Nanodet目标检测模型完成自动捡球机器人
从零开始,带你用Nanodet目标检测模型完成自动捡球机器人 - 古月居
开源地址:
https://github.com/Coolog/Nanodet-Robot-PathPlanning
作者提出 NanoDet-Plus,总结了上一代模型在标签分配、模型结构以及训练策略上的不足,提出了AGM和DSLA以及Ghost-PAN模块,并全面改进了训练策略,更加易于训练!同时也全面修改了模型部署时的输出方式,简化了结构,并提供了ncnn、MNN、OpenVINO以及安卓端的Demo,每个demo下都有非常详细的教程指导大家上手
目录
-
什么是动态匹配
-
动态匹配在小模型上的问题
-
NanoDet-Plus的训练辅助模块
01
前言
就在去年年底,NanoDet开源了,作为高性能的轻量级检测模型开源项目,不仅登上了GitHub trending第一,也收获了3700多的star,非常感谢支持的小伙伴们!在这过去的一年里也涌现出了非常多的轻量级模型,旷视的YOLOX-Nano,FaceBook的FBNetV5,百度的PPYOLO、PicoDet,都将NanoDet作为超越的对象,就连在开源界大热的YOLOv5也推出用于CPU的YOLOv5-n。
在被这么多模型给超越之后,NanoDet当然不能落后!在分析了上一代存在的不足之后,我对模型训练的标签匹配策略、多尺度特征融合以及训练Trick都进行了改进,终于赶在2021年的最后几天发布了NanoDet的最新升级版本,NanoDet-Plus!在同样的Backbone下,精度相较于上一代在COCO数据集上普遍提升了7mAP,且依旧在移动端保持着实时的推理速度。接下来,我将基于标签匹配策略优化、模型结构优化以及训练Trick优化这三个方面进行介绍。
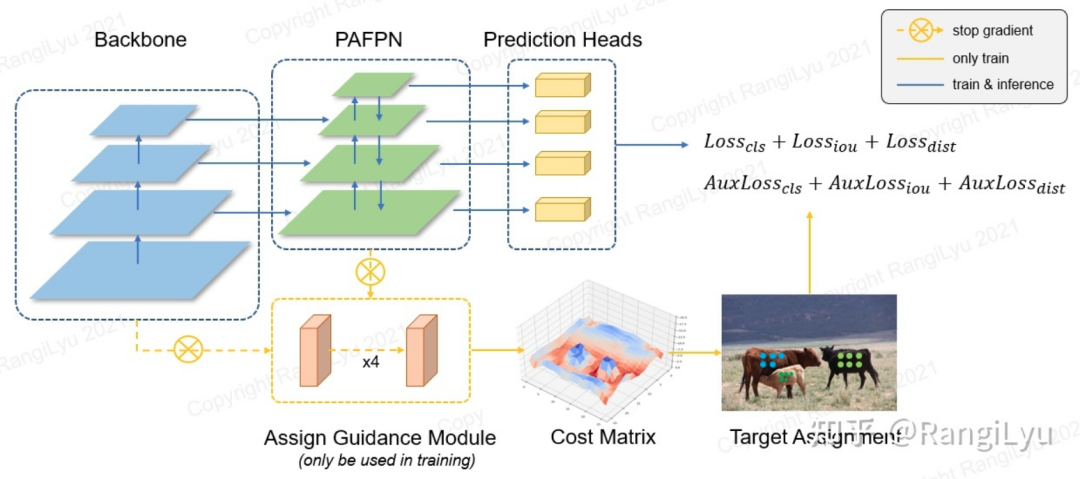
NanoDet-Plus整体架构图
02
标签匹配策略改进
标签匹配策略(Label Assignment)是目标检测模型训练中最核心的问题之一,从最早的直接基于位置的匹配,演化为目前最广泛应用的基于Anchor IOU的匹配,再到最近的基于Matching Cost的动态匹配,每一次的匹配策略的进化,都让目标检测的性能有了非常大的提升。上一代的NanoDet使用了ATSS作为匹配的算法,ATSS虽然会根据IOU的均值和方差为每一层feature map动态选取匹配样本,但其本质上依然是基于先验信息(中心点和anchor)的静态匹配策略。
今年的许多工作都将目光聚焦于全局的动态匹配策略上,比如DETR提出使用匈牙利匹配算法进行双边匹配,OTA提出使用Sinkhorn迭代求解匹配中的最优传输问题,YOLOX中使用OTA的近似算法SimOTA进行标签匹配。这些匹配策略都在大模型上取得了非常不错的效果,但是,在将基于Matching Cost的动态匹配应用到轻量级检测模型上时,却存在着大模型上所没有的的问题。
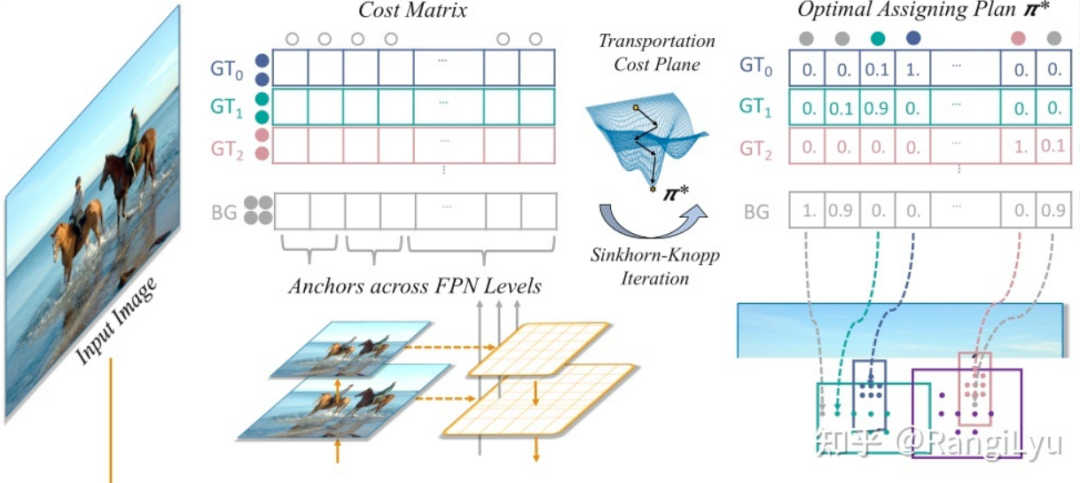
2.1 什么是动态匹配
在这之前先简单介绍一下什么是基于Matching Cost的动态匹配:简单来说,就是直接使用模型检测头的输出,与每一个Ground Truth计算一个匹配的代价,这个代价一般由分类loss和回归loss组成。Feature Map上所有的点(N个)的预测值与所有的Ground Truth(M个)计算得到的NxM的矩阵,就是所谓的Cost Matrix,基于这个Cost Matrix进行二分图匹配也好还是传输优化也好再或者直接取TopK也好,就是一种动态匹配策略。这种策略与之前的基于Anchor算IOU的匹配最大的不同就是,它不再只依赖先验的静态的信息,而是使用当前的预测结果去动态寻找最优的匹配,只要模型预测的越准确,匹配算法求得的结果也会更优秀。
看到这里,我们自然会想到一个问题,既然标签匹配需要依赖预测输出,但预测输出又是依赖标签匹配去训练的,但我的模型一开始是随机初始化的,啥也没有呀?那这不就成了一个鸡生蛋,蛋生鸡的问题了吗?不过好在神经网络天生具有抗噪能力,即使一开始随机初始化的时候给模型随机分配一些点去训练,只要这些点在对应的GT框内,模型也能够逐渐的去拟合那些最容易学到的特征。因此对于除了DETR这种稀疏预测以外,稠密的目标检测的动态标签匹配都会加上一些位置约束,比如OTA和SimOTA都使用了一个5x5的中心区域去限制匹配的自由程度。
2.2 动态匹配在小模型上的问题
在理解了动态匹配之后,我们再回过头来看小模型:由于小模型的检测头非常轻量,在NanoDet中只使用两个深度可分离卷积模块去同时预测分类和回归,和大模型中对分类和回归分别使用4组256channel的3x3卷积来说简直是天壤之别!让这样的检测头从随机初始化的状态去计算Matching Cost做匹配,这是不是有点太难为它了 。
于是我就在想,能不能设计一个学习能力更强的东西去引导小模型的检测头进行匹配呢?有人要说了,这不就是教师学生模型,不就是知识蒸馏(KD)吗?很巧的是,WACV上也有一篇paper做了这样的工作:LAD:Improving Object Detection by Label Assignment Distillation。链接为 https://arxiv.org/abs/2108.10520

LAD就是使用教师网络预测的结果去计算标签匹配,来指导学生网络训练。但是,KD存在的问题就是需要额外再训练一个教师模型,这就导致训练所需要的资源大大增加!那么有没有一个即插即用的小插件能够做这件事呢?其实,旷视在 CVPR 2021提出的IQDet,就使用了一个小模块,去对每个实例预测PAA中提出的高斯混合质量分布的三个参数来指导检测头的训练。但由于QDE需要先对Feature Map做ROI Align,也显得有一些复杂了。
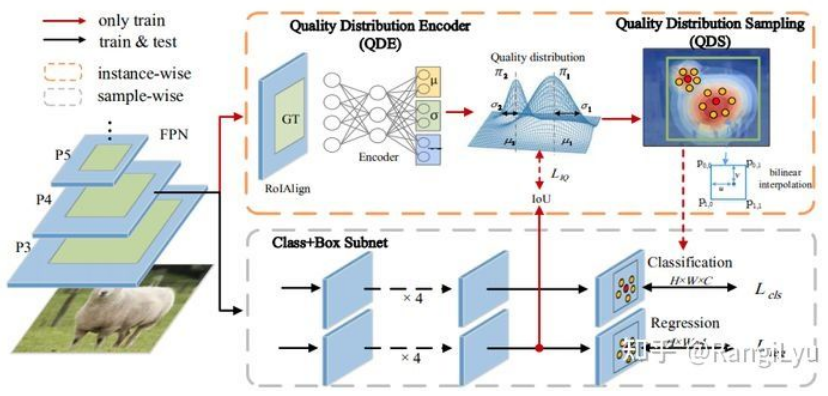
IQDet使用QDE预测质量分布
2.3 NanoDet-Plus的训练辅助模块
与之前的这些工作不同的是,NanoDet-Plus中设计了一种更为简单也更为轻量的训练辅助模块Assign Guidance Module(AGM)并配合动态的软标签分配策略Dynamic Soft Label Assigner(DSLA),来解决轻量级模型中的最优标签匹配问题。NanoDet-Plus的整体架构如下图所示:

NanoDet-Plus整体架构图
AGM仅由4个3x3的卷积组成,使用GN作为Normalize层,并在不同尺度的Feature Map间共享参数(其实就是大模型的检测头)。由于共享参数,且并非是深度可分离卷积(深度可分离卷积对GPU不友好),因此AGM所消耗的训练资源非常少,远远小于一个教师模型,而且这个模块只在训练时用到,训练完就直接扔了,完全不影响推理速度!可以说是非常友好的模块了!
使用AGM预测的分类概率和检测框会送入DSLA模块计算Matching Cost。Cost函数由三部分组成:classification cost,regression cost以及distance cost:
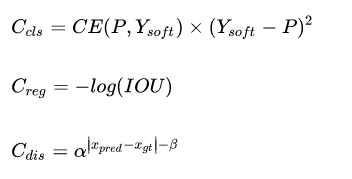
最终的代价函数就是这样:

其中distance cost也可以去掉,加上的话可以让AGM在前期收敛的更快,适合用在微调模型的场景。在上一代NanoDet上加入AGM和DSLA,在COCO数据集上提升了2.1 mAP。

03
模型结构改进
在上一代NanoDet中,使用了shufflenet v2 作为backbone,加上一个无卷积的PAFPN作为Neck,最后在检测头上合并分类和回归分支,且只使用两组深度可分离卷积。现在回过头来看这个模型,当时为了把模型的参数量控制在1M以内,所以去掉了neck里的全部卷积,这一操作还是太激进了,比较影响多尺度的特征融合的效果。
3.1 特征融合改进
在今年新出的这些轻量级模型如YOLOX和PicoDet,以及之前的YOLOv5中,都使用了CSP-PAN作为特征金字塔模块。因此,我也重新设计了一个非常轻量但性能不错的PAN:Ghost-PAN。Ghost PAN使用GhostNet中的GhostBlock作为处理多层之间特征融合的模块,其基本结构单元由一组1x1卷积和3x3的depthwise卷积组成,参数量和计算量都非常小。
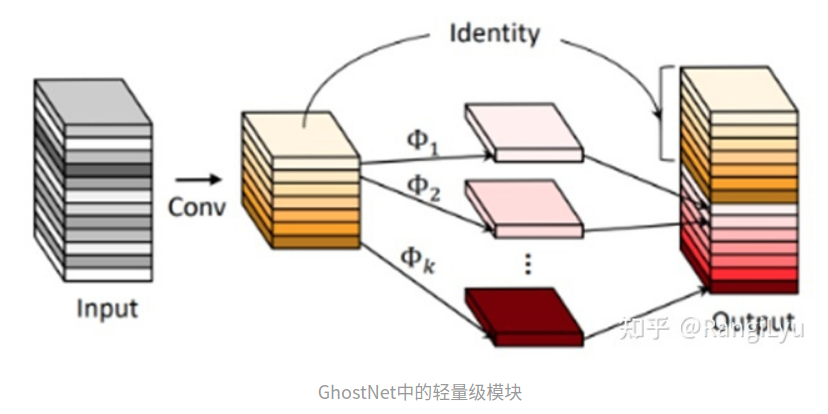
因此最终整个Ghost-PAN的参数量只有190k个参数,且在ARM上只增加了大概1ms的延时,x86端和GPU端的速度影响就更小了,但是小归小,它的性能一点也不差,在增加了GhostPAN后,模型的mAP提升了2个点!
3.2 检测头改进
ThunderNet的文章中提出,在轻量级模型中将深度可分离卷积的depthwise部分从3x3改成5x5,能够在增加较少的参数量的情况下提升检测器的感受野并提升性能。现在,在轻量级模型的depthwise部分增大kernel已经成为了非常通用的技巧,因此NanoDet-Plus也将检测头的depthwise卷积的卷积核大小也改成了5x5
PicoDet在原本NanoDet的3层特征基础上增加了一层下采样特征,为了能够赶上其性能,NanoDet-Plus中也采取了这种改进。这部分操作增加了大约0.7mAP。
3.3 Backbone改进
在过去的一年里,也涌现出了很多很强的轻量级检测backbone,比如FaceBook的FBNetV5和某度在PicoDet里使用的ESNet,这些backbone都依托网络结构搜索 Neural Architecture Search(NAS)的强大能力,在约束了计算量参数量和精度的搜索空间内搜出了非常强的backbone。
那么NanoDet-Plus在backbone上有什么改进吗?
很遗憾!对不起!我改进不了backbone
作为个人开发者,我没有能力像大厂那样能够花上几千GPU机时去搜索一个模型。这也是深度学习时代的一大壁垒——算力壁垒,算力霸权让普通研究者和个人开发者永远无法和大厂竞争。因此,我放弃了在backbone上和这些基于NAS的模型去竞争,还是基于上一代同样的backbone,将精力放在改进模型的其他部分。毕竟backbone是整个模型中最容易替换的部分了,改天把大厂们搜出来的backbone也替换进来就行了嘛(
04
训练Trick改进
友好,友好,友好!重要的事情要说三遍!
由于NanoDet是一个开源项目,而非刷点的论文,最终目的还是希望这个项目能够对使用者更加友好。上一代的NanoDet使用传统的SGD+momentum+MultiStepLr的方法训练模型。对老炼丹师来说,肯定还是觉得SGD比较香,配合MultiStepLr在第一阶段使用大学习率长时间训练后进行学习率衰减能有很大的涨幅。但是这种方法对新手来说还是太难调了!没有老炼丹师的经验,很容易导致模型不收敛或收敛不好。
因此,为了提升使用体验,NanoDet-Plus全面改进了训练策略:
优化器从SGD+momentum改成了对超参数更不敏感且收敛更快的AdamW;
学习率下降策略从MultiStepLr修改为了CosineAnnealingLR;
并且在反向传播计算梯度时加上了梯度裁剪,避免新手不会调参导致loss NAN;
除此之外,还加上了目前比较流行的模型平滑策略EMA。
加了这么多提升用户体验的方法,还不值得github给个Star加知乎点赞吗?
05
部署优化
上一代的NanoDet由于使用了多尺度的检测头,每层都有分类和回归两个输出,加上有三个尺度的特征图,这就导致了一共有6个输出,这对于不熟悉模型结构的人来说简直太不友好了!

因此,在NanoDet-Plus中,我将模型的输出数量减少到了一个!所有的输出tensor都事先reshape好,然后concatenate到一起,这么做虽然和之前相比要多一些操作,会略微影响模型的后处理速度,但是对不理解模型结构的人来说更加的友好。反过来说,如果已经对模型输出非常了解的人,那应该本身就已经是大佬了,把最后的输出用之前的方式优化一下应该也不成问题。
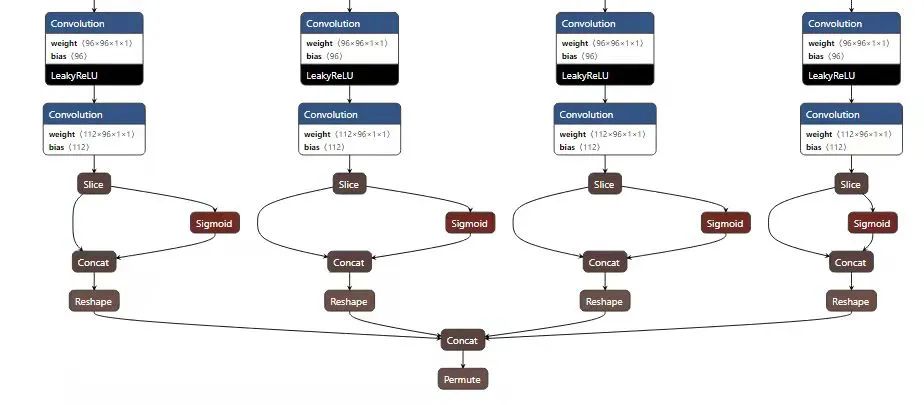
NanoDet-Plus的输出
在修改完模型输出之后,我对ncnn、MNN、OpenVINO以及安卓端的Demo的C++代码都进行了统一修改,这些部署后端的所有后处理代码基本都长一样,接口也保持一致,只要看懂了一个,其他几个就都能看懂。
06
总结
NanoDet-Plus总结了上一代模型在标签分配、模型结构以及训练策略上的不足,提出了AGM和DSLA以及Ghost-PAN模块,并全面改进了训练策略,更加易于训练!同时也全面修改了模型部署时的输出方式,简化了结构,并提供了ncnn、MNN、OpenVINO以及安卓端的Demo,每个demo下都有非常详细的教程指导大家上手。
最后再放一下NanoDet-Plus和其他模型的对比:
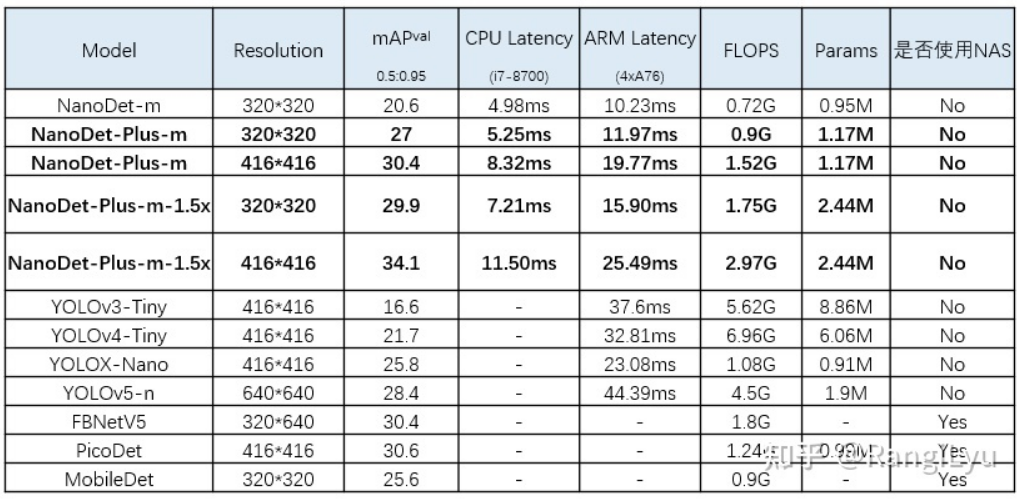
NanoDet与其他模型的性能对比
所有数据都是在4年前的老CPU八代i7还有几年前的老手机华为P30上测的(太穷了没钱买新机子),尽管在老机器上跑,但是最大的NanoDet-Plus-1.5x也依旧能够实时运行,且COCO mAP达到了34.1,如果换上十二代酷睿和今年的骁龙8gen1手机来测那速度更是起飞。
与今年的其他模型相比如YOLOv5-n,YOLOX-Nano以及FBNetV5相比也是很有优势,当然由于没有能力改backbone,因此并不能打过某度的几个用NAS搜出来的模型,不过对我来说,在手工设计的模型中能够取得性能上的优势已经很满足了,希望明年能看到更多的小模型能够打败NanoDet-Plus!
最后的最后,开源不易,为了搞这个项目我周末都没怎么休息过,恳请各位看官GitHub点个Star!!!
开源地址:https://github.com/RangiLyu/nanodet