解析库的使用
使用正则表达式,比较烦琐,而且万一有地方写错了,可能导致匹配失败。
对于网页的节点来说,有 id 、 class 或其他属性。 而且节点之间还有层次关系,在网页中可以通过 XPath 或 css 选择器来定位一个或多个节点 。 利用 XPath 或 css选择器来提取某个节点,然后再调用相应方法获取它的正文内容或者属性。
在 Python 中,有 lxml 、Beautiful Soup 、 pyquery 等解析库实现这个操作。
使用 XPath
XPath , 全称 XML Path Language ,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言 。
1. XPath 概览
XPath 提供了非常简洁明了的路径选择表达式,还提供了超过
100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等 。 几乎所有我们想要定位的节点,都可以用 XPath 来选择。
使用之前,首先要确保安装好 lxml 库
官方网站 : https://www.w3.org/TR/xpath
2. XPath 常用规则

例子:
//title[@lang=‘eng’]
代表选择所有名称为 title ,同时属性 lang 的值为 eng 的节点
实例引入
from lxml import etree
#一段 HTML 文本
text = '''
<div>
<ul>
<li class="item-O"><a href="linkl.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
#最后一个 li 节点是没有闭合的
html = etree.HTML(text) #调用 HTML 类进行初始化
result= etree.tostring(html)
print(result.decode('utf-8'))
调用 tostring ()方法即可输出修正后的 HTML 代码,但是结果是 bytes 类型 。 利用decode ()方法将其转成 str 类型,经过处理之后, li 节点标签被补全,并且还向动添加了 body 、 html 节点 。
运行结果:

也可以直接读取文本文件进行解析:
#输出结果略有不同,多了一个 DOCTYPE 的声明
html = etree.parse('. /test. html', etree.HTMLParser())
result= etree.tostring(html)
3.所有节点
用//开头的 XPath 规则来选取所有符合要求的节点
result = html.xpath('//*')
运行结果:

*代表匹配所有节点,也就是整个 HTML 文本中的所有节点都会被获取,返回形式是一个列表,每个元素是 Element 类型,其后跟了节点的名称,如 html 、 body 、 div 、 ul 、 li 、a等。
如果想获取所有 li 节点:
result = html.xpath('//li')
print(result)
print(result[0])
运行结果:

4. 子节点
通过 / 或 // 即可查找元素的子节点或子孙节点
其中/用于获取直接子节点,// 用于获取子孙节点
#选择 li 节点的所有直接 a 子节点
result = html.xpath('//li/a')
#取 ul 节点下的所有子孙 a 节点
result = html.xpath('//ul//a')
5.父节点
查找父节点可以用 … 来实现,也可以通过 parent ::来获取父节点
#选中 href 属性为 link4.html 的 a 节点,然后再获取其父节点,然后再获取其 class属性
result = html.xpath('//a[@href="link4.html"]/../@class')
result = html.xpath('//a[@href="link4.html"]/parent::*/@class')
6…属性匹配
可以用@符号进行属性过滤
#限制了节点的 class 属性为 item-0
result = html.xpath('//li[@class = "item-0"]')
7.文本获取
XPath 中的 text( )方法可获取节点中的文本
result = html.xpath('//li[@class = "item-0"]/text()')
没有获取到任何文本,只获取到了一个换行符:
因为 XPath 中text ()前面是/,而此处/的含义是选取直接子节点,很明显 l i 的直接子节点都是 a 节点,文本都是在a节点内部的,所以这里匹配到的结果就是被修正的li节点内部的换行符。
想获取 li 节点内部的文本,就有两种方式,一种是先选取 a 节点再获取文本,另一种就是使用 //
result1 = html.xpath('//li[@class = "item-0"]/a/text()')
result2 = html.xpath('//li[@class = "item-0"]//text()')
print(result1)
print(result2)
运行结果:

如果要想获取子孙节点内部的所有文本,可以直接用 //加 text( )的方式,这样可以保证获取到最全面的文本信息,但是可能会夹杂一些换行符等特殊字符。 如果想获取某些特定子孙节点下的所有文本,可以先选取到特定的子孙节点,然后再调用 text( )方法获取其内部文本,这样可以保证获取的结果是整洁的 。
8.属性获取
通过@href 即可获取节点的 href 属性
和属性匹配的方法不同,属性匹配是中括号加属性名和值来限定某个属性,如[@href="linkl.html”],而此处的@href 指的是获取节点的某个属性
result = html.xpath('//li/a/@href')
运行结果:

9.属性多值匹配
如果HTML 文本中 li 节点的 class 属性有两个值 li 和 li-first,此时如果还用之前的属性匹配获取,就无法匹配
这时就需要用 contains( )函数,第一个参数传人属性名称,第二个参数传入属性值,只要此属性包含所传入的属性值,就可以完成匹配了 。
result = html.xpath('//li[contains(@class,"li")]/a/text()')
10.多属性匹配
是根据多个属性确定一个节点,这时就需要同时匹配多个属性。 此时可以使用运算符 and 来连接:
result = html.xpath('//li[contains(@class,"li") and @name="item"]/a/text()')
同时根据 clas s 和 name 属性来选择,一个条件是 class 属性里面包含 li 字符串,另一个条件是 name 属性为 item 字符串,二者需要同时满足,用 and 操作符相连,相连之后置于中括号内进行条件筛选

11.按序选择
可以利用中括号传入索引的方法获取特定次序的节点
#选取第一个 li 节点,中括号中传入数字 l
result = html.xpath('//li[l]/a/text()')
#选取最后一个 li 节点,中括号中传入 last()
result = html.xpath ('//li[last()]/a/text()')
#选取位置小于 3 的 li 节点
result = html.xpath('//li[position()<3]/a/text ()')
#选取倒数第三个 li 节点,中括号中传入 last()-2
result = html.xpath('//li[last()-2]/a/text()')
在 XPath 中,提供了 100 多个函数,包括存取 、 数值、字符串、逻辑、节点、序列等处理功能,它们的具体作用可以参考: http://www.w3school.com.cn/xpath/xpath_functions.asp
12. 节点轴选择
XPath 提供了很多节点轴选择方法,包括获取子元素 、兄弟元素、父元素、祖先元素等
#调用ancestor 轴,可以获取所有祖先节点
result = html.xpath('//li[l]/ancestor::*')
#在冒号后面加了 div,得到的结果就只有 div 这个祖先节点
result = html.xpath('//li[l]/ancestor::div')
#调用了 attribute 轴,可以获取所有属性值,其后跟的选择器还是*,代表获取节点的所有属性,返回值就是 li 节点的所有属性值
result = html.xpath('//li[1]/attribute::*')
#调用了 child 轴,可以获取所有直接子节点,当前选取 href 属性为 linkl.html 的 a 节点
result= html.xpath('//li[1]/child::a[@href="linkl.html"]')
#调用了 descendant 轴,可以获取所有子孙节点,当前获取只包含 span 节点而不包含 a 节点
result = html.xpath('li[l]/descendant::span')
#调用了 following 轴,可以获取当前节点之后的所有节点,当前只获取了第二个后续节点
result = html.xpath('//li[1]/following::*(2]')
#调用 了 following-sibling 轴 ,可以获取当前节点之后的所有同级节点,当前获取了所有后续同级节点
result = html.xpath('//li[1]/following-sibling::*')
更多 XPath 的用法,可以查看http://www.w3school.com.cn/xpath/index.asp
更多 .Python lxml 库的用法,可以查看 http://lxml.de/
使用 Beautiful Soup
Beautiful Soup 提供一些简 单的、 Python 式的 函数来处理导航、搜索、修改分析树等功能 。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序 。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 UTF-8 编码 ,不需要考虑编码方式。
1.解析器

2. 基本用法
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>','lxml')
print (soup.prettify())
print(soup.p.string)
运行结果:

调用 prettify( )方法可以把要解析的字符串以标准的缩进格式输出,
对于不标准的 HTML 字符串 ,Beautifol Soup可以自动更正格式,在初始化 Beautifol Soup 时就完成了 。
soup.p.string可以选出 HTML 中的 p 节点,再调用 string 属性就可以得到里面的文本。
3.节点选择器
直接调用节点的名称就可以选择节点元素,再调用 string 属性就可以得到节点内的文本了
·选择元素
例子:
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse" ><b>The Dormouse' s story</b></p>
<p class ="story">Once upon a time there were three little sisters; and their names were
<a href = "http://example.com/elsie" class= "sister" id =" linkl " >< ! ... Else ... ></a>
<a href = "http://example.com/eacie" class ="sister" id="link2" >Lacie</a> and
<a href = "http://example.com/tillie" class ="sister" id= "link3">Tillie</a>;
and they lived at the bottom of a well. </p>
<p class="story">... </p>
"""
soup = BeautifulSoup(html,'lxml')
print(soup.title)
print(type(soup.title))#经过选择器选择后,选择结果都是Tag 类型
print(soup.title.string)#Tag 具有一些属性,比如 string,调用该属性,可以得到节点的文本内容
print(soup.head )
print(soup.p)
运行结果:

最后一个输出结果是第一个 p 节点的内容,后面的几个 p 节点并没有选到。所以,当有多个节点时,这种选择方式只会选择到第一个匹配的节点,其他的后面节点都会忽略。
·提取信息
(1)获取名称
可以利用 name 属性获取节点的名称 。
print(soup.title.name)

(2)获取属性
每个节点可能有多个属性,比如 id 和 class 等,选择这个节点元素后,可以调用 attrs 获取所有属性:
print(soup.p.attrs)
print(soup.p.attrs['name'])

attrs 的返回结果是字典形式,把选择的节点的所有属性和属性值组合成一个字典。
可以不用写 attrs ,直接在节点元素后面加中括号,传入属性名就可以获取属性值了。
print(soup.p['name'])
print(soup.p['class'])
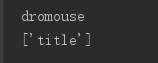
根据属性的值是否唯一,有的返回结果是字符串,有的返回结果是字符串组成的列表。 对于 class , 一个节点元素可能有多个 class , 所以返回的是列表。
(3)获取内容
·嵌套选择
在 Tag 类型的基础上再次选择得到的依然还是 Tag 类型,每次返回的结果都相同,所以可以做嵌套选择 。
print(soup.head.title)
print(type(soup.head.title))
print(soup.head.title.string)
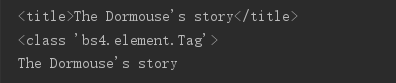
·关联选择
在做选择的时候,有时候不能做到一步就选到想要的节点元素,需要先选中某一个节点元素,然后以它为基准再选择它的子节点、父节点、 兄弟节点等。
(1)子节点和子孙节点
选取节点元素之后,如果想要获取它的直接子节点,可以调用 cont ents 属性
print(soup.p.contents)
返回结果是列表形式,若该节点里既包含文本,又包含节点,最后会将它们以列表形式统一返回 。
注意:列表中的每个元素都是 p 节点的直接子节点。若直接子节点例包含子节点,返回结果不会把子孙节点选出来。

调用 children 属性得到相应的结果:
print(soup.body.children)
for i, child in enumerate(soup.body.children):
print(i, child)
运行结果:

调用了 children 属性来选择,返回结果是生成器类型
要得到所有的子孙节点的话,可以调用 descendants 属性 :
print(soup.body. descendants)
for i, child in enumerate(soup.body. descendants):
print(i, child)

(2)父节点和祖先节点
如果要获取某个节点元素的父节点,可以调用 parent 属性:
print(soup.a.parent)

这里输出的仅仅是 a 节点的直接父节点,而没有再向外寻找父节点的祖先节点 。如果想获取所有的祖先节点,可以调用 parents 属性 :
print(type(soup.a.parents))
print(list(enumerate(soup.a.parents)))

返回结果是生成器类型
(3)兄弟节点
next_sibling 和 previous_sibling 分别获取节点的下一个和上一个兄弟元素, next_siblings 和 previous_siblings 则分别返回所有前面和后面的兄弟节点的生成器
print(' next_sibling ',soup.a.next_sibling )
print(' previous_sibling ',soup.a.previous_sibling)
print(' next_siblings ',list(enumerate(soup.a.next_siblings)))
print(' previous_siblings ',list(enumerate(soup.a.previous_siblings)))

(4)提取信息
print(soup.a.next_sibling.string)
print(list(soup.a.parents)[o].attrs['class'])
如果返回结果是单个节点,那么可以直接调用 string 、 attrs 等属性获得其文本和属性;如果返回结果是多个节点的生成器,则可以转为列表后取出某个元素,然后再调用 string 、 attrs 等属性获取其对应节点的文本和属性。
4.方法选择器
Beautifu l Soup 还提供了一些查询方法,比如 find_all()和 find ()等 ,调用它们,然后传入相应的参数,就可以灵活查询了。
• find_all()
查询所有符合条件的元素,给它传入一些属性或文本,就可以得到符
合条件的元素。
API 如下:
find_all(narne, attrs, recursive, text, **kwargs)
(l) name:根据节点名来查询元素
print(soup.find_all(name='p'))
print(type(soup.find_all(name='p')[0]))
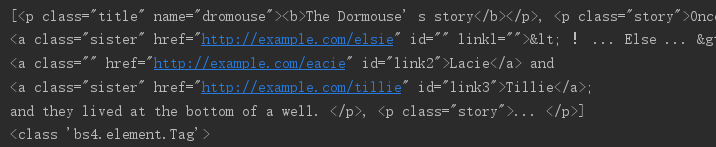
调用 find_all ()方法,返回结果是列表类型,每个元素依然都是 bs4.element.Tag 类型,所以依然可以进行嵌套查询,可以再继续查询其内部的节点。
for p in soup.find_all(name = 'p'):
print (p.find_all(name='a'))

(2) attrs
print(soup.find_all(attrs = {'id':'list-1'})
print(soup.find_all(attrs = {'name': 'elements'})
对于一些常用的属性,比如 id 和 ιlass 等, 我们可以不用 attrs 来传递。 比如,要查询 id 为 list-1的节点,可以直接传人 id 这个参数。
print(soup.find_all(id='list-1'))
print(soup.find_all(class = 'element'))
(3) text
text 参数可用来匹配节点的文本 ,传入的形式可以是字符串,可以是正则表达式对象。
print(soup.find_all(text=re.compile('link')))
#结果返回所有匹配正则表达式的节点文本组成的列表
• find{)
与find_all( )方法比较,find()方法返回的是单个元素,即第一个匹配的元素。
print(soup.find(name = 'p'))
print(type(soup.find(name = 'p')))
print(soup.find(class_= 'list' ))

还有许多查询方法:
口 fiind_parents( )和 find_parent( ): 前者返回所有祖先节点 , 后者返回直接父节点。
口 find_next_siblings( )和 find_next_sibling( ): 前者返回后面所有的兄弟节点 , 后者返回后面第一个兄弟节点 。
口 find_previous_siblings( )和 find_previous_sibling( ): 前者返回前面所有的兄弟节点 , 后者返回前面第一个兄弟节点 。
口 find_all_next( )和 find_next( ): 前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点 。
口 find_all_previous( )和 find_previous( ):前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点 。
5.css 选择器
css官方文档地址: http://www.w3school.com.cn/cssref/css_selectors.asp
使用 css 选择器时,只需要调用 select( )方法,传人相应的 css 选择器即可。
例子:
from bs4 import BeautifulSoup
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element"> Foo</li>
<li class="element">Bar</li>
<li class="element">]ay</li>
</ul>
<Ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
soup = BeautifulSoup(html,'lxml')
print (soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-2 .element'))
print(type(soup.select('ul')[0]))

·嵌套选择
for ul in soup.select('ul'):
print(ul.select('li'))

• 获取属性
直接传入中括号和属性名,以及通过 attrs 属性获取属性值,都可以成功 。
for ul in soup.select('ul'):
print(ul['id'])
print (ul.attrs['id'])
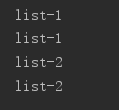
·获取文本
要获取文本,可以用 string 属性,还有一个方法就是 get_text()
for li in soup.select('li') :
print('Get Text:',li.get_text())
print('String:', li.string)

小总结:
1.推荐使用 lxml 解析库,必要时使用 html.parser。
2.节点选择筛选功能弱但是速度快 。
3.建议使用 find( )或者 find_all( )查询匹配单个结果或者多个结果 。
4.如果对 css 选择器熟悉的话,可以使用 select( )方法选择 。
使用 pyquery
如果比较熟悉css 选择器和jQuery,可以使用解析库一pyquery。
1.初始化
初始化 pyquery 的时候,需要传入 HTML 文本来初始化一个 PyQuery对象。 它的初始化方式有多种,比如直接传入字符串,传入 URL ,传人文件名,等等。
•字符串初始化
html = """
<div>
<ul>
<li class="item-O">first item</li>
<li class="item-1"><a herf = "link2.html"> second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class = cold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="links.html">fifth item</a></li>
</ul>
</div>
"""
from pyquery import PyQuery as pq #引人 PyQuery 这个对象,取别名为 pq
#字符串当作参数传递给 PyQuery 类,完成了初始化
doc = pq(html)
print (doc('li'))
•URL 初始化
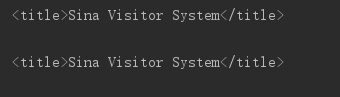
doc = pq(url='https://weibo.com')
print(doc('title'))
doc = pq(requests.get('https://weibo.com').text)#功能与上面相同
print(doc('title'))
•文件初始化
除了传递 URL ,还可以传递本地的文件名, 将参数指定为 filename 即可:
doc = pq(filename='demo.html')
2.基本 css 选择器
html = """
<div id="container">
<ul class="list">
<li class="item-O">first item</li>
<li class="item-1"><a herf = "link2.html"> second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class = cold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="links.html">fifth item</a></li>
</ul>
</div>
"""
from pyquery import PyQuery as pq
import requests
doc = pq(html)
print(doc('#container .list li'))
print(type(doc('#container .list li')))

css 选择器#container .list li 的意思是先选取 id 为 container 的节点,然后再选取其内部的 class 为 list 的节点内部的所有 li 节点,然后,打印输出 ,它的类型依然是 PyQuery 类型。
3.查找节点
一些常用的查询函数和 jQuery 中函数的用法完全相同 。
·子节点
查找子节点时 , 需要用到find( )方法,传人的参数是 css 选择器。
find( )方法会将符合条件的所有节点选择出来,结果的类型是PyQuery 类型 。find( )的查找范围是节点的所有子孙节点,而如果只想查找子节点,那么可以用children( )方法。
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)

lis = items.children('li')
print(type(lis))
print(lis)

如果要筛选所有子节点中符合条件的节点,比如想筛选出子节点中 class 为 active 的节点,可以向 children()方法传入 css 选择器 .active:
lis = items.children('.active')
print(lis)

·父节点
#这里的父节点是该节点的直接父节点,
container = items.parent()
print(type(container))
print(container)

祖先节点:parents( )方法
·兄弟节点
siblings( )方法
如果要筛选某个兄弟节点,我们依然可以向 siblings 方法传入 css 选择器
4.遍历
对于多个节点的结果,就需要遍历来获取,可调用 items( )方法得到一个生成器,遍历一下,就可以逐个得到节点对象:
lis = doc('li').items()
print(type(lis))
for li in lis:
print(li, type(li))

5.获取信息
比较重要的信息有两类, 一是获取属性,二是获取文本。
·获取属性
以调用 attr( )方法来获取属性:
a = doc(' .item-0.active a')
print(a, type(a))
print(a.attr('href'))
#也可以通过调用 attr 属性来获取属性
print(a.attr.href)

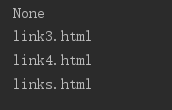
当返回结果包含多个节点时,调用 attr()方法,只会得到第一个节点的属性。遇到这种情况时,如果想获取所有的 a 节点的属性,就要遍历 :
a = doc('a')
for item in a.items() :
print(item.attr('href'))
·获取文本
可以调用 text( )方法以获取其内部的文本信息 ,此时会忽略掉节点内部包含的所有 HTML,只返回纯文字内容。
html( )方法可以获取这个节点内部的 HTML 文本。
html( )方法返回的是第一个节点的内部 HTML 文本,而 text( )则返回了所有的节点内部的纯文本。
6.节点操作
pyquery 提供了一系列方法来对节点进行动态修改,比如为某个节点添加一个 class ,移除某个节点等。
例子:
• addClass 和 removeClass
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)
首先选中了第三个 li 节点,然后调用 removeClass( )方法,将 li 节点的active 这个 class 移除,后来又调用 addClass( )方法,将 class 添加回来。

• attr 、 text 和 html
除了操作 class 这个属性外,也可以用 attr( )方法对属性进行操作 。还可以用 text()和 html( )方法来改变节点内部的内容。
li = doc('.item-0.active')
print(li)
li.attr('name','link1')
print(li)
li.text('changed item')
print(li)
li.html('<span>changed item</span>')
print(li)

因此 attr( )方法只传入第一个参数的属性名,则是获取这个属性值 ; 如果传入第二个参数,可以用来修改属性值。 text( )和 html( )方法如果不传参数 ,则是获取节点内纯文本和 HTML 文本;如果传人参数 ,则进行赋值。
• remove()
remove( )方法就是移除
li = doc('.item-0')
print(li)
li.find('span').remove()
print(li)

还有很多节点操作的方法,比如 append ( )、 empty( )和 prepend( )等方法,它们和 jQuery的用法完全一致,详细的用法可以参考官方文档: http://pyquery.readthedocs.io/en/latest/api.html
7.伪类选择器
CSS3 的伪类选择器功能强大
例如选择第一个节点、最后一个节点、奇偶数节点、包含某一文本的节点等
li = doc('li:first-child')#第一个 li 节点
print(li)
li = doc('li:last-child')#最后一个 li 节点
print(li)
li = doc('li:nth-child(2)')#第二个 li节点
print(li)
li = doc('li:gt(2)')#第三个 li 之后的 li 节点
print(li)
li = doc('li:nth-child(2n)')#偶数位置的 li 节点
print(li)
li = doc('li:contains(second)')#
print(li)
关于 css 选择器的更多用法,可以参考 http://www.w3school.com.cn/css/index.asp
pyquery 的官方文档: http://pyquery.readthedocs.io