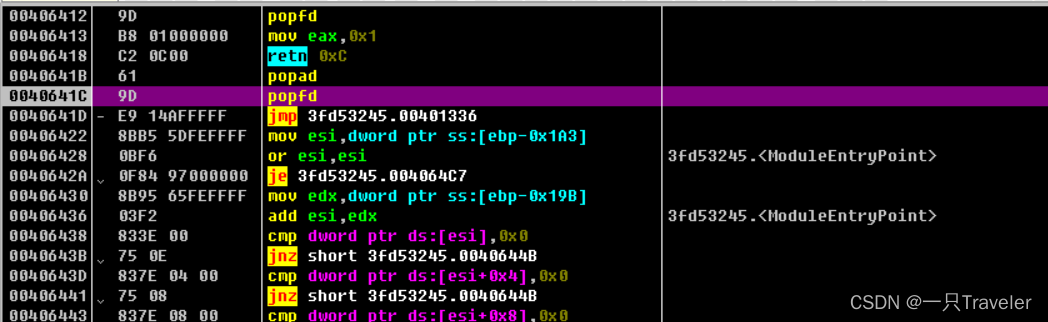
图中我们可以看到,程序暂停在了popfd处,框中的代码就是顶替了retn语句,这里标识壳函数调用完毕,要返回了,程序为什么会停止在popfd呢;因为我们硬件访问断点断的是0019ff50,而壳内解压缩代码最多涉及call压入的0019ff4c的栈所以能访问0019ff50的只有popad,当他执行后就访问截断,所以停在popfd这里
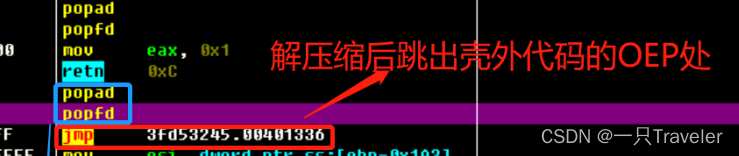
Popfd下面的jmp就是解压缩后跳出壳外代码的OEP处;
继续F8运行
jmp跳出壳后就是解压缩的代码了,右键分析当前代码把.text.段中数据重新反汇编成汇编代码

分析之后结果如下:
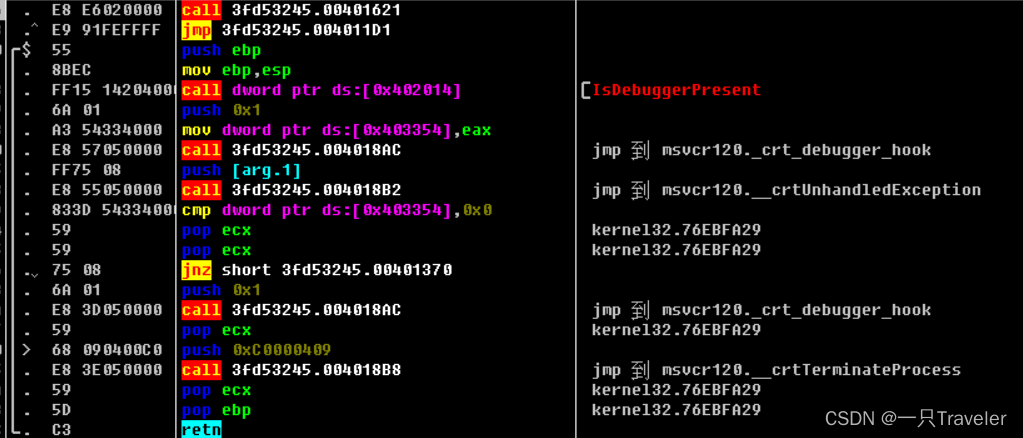
然后就是在这个位置处脱壳,用OD插件OllyDump来脱壳,生成新的可执行程序:

保存之后,至此手工脱壳完成
再将脱壳之后的程序拖到IDA中;F5查看main主函数里面的伪代码可以发现:
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v3; // ebp@0
char *v4; // ecx@1
char v5; // al@2
int result; // eax@4
signed int v7; // eax@5
int v8; // ecx@10
*(_BYTE *)(v3 - 56) = 0;
memset((void *)(v3 - 55), 0, 0x31u);
printf("Please Input Flag:");
gets_s((char *)(v3 - 56), 0x2Cu);
v4 = (char *)(v3 - 56);
do
v5 = *v4++;
while ( v5 );
if ( &v4[-v3 + 55] == (char *)42 )
{
v7 = 0;
while ( (*(_BYTE *)(v3 + v7 - 56) ^ byte_402130[v7 % 16]) == dword_402150[v7] )
{
if ( ++v7 >= 42 )
{
printf("right!\n");
goto LABEL_10;
}
}
printf("error!\n");
LABEL_10:
v8 = v3 ^ *(_DWORD *)(v3 - 4);
result = 0;
}
else
{
printf("error!\n");
result = -1;
}
return result;
}
通过第15行代码,我们知道输入的正确flag与byte_402130[v4 % 16]进行异或等于dword_402150[v4],这个v4就是一个数组下标,最大为41

实际上就是"this_is_not_flag"

这个数字取42个就行,然后写代码:
byte_402130 = "this_is_not_flag"
dword_402150 = [ 0x12, 4, 8, 0x14, 0x24, 0x5C, 0x4A, 0x3D, 0x56, 0x0A, 0x10, 0x67,
0, 0x41, 0, 1, 0x46, 0x5A, 0x44, 0x42, 0x6E, 0x0C, 0x44, 0x72, 0x0C, 0x0D,
0x40, 0x3E, 0x4B, 0x5F, 2, 1, 0x4C, 0x5E, 0x5B, 0x17, 0x6E, 0x0C, 0x16, 0x68,
0x5B, 0x12, 0, 0, 0x48 ]
x = ''
for i in range(0,42):
x += chr(dword_402150[i]^ord(byte_402130[i%16]))
print(x)
运行代码之后得到flag:

3 结论
软件逆向是一个熟能生巧的过程,除了学习别人的经验技巧之外,更多的是需要不断的练习。软件逆向过程是比较枯燥的,必须要有足够的耐心和细心。对于我的理解:破解软件最基本的工具就是别人写好的专门用于破解分析的软件,这样的软件很多,最基本的是三个。老大叫PEID,老二叫DIE64,老三叫OD。遇到要破解的软件,兄弟依次上阵。老大先上,作用是查一下这个软件有没有加壳,是什么壳?壳就是软件的防弹衣,这个防弹衣是用专门的程序编写的,这个防弹衣是在软件有了使用验证以后又增加的一层保护。其目的就是对付我们使用的破解工具,让我们不好下手。我们的老大查了以后,知道这个防弹衣的型号就可以用对应的脱防弹衣的工具来对付它了。接着,老二再上,作用是识别这个软件是什么语言编写的,通常来说有C、VC、VB、DELPHI、易语言等,因为不同的语言有特殊的破解方法。知道有没有壳?是什么语言编写的?然后老三就闪亮登场了。OD的作用就是分析软件。分析什么?就是要找出验证的关键位置,分析验证机制。