写在前面
博主在学习爬虫之初,利用BeautifulSoup爬取了无锡美团美食数据,博客链接在这里,后来有童鞋指出代码不能运行,在一番讨论后发现是在使用get_text函数时返回的数据为空值,博主本来想弄明白到底是怎么回事的,于是用相同的代码爬了一遍豆瓣电影的数据,发现使用get_text函数没有出现任何问题,也就是说博主在写这篇博客时,也还没弄明白为啥get_text函数没法解析美团的网页代码。这个问题姑且放在一遍,在使用get_text函数时,我发现,豆瓣网页解析出来的数据是纯文本数据,而非json数据,也就是说,我用get_text函数解析出来数据除了用正则表达式外,很难把我想要的信息解析出来。
为了正确的解析这种数据,博主琢磨一番,弄明白了其中的一些细节,供大家参考。博主写博客的目的,主要是为了梳理自己当时遇到的问题,加深对代码的理解。
- 编译环境:Python3.7
- 编译器:Spyder
开始爬虫
请求头构造
请求头的构造在我之前的博客里已经提到,这里不再讲解,这个请求头在一段时间之前是无需加入的,但是现在爬豆瓣必须加入,否则状态码不等于200。
导入包
import requests
import time
import json
import csv
import pandas as pd
from bs4 import BeautifulSoup
爬虫主体
results = []
raw = 'https://movie.douban.com/top250'
for index in range(10): # 1
url = raw + '?start=' + str(25*index) +'&filter='
page = requests.get(url = url,headers = headers)
time.sleep(2)
print(index)
print(page.status_code)
if (page.status_code != 200): # 2
print('error')
continue
page = requests.get(url = url, headers = headers)
soup = BeautifulSoup(page.text,'lxml')
div = soup.find_all('div', attrs={'class':'hd'}) # 3
pageindex = []
for i in div:
name = i('span') # 4
name1 = name[0].string.strip() # 5
href = i('a') # 6
lst = [] # 6
lst.append(str(href)) # 6
soup1 = BeautifulSoup(''.join(lst),'lxml') # 6
href = soup1.a.attrs['href'] # 6
name2 = name[1].string.strip('/\xa0') # 7
pageindex.append([name1,name2,href])
results.extend(pageindex)
对标注的地方进行解释:
- #1 总共有250部电影排名,每页上有25部电影,所以总共要访问10次网页,其中,初始页是’https://movie.douban.com/top250’,其他页(如第二页)在初始页网址后面加上’?start=25&filter='就行了,这里我并没有做初始页和其他页的区分,因为我试了一下,'https://movie.douban.com/top250’与’https://movie.douban.com/top250?start=0&filter='没有任何区别,都可以访问初始页;
- #2 判断网页状态是否正常,等于200则正常,如果不写请求头我这边的状态码是418,无法正常爬取;
- #3 用BeautifulSoup中的find_all函数找到div标签,但是div标签太多,总共有182个div标签,这样找出来肯定是不对的,仔细看网页代码,发现有用的信息都在’hd’里面,于是给find_all函数添加attrs参数attrs={‘class’:‘hd’},这样找出来的数据正好有25组;
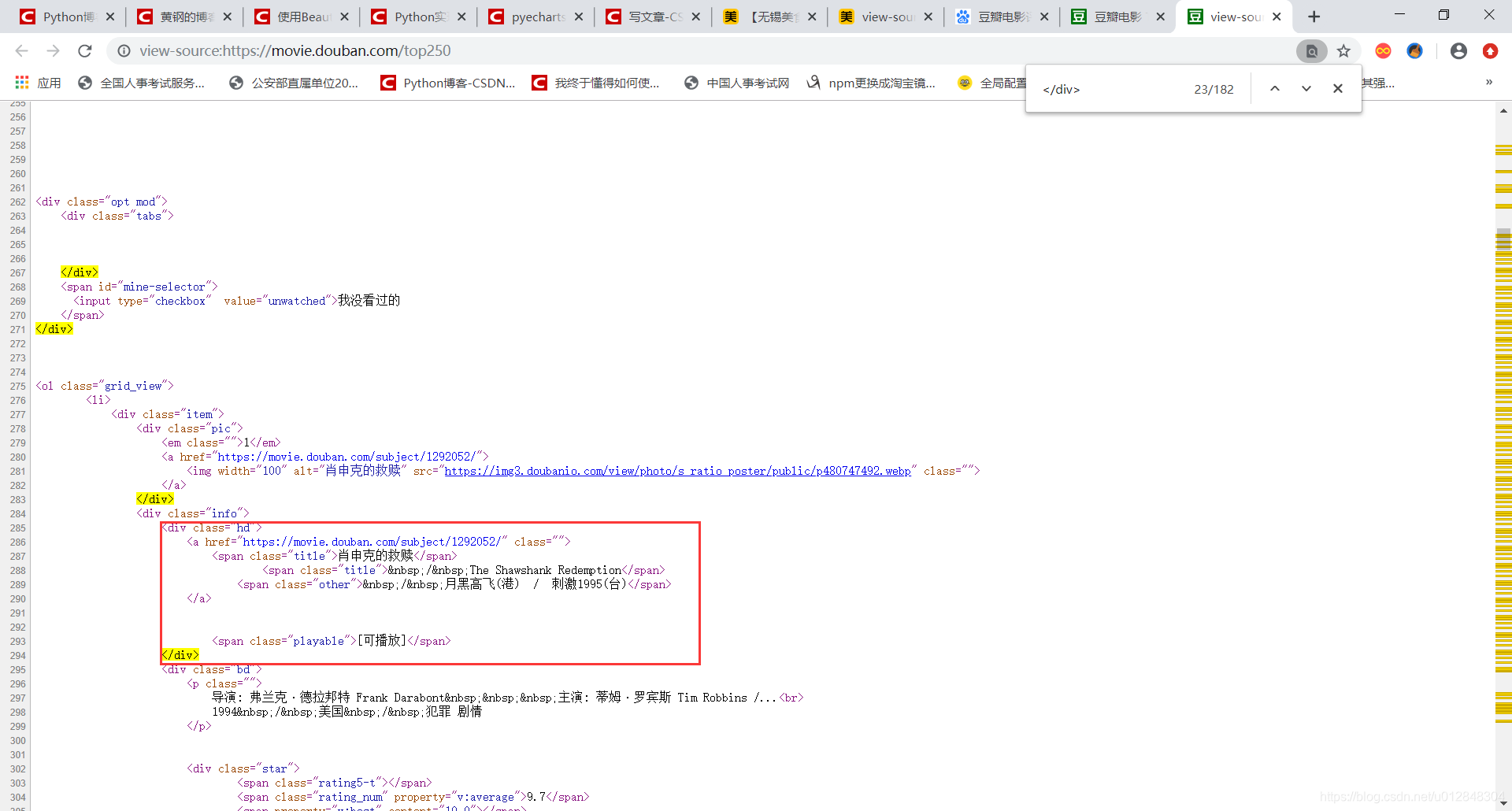
- #4 name = i(‘span’)是为了找出所有的span标签,看上面的截图,《肖生克的救赎》这部电影有4个span标签,第一个span标签是电影名,也是我们要找的第一个数据,第二个span标签是电影的外文名,我们也需要,第三个span标签是电影的别名,有的电影有,有的电影没有,我没有选取,第四个span标签是电影的播放状态,是否可播放;
- #5 把电影名标签取出来,并转化成字符,用strip函数删除字符串前面或后面的内容,这里未传递参数,表明作为整体取出。另外,也可以用split函数分割,split函数默认参数是按照空字符分割,包括空格、换行、制表符等;
- #6 找出所有的a标签,上图中我截出来的那部分,其实就一个a标签,里面有这部电影的豆瓣地址,但是这个标签的内容很长,除了豆瓣地址外,5中的span标签也在里面,所以我们这里不能像5一样直接索引获取我们想要的地址链接,做法有点复杂,具体步骤是:将a标签的所有内容转成字符串放入一个空列表,然后将这个列表用BeautifulSoup整理成网页代码的形式(看下面的图,s = str(soup1)),然后找出其中的href字段即可,这样就成功获取了想要的豆瓣地址链接;
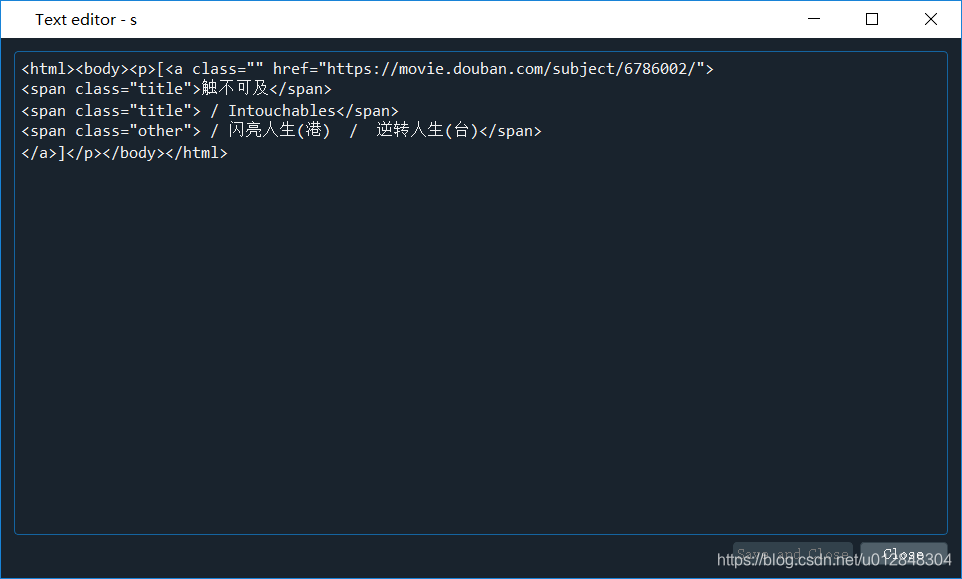
- #7 在处理别名时,遇到一个问题,如果还用strip()函数不传参数,得到的结果是下面这样的,电影名前面多了/\xa0这几个字符,当然要处理掉。
数据导出
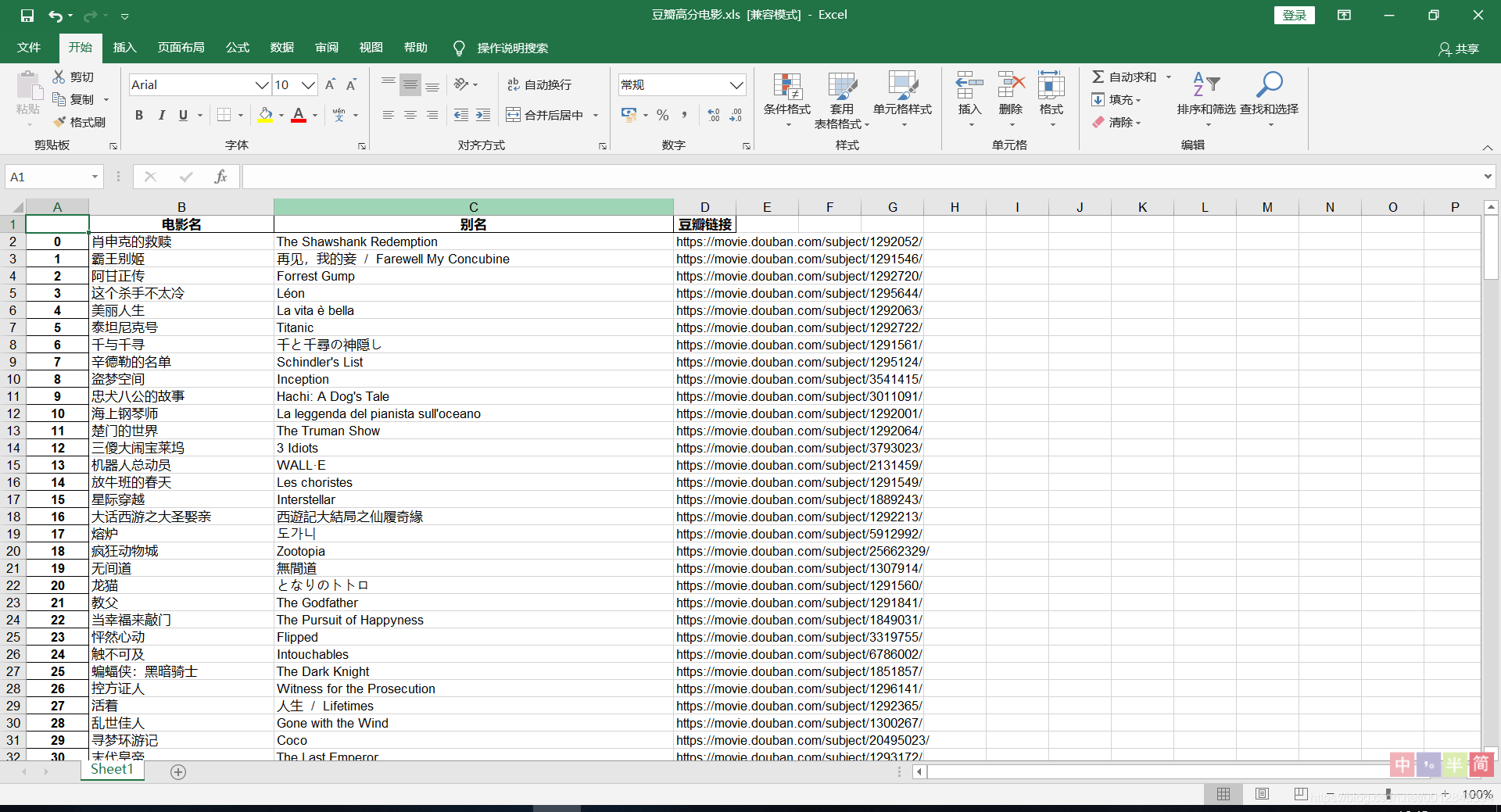
output = pd.DataFrame(results,columns = ['电影名','别名','豆瓣链接'])
output.to_excel('豆瓣高分电影.xls')
看结果:
至此完成所有爬取过程。
写在后面
博主也是爬虫初学,因为工作的原因,最早接触爬虫是要爬取gxb的网站获取相关数据,他们的网站其实没有这么复杂,但有个问题,很多情况下,数据都是贴成图片的形式展示的,所以爬取反而更费劲一点。但其实思路都是一样,首先是对网页发起请求,如果请求正常,则会给你返回一大串你想要的不想要的数据,那么接下来就是你从返回的数据中提取你想要的数据,如果返回的是json数据,那么很好,json.load()就行了,如果返回的是网页代码,那么通过beautifulsoup解析各种标签获取数据,基本是这个套路。
由于这些互联网企业都会不定期更新网页代码,所以爬虫代码不知道啥时候就不能用了,有空再来更新。