
- 本文提出一种3D-to-3D转换方法:Instruct 3D-to-3D;
- 借助预训练的Image-to-Image扩散模型,本文方法可以使各个视角图片的似然最大;本文方法显式地将source 3D场景作为condition,可以有效提升3D连续性和可控性。
- 同时,本文还提出dynamic scaling,使得几何变换的强度是可调整的。
目录
Related Works
Text-to-3D models
Proposed Method
Pipeline of Instruct 3D-to-3D
Dynamic Scaling
Experiments
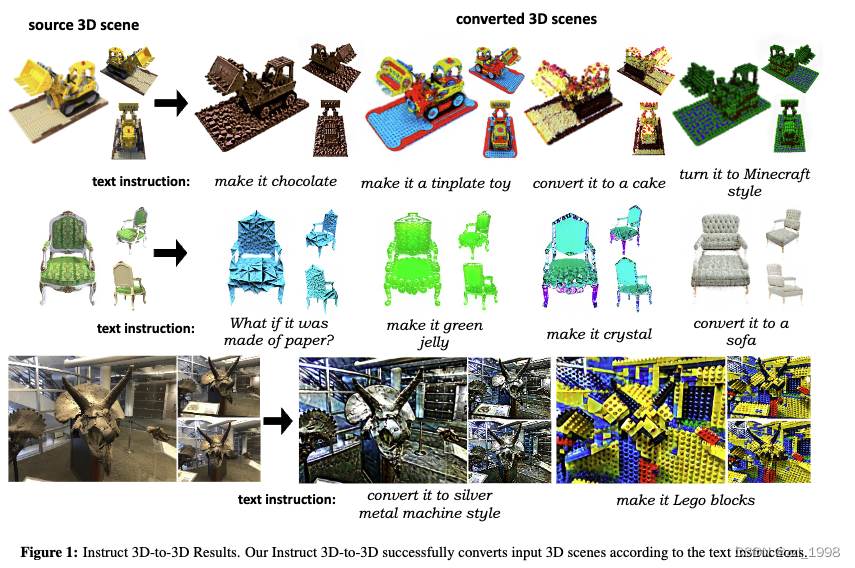
Qualitative Evaluations
Quantitative Evaluations
User Study
Sensitivity to the Scaling Strategy
Limitations
Text-to-3D models
DreamFields是第一个实现Text-to-3D的工作。DreamFields用CLIP引导生成,但是生成效果不佳。
DreamFusion是第一个将diffusion应用在Text-to-3D任务上的方法。对于任意输入图片,根据采样得到噪声和时间,生成噪声图像: 。噪声图像可用于计算损失的梯度:
。噪声图像可用于计算损失的梯度:

其中,y是文本描述。但是现有方法有两个问题:1)直接fine-tune 3D场景,可能到导致失去原3D场景的特征;2)需要对转换后的场景有详细的文本描述。
Proposed Method
Pipeline of Instruct 3D-to-3D

1. target model基于source model初始化;
2. 随机相机位姿c,用target model渲染目标图像I_tgt;将I_tgt送入StableDiffusion的encoder获得对应的隐码特征L_tgt。
3. 添加噪声: ;
;
4. 用source model和相机位姿c,渲染source image I_src;
5. 将x_t送入InstructPix2Pix,其中,source image I_src和text instruction y是控制条件。
6. 由于有两个控制条件,最后的噪声由下式求得,其中s_I和s_T是用于控制图片和文本控制强度的超参数。

7. 梯度可求得:

Dynamic Scaling
本文使用DVGO,该方法是一中voxel grid-based implicit 3D representations,以3D vocel grid的形式保留密度和颜色信息。
voxel grid是3D空间的离散部分,每个vertex描述颜色和密度信息。体渲染是基于射线周围vertices的插值信息求得。
3D场景的分辨率由voxels数量决定。DVGO中使用progressive scaling策略,在训练过程中逐步增加voxels数量:

本文中,vocels的数量初始化为N,但这会导致形状较难改变,因此本文提出dynamic scaling。该方法从N到N/2^l,逐渐减少voxels的数量,随后再逐渐恢复至N。图(3-b)展示了该过程。
Experiments
Qualitative Evaluations


Quantitative Evaluations
- 计算CLIP score和BRISQUE score

User Study

Sensitivity to the Scaling Strategy


Limitations
