网上的代码基本上都是python2,这里的代码使用的是python3注意没有urllib2这个库了。
要先做几个个准备工作:
①找到有图片的网站
②指定电脑保存路径
③利用浏览器工具查看网页代码中图片的保存路径(非常重要,如果错误可能抓取不到)
下面给出代码:
注意看注释
import re
import urllib.request
import urllib
import os
def getHtml(url):
'获取网站地址'
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
'图片地址注意要从浏览器中查看网页源代码找出图片路径'
reg = r'data-progressive="(.+?\.jpg)" '
imgre = re.compile(reg)
imglist = imgre.findall(html)
x = 0
path = 'E:\\Temporary\\new'
if not os.path.isdir(path):
os.makedirs(path)
paths = path + '\\'
for imgurl in imglist:
urllib.request.urlretrieve(imgurl, '{}{}.jpg'.format(paths, x))
x = x + 1
if __name__ == '__main__':
html = getHtml("https://bing.ioliu.cn/ranking")
getImg(html)
注意以上代码在pycharm python3.6.2环境运行
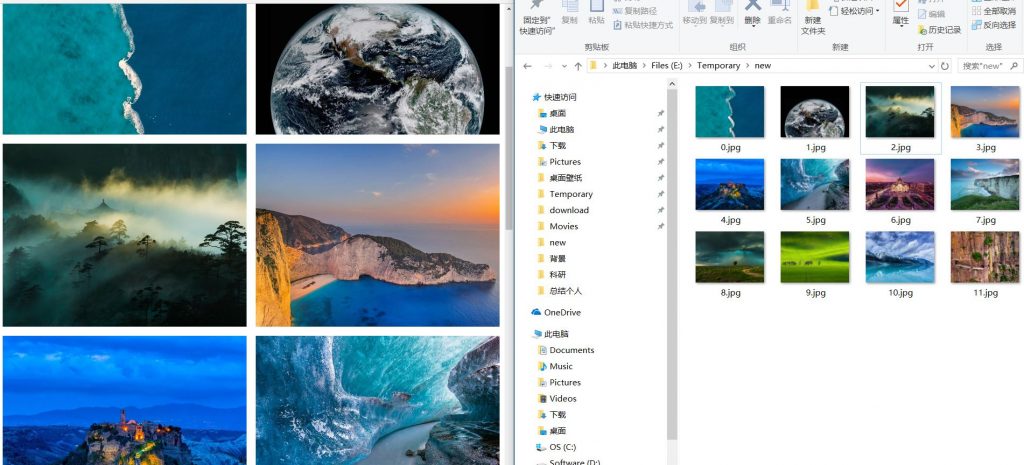
效果截图:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)