我是通过学习mooc上嵩天老师的数据分析与展示和阅读《利用python进行数据分析》做出的笔记
为了缩小代码量,公认约定使用np作为numpy
from numpy import * 往往实不可取的,因为它包含了与一些内置函数重名的函数
numpy通过np.array()可以将list/tuple转化为ndarray n维数组对象
In [55]: a = [[1, 2, 3], [4, 5, 6]]
In [56]: np.array(a)
Out[56]:
array([[1, 2, 3],
[4, 5, 6]])
ndarray一般是要元素类型一致的,不一致会变成以下实例:
In [130]: L = [1.2, 3, 5]
In [131]: np.array(L)
Out[131]: array([ 1.2, 3. , 5. ])
In [132]: np.array(L).astype(np.int32)
Out[132]: array([1, 3, 5])
而且ndarray如果每一行的列数不对齐,或者说同一维度上秩(秩,即轴的数量或维度的数量)不一样,会生成object类型
In [134]: np.array(L)
Out[134]: array([list([2, 3, 4]), list([1, 2])], dtype=object)
python有了list,我们为什么还要ndarray?
1.ndarray底层使用c实现的
In [6]: %time my_list = list(range(1000000))
Wall time: 26.1 ms
In [2]: %time my_arr = np.arange(1000000)
Wall time: 2 ms
比list快10倍100倍,有时候可能还不止
2.计算方便啊
In [63]: %time for _ in range(10): my_arr2 = my_arr * 2
Wall time: 37.1 ms
In [64]: my_arr2
Out[64]: array([ 0, 2, 4, ..., 1999994, 1999996, 1999998])
In [65]: %time for _ in range(10): my_list2 = [i * 2 for i in my_list]
Wall time: 1.21 s
不同大小的数组之间的运算叫做广播(broadcasting),这里不做介绍
ndarry的元素类型(图片来源网络,侵删)

我们拿刚才的例子做一个test
In [67]: my_arr
Out[67]: array([ 0, 1, 2, ..., 999997, 999998, 999999])
In [68]: my_arr.ndim
Out[68]: 1
In [69]: my_arr.shape
Out[69]: (1000000,)
In [70]: my_arr.size
Out[70]: 1000000
In [71]: my_arr.dtype
Out[71]: dtype('int32')
In [72]: my_arr.itemsize
Out[72]: 4
拿二维的对比一下
In [85]: my_arr2 = np.array(range(100), range(100))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
这里找到了自己以前对range函数的一个误区,它只是看起来像list,range(10)这种并不会返回[1, 2, 3 ....]因为他不是list,引用官方原话:
In many ways the object returned by range() behaves as if it is a list, but in fact it isn’t. It is an object which returns the successive items of the desired sequence when you iterate over it, but it doesn’t really make the list, thus saving space.
We say such an object is iterable, that is, suitable as a target for functions and constructs that expect something from which they can obtain successive items until the supply is exhausted. We have seen that the for statement is such an iterator. The function list() is another; it creates lists from iterables:
所以我重新建立一个二维的来比对一下
In [89]: my_arr2 = np.array( [list(range(100)), list(range(100))] )
In [90]: my_arr2
Out[90]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67,
68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84,
85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99],
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67,
68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84,
85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]])
In [96]: my_arr2.ndim
Out[96]: 2
In [97]: my_arr2.shape
Out[97]: (2, 100)
In [98]: my_arr2.size
Out[98]: 200
In [99]: my_arr2.dtype
Out[99]: dtype('int32')
In [100]: my_arr2.itemsize
Out[100]: 4
这里对nbarray的元素类型进行一个补充:

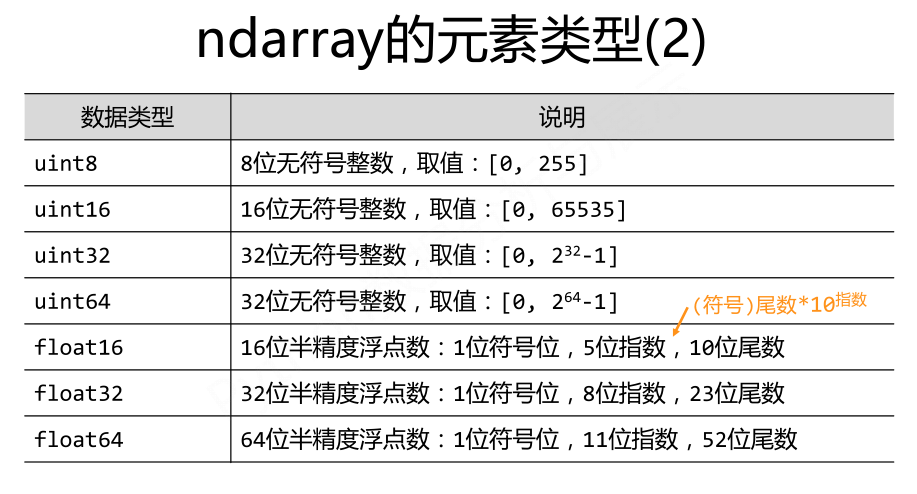

上述几张图片引用自北京理工大学嵩天老师的ppt
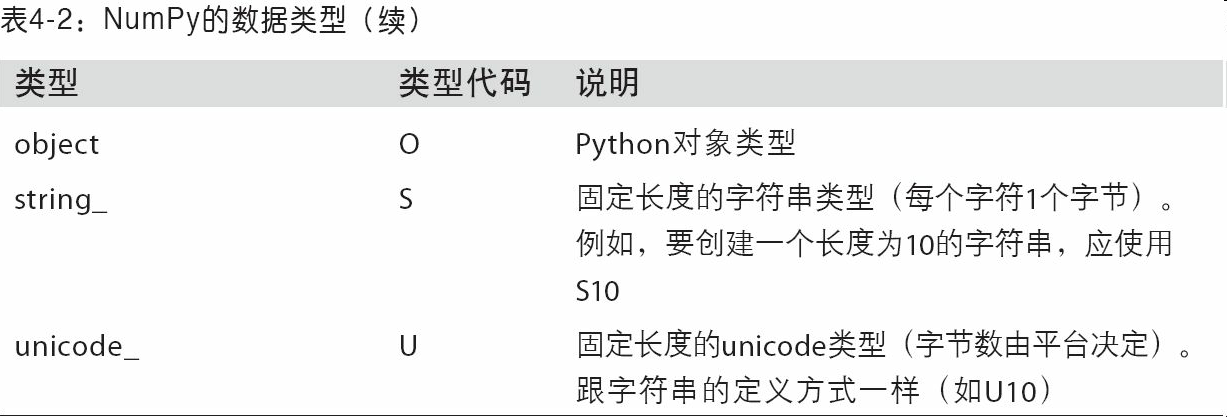
注意:使用numpy.string_类型时,一定要小心,因为NumPy的字符串数据是大小固定的,发生截取时,不会发出警告。pandas提供了更多非数值数据的便利的处理方法。
除了np.array函数,书上还介绍了如下函数

1.先说一下ones和ones_like(zeros类似,empty),full后面也有补充
In [106]: np.ones(10)
Out[106]: array([ 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
In [107]: np.ones((2, 3))
Out[107]:
array([[ 1., 1., 1.],
[ 1., 1., 1.]])
看一下他的参数
In [108]: help(np.ones)
Help on function ones in module numpy.core.numeric:
ones(shape, dtype=None, order='C')
Return a new array of given shape and type, filled with ones.
Parameters
----------
shape : int or sequence of ints
Shape of the new array, e.g., ``(2, 3)`` or ``2``.
dtype : data-type, optional
The desired data-type for the array, e.g., `numpy.int8`. Default is
`numpy.float64`.
order : {'C', 'F'}, optional
Whether to store multidimensional data in C- or Fortran-contiguous
(row- or column-wise) order in memory.
多用用上面几个函数我们会发现,ndarray大多数函数创建的是float64类型的
In [109]: np.ones((2, 3)).dtype
Out[109]: dtype('float64')
如果我们想得到一个整数的化,可以这样
In [110]: np.ones((2, 3), dtype = int)
Out[110]:
array([[1, 1, 1],
[1, 1, 1]])
也可以这样
In [125]: a = np.ones((2, 3))
In [126]: a.astype(np.int32)
Out[126]:
array([[1, 1, 1],
[1, 1, 1]])
再总结下np.ones_like,其实类似
In [112]: np.ones_like(my_arr)
Out[112]: array([1, 1, 1, ..., 1, 1, 1])
补充full
In [115]: a = np.full((2, 2), 1)
其他类似于ones
2.再说一下eye和identity
eye可以创建单位矩阵,identity只能创建单位方阵
np.eye的k值可以调节,为1的对角线的位置偏离度,0居中,1向上偏离1,以此类推,-1向下偏离。
In [121]: np.eye(2, 3, dtype=int)
Out[121]:
array([[1, 0, 0],
[0, 1, 0]])
In [122]: np.eye(2, 3, k=1, dtype=int)
Out[122]:
array([[0, 1, 0],
[0, 0, 1]])
identity类似
3.再补充几个创建的函数
| 函数 |
说明 |
| np.linspace() |
根据起止数据等间距地填充数据,形成数组 |
| np.concatenate() |
将两个或多个数组合并成一个新的数组 |
Examples
--------
>>> np.linspace(2.0, 3.0, num=5)
array([ 2. , 2.25, 2.5 , 2.75, 3. ])
>>> np.linspace(2.0, 3.0, num=5, endpoint=False)
array([ 2. , 2.2, 2.4, 2.6, 2.8])
>>> np.linspace(2.0, 3.0, num=5, retstep=True)
(array([ 2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
我们可以看出,
第一个,第二个参数的作用分别为起始位置,终止位置, 且为[s, e]
第三个参数[num]表示分组的数量
第四个参数[endpoint]表示有木有e(end),是不是闭区间
第五个参数[retstep]如果为true,后面我们可以看到他的每次移动步数是多少
这里先做两个补充:
轴(axis): 保存数据的维度;秩(rank):轴的数量
>>> a = np.array([[1, 2], [3, 4]])
>>> b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
>>> np.concatenate((a, b.T), axis=1)
array([[1, 2, 5],
[3, 4, 6]])
ndArray数组的修改(通过修改使维度变换)
.
| 方法 |
说明 |
| .reshape(shape) |
不改变数组元素,返回一个shape形状的数组,原数组不变 |
| resize(shape) |
与.reshape()功能一致,但修改原数组 |
| .swapaxes(ax1,ax2) |
将数组n个维度中两个维度进行调换 |
| .flatten() |
对数组进行降维,返回折叠后的一维数组,原数组不变 |
In [140]: my_arr
Out[140]: array([ 0, 1, 2, ..., 999997, 999998, 999999])
In [141]: my_arr.shape
Out[141]: (1000000,)
In [142]: my_arr.reshape(2, 500000)
Out[142]:
array([[ 0, 1, 2, ..., 499997, 499998, 499999],
[500000, 500001, 500002, ..., 999997, 999998, 999999]])
In [143]: my_arr
Out[143]: array([ 0, 1, 2, ..., 999997, 999998, 999999])
注意:改变的元素数量应该跟原来的一致
In [144]: my_arr.resize(2, 500000)
In [145]: my_arr
Out[145]:
array([[ 0, 1, 2, ..., 499997, 499998, 499999],
[500000, 500001, 500002, ..., 999997, 999998, 999999]])
In [146]: my_arr.flatten()
Out[146]: array([ 0, 1, 2, ..., 999997, 999998, 999999])
In [147]: my_arr
Out[147]:
array([[ 0, 1, 2, ..., 499997, 499998, 499999],
[500000, 500001, 500002, ..., 999997, 999998, 999999]])