论文链接:SeqGPT: An Out-of-the-box Large Language Model for Open Domain Sequence Understanding(https://arxiv.org/abs/2308.10529)
GitHub链接:https://github.com/Alibaba-NLP/SeqGPT
体验地址:https://www.modelscope.cn/studios/TTCoding/open_ner/summary

概念介绍
自然语言理解(Natural Language Understanding, 简称NLU)任务是帮助机器理解自然语言的任务的总称,与自然语言生成(Natural Language Generation,简称NLG) 合称为自然语言处理(Natural Language Processing,简称NLP)。NLU任务覆盖文本分类、信息抽取、情感分类、关系抽取、事件抽取等子任务,是各类信息处理系统,如信息管理系统、推荐系统、搜索引擎的重要基础组件。
正是由于其重要性和应用的广泛性,NLU一直是NLP从业人员重点研发的方向。在过去几十年中,尤其自BERT诞生后,NLU技术取得长足进步。在各类细分场景中,基于大规模高质量的标注数据,采用监督学习的NLU模型达到了极高的精度。但是,监督模型高昂的定制成本(数据标注成本、研发时间成本等)限制了它的应用范围。除了需求相对固定,有大规模使用可以摊薄成本的场景外,对于成本敏感、数据标注难度大、需求变化快的场景,很难实际落地。因此,研究者一直致力于探索一种没有领域(可以等价为场景)限制的通用模型,即开放域(open domain)模型,期望在任何场景都可以开箱即用。
动机
然而,受限于小模型的泛化性不足,真正的开放域模型如凤毛麟角。随着大规模语言模型,特别是GPT3的出现,研究者看到了理想实现的可能性。ChatGPT的出现则直接将开放域模型变成了现实。用户只需仔细描述自己的需求,无需标注大量数据,即可以获得相对可靠的结果。但是深度使用过类似ChatGPT的做NLU任务用户应该不难发现,还存在一些问题。
成本问题,NLU任务作为基础性任务,其调用量巨大,长期的调用成本甚至超过了专门研发监督模型的成本。
数据安全问题,对于一些数据安全管理严格的场景,是不可能将输出传输到外部互联网服务器的。
推理速度问题,ChatGPT接口的并发数和RT很难支持NLU这一类基础任务每天大规模的实时请求。
提示工程繁琐,ChatGPT的效果受提示影响很大,对于不同任务需要精心设计提示语。严格来说,不能算开箱即用的开放域模型,因为对不同任务还是有提示设计的成本。
范围格式可解析性与稳定性差,ChatGPT等模型的输出为自然语言形式,没有严格的模式(即使通过提示语进行限制,依然会有很高比例的例外),给下游任务利用模型结果造成困难。
闭源模型,无法结合沉淀的业务数据深度定制。通用版本的效果难以满足高准确率需求的场景。
因此,研发一款规模较小(使用成本低、推理速度快)、输入输出简洁(类似于API)、可私有定制的模型,有其必要性。
方法简述
统一任务范式
大规模语言模型输入是序列,包含任务相关知识,然后输出答案。为了用一个模型和一致的输入输出格式解决不同的NLU任务,我们将NLU统一转换成两个原子任务:
对于每个原子任务,我们设计了一个简单的提示模板(如下图所示),它包含(1)一些控制词,区分输入的不同要素,(2)要分析的具体文本,以及(3)所需要的的标签列表。输出答案则根据原子任务类型格式化为固定且易于解析的形式。特别地,对于抽取任务,答案逐行列出。每行包含用户输入的类型,后面跟着相应答案的短语列表。对于分类任务,答案格式化为单行列表,其中包含提供的标签集合中的答案标签。

通常,大多数任务只涉及其中一个原子任务。NLI和NER是仅依靠分类或提取的任务的示例。然而,有些任务需要将其分解为多个原子任务。例如,关系抽取(RE)首先识别实体,然后进行分类以区分每对实体之间的关系。此外,我们还进行了必要的提示设计工作,以处理特定任务的输入。例如,NLI涉及两个句子(即前提和假设)。我们使用分隔符将它们连接起来。
训练流程
我们基于BLOOMZ训练SeqGPT,并采用两阶段的训练策略,包括预训练(Pre-training, 简称PT)和微调(Fine-tuning, 简称FT),并在每个阶段使用不同的训练数据。在我们的初步实验中,这种策略优于使用PT和FT数据的简单混合训练。训练方式采用标准的因果语言模型(Causal language model, 简称CLM)训练方法,训练参数细节请参考论文。
预训练数据
相关研究证明,丰富数据多样性有利于提升模型的泛化能力。因此,我们构建了一个大规模的预训练(PT)数据集,包含来自多个领域(包括维基百科、新闻和社交媒体等)极其多样化的标签集的数据。我们主要选择了三个任务:分类(CLS)、实体分类(ET)和实体识别(NER)。我们通过调用ChatGPT为每个样本获得伪标签。最终,PT数据集包含1,146,271个实例和817,075个不同的标签。下表列出了详细的统计信息。

负例采样:由于ChatGPT生成的PT数据缺乏负例标签,即没有答案的标签(抽取任务)或不正确的类别(分类任务),因此不能直接用于训练。我们使用随机抽样的标签来增加PT数据中的负样本。由于标签集规模较大,这些抽样的细粒度标签很可能与输入句子无关(没有相关类型实体或不是对应的目标类别),因此可以安全地假设是负例标签。
微调数据
为了进一步校准模型以执行各类NLU任务并消除PT数据中的错误造成的影响,我们收集了来自不同领域的大规模高质量NLU数据集进行微调。如下图所示,我们的微调(FT)数据集包含110个NLU数据集,涵盖英语和中文两种语言以及10大类任务。除了任务多样性外,领域(包括医学、新闻和与AI助手的对话)的多样性以及标签多样性也保证了数据多样性。每个任务被转化为原子任务,共产生了139个分类原子任务和94个抽取原子任务。我们手动选择了其中一小部分NLU数据集作为零样本评估的评估集。
FT数据集包含大量的数据集,以确保多样性,但与此同时,也引入了数据不平衡的问题。以两个分类数据集为例,IFLYTEK和AG News的平均每个标签的实例数分别为124和31,900。因此,我们为每个数据集-标签对设置了一个配额来平衡数据。对于那些实例数少于配额的数据集-标签对,我们使用整个实例集而不进行上采样。然后我们将所有数据混合在一起,并在训练中均匀地从中采样。
结果分析
评价方式
考虑到语言模型有时会生成合理但不完全匹配的答案,传统的Micro-F1指标对于评估来说不够平滑。为了缓解这个问题并使评估更容忍一些次要缺陷,我们提出将Micro-F1和更平滑的ROUGE分数结合作为整体指标。具体而言,我们将ROUGE-1、ROUGE-2和ROUGE-L的平均值作为ROUGE分数,将Micro-F1和ROUGE分数的平均值作为最终得分。
本文重点评估模型泛化能力,我们将数据集分为held-in和held-out两部分,两部分从数据集层面没有交集。下文如无特殊说明,均为在held-out数据集上效果。为了提高效率,我们从每个测试集拆分中随机抽取48个记录(我们前期的实验证明这个结果与使用完整测试集是无偏的)。此外,在涉及被拆分的任务时,我们报告原子任务的平均分数。
效果对比

上表中比较了SeqGPT家族和基线模型的测试集性能。我们有以下发现:
(1)最小的SeqGPT-560m在性能上大幅超过ChatGPT,超出了19.1个百分点,证明了我们的框架的有效性,说明小型模型可以学习到强大的自然语言理解能力。需要说明是,ChatGPT的总体得分较低有两方面原因,一是我们没有针对每个任务进行仔细的提示工程,而是采用了和我们构建数据集类似的提示进行发问。二是因为ChatGPT生成的输出格式无法总是严格遵守我们的评估数据格式,自动评估脚本无法处理。因此,我们补充了进行了人工评价,结果参考最后人工评价部分。
(2)通过使用更大的7b1主干模型,平均得分进一步提高到65.5,我们认为这一提升可以归功于更好的复杂推理能力和更多样化的世界知识,这些都是更大的预训练语言模型所带来的。(3)弱监督的超细粒度预训练数据对于较小的模型尤为有帮助。如果不使用预训练数据,SeqGPT-560m的性能从57.2下降到53.9。具体而言,对于需要对实体进行多样化理解的实体分类任务,各个大小的SeqGPT的得分都显著下降。(4)然而,利用预训练数据所实现的性能提升随着模型的增大而减小。我们认为这是因为在我们的预训练数据中的超细粒度知识也可以在LLM的预训练阶段直接学习,并且这些知识会随着预训练LLM模型的增大而更好地学习和保留。
规模缩放实验


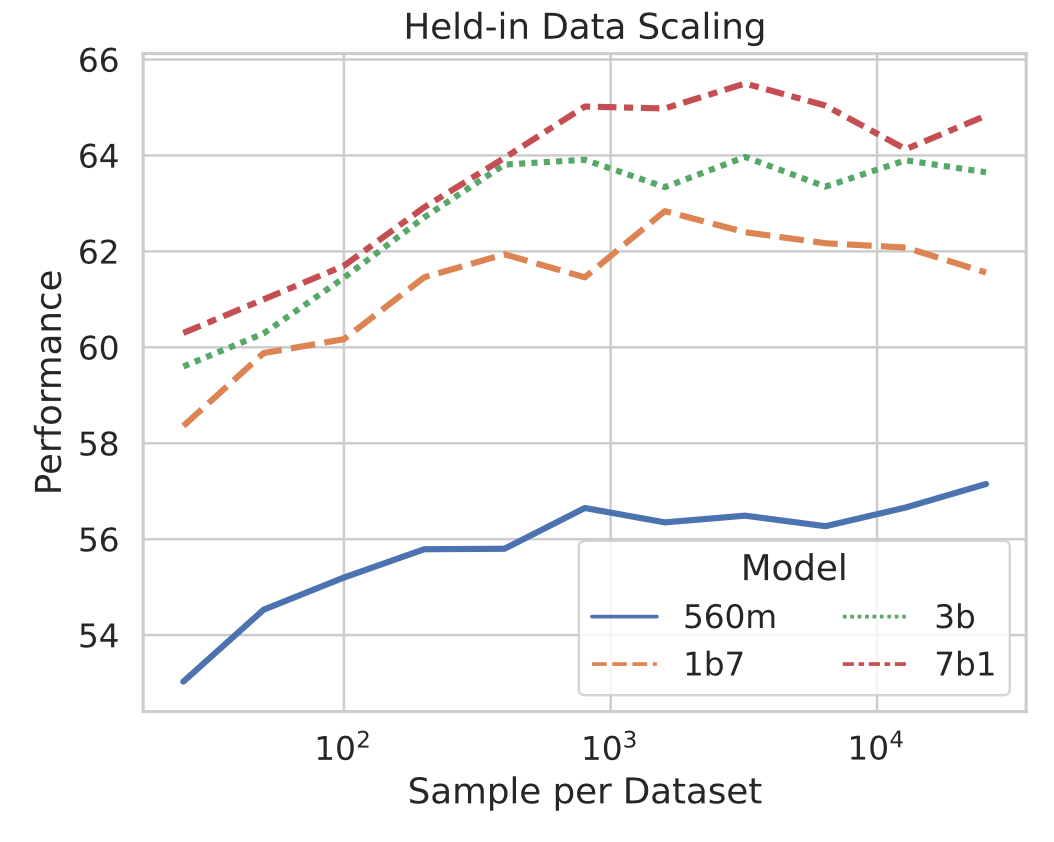
我们也做了多组缩放实验,分别是:(1)模型参数量缩放;(2)任务数缩放;(3)每个任务的数据量缩放。相应结果如上图展示。可以有以下结论:
在一定范围内,是符合scalig law的,模型规模越大,数据越多模型效果越好。
在held-in数据上,模型规模持续增长的边际效益递减,held-out数据集上这个问题没有那么明显。
任务数的增加对提升held-out效果至关重要,即数据多样性非常重要。
与3相对的是,每个任务的数据量不是越多越好,边际效应递减甚至为负,因此如果要提升模型效果,多样性优先于数据量。这个多样性体现在任务的多样性、数据领域多样性、相同任务的标签集多样性等。
跨语言实验

我们使用了大量来自英语和中文的训练数据。为了探索每种语言数据的影响以及SeqGPT的跨语言泛化能力,我们进行了跨语言泛化实验(1B7),主要结果如上表所示。我们可以看到,使用单一语言(英语/中文)训练的模型可以推广到另一种语言的任务,并取得较好的性能。比较仅使用英语和使用两种语言的数据训练的结果,我们发现不仅中文任务上效果得到提升,在英语任务也可以得到提升,表明语言之间存在一些共通的能力,可以通过多语言训练阶段学习到。
跨任务实验
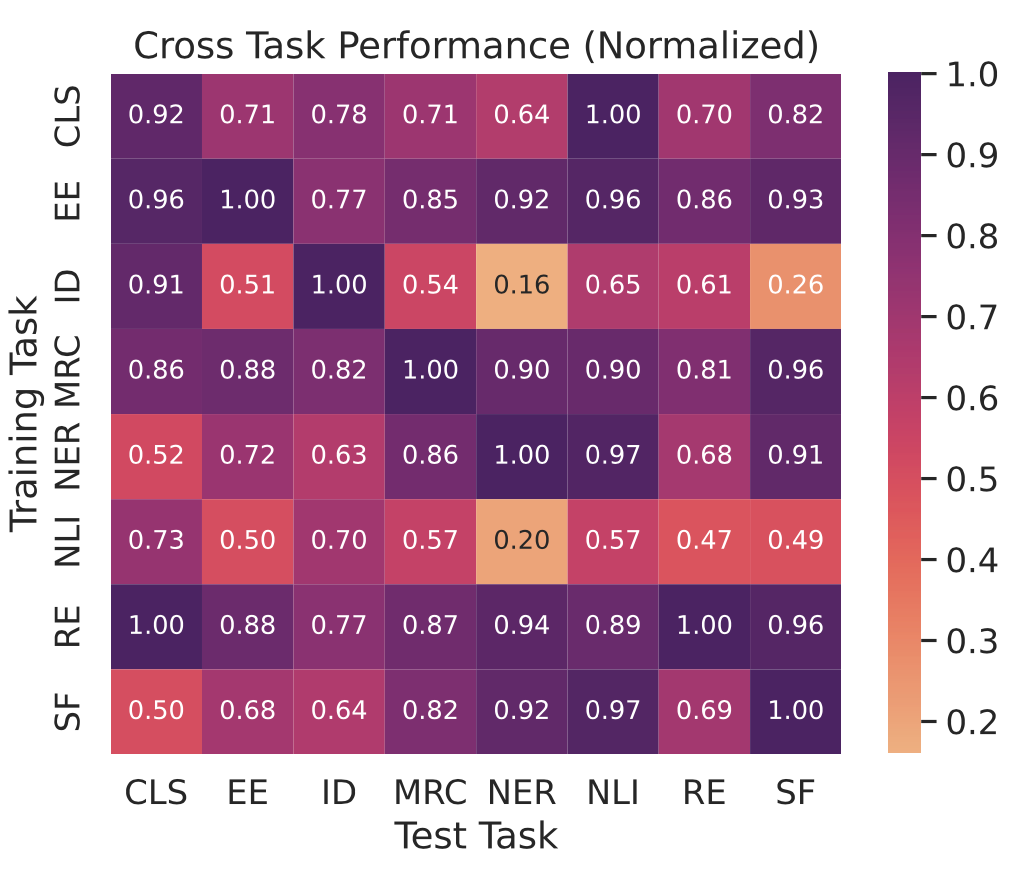
尽管在我们对所有任务使用相同的提示模版,但解决不同任务所需的能力是多样的。为了分析SeqGPT在训练期间未见过的任务上的工作方式以及训练任务如何影响不同测试任务的性能,我们使用单一任务数据训练了一系列模型,上图中展示了结果。在大多数评估任务中,当训练和测试任务相同时取得了最高或接近最高的性能。对于NLI任务,结论相反,使用NLI数据训练的模型效果最差。我们认为这是因为虽然我们把NLI任务转化为了分类任务,但其本质是逻辑推理,不同数据集的分类逻辑差别较大,因此模型很难泛化。在EE、MRC和RE上训练的模型可以很好地推广到所有测试任务,这表明解决这些任务所需的多样化知识对其他任务也至关重要。这些任务的数据可以作为针对通用领域自然语言理解的模型的重要训练资源。
人工评价
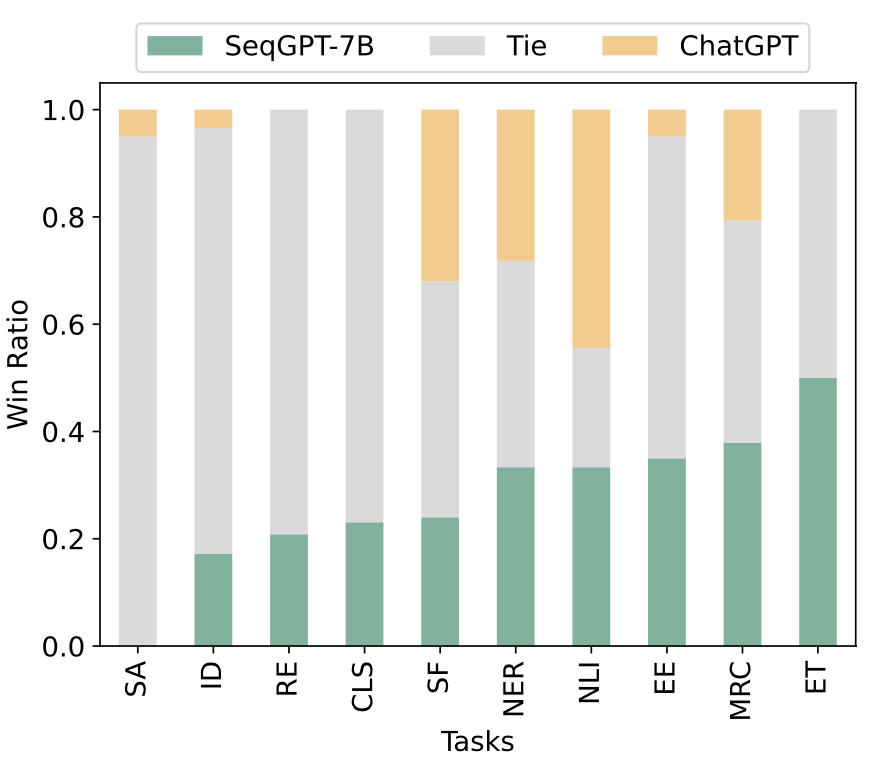
为了进一步了解我们模型指标上优于ChatGPT的原因,排除格式问题引入的误差,我们对保留的数据集进行了人工评估。评估聘请了十名专业的标注员,并向他们展示了ChatGPT和SeqGPT-7B的答案(隐藏了模型名称)。标注员需要从核心内容上(忽略格式和额外解释性语言)决定哪个模型给出了更好的答案,或者两个模型效果相近。结果如上图所示。从结果可以看出,SeqGPT-7B的确在大多数任务上准确率更好,这证明了使用多样化NLU任务数据的训练模型的收益。此外,我们发现SeqGPT-7B的输出比ChatGPT的输出更简洁,更容易被解析。
总结
本文介绍了SeqGPT,用一个统一的模型,通过将不同的NLU任务转化为两个通用的原子任务来处理。SeqGPT提供了一致的输入输出格式,使其能够通过任意变化的标签集来解决未见过的任务,而不需要繁琐的提示工程而且结果易于解析。我们使用极细粒度的合成数据和各种领域的大量NLU数据集对模型进行训练。训练过程进一步增强了数据平衡和随机采样负标签。无论是自动基准测试还是对未见任务的人工评估,SeqGPT都相对于ChatGPT的有一定优势。此外,我们通过实验揭示了训练任务数量和模型性能之间的对数相关性。我们还评估了SeqGPT在各种任务和语言上的泛化能力。然而,还有一些值得继续深入的问题。比如为什么PT数据无法增强SeqGPT-7B1,而FT数据的增加可以呢?如何生成更多高质量的NLU数据来满足SeqGPT的数据需求?我们希望未来的研究能够解答这些问题,进一步改进开放域NLU模型。
讨论
最后,还想讨论一个从ChatGPT出现就一直被提起的问题:大模型时代,还有必要做原子化的NLU模型的?我们认为这还是有必要的,虽然说一些以NLU为辅助的任务可以使用LLM进行端到端重构,但是还是有大量的场景需要专用的、小的NLU模型。这里举一些例子,抛转引玉。
受资源、成本、时间要求等限制,无法使用大模型的场景,如端上场景等。
以NLU为最终目的的场景,从性价比考虑,无需使用通用大模型。如数据挖掘等。
以NLU为重要组件,整体方案成熟,无需使用LLM重构的场景,如信息检索等。
因此,大模型的出现只是缩小了NLU的使用范围,但对高效高质专用模型的需求依然存在。超算替代不了PC, intel 酷睿也替代不了Arm单片机,其中原因相似。以上仅一家之言,还请各位指教。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)
