单机查询流程
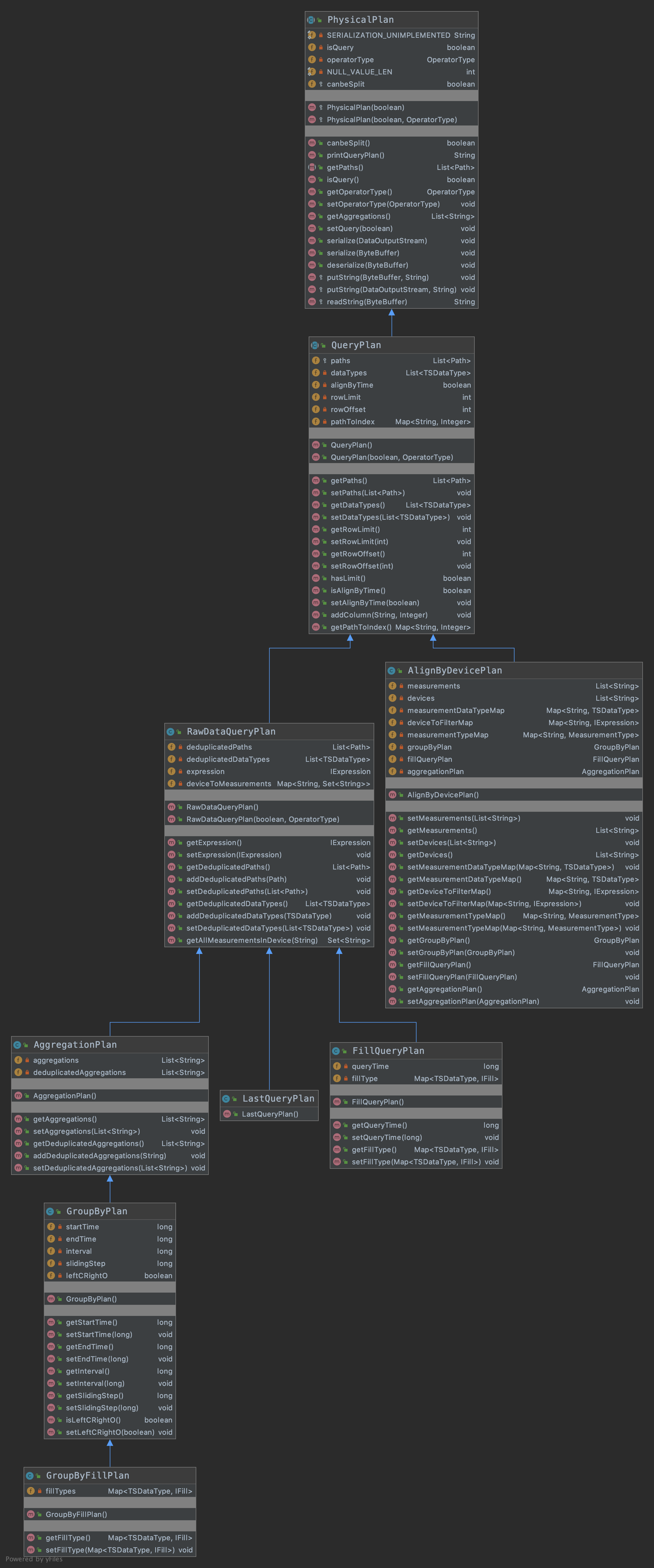
QueryPlan类:
QueryPlan是有关查询相关的类,所有的plan都继承了PhysicalPlan这个虚类,QueryPlan也是一个虚类。其UML类图如下所示:
IotDB中的各种reader
此章节请酌情参考查询基础组件
下面分别进行讲解一下:
Tsfile模块的reader
PointReader
PointReader, 顾名思义是查询一个点的reader,一个点也就是一条记录,即<time,value>的一个pari。其类图如下所示:
1 2 3 4 5 6 7 8 9 10 // 是否有下一个time value 对 boolean hasNextTimeValuePair() throws IOException; // 下一个time value 对 TimeValuePair nextTimeValuePair() throws IOException; // 当前的time value 对 TimeValuePair currentTimeValuePair() throws IOException; void close() throws IOException;
其实现类只有一个就是BatchDataIterator,只有如下一个属性:
1 private BatchData batchData;
实际上就是对这个BatchData进行操作。batchData是一些的<time,value>对的集合,所以PointReader就是从这个BatchData中取出特定的数据然后封装为TimeValuePair返回。
PageReader 是读取一个page所有的数据,其主要方法如下:
1 2 3 4 5 6 7 8 9 10 // 返回这个page所有满足的数据 BatchData getAllSatisfiedPageData() throws IOException; // 返回这个page的一些元数据 Statistics getStatistics(); // filter是查询这个page的一个过滤条件 void setFilter(Filter filter); boolean isModified();
ChunkReader
1 2 3 4 5 6 7 8 9 10 // 是否还有下一个page boolean hasNextSatisfiedPage() throws IOException; // 获取下一个page数据 BatchData nextPageData() throws IOException; void close() throws IOException; // 这个chunk所有的page reader List<IPageReader> loadPageReaderList() throws IOException;
BatchReader
BatchReader 实际上就是读取一个时序的接口。其UML类图如下所示(个人认为FileSeriesReaderByTimestamp这个类应该继承自FileSeriesReader,就跟ChunkReade与ChunkReaderByTimestamp一样 )。
1 2 3 4 5 6 7 // 判断是否还具有下一个batch data boolean hasNextBatch() throws IOException; // 获取下一个batch data BatchData nextBatch() throws IOException; void close() throws IOException;
AbstractFileSeriesReader 类主要属性如下:
1 2 3 4 5 6 7 8 9 // 加载chunk protected IChunkLoader chunkLoader; // 所有的需要读取的chunk 元数据信息 protected List<ChunkMetadata> chunkMetadataList; // chunk reader protected ChunkReader chunkReader; private int chunkToRead; protected Filter filter;
FileSeriesReader 与 FileSeriesReaderByTimestamp的区别是:FileSeriesReaderByTimestamp中保存了一个timestamp,相当于每次查询的时候多了一个过滤条件,判断当前chunk 的endtime 是否大于此timestamp。
总结
通过以上可以看出:
BatchReader实际上封装了对一个时序的读取,BatchReader里面有很多的chunk,最终的读取也是转化为了ChunkReader的读取;
ChunkReader封装了多个PageReader,最终的读取也是调用了PageReader读取。
PageReader 负责对整个Page进行过滤(如果有过滤条件的话)读取,然后满足条件的BatchData。
PointReader 封装了对一条记录的读取,其实也就是封装了对BatchData的读取。其实这个类主要用在了iotdb-server中,tsfile中并没有用到
Server模块的reader
原始数据查询接口
原始数据查询接口,返回 BatchData,可带时间过滤条件或值过滤条件,两种过滤不可同时存在
IBatchReader接口函数如下:
1 2 3 4 5 // 判断是否还有 BatchData boolean hasNextBatch() throws IOException; // 获得下一个 BatchData,并把游标后移 BatchData nextBatch() throws IOException;
使用流程如下:
1 2 3 4 5 6 while (batchReader.hasNextBatch()) { BatchData batchData = batchReader.nextBatch(); // use batchData to do some work ... }
实现类是SeriesRawDataBatchReader,主要属性和方法如下:
1 2 3 4 5 6 7 8 // 这是这个类的精髓所在,所有的数据的读取都是由seriesReader发起的。 private final SeriesReader seriesReader; private boolean hasRemaining; private boolean managedByQueryManager; private BatchData batchData; private boolean hasCachedBatchData = false;
主要方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 /** * This method overrides the AbstractDataReader.hasNextOverlappedPage for pause reads, to achieve * a continuous read */ @Override public boolean hasNextBatch() throws IOException { // 首先判断是否还有缓存好的数据。如果有则直接消费 if (hasCachedBatchData) { return true; } /* * consume page data firstly */ // 读page的数据 if (readPageData()) { hasCachedBatchData = true; return true; } /* * consume chunk data secondly */ // 读chunk的数据 if (readChunkData()) { hasCachedBatchData = true; return true; } /* * consume next file finally */ // 读文件的数据 while (seriesReader.hasNextFile()) { if (readChunkData()) { hasCachedBatchData = true; return true; } } return hasCachedBatchData; } @Override // 很简单,无需多说。 public BatchData nextBatch() throws IOException { if (hasCachedBatchData || hasNextBatch()) { hasCachedBatchData = false; return batchData; } throw new IOException("no next batch"); }
聚合查询接口
聚合查询接口 (主要用于聚合查询和降采样查询)
SeriesAggregateReader类中属性就一个,也是最重要的一个就是SeriesReader,所有的方法也都是调用的SeriesReader的方法。
按递增时间戳查询
按递增时间戳查询对应值的接口(主要用于带值过滤的查询)
其接口如下:
1 2 // 获取此timestamp对应的value Object getValueInTimestamp(long timestamp) throws IOException;
其实现类主要有3种:ByTimestampReaderAdapter、DiskChunkReaderByTimestamp以及SeriesReaderByTimestamp。
ByTimestampReaderAdapter
1 2 3 4 private IPointReader pointReader; // only cache the first point that >= timestamp private boolean hasCached; private TimeValuePair pair;
ByTimestampReaderAdapter 属性有以上三个,其实现主要是通过调用IPointReader的函数来实现的。
DiskChunkReaderByTimestamp
1 2 private ChunkReaderByTimestamp chunkReaderByTimestamp; private BatchData data;
DiskChunkReaderByTimestamp 主要属性有上面两个,其主要实现也是通过DiskChunkReaderByTimestamp的函数实现的。
SeriesReaderByTimestamp
1 2 private SeriesReader seriesReader; private BatchData batchData;
SeriesReaderByTimestamp 主要属性有上面两个,其主要实现也是通过SeriesReader中的函数来实现的。
Cluster模块的reader
BatchData类:
封装了存取数据的一些操作。
本质上是一个二维的数组List<Object[]>,第一维是list,长度可变,长度无限制;第二维是长度初始为16,最大为1000的数组,在没超过阈值1000的情况下,会以2倍的速度扩张。如果达到了阈值1000,则会调用list.add(Object[]),此时object数组的长度就是1000了。
SeriesReader类分析
参考http://iotdb.apache.org/zh/SystemDesign/5-DataQuery/2-SeriesReader.html
数据按照粒度从大到小分成五种:文件,TimeSeriesMetadata,Chunk,Page,相交数据点。在原始数据查询中,最大的数据块返回粒度是一个 page,如果一个 page 和其他 page 由于乱序写入相互覆盖了,就解开成数据点做合并。聚合查询中优先使用 Chunk 的统计信息,其次是 Page 的统计信息,最后是相交数据点。
设计原则是能用粒度大的就不用粒度小的。
SeriesReader类中几个重要的字段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 /* * file cache,文件层的cache,分别保存了顺序和乱序的一些文件描述 */ private final List<TsFileResource> seqFileResource; private final List<TsFileResource> unseqFileResource; /* * TimeSeriesMetadata cache */ // 第一个TimeSeriesMetadata,这个是开始时间最小的那个timeseriesMeta private TimeseriesMetadata firstTimeSeriesMetadata; // 保存了顺序文件的TimeseriesMetadata private final List<TimeseriesMetadata> seqTimeSeriesMetadata = new LinkedList<>(); // 保存了乱序文件的TimeseriesMetadata,是一个优先级队列,按照开始时间排序 private final PriorityQueue<TimeseriesMetadata> unSeqTimeSeriesMetadata = new PriorityQueue<>(Comparator.comparingLong(timeSeriesMetadata -> timeSeriesMetadata.getStatistics().getStartTime())); /* * chunk cache */ // 开始时间最小的那个chunkMetaData private ChunkMetadata firstChunkMetadata; // 按照开始时间的一个优先级队列,保存ChunkMetaData。 private final PriorityQueue<ChunkMetadata> cachedChunkMetadata = new PriorityQueue<>(Comparator.comparingLong(ChunkMetadata::getStartTime)); /* * page cache */ // 开始时间最小的那个VersionPageReader private VersionPageReader firstPageReader; // 按照开始时间的一个优先级队列,保存的VersionPageReader。 private PriorityQueue<VersionPageReader> cachedPageReaders = new PriorityQueue<>(Comparator.comparingLong(VersionPageReader::getStartTime)); /* * point cache */ // 相交数据点层 private PriorityMergeReader mergeReader = new PriorityMergeReader(); /* * result cache,相交数据点产出结果的缓存 */ // 是否缓存了下一个batch private boolean hasCachedNextOverlappedPage; // 缓存的下一个batch的引用 private BatchData cachedBatchData;
重点函数分析
基本上读操作的流程如下:
1 2 3 4 5 6 7 8 9 while (seriesReader.hasNextFile()) { // do something while (seriesReader.hasNextChunk()) { // do something while (seriesReader.hasNextPage()) { // do something } } }
下面就会分析上述三个方法。
hasNextFile
判断本文件是否读完:如果firstPageReader还没读完,或是相交数据点还有数据,或是cachedPageReaders不为空,则说明上一个文件还未读完。则抛出异常。
判断本chunk是否读完:如果firstChunkMetadata != null||!cachedChunkMetadata.isEmpty(),则抛出异常。
判断是否还有文件。如果firstTimeSeriesMetadata != null,则返回true,否则执行第4步。
走到这里说明已经解开的page、chunk、page都读完了,所以需要解(unpack)下一个文件,会调用tryToUnpackAllOverlappedFilesToTimeSeriesMetadata函数解下一个文件。
第4步解完数据之后,在判断firstTimeSeriesMetadata != null,决定是否还有文件。
hasNextChunk
主要功能:判断该时间序列还有没有下一个chunk。
约束:在调用这个方法前,需要保证 SeriesReader 内已经没有 page 和 数据点 层级的数据了,也就是之前解开的 chunk 都消耗完了。
判断文件是否读完:与hasNextFile步骤1一致。(代码写的不好,没有把这个判断条件封装为一个函数 )
如果 firstChunkMetaData 不为空,则代表当前已经缓存了第一个 ChunkMetaData,且未被使用,直接返回true;
尝试去解开第一个顺序文件和第一个乱序文件,填充 chunk 层。并解开与 firstChunkMetadata 相重合的所有文件。原理与解开TimeSeriesMetadata一致。
解压所有重叠的seq/unseq文件,找到第一个TimeSeriesMetadata,因为在用户使用的场景中可能有太多的文件,无法一次性把所有的文件都打开,这可能导致OOM,所以一次只解压缩一个文件。
填充seqTimeSeriesMetadata,直到它不为空。如果seqTimeSeriesMetadata为空,则按序遍历seqFileResource,去获取此文件的timeseriesMetadata,直到找到一个timeseriesMetadata!=null, 然后加入到seqTimeSeriesMetadata中。备注:此时seqTimeSeriesMetadata长度长度为1
同理填充unSeqTimeSeriesMetadata,直到它不为空。
找出seqTimeSeriesMetadata和unSeqTimeSeriesMetadata两个中,开始时间最早的那个timeseriesMetadata。
然后调用unpackAllOverlappedTsFilesToTimeSeriesMetadata函数,遍历所有的seqFileResource和unseqFileResource,找出所有的和第3步的timeseriesMetadata有重叠的timeseriesMetadata,分别填充到seqTimeSeriesMetadata和unSeqTimeSeriesMetadata。
重叠的定义如下:只要这个file的开始时间小于第三步找到的那个timeseriesMetadata结束时间,则认为数据在时间上有重叠的。
从填充的seqTimeSeriesMetadata和unSeqTimeSeriesMetadata中,找出开始时间最早的那个作为firstTimeSeriesMetadata。(个人认为其实没必要,因为在第3步中已经找出来了 )
分布式查询流程
从Cli是怎么路由到IotDB Server处理?
Client模块 Client::main()函数,首先解析下host,port,username等参数,根据这些参数建立conn;
建立conn之后,走到了receiveCommands函数,此函数是一个while(true),处理用户输入的一些sql;
Client::receiveCommands->AbstractClient::processCommand->AbstractClient::handleInputCmd。(做一些参数解析(主要是help,SET_TIMESTAMP_DISPLAY,SET_TIME_ZONE等操作)) -> AbstractClient::executeQuery -> IoTDBStatement::execute ->IoTDBStatement::executeSQL
下面分析下IoTDBStatement中的executeSQL函数,此函数首先构造了一个TSExecuteStatementReq execReq,execReq封装了sql等信息,然后调用client.executeStatement(execReq)这个rpc接口,client就是调用的本地的单机的6667端口的JDBC服务。
executeStatement的处理逻辑
做一些参数校验,权限校验的工作。
解析SQL为PhysicalPlan。然后根据plan是query还是update,执行不同的分支,由于此篇文章讲解query的流程。所以会走到internalExecuteQueryStatement。这个函数的主要任务其实就是创建QueryDataSet,然后作为TSExecuteStatementResp的一个属性返回。
createQueryDataSet。最终调用了executor.processQuery,根据executor是ClusterPlanExecutor还是PlanExecutor,决定走cluster流程还是单机流程。(不过目前实现都是一样的)
processDataQuery。会根据query的种类(groupBy、groupByFill、Aggregate、FillQuery、LastQuery、RawDataQuery)等走不同的分支,在此以RawDataQueryPlan为例。
QueryRouter::rawDataQuery()
首先对之前生成PhysicalPlan一起生成的过滤表达式IExpression进行优化,具体的优化算法请参考:过滤条件和查询表达式
根据filter是GLOBAL_TIME(全局只有一个时间的过滤条件),还是有值的过滤条件,走不同的分支,我们以值过滤条件为例,走到了RawDataQueryExecutor::executeWithValueFilter()
创建TimeGenerator,这里面主要有3个属性:
HashMap<Path, List
> leafCache,根据过滤表达式IExpression构造出来的,key是seriesPath,value是List
,LeafNode是一个包装了一个IBatchReader的类;
Node operatorNode,是一个树,每个叶子节点都是一个LeafNode。
boolean hasOrNode,这颗树是否有or 节点。
上面提到LeafNode里面包含一个IBatchReader,那么这个IBatchReader是怎么创建的呢?请参考下面具体解析。
遍历所有的序列,为所有的序列调用getReaderByTimestamp创建SeriesReaderByTimestamp.
调用new RawQueryDataSetWithValueFilter()返回。
LeafNode中的IBatchReader创建逻辑
在TimeGenerator::construct函数中,调用了generateNewBatchReader来创建TimeGenerator,目前主要有3种实现:ClusterTimeGenerator、ServerTimeGenerator以及TsFileTimeGenerator。
对于每个leafNode,其对应一个SingleSeriesExpression,也对应一个IBatchReader
ClusterTimeGenerator::generateNewBatchReader
主要函数:MetaGroupMember::getSeriesReader,首先根据filter和path构造出List
。如果没有时间过滤条件,则需要广播到所有的partitionGroup;如果有时间过滤条件,则根据时间过滤条件计算出要查询的数据所在的partitionGroup:先找到partitionGroup所在的header(算法如下),然后在根据header找到partition Group。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void getIntervalHeaders(String storageGroupName, long timeLowerBound, long timeUpperBound, PartitionTable partitionTable, Set<Node> result) { // 获取配置的partitionInterval long partitionInterval = StorageEngine.getTimePartitionInterval(); // 计算时间下限用于计算slot id时间,之所以先除以partitionInterval,然后在乘以partitionInterval。 // 是因为在routeToHeaderByTime中根据path和time定位slot id的时候有这个逻辑:time / timePartitionInterval。 // 个人认为此处操作是多此一举,比如时间戳是10,partitionInterval是3,则最终计算出来的partitionInstance=10/3=3, 如果先开始10/3*3=9,然后在计算9/3还是3,所以此处转化没有用,唯一的用处就是后面计算都是整数了 long currPartitionStart = timeLowerBound / partitionInterval * partitionInterval; // 然后遍历,每次增加partitionInterval,直到上限达到timeUpperBound为止。 // 此处有性能不会有问题,因为凡是走到这里的,则时间过滤条件的上限和下限都是配置了的。 while (currPartitionStart <= timeUpperBound) { result.add(partitionTable.routeToHeaderByTime(storageGroupName, currPartitionStart)); currPartitionStart += partitionInterval; } }
为每个partition 构建一个SeriesReader。然后merge到ManagedMergeReader中,ManagedMergeReader维护了一个最小堆,根据reader的nextTimeValuePair的时间戳进行比较。
ServerTimeGenerator::generateNewBatchReader todo
TsFileTimeGenerator::generateNewBatchReader todo