1.Kafka 简介
Apache Kafka 是一种高吞吐、分布式的流处理平台,由 LinkedIn 开发并于 2011 年开源。它具有 高伸缩性、高可靠性 和 低延迟 等特点,因此在大型数据处理场景中备受青睐。Kafka 可以处理多种类型的数据,如事件、日志、指标等,广泛应用于 实时数据流处理、日志收集、监控和分析 等领域。
通常用作消息队列和流处理,作为消息队列的时候,竞品有 RabbitMQ、ActiveMQ、RocketMQ、Apache Pulsar 等。
2.Kafka 架构
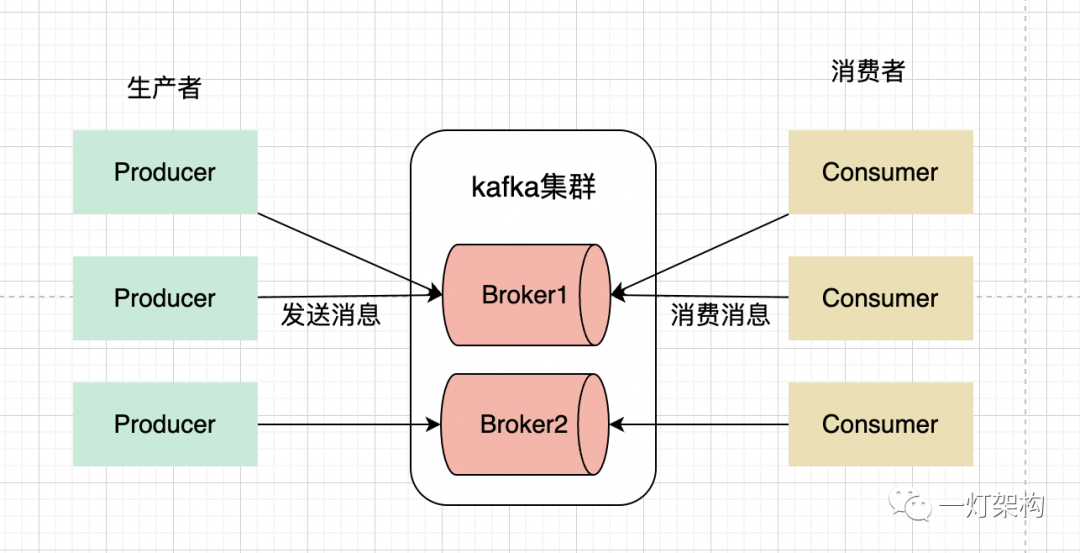
下面介绍一下 Kafka 架构中最重要的三个参与者:
-
Producer(生产者):生产者负责将消息发送到 Kafka 集群。
-
Consumer(消费者):消费者负责从 Kafka 集群中拉取并消费消息。
-
Broker(代理节点):Broker 是 Kafka 集群中的一个服务代理节点,可以看作是一台服务器。Kafka 集群通常由多个 Broker 组成,以实现负载均衡和容错。
3.分区与副本
Kafka 为了对消息进行分类,引入了 Topic(主题)的概念。生产者在发送消息的时候,需要指定发送到某个 Topic,然后消息者订阅这个 Topic 并进行消费消息。
Kafka 为了提升性能,又在 Topic 的基础上,引入了 Partition(分区)的概念。Topic 是逻辑概念,而 Partition 是物理分组。一个 Topic 可以包含多个 Partition,生产者在发送消息的时候,需要指定发送到某个 Topic 的某个 Partition,然后消息者订阅这个 Topic 并消费这个 Partition 中的消息。
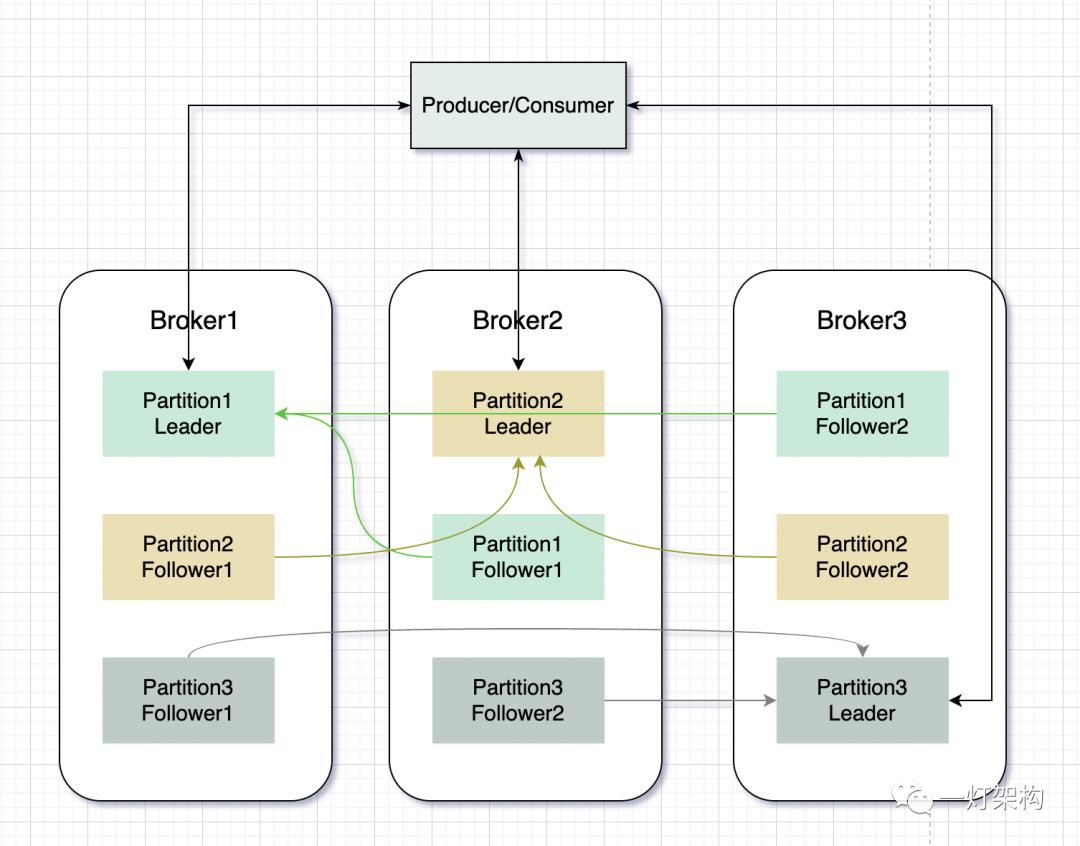
Kafka 为了提高系统的吞吐量和可扩展性,把一个 Topic 的不同 Partition 放到多个 Broker 节点上,充分利用机器资源,也便于扩展 Partition。
Kafka 为了保证数据的安全性和服务的高可用,又在 Partition 的基础上,引入 Replica(副本)的概念。一个 Partition 包含多个 Replica,Replica 之间是一主多从的关系,有两种类型 Leader Replica(领导者副本)和 Follower Replica(跟随者副本),Replica分布在不同的Broker节点上。
Leader Replica 负责读写请求,Follower Replica 只负责同步 Leader Replica 数据,不对外提供服务。当 Leader Replica 发生故障,就从 Follower Replica 选举出一个新的 Leader Replica 继续对外提供服务,实现了故障自动转移。
下图展示的是,同一个 Topic 的不同 Partition 在 Broker 节点的分布情况:
Kafka 为了提升 Replica 的同步效率和数据写入效率,又对 Replica 进行分类。针对一个 Partition 的所有 Replica 集合统称为 AR(Assigned Replicas,已分配的副本),包含 Leader Replica 和 Follower Replica。与 Leader Replica 保持同步的 Replica 集合称为 ISR(In-Sync Replicas,同步副本),与 Leader Replica 保持失去同步的 Replica 集合称为 OSR(Out-of-Sync Replicas,失去同步的副本),AR = ISR + OSR。
Leader Replica 将消息写入磁盘前,需要等 ISR 中的所有副本同步完成。如果 ISR 中某个 Follower Replica 同步数据落后 Leader Replica 过多,会被转移到 OSR 中。如果 OSR 中的某个 Follower Replica 同步数据追上了 Leader Replica,会被转移到 ISR 中。当 Leader Replica 发生故障的时候,只会从 ISR 中选举出新的 Leader Replica。
4.偏移量
Kafka 为了记录副本的同步状态,以及控制消费者消费消息的范围,于是引入了 LEO(Log End Offset,日志结束偏移量)和 HW(High Watermark,高水位)。
- LEO 表示分区中的下一个被写入消息的偏移量,也是分区中的最大偏移量。LEO 用于记录 Leader Replica 和 Follower Replica 之间的数据同步进度,每个副本中各有一份。
- HW 表示所有副本(Leader 和 Follower)都已成功复制的最小偏移量,是所有副本共享的数据值。换句话说,HW 之前的消息都被视为已提交,消费者可以消费这些消息。用于确保消息的一致性和只读一次。
下面演示一下 LEO 和 HW 的更新流程:
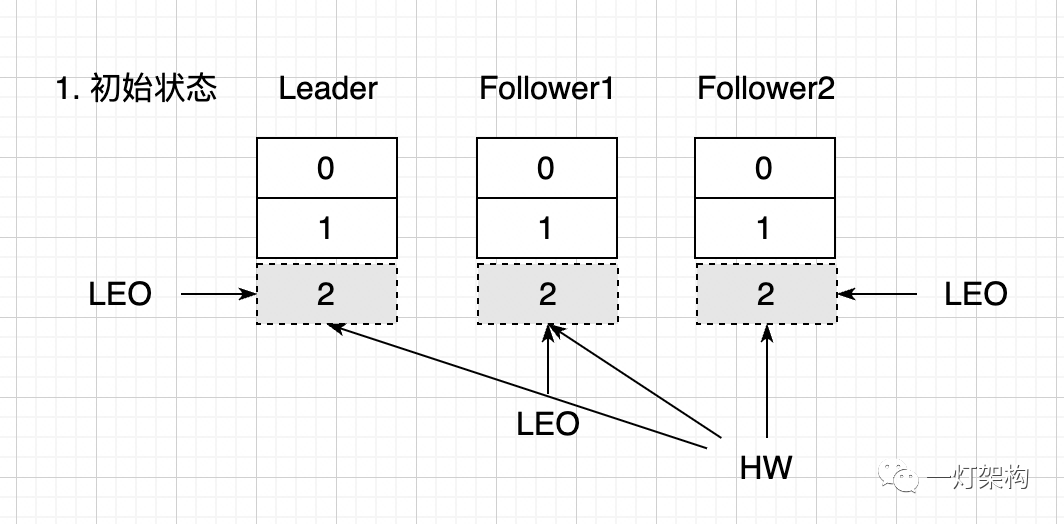
(1)初始状态,三个副本中各有 0 和 1 两条消息,LEO 都是 2,位置 2 是空的,表示是即将被写入消息的位置。HW 也都是 2,表示 Leader Replica 中的所有消息已经全部同步到 Follower Replica 中,消费者可以消费 0 和 1 两条消息。
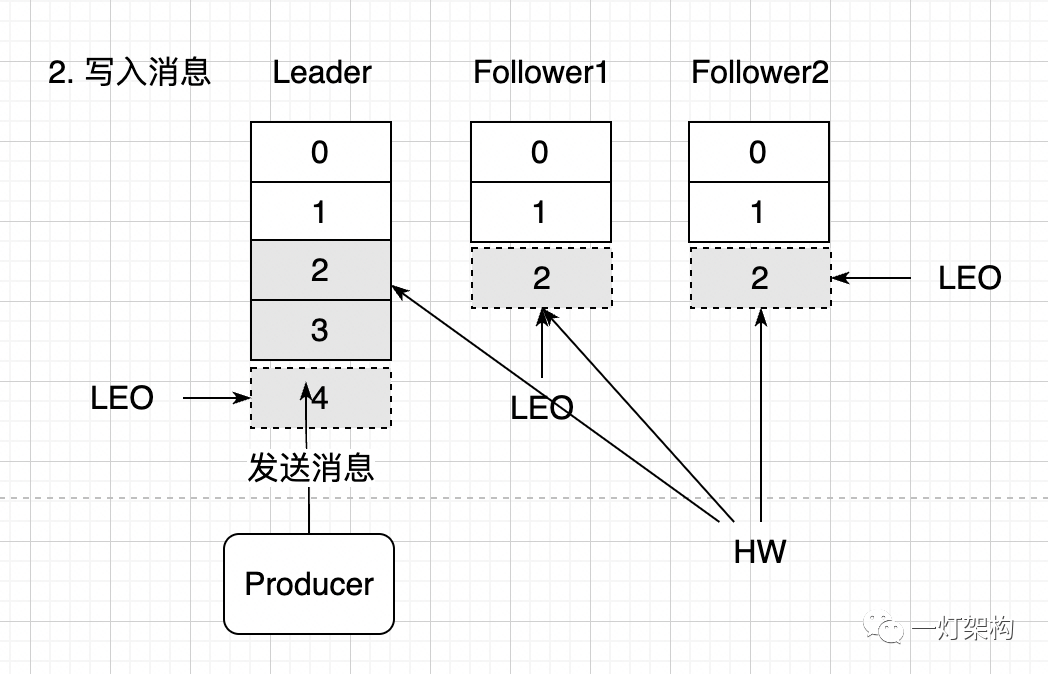
(2)生产者往 Leader Replica 中发送两条消息,此时 Leader Replica 的 LEO 的值增加 2,变成 4。由于还没有开始往 Follower Replica 同步消息,所以 HW 值和 Follower Replica 中 LEO 值都没有变。由于消费者只能消费 HW 之前的消息,也就是 0 和 1 两条消息。
(3)Leader Replica 开始向 Follower Replica 同步消息,同步速率不同,Follower1 的两条消息 2 和 3 已经同步完成,而 Follower2 只同步了一条消息 2。此时,Leader 和 Follower1 的 LEO 都是 4,而 Follower2 的 LEO 是 3,HW 表示已成功同步的最小偏移量,值是 3,表示此时消费者只能读到 0、1、2,三条消息。
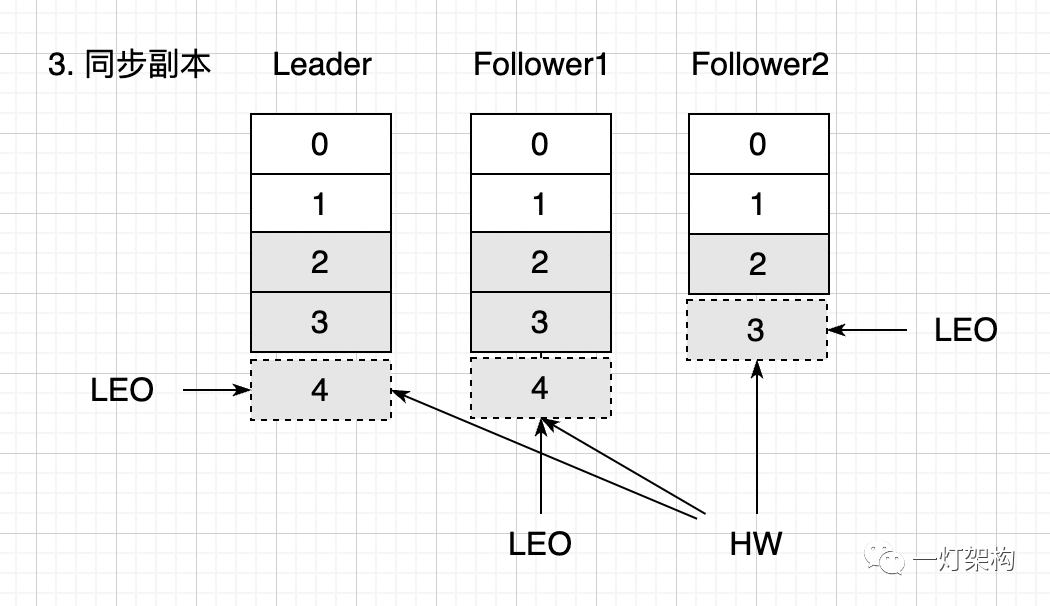
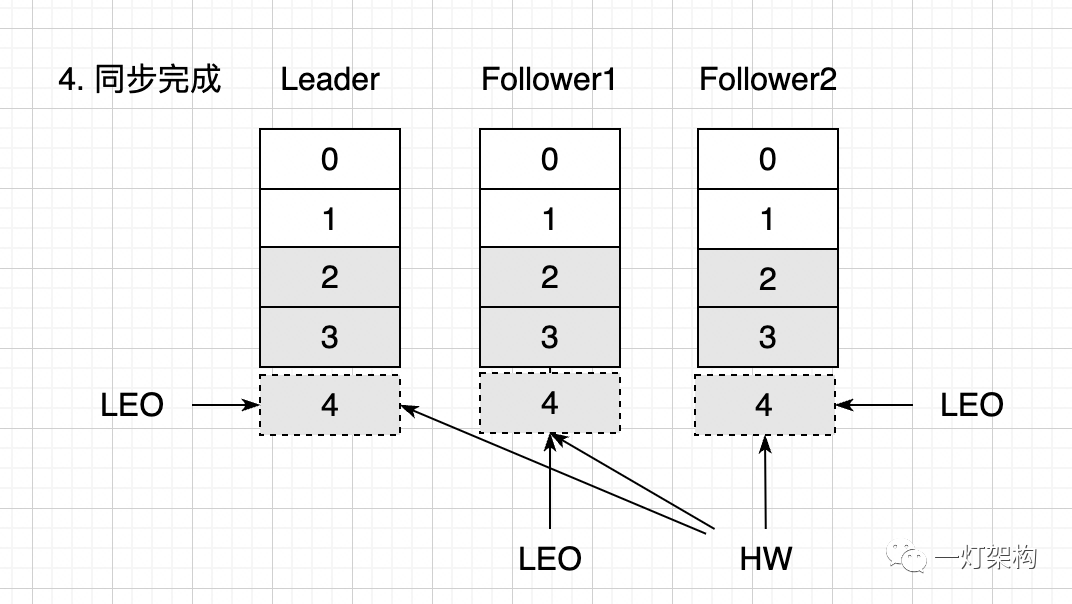
所有消息都同步完成,三个副本的 LEO 都是 4,HW 也是 4,消费者可以读到 0、1、2、3,四条消息。
5.消费者组
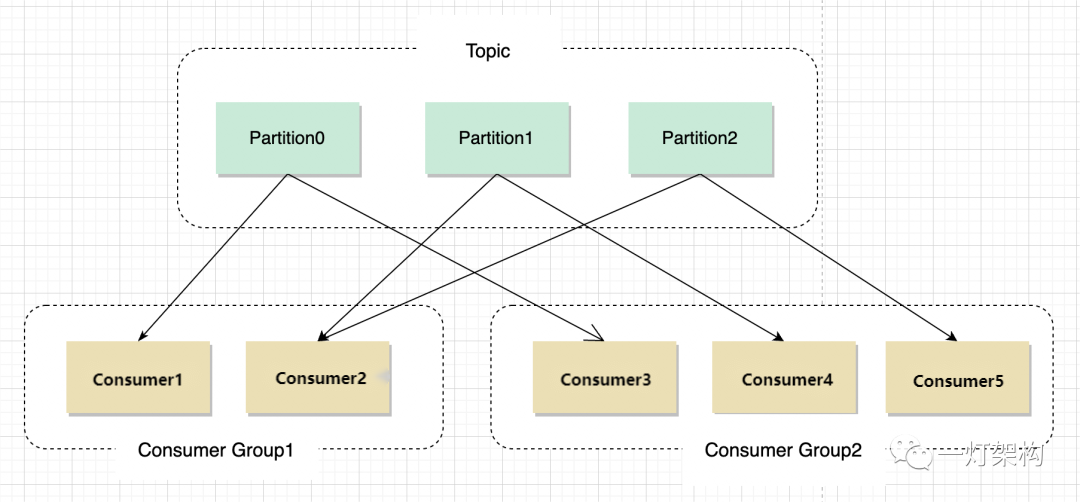
Kafka 为了提高消息的处理效率,引入了消费者组的概念。一个 消费者组(Consumer Group)包含多个消费者,一个消费者组可以同时订阅多个 Topic,一个 Topic 也可以同时被多个消费者组订阅。
为了保证同一个 Partition 的消息被顺序处理,针对一个消费者组,一个 Partition 的消息只会交给这个消息者组的一个消费者处理。
6.总结
本文简单介绍了 Kafka 架构,以及架构中涉及到底的一些名词概念,包括 Producer(生产者)、Consumer(消费者)、Broker(代理节点)、Topic(主题)、Partition(分区)、Leader Replica(领导者副本)、Follower Replica(跟随者副本)、LEO(Log End Offset,日志结束偏移量)、HW(High Watermark,高水位)、Consumer Group(消费者组)等。下篇文章再接着介绍 Kafka 如何解决消息丢失、重复消费、顺序消息、持久化消息、Leader 选举过程等。