1.I/O软件的层次结构
- 通常把 I/O 软件组织成四个层次:
-
用户层 I/O 软件。实现与用户交互的接口,用户可直接调用该层所提供的、与 I/O 操作有关的库函数对设备进行操作。
-
设备独立性软件。用于实现用户程序与设备驱动器的统一接口、设备命名、设备的保护以及设备的分配与释放等,同时为设备管理和数据传送提供必要的存储空间。
-
设备驱动程序。与硬件直接相关,用于具体实现系统对设备发出的操作指令,驱动 I/O 设备工作的驱动程序。
-
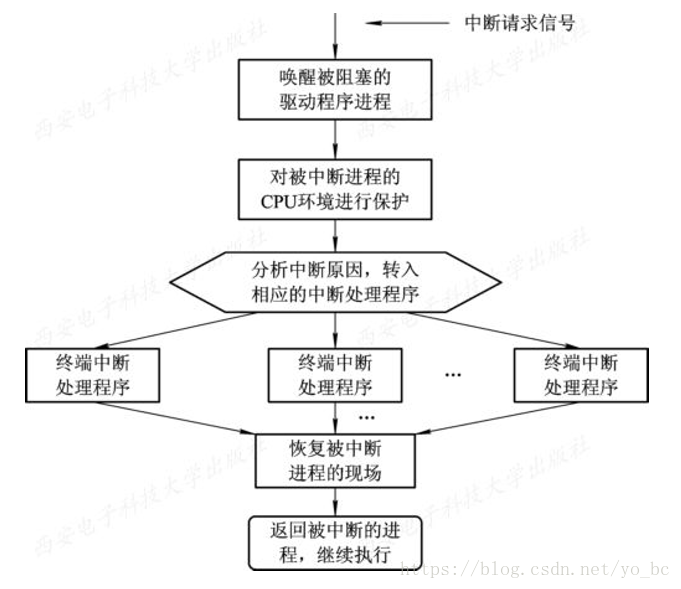
中断处理程序。CPU 先保护被中断进程的 CPU 环境,再转入相应的的中断处理程序进行处理,处理完毕后 CPU 再恢复被中断进程的现场,返回到被中断的进程。
2.中断机构和中断处理程序
中断在操作系统中有着特殊重要的地位,它是多道程序得以实现的基础,没有中断,就不可能实现多道程序,因为进程之间的切换是通过中断来完成的。另一方面,中断也是设备管理的基础,为了提高处理机的利用率和实现CPU与I/O设备并行执行,也必需有中断的支持。
-
中断和陷入
- 中断,是指CPU对I/O设备发来的中断信号的响应。由外部设备引起,故又称为外中断。
- 陷入,是由CPU内部事件引起的中断,如程序出错等等,故又称为内中断。
- 中断和陷入的主要区别是信号的来源,即是来自 CPU 外部,还是 CPU 内部。
-
中断向量表和中断优先级
- 中断向量表:
- 通常是为每种设备配以相应的中断处理程序,并把该程序的入口地址放在中断向量表中的一个表项,并为每一个设备的中断请求规定一个中断号,它直接对应于中断向量表的一个表项。当 I/O 设备发来中断请求信号时,由中断控制器确定该请求的中断号,并去查找中断向量表取得设备中断处理程序的入口地址,这样便可转入中断处理程序执行。
- 中断优先级:
-
对多中断源的处理方式
- 屏蔽(禁止)中断
- 类似于关中断,当处理机正在处理一个中断时,将屏蔽掉所有的中断,让它们等待。直到处理机处理完本次中断后,再去检查是否有中断发生。
- 嵌套中断
- CPU 优先响应最高优先级的中断请求。高优先级的中断请求可以抢占正在运行的低优先级中断的处理机。
-
中断处理程序
- 中断处理程序是I/O系统中最低的一层,它是整个I/O系统的基础。中断机构的处理过程:
- CPU测定是否有未响应的中断信号。程序每当执行完当前指令后,处理机都要测试是否有未响应的中断信号。
- 保护被中断进程的CPU环境。
- 转入相应的设备处理程序。由处理机对各个中断源进行测试,以确定引起本次中断的 I/O 设备,并向提供中断信号的设备发送确认信号。在该设备收到确认信号后,就立即取消它所发出的中断请求信号。然后,将相应的设备中断处理程序的入口地址装入到程序计数器中。这样,当处理机运行时,便可自动地转向中断处理机程序。
- 中断处理。
- 恢复CPU现场并退出中断。
3.设备驱动程序
设备处理程序通常又称为设备驱动程序,它是I/O系统的高层与设备控制器之间的通信程序,其主要任务是接收上层软件发来的抽象I/O要求,如read或write命令,再把它转换为具体要求后,发送给设备控制器,启动设备去执行;反之,它也将由设备控制器发来的信号传送给上层软件。由于驱动程序与硬件密切相关,故通常应为每一类设备配置一种驱动程序。
在多道程序系统中,驱动程序一旦发出 I/O 命令,启动了一个 I/O 操作后,驱动程序便把控制返回给 I/O 系统,把自己阻塞起来,直到中断到来时再被唤醒。具体的 I/O 操作是在设备控制器的控制下进行的,因此,在设备忙于传送数据时,处理机又可以去干其它的事情,实现了处理机与 I/O 设备的并行操作。
对I/O设备的控制方式
-
使用轮询的可编程I/O方式
- 处理机对 I/O 设备的控制采取轮询的可编程I/O方式,即在处理机向控制器发出一条 I/O 指令启动输入设备输入数据时,要同时把状态寄存器中的忙/闲标志 busy 置为 1,然后便不断地循环测试 busy。当 busy=1 时,表示输入机尚未输完一个字(符),处理机应继续对该标志进行测试,直至 busy=0,表明输入机已将输入数据送入控制器的数据寄存器中。于是处理机将数据寄存器中的数据取出,送入内存指定单元中,这样便完成了一个字(符)的 I/O。接着再去启动读下一个数据,并置 busy=1。
-
使用中断的可编程I/O方式
- 采用中断的可编程I/O方式,即当某进程要启动某个 I/O 设备工作时,便由 CPU 向相应的设备控制器发出一条 I/O 命令,然后立即返回继续执行原来的任务。设备控制器于是按照该命令的要求去控制指定 I/O 设备。此时,CPU 与 I/O 设备并行操作。一旦数据进入数据寄存器,控制器便通过控制线向 CPU 发送一中断信号,由 CPU 检查输入过程中是否出错,若无错,便向控制器发送取走数据的信号,然后再通过控制器及数据线将数据写入内存指定单元中。适用于低速流设备,如键盘,鼠标。
-
直接存储器(DMA)访问方式
- 中断驱动 I/O 比程序 I/O 方式更有效,但须注意,它仍是以字(节)为单位进行 I/O 的,每当完成一个字(节)的 I/O 时,控制器便要向 CPU 请求一次中断。换言之,采用中断驱动 I/O 方式时的 CPU 是以字(节)为单位进行干预的。
- 从而引入直接存储器访问方式,其特点如下:
- 数据传输的基本单位是数据块,即在 CPU 与 I/O 设备之间,每次传送至少一个数据块;
- 所传送的数据是从设备直接送入内存的,或者相反;
- 仅在传送一个或多个数据块的开始和结束时,才需 CPU 干预,整块数据的传送是在控制器的控制下完成的。
-
I/O通道控制方式
- I/O 通道方式是 DMA 方式的发展,它可进一步减少 CPU 的干预,即把对一个数据块的读(或写)为单位的干预减少为对一组数据块的读(或写)及有关的控制和管理为单位的干预。同时,又可实现 CPU、通道和 I/O 设备三者的并行操作。而通道能与 I/O 设备并行是因为 I/O 通道实际上是一种特殊的处理机,它具有执行 I/O 指令的能力,并通过执行通道 I/O 程序来控制 I/O 操作。增设 I/O 通道的主要目的是为了建立独立的 I/O 操作,或者说是使一些原来由 CPU 处理的 I/O 任务转由通道来承担。
4.与设备无关的I/O软件
为了方便用户和提高OS的可适应性与可扩展性,在现代OS的I/O系统中,都无一例外地增加了与设备无关的I/O软件,以实现设备独立性,也称为设备无关性。其基本含义是:应用程序中所用的设备,不局限于使用某个具体的物理设备。这是在设备驱动程序之上设置的一层软件,称为与设备无关的I/O软件,或设备独立性软件。
- 通过在系统配置:
- ①设备控制表 DCT;
- ②控制器控制表 COCT;
- ③通道控制表 CHCT;
- ④系统设备表 SDT;
- 实现都独占设备的分配。
- 同时,在系统中需要配置一张逻辑设备表 LUT,用于将逻辑设备名映射为物理设备名。】
5.用户层的 I/O 软件
一般而言,大部分的 I/O 软件都在操作系统内部,但仍有一小部分在用户层,包括系统调用、与用户程序链接在一起的库函数,以及完全运行于内核之外的假脱机系统等。
假脱机(Spooling)系统
如果说可以通过多道程序技术将一台物理CPU 虚拟为多台逻辑 CPU,从而允许多个用户共享一台主机,那么,通过 SPOOLing 技术便可将一台物理 I/O 设备虚拟为多台逻辑 I/O 设备,同样允许多个用户共享一台物理 I/O设备。
-
假脱机技术
- 脱机输入、脱机输出技术。该技术是利用专门的外围控制机,先将低速I/O设备上的数据传送到高速磁盘上,或者相反。
- 事实上,当系统中引入了多道程序技术后,完全可以利用其中的一道程序,来模拟脱机输入时的外围控制机功能,把低速 I/O 设备上的数据传送到高速磁盘上;再用另一道程序来模拟脱机输出时外围控制机的功能,把数据从磁盘传送到低速输出设备上。这样,便可在主机的直接控制下,实现脱机输入、输出功能。此时的外围操作与 CPU 对数据的处理同时进行,我们把这种在联机情况下实现的同时外围操作称为 SPOOLing,或称为假脱机操作。
-
SPOOLing 系统的组成
- 输入井和输出井
- 这是在磁盘上开辟的两个存储空间。输入井是模拟脱机输入时的磁盘设备;输出井是模拟脱机输出时的磁盘。
- 输入缓冲区和输出缓冲区
- 为了缓和 CPU 和磁盘之间速度不匹配的矛盾,在内存中要开辟两个缓冲区:输入缓冲区和输出缓冲区。输入缓冲区用于暂存由输入设备送来的数据,以后再传送到输入井。输出缓冲区用于暂存从输出井送来的数据,以后再传送给输出设备。
- 输入进程和输出进程
- 输入进程也称为预输入进程,用于模拟脱机输入时的外围控制机。输出进程也称为预输出进程,用于模拟脱机输出时的外围控制机。
- 井管理程序
- 用于控制作业与磁盘井之间信息的交换。当作业执行过程中向某台设备发出启动输入或输出操作请求时,由操作系统调用井管理程序,由其控制从输入井读取信息或将信息输出至输出井。

-
SPOOLing系统的特点
- 提高了I/O的速度。
- 将独占设备改造为共享设备。
- 实现了虚拟设备功能。
-
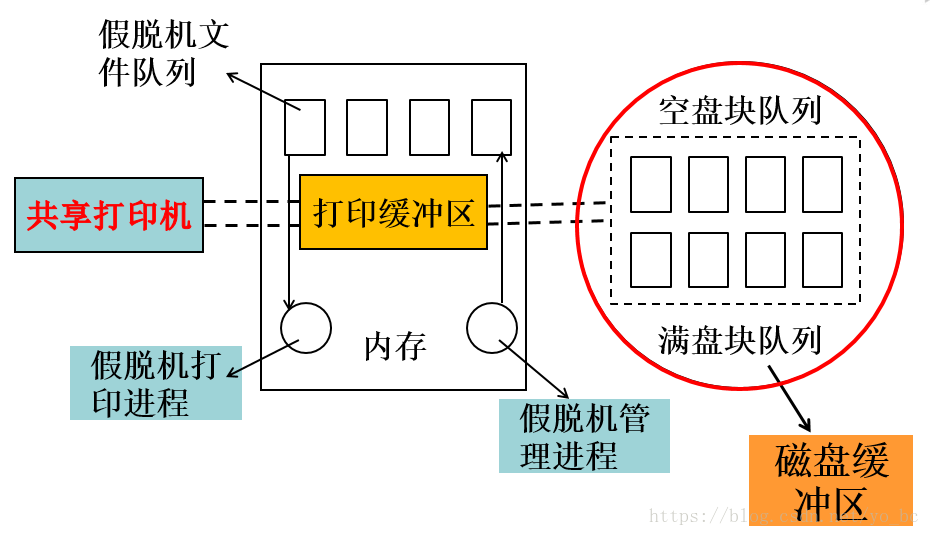
假脱机打印机系统
- 打印机是经常要用到的输出设备,属于独占设备。利用 SPOOLing 技术,可将之改造为一台可供多个用户共享的设备,从而提高设备的利用率。主要有以下三部分:
- 磁盘缓冲区
- 打印缓冲区
- 缓和 CPU 和磁盘之间速度不匹配的矛盾,设置在内存中,暂存从磁盘缓冲区送来的数据。
- 假脱机管理进程和假脱机打印进程
- 由假脱机管理进程为每个要求打印的用户数据建立一个假脱机文件,并把它放入假脱机文件队列中,由假脱机打印进程依次对队列中的文件进行打印。
- 每当用户进程发出打印输出请求时,由假脱机管理进程完成两项工作:①在磁盘缓冲区中为之申请一个空闲盘块,并将要打印的数据送入其中暂存;②为用户进程申请一张空闲的用户请求打印表,并将用户的打印要求填入其中,再将该表挂到假脱机文件队列上。
- 真正的打印输出是假脱机打印进程负责的,当打印机空闲时,该进程首先从假脱机文件队列的队首摘取一张请求打印表,然后根据表中的要求将要打印的数据由输出井传送到内存缓冲区,再交付打印机进行打印。
-
守护进程
- 除了假脱机打印机系统可以实现打印机共享,也可以为打印机建立一个守护进程。由守护进程执行一部分原来假脱机管理进程实现的功能。另一部分由请求进程自己完成,每个要求打印的进程先生成一份要求打印的文件,然后放入假脱机文件队列中。守护进程是按照目录中的文件依次来完成诸进程对该设备的请求的。
6.缓冲区管理
在现代操作系统中,几乎所有的I/O设备在与处理机交换数据时都用了缓冲区。
单缓冲区、双缓冲区、环形缓冲区、缓冲池。
缓冲的引入的原因
- 缓和CPU与I/O设备间速度不匹配的矛盾。
- 减少对CPU的中断频率,放宽对CPU中断响应时间的限制。
- 解决数据粒度不匹配的问题。
- 提高CPU和I/O设备之间的并行性。
单缓冲区
- 每当用户进程发起一次I/O请求,系统就在主存中分配一个缓冲区。假定从磁盘把一块数据输入到缓冲区 的时间为T,OS将该缓冲区中的数据传送到用户区的时间为M,而CPU对这一块数据处理计算的时间为 C。由于T和C是可以实现并行的,所以当T>C时,系统对每一块数据的处理时间为M+T,反之则为 M+C,故可以把系统对每一块数据处理时间表示为Max(C,T)+M.
- 简单的理解:单缓冲区的总体运行时间 = (磁盘块-1) * MAX(C,T) +磁盘块 * M + C + T
- 例题: 文件占38个磁盘块,设有一个缓冲区,磁盘块大小相同,一个磁盘块读入缓冲区的时间是230μs,将缓 冲区数据送到用户区的时间是10μs,读入并处理完该文件的时间是18090μs,单缓冲区结构,求CPU对 一块数据进行处理的时间
- 解:
- 得 37 * Max(C,230) + 38 * 10 + C + 230 = 18090
- 若C<=230,得到的数据很明显不对
- 若C>230,求得C=460μs
双缓冲区
- 为了加快输入输出速度,引入双缓冲机制,也称为缓冲对换。设备输入时,先送入第一缓冲区,装满后 转向第二缓冲区。此时系统可从第一缓冲区移出数据,送入用户进程,接着Cpu对数据进行计算。在双 缓冲时,系统处理一块数据的时间可以粗略地认为是Max(C,T),如果考虑M,则处理一块数据的时间为 Max(C+M,T) (更准确的:Max(C,T-M)+M)如果CT,则可使CPU 不必等待设备输入。
- 简单的理解:双缓冲区的总体运行时间 = (磁盘块 - 1) * Max(T,M+C) + T + M + C
- 例题: 一个文件占34个磁盘块,设一个缓冲区与磁盘块大小相同,将缓冲区的数据传送到用户区的时间是 50μs,CPU对一块数据进行处理的时间为180μs,读入并处理完该文件的时间是12810μs,在双缓冲区 的结构下,求把一个磁盘块读入缓冲区的时间
- 解:
- 得 33 * Max(T,180+50) + T + 50 + 180 = 12810
- 同上,最终求得T = 370μs
环形缓冲区
当输入与输出的速度基本相匹配时,采用双缓冲能获得较好的效果,可使生产者和消费者基本上能并行 操作。但当两者的速度相差很远时,双缓冲的效果很不理想,因此引入环形缓冲区 在环形缓冲区中包括多个缓冲区,每个缓冲区的大小相同,作为输入的多缓冲区可分为三类:用于装输 入数据得空缓冲区,已装满数据的缓冲区G,计算进程正在使用的现行工作缓冲区C。
缓冲池
既可以用于输入也可以用于输出的公用缓冲池,在池找那个设置了多个可供若干个进程共享的缓冲区 缓冲池和缓冲区的区别:缓冲区仅仅是一组内存块的链表,而缓冲池则是包含了一个管理的数据结构以 及一组操作函数的管理机制,用于管理多个缓冲区。
7.磁盘存储器地性能和调度
改善磁盘系统的性能
- 选择好的磁盘调度算法,以减少磁盘的寻道时间。
- 提高磁盘 I/O 速度,以提高对文件的访问速度。
- 采取冗余技术,提高磁盘系统的可靠性,建立高度可靠的文件系统。
磁盘性能简述
-
数据的组织和格式
- 磁盘设备可包括一个或多个物理盘片,每个磁盘片分一个或两个存储面(Surface),每个盘面上有若干个磁道(Track),磁道之间留有必要的间隙(Gap)。为使处理简单起见,在每条磁道上可存储相同数目的二进制位。 这样,磁盘密度即每英寸中所存储的位数,显然是内层磁道的密度较外层磁道的密度高。每条磁道又被逻辑上划分成若干个扇区(sectors),软盘大约为 8~32 个扇区,硬盘则可多达数百个,图中显示了一个磁道分成 8 个扇区。一个扇区称为一个盘块(或数据块),常常叫做磁盘扇区。各扇区之间保留一定的间隙。
-
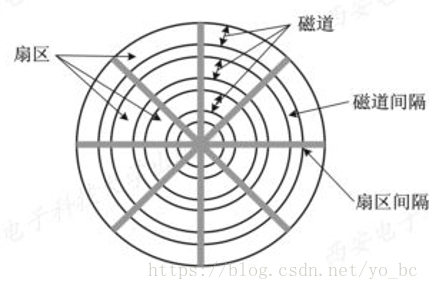
- 磁盘上存储的物理记录块数目是由扇区数、磁道数以及磁盘面数所决定的。
- 为了在磁盘上存储数据,必须先将磁盘低级格式化。下图示出了一种温盘(温切斯特盘)中一条磁道格式化的情况。
-
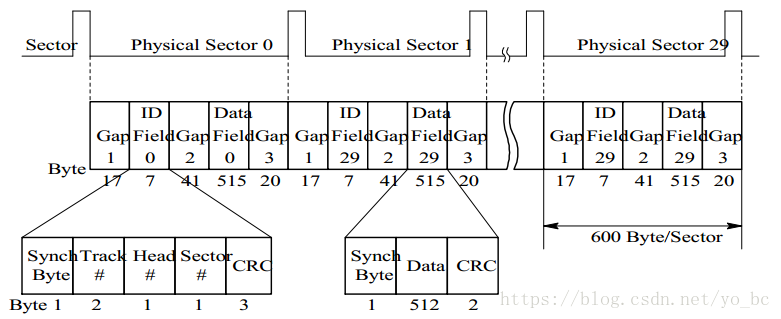
- 其中每条磁道含有 30 个固定大小的扇区,每个扇区容量为 600 个字节,其中 512 个字节存放数据,其余的用于存放控制信息。
- 每个扇区包括两个字段:
- 标识符字段(ID Field),其中一个字节的 SYNCH 具有特定的位图像,作为该字段的定界符,利用磁道号(Track)、 磁头号(Head #)及扇区号(Sector #)三者来标识一个扇区;CRC 字段用于段校验。
- 数据字段(Data Field),其中可存放 512 个字节的数据。
- 但是,在真正可以使用磁盘前,还需要对磁盘进行一次高级格式化,即设置一个引导块、空闲存储管理、根目录和一个空文件系统,同时在分区表中标记该分区所使用的文件系统。
-
磁盘的类型
- 对磁盘,可以从不同的角度进行分类。最常见的有:将磁盘分成硬盘和软盘、单片盘和多片盘、固定头磁盘和活动头(移动头)磁盘等。
- 固定头磁盘。在每条磁道上都有一读/写磁头,所有的磁头都被装在一刚性磁臂中。这种结构的磁盘主要用于大容量磁盘上。
- 移动头磁盘。每一个盘面仅配有一个磁头,也被装入磁臂中。为能访问该盘面上的所有磁道,该磁头必须能移动以进行寻道。广泛应用于中小型磁盘设备中,在微型机上配置的温盘和软盘都采用移动磁头结构。
-
磁盘访问时间
- 寻道时间 Ts,这是指把磁臂(磁头)移动到指定磁道上所经历的时间。
- 旋转延迟时间 Tr,这是指定扇区移动到磁头下面所经历的时间。
- 传输时间 Tt,这是指把数据从磁盘读出或向磁盘写入数据所经历的时间。
早期的磁盘调度算法
由于在访问磁盘的时间中,主要是寻道时间,因此,磁盘调度的目标是使磁盘的平均寻道时间最少。
-
先来先服务 FCFS
- 根据进程请求访问磁盘的先后顺序进行调度,此算法的优点是公平、简单,且每个进程的请求都能依次 得到处理,不会出现某一进程的请求长期得不到满足的情况。但此算法由于未对寻道进行优化,致使平 均寻道时间可能较长
-
| 初始位置 |
100 |
| 磁道编号 |
移动距离 |
| 55 |
45 |
| 58 |
3 |
| 39 |
19 |
| 18 |
21 |
| 90 |
72 |
| 160 |
70 |
| 150 |
10 |
| 38 |
112 |
| 184 |
146 |
| 平均寻道长度 |
55.3 |
-
最短寻道时间优先
- 该算法选择这样的进程:其要求访问的磁道与当前磁头所在的磁道距离最近,以使每次的寻道时间最短。但这种算法不能保证平均寻道时间最短。
-
| 初始位置 |
100 |
| 磁道编号 |
移动距离 |
| 90 |
10 |
| 58 |
32 |
| 55 |
3 |
| 39 |
16 |
| 38 |
1 |
| 18 |
20 |
| 150 |
132 |
| 160 |
10 |
| 184 |
24 |
| 平均寻道长度 |
27.5 |
基于扫描的磁盘调度算法
-
扫描(SCAN)算法(电梯算法)
- 扫描算法不仅考虑到欲访问的磁道与当前磁道间的距离,更优先考虑的是磁头当前的移动方向。例如,当磁头正在自里向外移动时,SCAN 算法所考虑的下一个访问对象,应是其欲访问的磁道既在当前磁道之外,又是距离最近的。这样自里向外地访问,直至再无更外的磁道需要访问时,才将磁臂换向为自外向里移动。这时,同样也是每次选择这样的进程来调度,即要访问的磁道在当前位置内且距离最近者。
- 由于在这种算法中磁头移动的规律颇似电梯的运行,因而又常称之为电梯调度算法。
-
| 初始位置 |
100 |
| 磁道编号 |
移动距离 |
| 150 |
50 |
| 160 |
10 |
| 184 |
24 |
| 90 |
94 |
| 58 |
32 |
| 55 |
3 |
| 39 |
16 |
| 38 |
1 |
| 18 |
20 |
| 平均寻道长度 |
27.5 |
-
循环扫描(CSCAN)算法
- 循环扫描算法是对扫描算法的改进。如果对磁道的访问请求是均匀分布的,当磁头到达磁盘的一端,并反向运动时落在磁头之后的访问请求相对较少。这是由于这些磁道刚被处理,而磁盘另一端的请求密度相当高,且这些访问请求等待的时间较长,为了解决这种情况,循环扫描算法规定磁头单向移动。例如,只自里向外移动,当磁头移到最外的被访问磁道时,磁头立即返回到最里的欲访磁道,即将最小磁道号紧接着最大磁道号构成循环,进行扫描。