基于Python和Django框架的简单博客平台。该平台提供了一个用户友好的界面,使用户能够轻松地创建和管理博客文章、评论和标签
前期环境:需要准备的环境 python3以上
创建一个虚拟环境(以兼容不同的Django版本)
- 创建一个文件夹来专门存放Django(website)
- 安装Django
pip3 install django
- 打开cmd到website中创建虚拟环境(djangoenv为虚拟环境项目名)
cd desktop/website
python -m venv djangoenv
- 继续输入
djangoenv\Scripts\activate就可以将该虚拟环境激活了
这是每一次使用虚拟环境都要进行的操作
以上虚拟环境就创建好了
创建一个Django项目
`django-admin startproject one(项目名)

初始化生成文件的用途
Manage.py 一个在命令行中可以调用的网站管理工具
one文件夹里
init.py 告诉Python这个文件夹是一个模块
settings.py one项目中一些配置
urls.py 网站内各个网址声明
usgi.py web服务器与django项目的接口
新建一个一个Django App
`cd one`
python manage.py startapp blog(app项目名)
再将App添加到settings.py里INSTALLED_APPS默认包括了一下Django自带的应用:
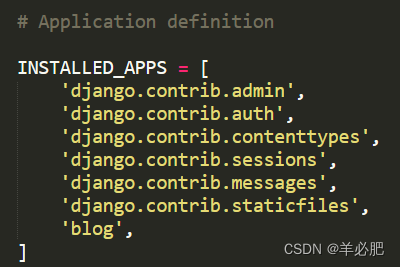
- django.contrib.admin--管理员站点
- django.contrib.auth--认证授权系统
- django.contrib.contenttypes--内容类型框架
- django.contrib.sessions--会话框架
- django.contrib.messages--消息框架
- django.contrib.staticfiles--管理静态文件的框架
默认开启的某些应用至少需要一个数据表,所以在使用他们之前要创建一些表
python manage.py migrate
这个命令是用来检查INSTALLED_APPS设置,为其中的每个应用创建需要的数据表(作用到数据库文件)
Django的大致运行流程
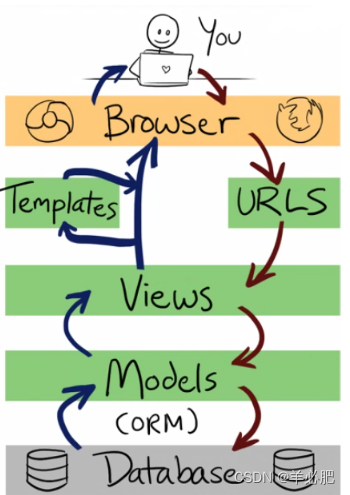
对于不同路径的响应(一般是在urls.py--blog中修改)
在blog文件夹下创建一个新的文件:urls.py用于处理网址的解析,同时在one文件夹下的urls.py中添加一条路径
urls.py--one path('',include('blog.urls')),
- urls.py--one中要添加
from django.urls import path,include
- urls.py--blog中添加
from django.urls import path
函数include()允许引用其他的URLconfs.,他会截断与此项相匹配的URL部分,并将剩余的字符串发送到URLconf以供进一步处理.包括其他URL模式时总应该使用include(),admin.site.urls是唯一的例外.
函数path()具有四个参数,两个必须参数:route和view,
两个可选参数: kwargs和name一般只填写两个必选参数:
route是一个匹配URL的准则.当Django响应一个请求时,他会从urlpatterns的第一项开始,按顺序以此匹配列表中的项,直到找到匹配的项,这些准则不会匹配GET和POST参数或域名.
例如,URLconf 在处理请求 https://www.example.com/myapp/ 时,它会尝试匹配 myapp/ 。处理请求 https://www.example.com/myapp/?page=3 时,也只会尝试匹配 myapp/
path() 参数: view
当 Django 找到了一个匹配的准则,就会调用这个特定的视图函数,并传入一个 HttpRequest 对象作为第一个参数,被“捕获”的参数以关键字参数的形式传入。
route参数可以有一些特定的格式来处理路径
<slug:blog_link>--slug可以识别字符和数字<int:blog_id>--int用于识别数字,表示这个网址是个数字存到blog_id这个变量里<str:blog_title>--str用于识别字符串

如上图所示有一个默认的路径http://127.0.0.1:8000/admin/
编写模型
模型是您的数据唯一而且准确的信息来源.它包含您正在存储的数据的重要字段和行为.一般来说,每一个模型都映射一个数据库表
- 每个模型都是一个python类,这些类继承django.db.models.Model
- 模型类的每个属性都相当于一个数据库字段
- 综上,Django正在给你一个自动生成访问数据库的API
Django中可用的各类模型

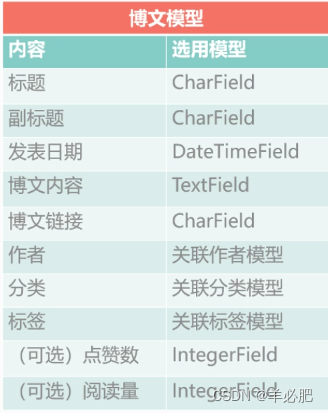
三个关联模型是为了防止出现重复过多的问题(方便添加数据)
关联作者模型
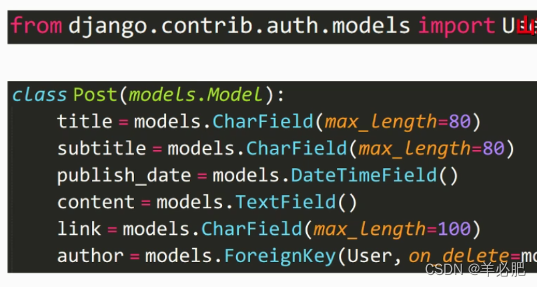
利用ForeignKey()即可关联另外一个模型
在models.py文件中建立一个Post模型,还有与之相关联的Category,Tag模型
- ForeignKey()--一般用于一对多的模型
- ManyToManyField()--一般用于多对多的模型
- 关联作者模型有现成的直接引入
from django.contrib.auth.models import User

然后,想要在后台直接操作这三个数据,需要现在admin.py中注册一下

-
from .models import Post,Category,Tag--将Post,Category,Tag从models.py中导入
-
admin.site.register --进行注册
最后每当我们在models做了修改之后都需要执行两个操作
python manage.py makemigrations
python manage.py migrate
第一个命令用于检测你对模型文件的修改,并且把修改的部分作为一次迁移(这是一种对于变化的存储形式)
第二个命令,在数据库中创建新定义的模型的数据表