一、任务描述
实际施工现场需要对每个进出的人员进行安全帽监测,对未佩戴安全帽的人员平台进行风险告警,通知工作人员并记录下来。
主要包括三类目标物体:头盔(helmet),人(person)和人头(head)
二、实现流程
1、数据集:直接用的网络数据集,下载地址:
https://aistudio.baidu.com/aistudio/datasetdetail/50329
2、算法:用的算法框架是百度的PaddleDetection,代码下载地址:
https://github.com/PaddlePaddle/PaddleDetection
3、将数据集解压保存在helmet_data文件夹下
4、将数据集拆分成训练集、测试集和验证集,用txt文件记录保存下来。代码如下:
import logging
import random
import os
import os.path as osp
import xml.etree.ElementTree as ET
def list_files(dirname):
""" 列出目录下所有文件(包括所属的一级子目录下文件)
Args:
dirname: 目录路径
"""
def filter_file(f):
if f.startswith('.'):
return True
return False
all_files = list()
dirs = list()
for f in os.listdir(dirname):
if filter_file(f):
continue
if osp.isdir(osp.join(dirname, f)):
dirs.append(f)
else:
all_files.append(f)
for d in dirs:
for f in os.listdir(osp.join(dirname, d)):
if filter_file(f):
continue
if osp.isdir(osp.join(dirname, d, f)):
continue
all_files.append(osp.join(d, f))
return all_files
def is_pic(filename):
""" 判断文件是否为图片格式
Args:
filename: 文件路径
"""
suffixes = {'JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png'}
suffix = filename.strip().split('.')[-1]
if suffix not in suffixes:
return False
return True
def replace_ext(filename, new_ext):
""" 替换文件后缀
Args:
filename: 文件路径
new_ext: 需要替换的新的后缀
"""
items = filename.split(".")
items[-1] = new_ext
new_filename = ".".join(items)
return new_filename
def split_voc_dataset(dataset_dir, save_dir, val_percent=0.15, test_percent=0.15):
# 注意图片目录和标注目录名已全部修改
if not osp.exists(osp.join(dataset_dir, "JPEGImages")):
logging.error("\'JPEGImages\' is not found in {}!".format(dataset_dir))
if not osp.exists(osp.join(dataset_dir, "Annotations")):
logging.error("\'Annotations\' is not found in {}!".format(
dataset_dir))
all_image_files = list_files(osp.join(dataset_dir, "JPEGImages"))
image_anno_list = list()
label_list = list()
for image_file in all_image_files:
if not is_pic(image_file): # 判断是否为图片格式
continue
anno_name = replace_ext(image_file, "xml")
if osp.exists(osp.join(dataset_dir, "Annotations", anno_name)):
image_anno_list.append([image_file, anno_name])
try:
tree = ET.parse(osp.join(dataset_dir, "Annotations", anno_name))
except:
raise Exception("文件{}不是一个良构的xml文件,请检查标注文件".format(
osp.join(dataset_dir, "Annotations", anno_name)))
objs = tree.findall("object")
for i, obj in enumerate(objs):
cname = obj.find('name').text
if not cname in label_list:
label_list.append(cname)
else:
logging.error("The annotation file {} doesn't exist!".format(anno_name))
random.shuffle(image_anno_list) # 随机打乱
image_num = len(image_anno_list) # 总图片数量
val_num = int(image_num * val_percent) # 验证集数量
test_num = int(image_num * test_percent) # 测试集数量
train_num = image_num - val_num - test_num # 训练集数量
train_image_anno_list = image_anno_list[:train_num] # 训练集样本
val_image_anno_list = image_anno_list[train_num:train_num + val_num] # 验证集样本
test_image_anno_list = image_anno_list[train_num + val_num:] # 测试集样本
with open(osp.join(save_dir, 'train_list.txt'), mode='w', encoding='utf-8') as f:
for x in train_image_anno_list:
file = osp.join("JPEGImages", x[0])
label = osp.join("Annotations", x[1])
f.write('{} {}\n'.format(file, label))
with open(osp.join(save_dir, 'val_list.txt'), mode='w', encoding='utf-8') as f:
for x in val_image_anno_list:
file = osp.join("JPEGImages", x[0])
label = osp.join("Annotations", x[1])
f.write('{} {}\n'.format(file, label))
if len(test_image_anno_list):
with open(osp.join(save_dir, 'test_list.txt'), mode='w', encoding='utf-8') as f:
for x in test_image_anno_list:
file = osp.join("JPEGImages", x[0])
label = osp.join("Annotations", x[1])
f.write('{} {}\n'.format(file, label))
with open(osp.join(save_dir, 'labels.txt'), mode='w', encoding='utf-8') as f:
for l in sorted(label_list):
f.write('{}\n'.format(l))
return image_anno_list, label_list
if __name__ == '__main__':
dataset_dir = "/root/bigdata/pycharm_projects/PaddleDetection/data/helmet_data/helmet_train_data"
split_voc_dataset(dataset_dir=dataset_dir, save_dir=dataset_dir)
5、修改tools下的x2coco.py的训练集文件地址参数,然后运行x2coco.py来将xml文件转成json文件,具体修改如下(我这边为了方便,将需要修改的参数都放到一个params.py文件中):


注意:由于数据集标注文件已经是xml,所以不需要做其他转换。如果标注文件是yolo格式的txt文件,则需要先将其转换为voc格式的xml文件。
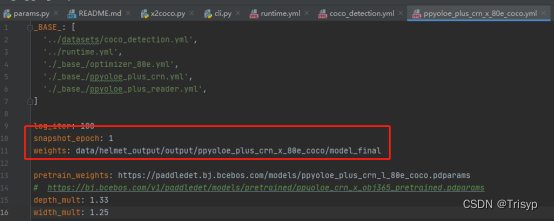
6、修改PaddleDetection中的/configs/ppyoloe/ppyoloe_plus_crn_x_80e_coco.yml'文件,
及其相关文件。
具体修改如下:
'../datasets/coco_detection.yml',

--------------------------------------------------------------------------------
ppyoloe_plus_crn_x_80e_coco.yml:
--------------------------------------------------------------------------------
'./_base_/optimizer_80e.yml',

--------------------------------------------------------------------------------
'../runtime.yml',

这里注意,没gpu的这个数据集要跑三天左右,建议买个gpu,不然感觉有点浪费时间
--------------------------------------------------------------------------------
另外有需要调整神经网络训练参数的可以去'./_base_/ppyoloe_plus_crn.yml'里面修改;有需要调整样本参数的可以去'./_base_/ppyoloe_plus_reader.yml'里面修改。
7、执行模型训练文件train.py:
python tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_x_80e_coco.yml --eval --amp
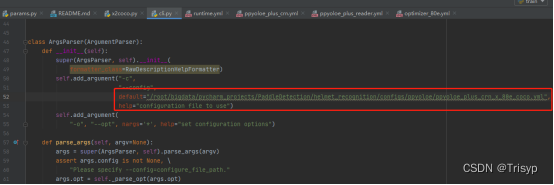
如果直接执行train.py不指定coco文件的话,就在cli.py中修改config的默认值,具体如下:
8、推理测试集数据,先修改infer.py的参数值,修改如下:

执行语句:python tools/infer.py -c configs/ppyoloe/ppyoloe_plus_crn_x_80e_coco.yml -o weights=../output/ppyoloe_plus_crn_x_80e_coco/best_model
如果直接执行infer.py不指定weights的话,就会直接使用ppyoloe_plus_crn_x_80e_coco.yml中的weights值。
其中weights参数是最好的训练模型的权重的绝对路径,
infer_dir是测试集图片数据的绝对路径,
output_dir是结果输出绝对路径,
最终生成推理结果的图片和测试集的推理结果bbox.json都存储在helmet_output/infer_output/路径下。