大家好,我是来自团队Pursuing the Past Youth的Ethan,天池ID是GrandRookie。和队友青禹小生、wbbhcb、Chauncy YAO经过2个多月的“征途”,最终在本届智能算法赛部分拿到了线上Top1的成绩。下面给出我们团队的完整解决方案。
赛题介绍
首先简单介绍下赛题,区别于之前做过的很多比赛主要偏向互联网的业务场景,本届比赛的选题则是围绕“智慧海洋建设,赋能海上安全治理能力现代化”。要求选手通过分析渔船北斗设备位置数据,具体判断出是
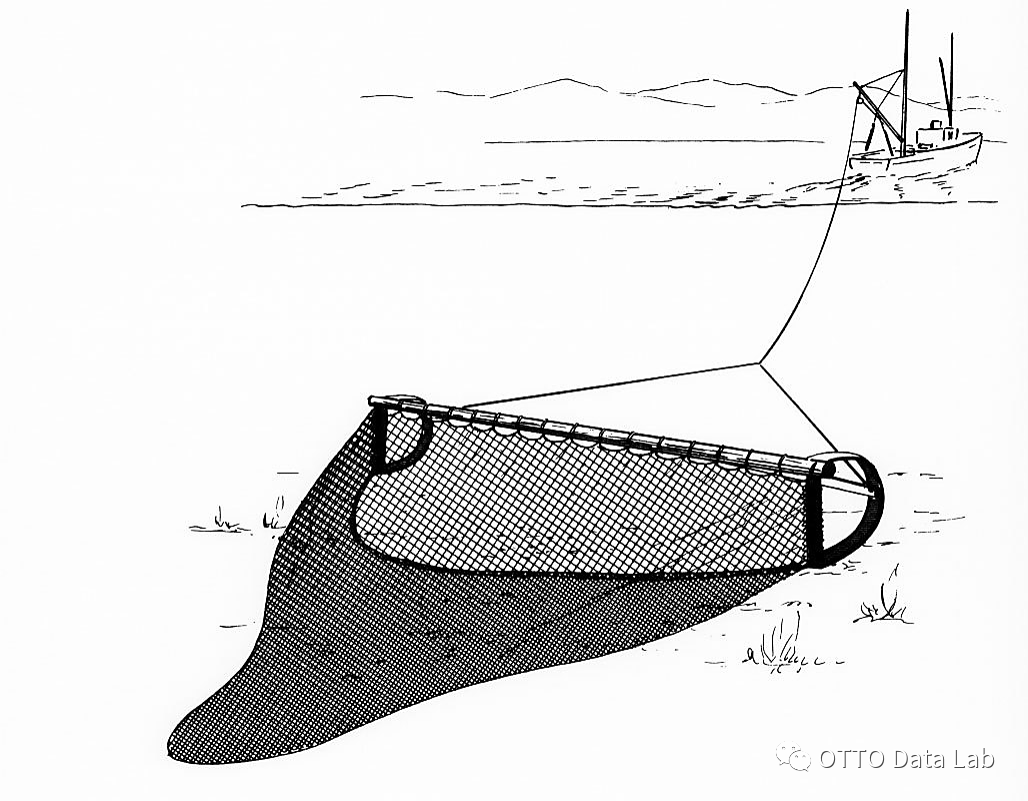
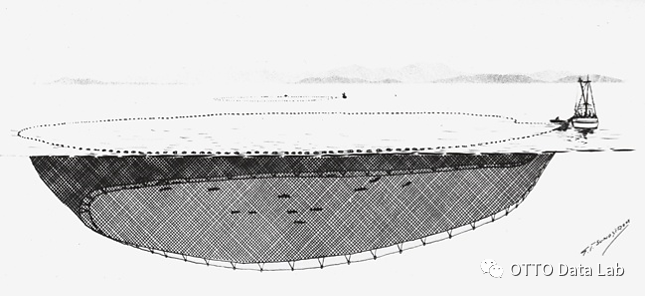
拖网作业、
围网作业还是
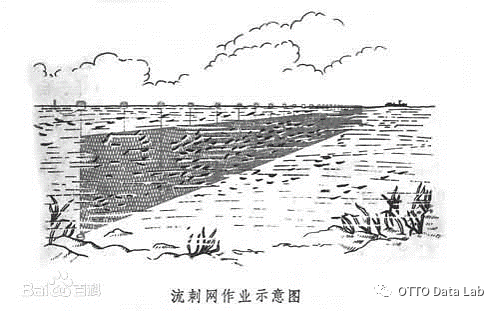
流刺网作业。
总结一下就是
“轨迹(序列数据)+多分类”的任务,评估指标选用的是F1值,比较常规,就不多做介绍了。
数据探索
我们团队习惯于从业务的角度出发去构造特征,但因为不具备海洋专业知识,比赛前期我们花了些时间查找了相关资料
2.1 渔船作业方式的定义
2.2 渔船作业过程中的三种状态
Anchored-off:船舶休息的点
Turning:船舶转弯的点
Straight-sailing:船舶航行的点
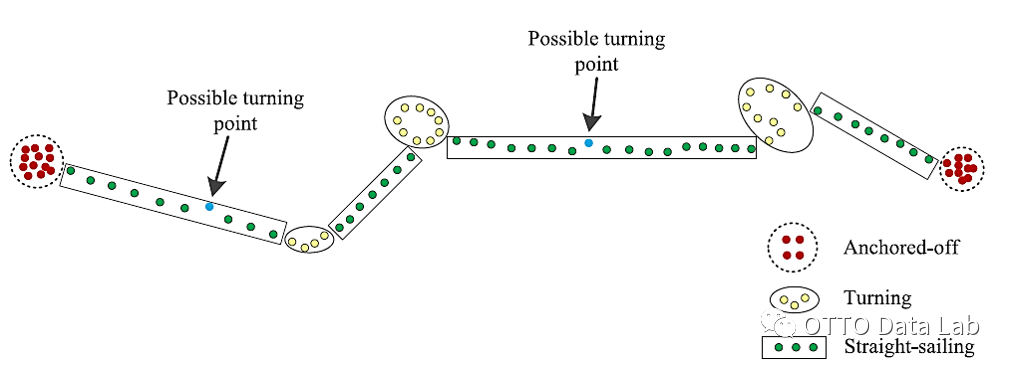
Kai Sheng, Zhong Liu, Dechao Zhou, Ailin He and Chengxu Feng(College of Electronic Engineering, Naval University of Engineering, Wuhan, Hubei,China). Research on Ship Classification Basedon Trajectory Features. THE JOURNAL OF NAVIGATION, Page 1 of 17. doi:10.1017/S0373463317000546
 特征工程
特征工程
基于以上查找的两部分资料,我们就找到了构造本题特征工程的两个切入点:
1. 表征渔船的轨迹
2. 表征渔船不同状态下的信息
3.1 如何表征轨迹序列?
3.1.1 传统经纬度统计特征
常规的做法就是对渔船的经纬度序列做均值、方差、分位数、众数等统计,可以简单地刻画渔船的活动范围
mode_df = data.groupby(['渔船ID', 'lat', 'lon'])['time'].agg({'mode_cnt':'count'}).reset_index()mode_df['rank'] = mode_df.groupby('渔船ID')['mode_cnt'].rank(method='first', ascending=False)for i in range(1, 4): tmp_df = mode_df[mode_df['rank']==i] del tmp_df['rank'] tmp_df.columns = ['渔船ID', 'rank{}_mode_lat'.format(i), 'rank{}_mode_lon'.format(i), 'rank{}_mode_cnt'.format(i)] data_ = data_.merge(tmp_df, on=['渔船ID'], how='left')
3.1.2 基于轨迹序列绝对和相对位置的复合向量编码
经纬度常规的统计特征对渔船轨迹信息的表征能力其实是有限的,这里我们设计了一种轨迹序列的编码方式(该方法可拓展至其他类型的轨迹序列数据),进一步刻画了轨迹的动态信息和渔船经过的每个点之间的联系。
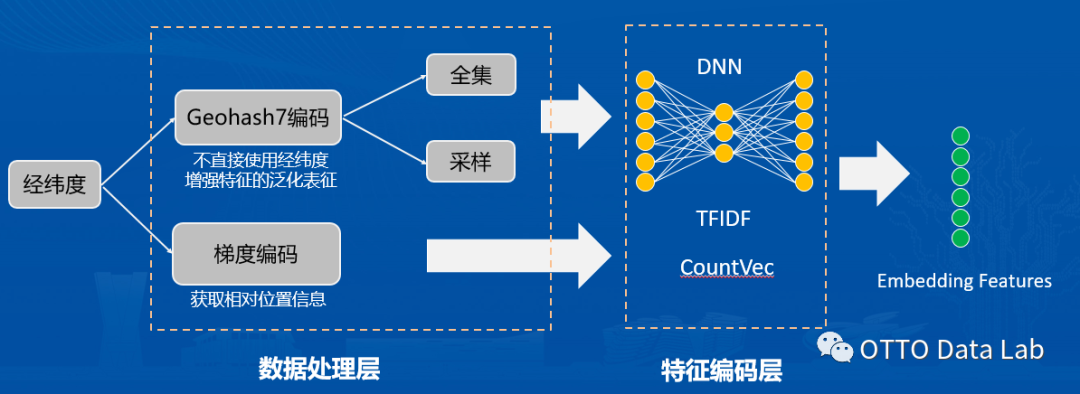 输入层
输入层:
渔船的轨迹序列
数据处理层:
1. Geohash7编码:Geohash其实是将地图拆分成了一个个矩形网格,当经纬度落入到某个网格内时,则使用网格的编码代替经纬度,相当于是一种聚类方式。这里我们不直接使用经纬度(细粒度)的好处就是可以提高特征的泛化能力。

除此之外,我们还采用了全集和下采样两种提取方式来提取Geohash7编码后的轨迹序列。下采样的好处是缓解渔船位置信息频繁上报而产生的噪音。
2. 梯度编码:轨迹序列的梯度是指的后一个位置相对于前一个位置的变化,目的是为了获取相对位置信息
特征编码层:
1. Word2Vec:将渔船的轨迹序列当成文本,每个地点则是一个“词语”,使用Word2Vec进行向量表征。
def w2v_feat(df, group_id, feat, length): print('start word2vec ...') data_frame = df.groupby(group_id)[feat].agg(list).reset_index() model = Word2Vec(data_frame[feat].values, size=length, window=5, min_count=1, sg=1, hs=1, workers=1, iter=10, seed=1, hashfxn=hashfxn) data_frame[feat] = data_frame[feat].apply(lambda x: pd.DataFrame([model[c] for c in x])) for m in range(length): data_frame['w2v_{}_mean'.format(m)] = data_frame[feat].apply(lambda x: x[m].mean()) del data_frame[feat] return data_frame
2. Node2Vec:把渔船经过的地点当成图中的“点”,而不同地点之间的关系则是“边”,使用Node2Vec进行向量表征。
3. TFIDF&CountVec:借鉴了文本的常用处理方法,提取了渔船轨迹序列中Geohash的频次信息。
def tfidf(input_values, output_num, output_prefix, seed=1024): tfidf_enc = TfidfVectorizer() tfidf_vec = tfidf_enc.fit_transform(input_values) svd_enc = TruncatedSVD(n_components=output_num, n_iter=20, random_state=seed) svd_tmp = svd_enc.fit_transform(tfidf_vec) svd_tmp = pd.DataFrame(svd_tmp) svd_tmp.columns = ['{}_tfidf_{}'.format(output_prefix, i) for i in range(output_num)] return svd_tmp
输出层:
轨迹序列Embedding向量
3.2 如何刻画渔船不同运行状态?
3.2.1 Anchored-off状态特征
这里粗略的认为当渔船的速度为0时,渔船处于停靠或是收网的状态。统计该状态下渔船所处的位置,可以让模型捕捉到不同作业方式下渔船停靠点或收网点的规律。
group_df = data[data['速度']==0].groupby(['渔船ID'])[col].agg( {'锚点_'+col+'_mean': 'mean', '锚点_'+col+'_max': 'max', '锚点_'+col+'_min': 'min', '锚点_'+col+'_nuniq': 'nunique', '锚点_'+col+'_q1': lambda x: np.quantile(x, 0.10), '锚点_'+col+'_q2': lambda x: np.quantile(x, 0.20), '锚点_'+col+'_q3': lambda x: np.quantile(x, 0.30), '锚点_'+col+'_q4': lambda x: np.quantile(x, 0.40), '锚点_'+col+'_q5': lambda x: np.quantile(x, 0.50), '锚点_'+col+'_q6': lambda x: np.quantile(x, 0.60), '锚点_'+col+'_q7': lambda x: np.quantile(x, 0.70), '锚点_'+col+'_q8': lambda x: np.quantile(x, 0.80), '锚点_'+col+'_q9': lambda x: np.quantile(x, 0.90)} ).reset_index()
3.2.2 Turning状态特征
将数值型的方向特征进行离散化处理后,统计渔船作业过程中不同方向的频次及比例。
data['方向'] = data['方向'].apply(lambda x:(int(round(x/30)))*30)degree_df = data.pivot_table(index='渔船ID',columns='方向',values='lat', dropna=False, aggfunc='count').fillna(0)degree_df.columns = [str(f)+'_方向_count' for f in degree_df.columns]degree_df.reset_index(inplace=True)
3.3.3 Straight-sailing状态特征
渔船的历史数据中存在大量的速度为0的记录,会对速度进行均值、方差等统计产生较大的影响。我们单独取速度大于0时的样本,再对速度构造统计特征,一方面去除速度为0的影响、另一方面刻画了渔船航行时的状态。
group_df = data[data['速度']>0].groupby(['渔船ID'])['速度'].agg({ '速度_mean_new': 'mean', '速度_q10_new': lambda x: np.quantile(x, 0.10), '速度_q20_new': lambda x: np.quantile(x, 0.20), '速度_q30_new': lambda x: np.quantile(x, 0.30), '速度_q40_new': lambda x: np.quantile(x, 0.40), '速度_q50_new': lambda x: np.quantile(x, 0.50), '速度_q60_new': lambda x: np.quantile(x, 0.60), '速度_q70_new': lambda x: np.quantile(x, 0.70), '速度_q80_new': lambda x: np.quantile(x, 0.80), '速度_q90_new': lambda x: np.quantile(x, 0.90),}).reset_index()
模型策略
LightGBM Is All You Need!
本次比赛我们的最优模型仍然是熟悉的LightGBM模型,单模型线上F1值是0.9026,模型融合后可以达到0.9040,这两个成绩均能取得Top1的成绩。
遗憾的是我们在深度学习模型方面也做了尝试,例如将轨迹转化为二维图像,利用resnet识别、取出resnet最后的FC层为特征与其他特征合并一起等,但最终都失败了。﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌
本次方案的开源代码(感谢青禹小生和Chauncy YAO的整理),欢迎大家star, 谢谢!

github地址:
青禹小生:https://github.com/juzstu/TianChi_HaiYang/Chauncy YAO:https://github.com/ycd2016/DCIC2020-IOC
更多精彩内容(请点击图片进行阅读)


 公众号:
AI蜗牛车
保持谦逊、保持自律、保持进步
公众号:
AI蜗牛车
保持谦逊、保持自律、保持进步

个人微信
备注:
昵称+学校/公司+方向
如果没有备注不拉群!
拉你进AI蜗牛车交流群

点个在看,么么哒!
