原始数据:唐诗一百首.txt

方法1:
f=open('唐诗一百首.txt', encoding='gbk')
txt=[]
for line in f:
txt.append(line.strip())
print(txt)
line.strip() 去除首尾空格
encoding 编码格式 utf-8,gbk

方法2
f=open('唐诗一百首.txt')
line = f.readline().strip() #读取第一行
txt=[]
txt.append(line)
while line: # 直到读取完文件
line = f.readline().strip() # 读取一行文件,包括换行符
txt.append(line)
f.close() # 关闭文件
print(txt)
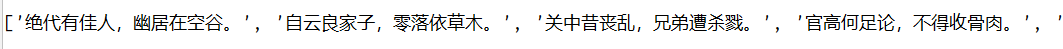
方法3:
f=open('唐诗一百首.txt')
data = f.readlines() # 直接将文件中按行读到list里,效果与方法2一样
f.close() # 关
print(data) #返回list
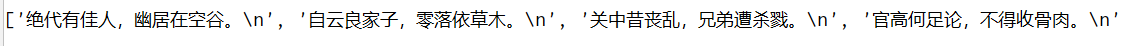
读取出的有换行符\n
方法4:
读取数据文件
import numpy as np
data = np.genfromtxt("文档练手.txt",dtype=[int, float,int]) # 将文件中数据加载到data数组里
print(data)
原始txt

结果:
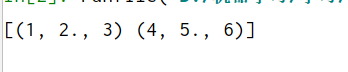
np.genfromtxt 里有个分隔符参数,delimiter 默认None,也可以delimiter=’,’
读取
