LLVM相关
环境搭建
PC
VMware Workstation
下载: https://www.vmware.com/go/getworkstation-win
KEY: ZC3WK-AFXEK-488JP-A7MQX-XL8YF (可自行网上查询或购买正版)
Ubuntu16.04.iso
下载: http://releases.ubuntu.com/16.04/ubuntu-16.04.3-desktop-amd64.iso
首先优雅地开启VMwarWorkstation软件, 按照下方图文操作.
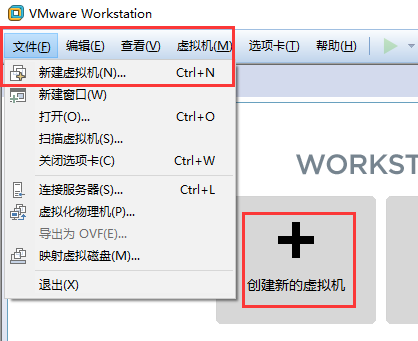
选择新建虚拟机
如果想要自己完整的安装ubuntu系统则需要选择"自定义", 想懒省事话选择"典型", 不过默认是英文环境.
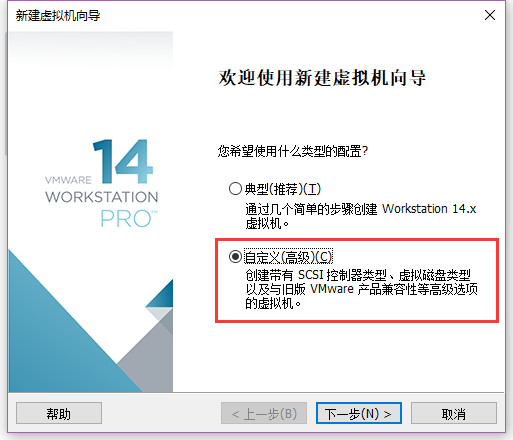
选择自定义
兼容性, 直接点下一步
这里选择稍后安装系统, 也可以选择第二项
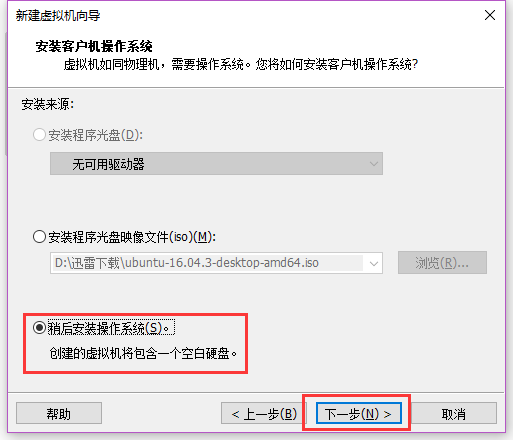
选择稍后安装
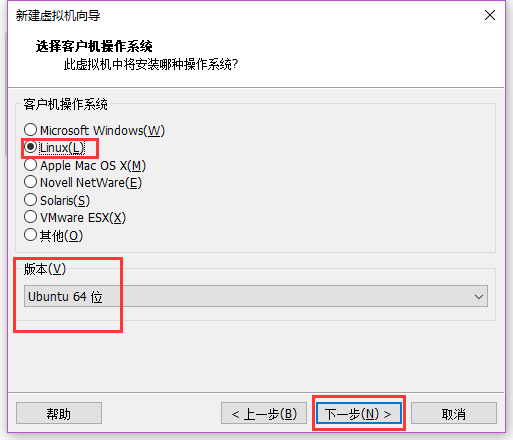
选择好对应系统和版本
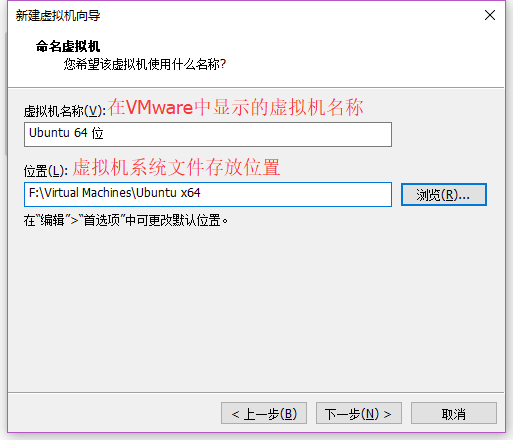
设置名称(不是虚拟机系统内的用户名)和系统文件存储位置
这里根据自己电脑配置选择, 我的CPU是I7 7700HQ, 4核8线程, 所以按照一半来设置
处理器数量: 核心数
内核数量: 线程
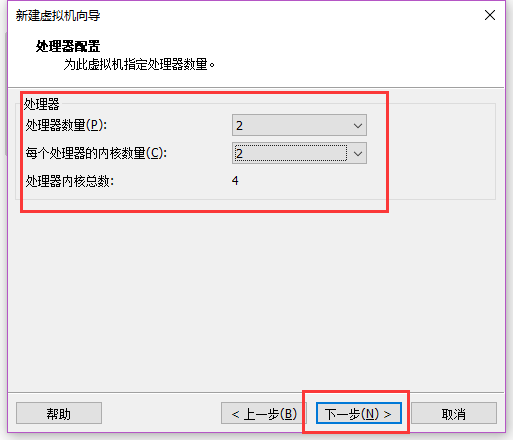
选择CPU数量
内存同样按照一半来配置,可根据自身主要使用哪个系统(PC/虚拟机)来进行配置
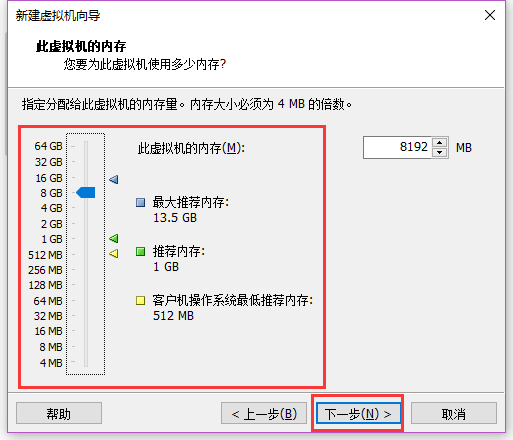
选择内存大小
网络连接方式使用默认的即可, 后期有需要可在"虚拟机"->"设置"中更改,这里不多作解释.
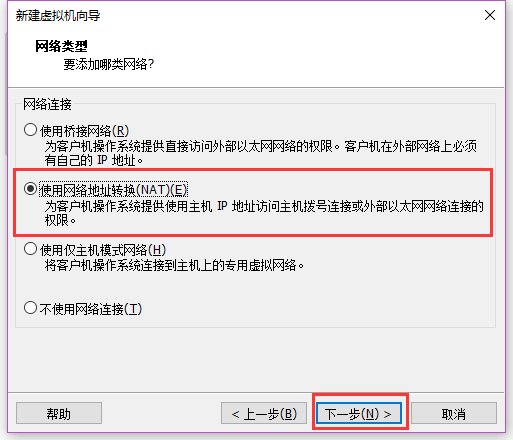
选择网络连接方式

IO选择,默认
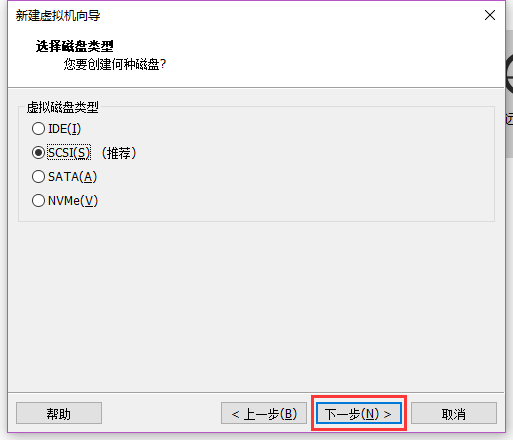
磁盘类型,同样默认
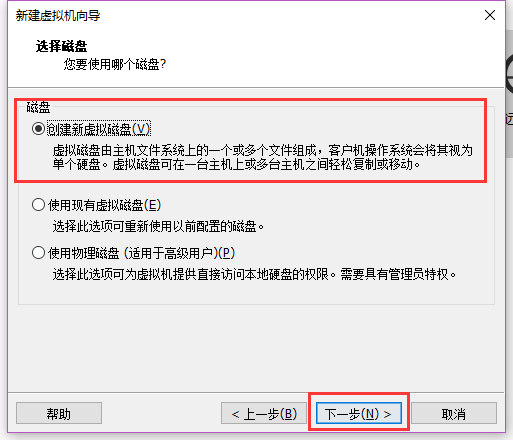
默认
勾选"立即分配所有磁盘空间"会导致在在设置完成后花费较长时间分配完整的50G空间, 如果没有特殊需求, 不推荐.
单/多个文件可根据自己选择,但总的来说,默认就好.
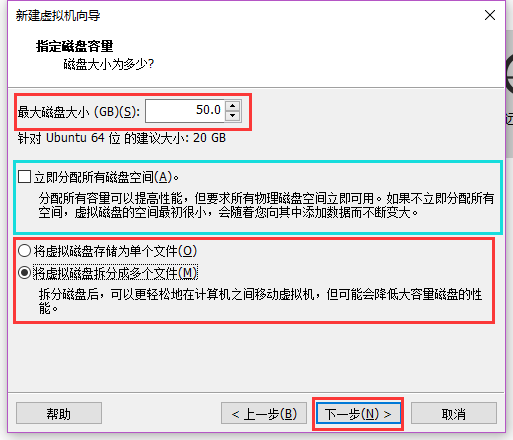
对磁盘大小进行设置, 其它默认

虚拟机启动文件,默认
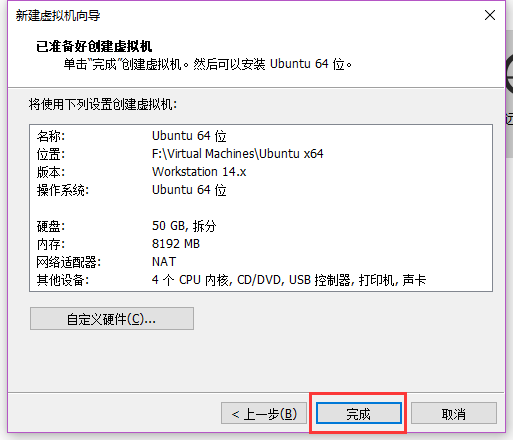
按下"完成"按钮
在左则"库"中选中虚拟机, 如果没有"库"的话, 在"查看" -> "自定义"中选择"库(F9)
点击标签页中的"编辑虚拟机设置" 或 菜单栏的"虚拟机" -> “设置”

打开设置窗口
然后,把系统镜像文件对准空壳的小口, 我们要开始往里塞了!
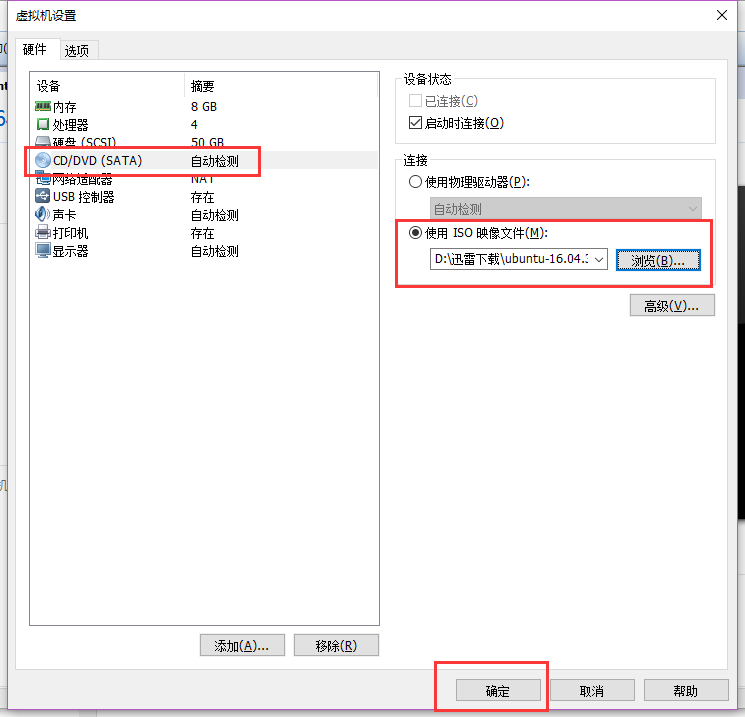
选择镜像文件
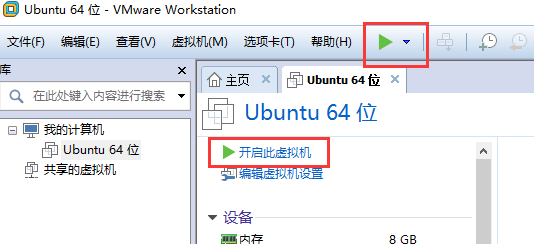
启动虚拟机
语言列表拉到最下选择中文, 也可以默认使用英文环境.
如果安装的时候选择了中文, 安装好后用户文件夹名称也是中文, 这对撸代码不利, 不过有可以将文件夹切换回英文的方法, 以后会说.
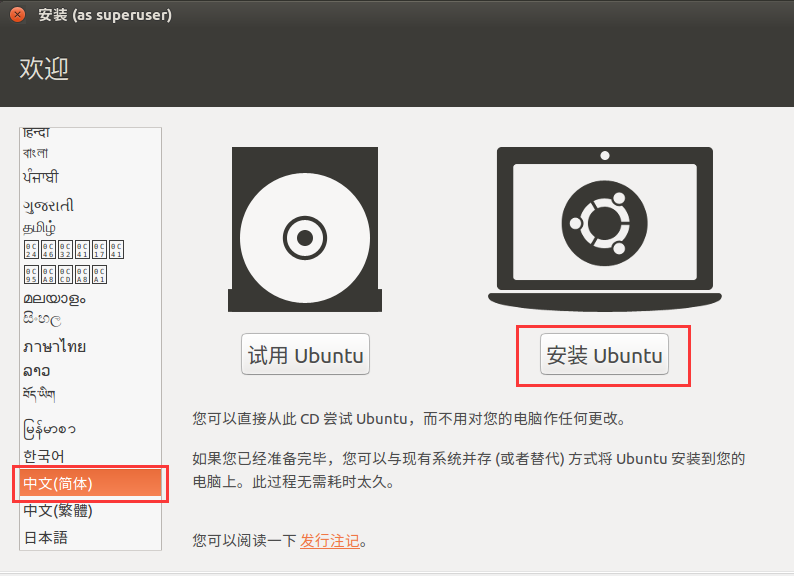
选择系统语言并开始安装系统
如果不选择"安装时下载更新"会节约安装时间, 但安装后好后系统肯定会提示更新(除非离线), 这个自行定夺.
关于"第三方软件", 如果不拿它当日常主力系统的话(你拿虚拟机当日常系统使用吗?),可以不勾选, 这项也可以安装好系统之后看到.
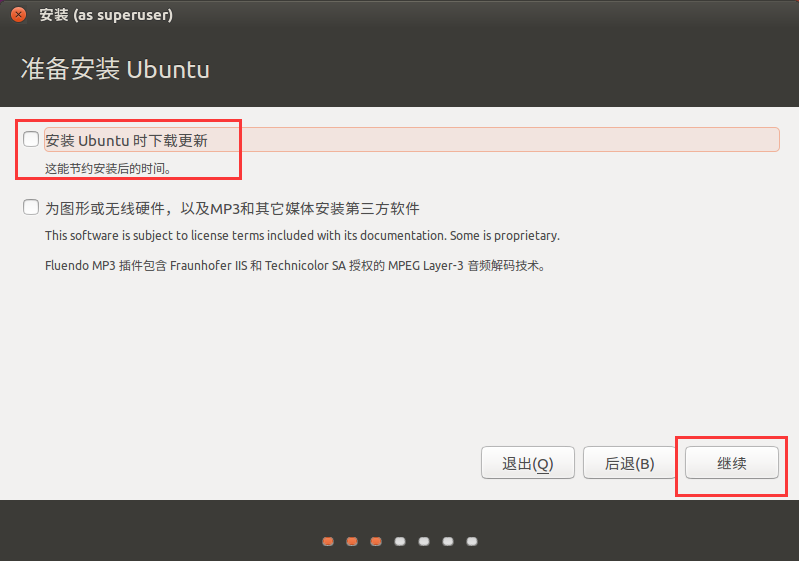
我们已经创造了存放系统的空壳, 自然是专用的啦.
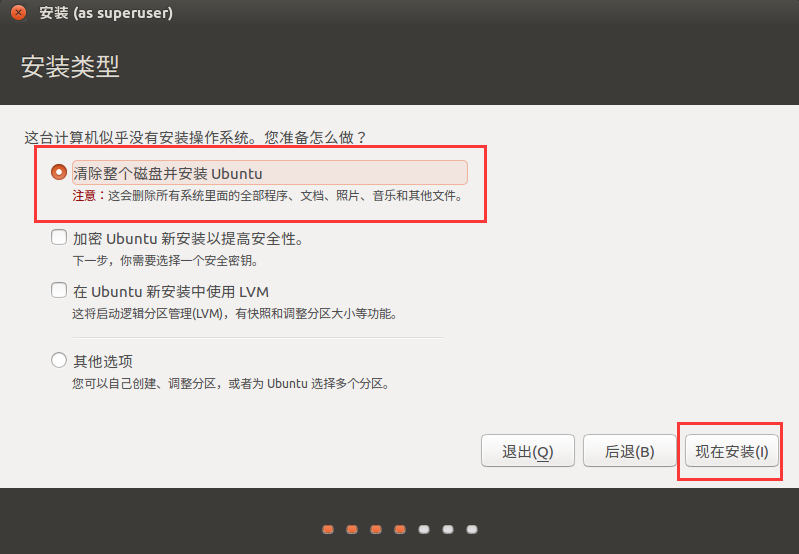
清除杂念, 开始安装
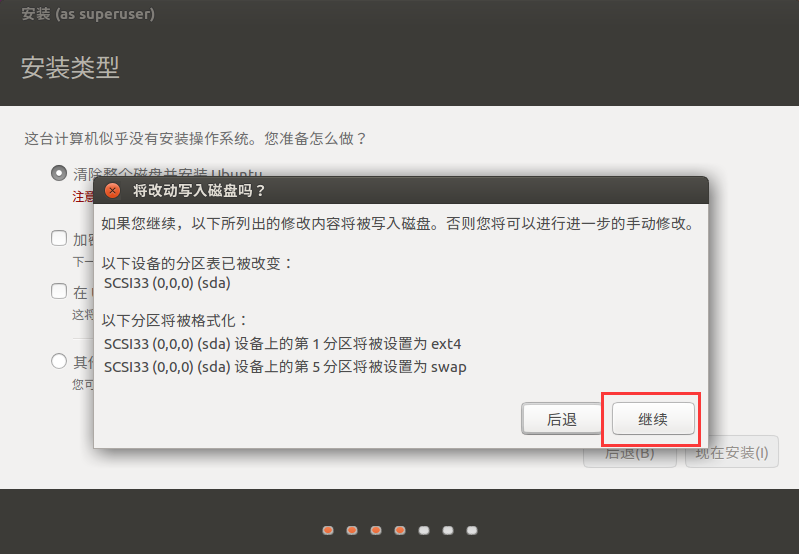
默认
时区选择, 貌似中国这一块点哪都显示的是"Shanghai", 所以不用在意.

选择时区
默认啦
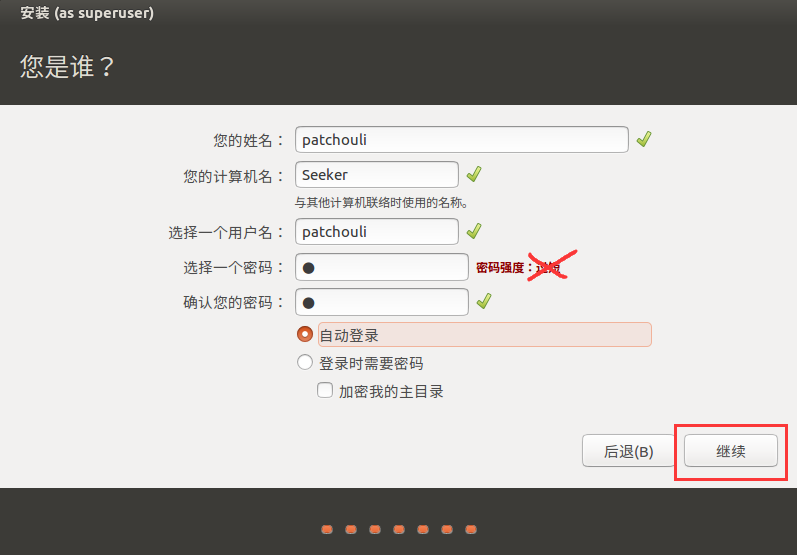
设置好你的用户账户
VMware
用VMware菜单里的功能安装
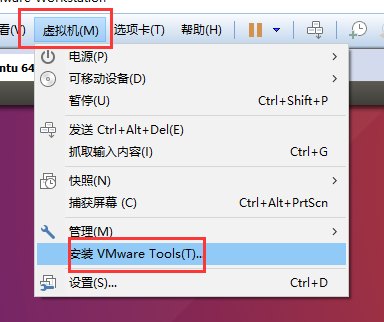
点击安装
这里会有一个提示, 现在虚拟机的光驱里应该塞的是Ubuntu的镜像, 而安装Tools需要从光驱中安装,所以要把镜像拔出来

拔出! 插入!
然后会在启动栏中看到光驱图标, 或者在文件中看到内容
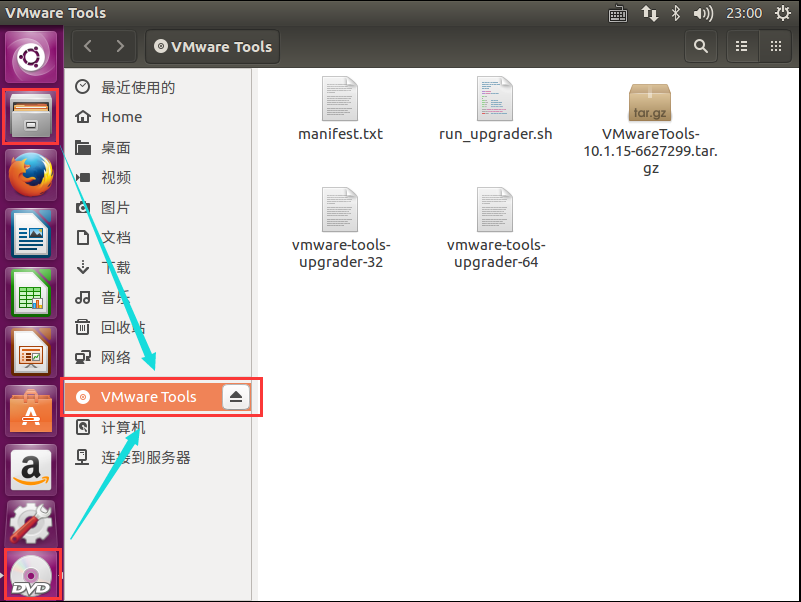
文件-> VMware Tools, 或者 直接点击DVD图标
接下来, 我们要使用这个安装包
Tools的安装包
把它移动到其它地方, 可以使用常规的复制粘贴, 或者使用终端命令行来执行:
\1. CTRL + ALT + T 打开终端
\2. 输入:cd /media/[用户名]/VMware Tools/
(善用TAB自动补全! 输入cd /me{tab}pat{tab}VM{tab} 就可以打出需要的路径)
\3. 输入: cp VM{tab}{空格}/home/pat{tab}Doc{tab} # 这里将安装包拷贝到文档目录下
\4. 切换到文档目录: cd /home/pat{tab}Doc{tab} 并查看有没有成功: ls

将安装包拷出来
\5. 输入 tar -xzvf VM{tab} ./IS
#tar和参数可自行查询, 目前只需要明白解压tar.gz文件需要这个命令即可
\6. 一长串信息刷屏后, 文件夹中会出现另一个文件夹(vmware-tools-distrib), 我们进入
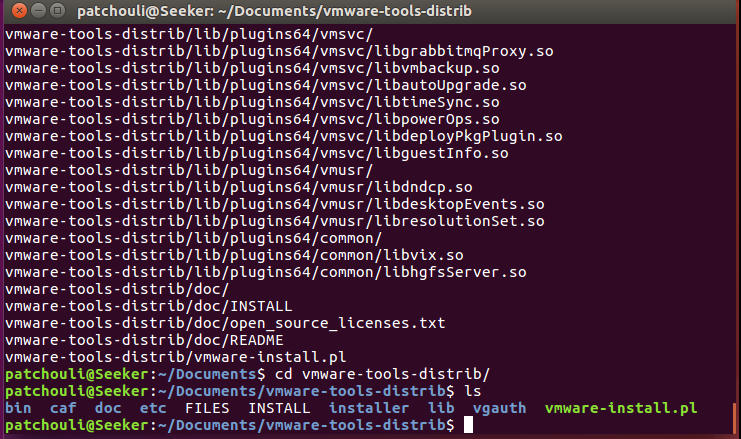
进入解压后的文件夹
\7. 输入: sudo ./vm{tab}
8.安装的时候会出现各种确认信息, 如果是[no]或[yes]就按一下y再回车, 如果只是文件路径, 直接回车.

出现[no]或者[yes]就输入一个y
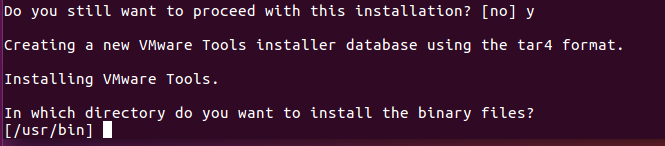
直接回车即可
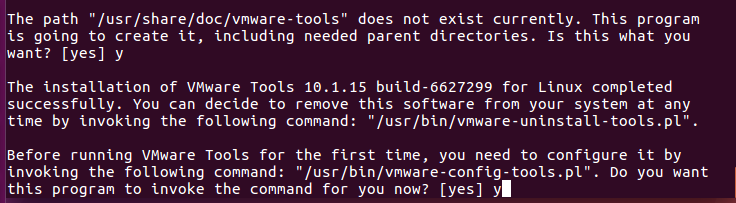
输入y
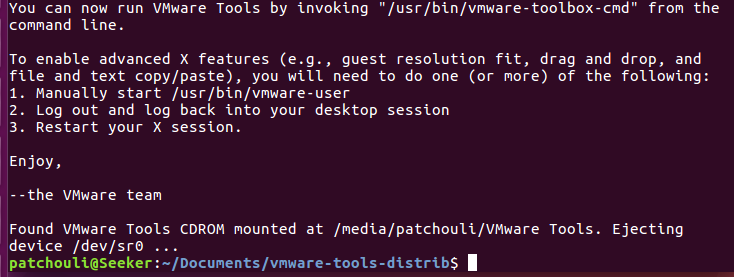
断断续续过后, 安装完成~
\9. 重启大法!
\10. 接下来可以随意使用拖拽, CTRL+XVC,或者右键来移动复制文件啦~
Root
1.首先设置root用户密码:
**sudo passwd root**
输入普通用户密码,再输入root用户密码;
2.启用登录时的root选项:
编辑50-ubuntu.conf文件:
**sudo gedit /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf**
添加:
greeter-show-manual-login=true
编辑/root/.profile文件:
**sudo gedit /root/.profile**
找到 mesg n这一行,修改为:
tty -s && mesg n
保存退出~
3.配置root自动登陆:
编辑lightdm.conf文件:
**sudo gedit /etc/lightdm/lightdm.conf**
添加如下内容:
[SeatDefaults]
autologin-user=root
greeter-session=unity-greeter
user-session=ubuntu
greeter-show-manual-login=true
allow-guest=false
保存重启完事~
LLVM release
用 sh -x test.sh 执行脚本就会这样,这是进入了调试模式,会打印每行被执行到的代码。
或者脚本里被加入了 set -x 和 set +x 调试开关。
遇到 vi 编辑器的上下左右方向金变成ABCD 时:
解决方法:
cp /etc/vim/vimrc ~/.vimrc
脚本安装
apt install vim
vim install_llvm.sh
#!/bin/bash
set -eux
LINUX_VER=${LINUX_VER:-ubuntu-16.04}
LLVM_VER=${LLVM_VER:-7.0.0}
PREFIX=${PREFIX:-${HOME}}
LLVM_DEP_URL=https://releases.llvm.org/${LLVM_VER}
TAR_NAME=clang+llvm-${LLVM_VER}-x86_64-linux-gnu-${LINUX_VER}
wget -q ${LLVM_DEP_URL}/${TAR_NAME}.tar.xz
tar -C ${PREFIX} -xf ${TAR_NAME}.tar.xz
rm ${TAR_NAME}.tar.xz
mv ${PREFIX}/${TAR_NAME} ${PREFIX}/clang+llvm
set +x
echo "Please set:"
echo "export PATH=\$PREFIX/clang+llvm/bin:\$PATH"
echo "export LD_LIBRARY_PATH=\$PREFIX/clang+llvm/lib:\$LD_LIBRARY_PATH"
chmod 777 install_llvm.sh
./install_llvm.sh
export PATH=/root/clang+llvm/bin:\$PATH
export LD_LIBRARY_PATH=/root/clang+llvcm/lib:\$LD_LIBRARY_PATH
apt update
getdit /etc/environment
PATH= :/root/clang+llvm/bin"
LD_LIBRARY_PATH="/root/clang+llvcm/lib"
source /etc/environment
reboot
root@ty-virtual-machine:~# clang -v
clang version 7.0.0 (tags/RELEASE_700/final)
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /root/clang+llvm/bin
Found candidate GCC installation: /usr/lib/gcc/x86_64-linux-gnu/5
Found candidate GCC installation: /usr/lib/gcc/x86_64-linux-gnu/5.4.0
Found candidate GCC installation: /usr/lib/gcc/x86_64-linux-gnu/6
Found candidate GCC installation: /usr/lib/gcc/x86_64-linux-gnu/6.0.0
Selected GCC installation: /usr/lib/gcc/x86_64-linux-gnu/5.4.0
Candidate multilib: .;@m64
Selected multilib: .;@m64
root@ty-virtual-machine:~# vim helloworld.c
//helloworld.c
#include <stdio.h>
int main() {
printf("hello world\n");
return 0;
}
root@ty-virtual-machine:~# clang helloworld.c -o hello.out
root@ty-virtual-machine:~# ./hello.out
hello world
root@ty-virtual-machine:~# vim helloworld.cpp
//helloworld.cpp
#include <iostream>
using namespace std;
int main() {
cout << "hello world" << endl;
return 0;
}
root@ty-virtual-machine:~# clang++ helloworld.cpp -o hello.out
root@ty-virtual-machine:~# ./hello.out
hello world
Clang(Clang++)使用
我们先随便写一段以下代码:
//test.cpp
#include <iostream>
#include <algorithm>
using namespace std;
int a[10] = {4,2,7,5,6,1,8,9,3,0};
int main() {
for(int i = 0; i < 10; ++i)
cout << a[i] << (i == 9?"\n":" ");
sort(a,a+10);
for(int i = 0; i < 10; ++i)
cout << a[i] << (i == 9?"\n":" ");
return 0;
}
3.1.生成预处理文件:
$ clang++ -E test.cpp -o test.i
3.2.生成汇编程序:
$ clang++ -S test.i

3.3.生成目标文件:
$ clang++ -c test.s

3.4.生成可执行文件:
$ clang++ -o test.out test.o

emm…和GCC大致还是一样的嘛 非常的好用。
3.5.查看Clang编译的过程
$ clang -ccc-print-phases A.c
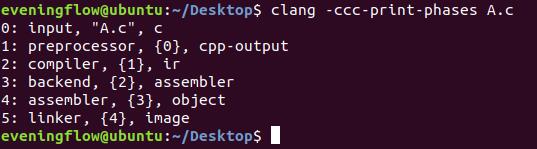
- 0.获取输入:A.c文件,C语言
- 1.预处理器:处理define、include等
- 2.编译:生成中间代码(IR)
- 3.后端:生成汇编代码
- 4.汇编:生成目标代码
- 5.链接器:链接其他动态库
3.6.词法分析
$ clang -fmodules -E -Xclang -dump-tokens A.c
如图,写一个小函数对其进行词法分析。
3.7.语法分析
$ clang -fmodules -fsyntax-only -Xclang -ast-dump A.c
生成语法树如下:
有颜色区分还是比较美观的。
3.8.语义分析
生成LLVM IR。LLVM IR有3种表示形式(本质是等价的)
- (1).text:便于阅读的文本格式,类似于汇编语言,拓展名.ll
- (2).memory:内存格式
- (3).bitcode:二进制格式,拓展名.bc
生成text格式:
$ clang -S -emit-llvm A.c
1.3 Linux 基础c
常用基础命令
ls 用来显示目标列表
cd [path] 用来切换工作目录
pwd 以绝对路径的方式显示用户当前工作目录
man [command] 查看Linux中的指令帮助、配置文件帮助和编程帮助等信息
apropos [whatever] 在一些特定的包含系统命令的简短描述的数据库文件里查找关键字
echo [string] 打印一行文本,参数“-e”可激活转义字符
cat [file] 连接文件并打印到标准输出设备上
less [file] 允许用户向前或向后浏览文字档案的内容
mv [file1] [file2] 用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中
cp [file1] [file2] 用来将一个或多个源文件或者目录复制到指定的目的文件或目录
rm [file] 可以删除一个目录中的一个或多个文件或目录,也可以将某个目录及其下属的所有文件及其子目录均删除掉
ps 用于报告当前系统的进程状态
top 实时查看系统的整体运行情况
kill 杀死一个进程
ifconfig 查看或设置网络设备
ping 查看网络上的主机是否工作
netstat 显示网络连接、路由表和网络接口信息
nc(netcat) 建立 TCP 和 UDP 连接并监听
su 切换当前用户身份到其他用户身份
touch [file] 创建新的空文件
mkdir [dir] 创建目录
chmod 变更文件或目录的权限
chown 变更某个文件或目录的所有者和所属组
nano / vim / emacs 字符终端的文本编辑器
exit 退出 shell
使用变量:
var=value 给变量var赋值value
$var, ${var} 取变量的值
`cmd`, $(cmd) 代换标准输出
'string' 非替换字符串
"string" 可替换字符串
$ var="test";
$ echo $var
test
$ echo 'This is a $var';
This is a $var
$ echo "This is a $var";
This is a test
$ echo `date`;
2017年 11月 06日 星期一 14:40:07 CST
$ $(bash)
$ echo $0
/bin/bash
$ $($0)
Bash 快捷键
Up(Down) 上(下)一条指令
Ctrl + c 终止当前进程
Ctrl + z 挂起当前进程,使用“fg”可唤醒
Ctrl + d 删除光标处的字符
Ctrl + l 清屏
Ctrl + a 移动到命令行首
Ctrl + e 移动到命令行尾
Ctrl + b 按单词后移(向左)
Ctrl + f 按单词前移(向右)
Ctrl + Shift + c 复制
Ctrl + Shift + v 粘贴
更多细节请查看:Bash Keyboard Shortcuts
根目录结构
$ uname -a
Linux manjaro 4.11.5-1-ARCH #1 SMP PREEMPT Wed Jun 14 16:19:27 CEST 2017 x86_64 GNU/Linux
$ ls -al /
drwxr-xr-x 17 root root 4096 Jun 28 20:17 .
drwxr-xr-x 17 root root 4096 Jun 28 20:17 ..
lrwxrwxrwx 1 root root 7 Jun 21 22:44 bin -> usr/bin
drwxr-xr-x 4 root root 4096 Aug 10 22:50 boot
drwxr-xr-x 20 root root 3140 Aug 11 11:43 dev
drwxr-xr-x 101 root root 4096 Aug 14 13:54 etc
drwxr-xr-x 3 root root 4096 Apr 8 19:59 home
lrwxrwxrwx 1 root root 7 Jun 21 22:44 lib -> usr/lib
lrwxrwxrwx 1 root root 7 Jun 21 22:44 lib64 -> usr/lib
drwx------ 2 root root 16384 Apr 8 19:55 lost+found
drwxr-xr-x 2 root root 4096 Oct 1 2015 mnt
drwxr-xr-x 15 root root 4096 Jul 15 20:10 opt
dr-xr-xr-x 267 root root 0 Aug 3 09:41 proc
drwxr-x--- 9 root root 4096 Jul 22 22:59 root
drwxr-xr-x 26 root root 660 Aug 14 21:08 run
lrwxrwxrwx 1 root root 7 Jun 21 22:44 sbin -> usr/bin
drwxr-xr-x 4 root root 4096 May 28 22:07 srv
dr-xr-xr-x 13 root root 0 Aug 3 09:41 sys
drwxrwxrwt 36 root root 1060 Aug 14 21:27 tmp
drwxr-xr-x 11 root root 4096 Aug 14 13:54 usr
drwxr-xr-x 12 root root 4096 Jun 28 20:17 var
由于不同的发行版会有略微的不同,我们这里使用的是基于 Arch 的发行版 Manjaro,以上就是根目录下的内容,我们介绍几个重要的目录:
-
/bin、/sbin:链接到 /usr/bin,存放 Linux 一些核心的二进制文件,其包含的命令可在 shell 上运行。
-
/boot:操作系统启动时要用到的程序。
-
/dev:包含了所有 Linux 系统中使用的外部设备。需要注意的是这里并不是存放外部设备的驱动程序,而是一个访问这些设备的端口。
-
/etc:存放系统管理时要用到的各种配置文件和子目录。
-
/etc/rc.d:存放 Linux 启动和关闭时要用到的脚本。
-
/home:普通用户的主目录。
-
/lib、/lib64:链接到 /usr/lib,存放系统及软件需要的动态链接共享库。
-
/mnt:这个目录让用户可以临时挂载其他的文件系统。
-
/proc:虚拟的目录,是系统内存的映射。可直接访问这个目录来获取系统信息。
-
/root:系统管理员的主目录。
-
/srv:存放一些服务启动之后需要提取的数据。
-
/sys:该目录下安装了一个文件系统 sysfs。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建时,对应的文件和目录也在内核对象子系统中被创建。
-
/tmp:公用的临时文件存放目录。
-
/usr:应用程序和文件几乎都在这个目录下。
-
/usr/src:内核源代码的存放目录。
-
/var:存放了很多服务的日志信息。
进程管理
- top
- ps
- 用于报告当前系统的进程状态。可以搭配 kill 指令随时中断、删除不必要的程序。
- 查看某进程的状态:
$ ps -aux | grep [file],其中返回内容最左边的数字为进程号(PID)。
- kill
- 用来删除执行中的程序或工作。
- 删除进程某 PID 指定的进程:
$ kill [PID]
UID 和 GID
Linux 是一个支持多用户的操作系统,每个用户都有 User ID(UID) 和 Group ID(GID),UID 是对一个用户的单一身份标识,而 GID 则对应多个 UID。知道某个用户的 UID 和 GID 是非常有用的,一些程序可能就需要 UID/GID 来运行。可以使用 id 命令来查看:
$ id rootuid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel),19(log)$ id firmyuid=1000(firmy) gid=1000(firmy) groups=1000(firmy),3(sys),7(lp),10(wheel),90(network),91(video),93(optical),95(storage),96(scanner),98(power),56(bumblebee)
UID 为 0 的 root 用户类似于系统管理员,它具有系统的完全访问权。我自己新建的用户 firmy,其 UID 为 1000,是一个普通用户。GID 的关系存储在 /etc/group 文件中:
$ cat /etc/grouproot:x:0:rootbin:x:1:root,bin,daemondaemon:x:2:root,bin,daemonsys:x:3:root,bin,firmy......
所有用户的信息(除了密码)都保存在 /etc/passwd 文件中,而为了安全起见,加密过的用户密码保存在 /etc/shadow 文件中,此文件只有 root 权限可以访问。
$ sudo cat /etc/shadowroot:$6$root$wvK.pRXFEH80GYkpiu1tEWYMOueo4tZtq7mYnldiyJBZDMe.mKwt.WIJnehb4bhZchL/93Oe1ok9UwxYf79yR1:17264::::::firmy:$6$firmy$dhGT.WP91lnpG5/10GfGdj5L1fFVSoYlxwYHQn.llc5eKOvr7J8nqqGdVFKykMUSDNxix5Vh8zbXIapt0oPd8.:17264:0:99999:7:::
由于普通用户的权限比较低,这里使用 sudo 命令可以让普通用户以 root 用户的身份运行某一命令。使用 su 命令则可以切换到一个不同的用户:
$ whoamifirmy$ su root# whoamiroot
whoami 用于打印当前有效的用户名称,shell 中普通用户以 $ 开头,root 用户以 # 开头。在输入密码后,我们已经从 firmy 用户转换到 root 用户了。
权限设置
在 Linux 中,文件或目录权限的控制分别以读取、写入、执行 3 种一般权限来区分,另有 3 种特殊权限可供运用。
使用 ls -l [file] 来查看某文件或目录的信息:
$ ls -l /lrwxrwxrwx 1 root root 7 Jun 21 22:44 bin -> usr/bindrwxr-xr-x 4 root root 4096 Jul 28 08:48 boot-rw-r--r-- 1 root root 18561 Apr 2 22:48 desktopfs-pkgs.txt
第一栏从第二个字母开始就是权限字符串,权限表示三个为一组,依次是所有者权限、组权限、其他人权限。每组的顺序均为 rwx,如果有相应权限,则表示成相应字母,如果不具有相应权限,则用 - 表示。
-
r:读取权限,数字代号为 “4”
-
w:写入权限,数字代号为 “2”
-
x:执行或切换权限,数字代号为 “1”
通过第一栏的第一个字母可知,第一行是一个链接文件 (l),第二行是个目录(d),第三行是个普通文件(-)。
用户可以使用 chmod 指令去变更文件与目录的权限。权限范围被指定为所有者(u)、所属组(g)、其他人(o)和所有人(a)。
- -R:递归处理,将指令目录下的所有文件及子目录一并处理;
- <权限范围>+<权限设置>:开启权限范围的文件或目录的该选项权限设置
-
$ chmod a+r [file]:赋予所有用户读取权限
- <权限范围>-<权限设置>:关闭权限范围的文件或目录的该选项权限设置
-
$ chmod u-w [file]:取消所有者写入权限
- <权限范围>=<权限设置>:指定权限范围的文件或目录的该选项权限设置;
-
$ chmod g=x [file]:指定组权限为可执行
-
$ chmod o=rwx [file]:制定其他人权限为可读、可写和可执行

字节序
目前计算机中采用两种字节存储机制:大端(Big-endian)和小端(Little-endian)。
MSB (Most Significan Bit/Byte):最重要的位或最重要的字节。
LSB (Least Significan Bit/Byte):最不重要的位或最不重要的字节。
Big-endian 规定 MSB 在存储时放在低地址,在传输时放在流的开始;LSB 存储时放在高地址,在传输时放在流的末尾。Little-endian 则相反。常见的 Intel 处理器使用 Little-endian,而 PowerPC 系列处理器则使用 Big-endian,另外 TCP/IP 协议和 Java 虚拟机的字节序也是 Big-endian。
例如十六进制整数 0x12345678 存入以 1000H 开始的内存中:
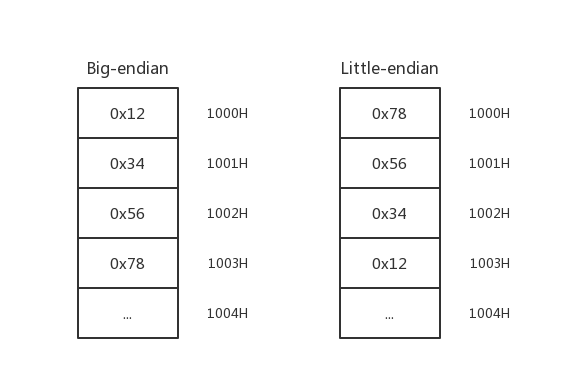
我们在内存中实际地看一下,在地址 0xffffd584 处有字符 1234,在地址 0xffffd588 处有字符 5678。
gdb-peda$ x/w 0xffffd584
0xffffd584: 0x34333231
gdb-peda$ x/4wb 0xffffd584
0xffffd584: 0x31 0x32 0x33 0x34
gdb-peda$ python print('\x31\x32\x33\x34')
1234
gdb-peda$ x/w 0xffffd588
0xffffd588: 0x38373635
gdb-peda$ x/4wb 0xffffd588
0xffffd588: 0x35 0x36 0x37 0x38
gdb-peda$ python print('\x35\x36\x37\x38')
5678
gdb-peda$ x/2w 0xffffd584
0xffffd584: 0x34333231 0x38373635
gdb-peda$ x/8wb 0xffffd584
0xffffd584: 0x31 0x32 0x33 0x34 0x35 0x36 0x37 0x38
gdb-peda$ python print('\x31\x32\x33\x34\x35\x35\x36\x37\x38')
123455678
db-peda$ x/s 0xffffd584
0xffffd584: "12345678"
输入输出
- 使用命令的输出作为可执行文件的输入参数
-
$ ./vulnerable your_command_here``
$ ./vulnerable $(your_command_here)
- 使用命令作为输入
$ your_command_here | ./vulnerable
- 将命令行输出写入文件
$ your_command_here > filename
- 使用文件作为输入
$ ./vulnerable < filename
文件描述符
在 Linux 系统中一切皆可以看成是文件,文件又分为:普通文件、目录文件、链接文件和设备文件。文件描述符(file descriptor)是内核管理已被打开的文件所创建的索引,使用一个非负整数来指代被打开的文件。
标准文件描述符如下:
| 文件描述符 |
用途 |
stdio 流 |
| 0 |
标准输入 |
stdin |
| 1 |
标准输出 |
stdout |
| 2 |
标准错误 |
stderr |
当一个程序使用 fork() 生成一个子进程后,子进程会继承父进程所打开的文件表,此时,父子进程使用同一个文件表,这可能导致一些安全问题。如果使用 vfork(),子进程虽然运行于父进程的空间,但拥有自己的进程表项。
核心转储
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存、寄存器状态、堆栈指针、内存管理信息等记录下来,保存在一个文件中,这种行为就叫做核心转储(Core Dump)。
会产生核心转储的信号
| Signal |
Action |
Comment |
| SIGQUIT |
Core |
Quit from keyboard |
| SIGILL |
Core |
Illegal Instruction |
| SIGABRT |
Core |
Abort signal from abort |
| SIGSEGV |
Core |
Invalid memory reference |
| SIGTRAP |
Core |
Trace/breakpoint trap |
开启核心转储
-
输入命令 ulimit -c,输出结果为 0,说明默认是关闭的。
-
输入命令 ulimit -c unlimited 即可在当前终端开启核心转储功能。
-
如果想让核心转储功能永久开启,可以修改文件 /etc/security/limits.conf,增加一行:
#<domain> <type> <item> <value>* soft core unlimited
修改转储文件保存路径
-
通过修改 /proc/sys/kernel/core_uses_pid,可以使生成的核心转储文件名变为 core.[pid] 的模式。
# echo 1 > /proc/sys/kernel/core_uses_pid
-
还可以修改 /proc/sys/kernel/core_pattern 来控制生成核心转储文件的保存位置和文件名格式。
# echo /tmp/core-%e-%p-%t > /proc/sys/kernel/core_pattern
此时生成的文件保存在 /tmp/ 目录下,文件名格式为 core-[filename]-[pid]-[time]。
使用 gdb 调试核心转储文件
gdb [filename] [core file]
例子
$ cat core.c
#include <stdio.h>
void main(int argc, char **argv) {
char buf[5];
scanf("%s", buf);
}
$ gcc -m32 -fno-stack-protector core.c
$ ./a.out
AAAAAAAAAAAAAAAAAAAA
Segmentation fault (core dumped)
$ file /tmp/core-a.out-12444-1503198911
/tmp/core-a.out-12444-1503198911: ELF 32-bit LSB core file Intel 80386, version 1 (SYSV), SVR4-style, from './a.out', real uid: 1000, effective uid: 1000, real gid: 1000, effective gid: 1000, execfn: './a.out', platform: 'i686'
$ gdb a.out /tmp/core-a.out-12444-1503198911 -q
Reading symbols from a.out...(no debugging symbols found)...done.
[New LWP 12444]
Core was generated by `./a.out'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x5655559b in main ()
gdb-peda$ info frame
Stack level 0, frame at 0x41414141:
eip = 0x5655559b in main; saved eip = <not saved>
Outermost frame: Cannot access memory at address 0x4141413d
Arglist at 0x41414141, args:
Locals at 0x41414141, Previous frame's sp is 0x41414141
Cannot access memory at address 0x4141413d
调用约定
函数调用约定是对函数调用时如何传递参数的一种约定。关于它的约定有许多种,下面我们分别从内核接口和用户接口介绍 32 位和 64 位 Linux 的调用约定。
内核接口
x86-32 系统调用约定:Linux 系统调用使用寄存器传递参数。eax 为 syscall_number,ebx、ecx、edx、esi、ebp 用于将 6 个参数传递给系统调用。返回值保存在 eax 中。所有其他寄存器(包括 EFLAGS)都保留在 int 0x80 中。
x86-64 系统调用约定:内核接口使用的寄存器有:rdi、rsi、rdx、r10、r8、r9。系统调用通过 syscall 指令完成。除了 rcx、r11 和 rax,其他的寄存器都被保留。系统调用的编号必须在寄存器 rax 中传递。系统调用的参数限制为 6 个,不直接从堆栈上传递任何参数。返回时,rax 中包含了系统调用的结果。而且只有 INTEGER 或者 MEMORY 类型的值才会被传递给内核。
用户接口
x86-32 函数调用约定:参数通过栈进行传递。最后一个参数第一个被放入栈中,直到所有的参数都放置完毕,然后执行 call 指令。这也是 Linux 上 C 语言函数的方式。
x86-64 函数调用约定:x86-64 下通过寄存器传递参数,这样做比通过栈有更高的效率。它避免了内存中参数的存取和额外的指令。根据参数类型的不同,会使用寄存器或传参方式。如果参数的类型是 MEMORY,则在栈上传递参数。如果类型是 INTEGER,则顺序使用 rdi、rsi、rdx、rcx、r8 和 r9。所以如果有多于 6 个的 INTEGER 参数,则后面的参数在栈上传递。
环境变量
环境变量字符串都是 name=value 这样的形式。大多数 name 由大写字母加下画线组成,一般把 name 部分叫做环境变量名,value 部分则是环境变量的值,而且 value 需要以 “/0” 结尾,环境变量定义了该进程的运行环境。
分类
- 按照生命周期划分
- 永久环境变量:修改相关配置文件,永久生效。
- 临时环境变量:使用
export 命令,在当前终端下生效,关闭终端后失效。
- 按照作用域划分
- 系统环境变量:对该系统中所有用户生效。
- 用户环境变量:对特定用户生效。
设置方法
-
在文件 /etc/profile 中添加变量,这种方法对所有用户永久生效。如:
# Set our default
pathPATH="/usr/local/sbin:/usr/local/bin:/usr/bin"
export PATH
添加后执行命令 source /etc/profile 使其生效。
-
在文件 ~/.bash_profile 中添加变量,这种方法对当前用户永久生效。其余同上。
-
直接运行命令 export 定义变量,这种方法只对当前终端临时生效。
常用变量
使用命令 echo 打印变量:
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/bin:/usr/lib/jvm/default/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl
$ echo $HOME
/home/firmy
$ echo $LOGNAME
firmy
$ echo $HOSTNAME
firmy-pc
$ echo $SHELL
/bin/bash
$ echo $LANG
en_US.UTF-8
使用命令 env 可以打印出所有环境变量:
$ env
COLORFGBG=15;0
COLORTERM=truecolor
...
使用命令 set 可以打印出所有本地定义的 shell 变量:
$ set'!'=0'#'=0...
使用命令 unset 可以清除变量:
unset $变量名
LD_PRELOAD
该环境变量可以定义在程序运行前优先加载的动态链接库。在 pwn 题目中,我们可能需要一个特定的 libc,这时就可以定义该变量:
LD_PRELOAD=/path/to/libc.so ./binary
一个例子:
$ ldd /bin/true
linux-vdso.so.1 => (0x00007fff9a9fe000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1c083d9000)
/lib64/ld-linux-x86-64.so.2 (0x0000557bcce6c000)
$ LD_PRELOAD=~/libc.so.6 ldd /bin/true
linux-vdso.so.1 => (0x00007ffee55e9000)
/home/firmy/libc.so.6 (0x00007f4a28cfc000)
/lib64/ld-linux-x86-64.so.2 (0x000055f33bc50000)
注意,在加载动态链接库时需要使用 ld.so 进行重定位,通常被符号链接到 /lib64/ld-linux-x86-64.so 中。动态链接库在编译时隐式指定 ld.so 的搜索路径,并写入 ELF Header 的 INTERP 字段中。从其他发行版直接拷贝已编译的 .so 文件可能会引发 ld.so 搜索路径不正确的问题。相似的,在版本依赖高度耦合的发行版中(如 ArchLinux),版本相差过大也会引发 ld.so 的运行失败。
本地同版本编译后通常不会出现问题。如果有直接拷贝已编译版本的需要,可以对比 interpreter 确定是否符合要求,但是不保证不会失败。
上面的例子中两个 libc 是这样的:
$ file /lib/x86_64-linux-gnu/libc-2.23.so
/lib/x86_64-linux-gnu/libc-2.23.so: ELF 64-bit LSB shared object, x86-64, version 1 (GNU/Linux), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=088a6e00a1814622219f346b41e775b8dd46c518, for GNU/Linux 2.6.32, stripped
$ file ~/libc.so.6
/home/firmy/libc.so.6: ELF 64-bit LSB shared object, x86-64, version 1 (GNU/Linux), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=088a6e00a1814622219f346b41e775b8dd46c518, for GNU/Linux 2.6.32, stripped
都是 interpreter /lib64/ld-linux-x86-64.so.2,所以可以替换。
而下面的例子是在 Arch Linux 上使用一个 Ubuntu 的 libc,就会出错:
$ ldd /bin/true
linux-vdso.so.1 (0x00007ffc969df000)
libc.so.6 => /usr/lib/libc.so.6 (0x00007f7ddde17000)
/lib64/ld-linux-x86-64.so.2 => /usr/lib64/ld-linux-x86-64.so.2 (0x00007f7dde3d7000)
$ LD_PRELOAD=~/libc.so.6 ldd /bin/true
Illegal instruction (core dumped)
一个在 interpreter /usr/lib/ld-linux-x86-64.so.2,而另一个在 interpreter /lib64/ld-linux-x86-64.so.2。
environ
libc 中定义的全局变量 environ 指向环境变量表。而环境变量表存在于栈上,所以通过 environ 指针的值就可以泄露出栈地址。
gdb-peda$ vmmap libc
Start End Perm Name
0x00007ffff7a1c000 0x00007ffff7bcf000 r-xp /usr/lib/libc-2.27.so
0x00007ffff7bcf000 0x00007ffff7dce000 ---p /usr/lib/libc-2.27.so
0x00007ffff7dce000 0x00007ffff7dd2000 r--p /usr/lib/libc-2.27.so
0x00007ffff7dd2000 0x00007ffff7dd4000 rw-p /usr/lib/libc-2.27.so
gdb-peda$ vmmap stack
Start End Perm Name
0x00007ffffffde000 0x00007ffffffff000 rw-p [stack]
gdb-peda$ shell nm -D /usr/lib/libc-2.27.so | grep environ
00000000003b8ee0 V environ
00000000003b8ee0 V _environ
00000000003b8ee0 B __environ
gdb-peda$ x/gx 0x00007ffff7a1c000 + 0x00000000003b8ee0
0x7ffff7dd4ee0 <environ>: 0x00007fffffffde48
gdb-peda$ x/5gx 0x00007fffffffde48
0x7fffffffde48: 0x00007fffffffe1da 0x00007fffffffe1e9
0x7fffffffde58: 0x00007fffffffe1fd 0x00007fffffffe233
0x7fffffffde68: 0x00007fffffffe25f
gdb-peda$ x/5s 0x00007fffffffe1da
0x7fffffffe1da: "COLORFGBG=15;0"
0x7fffffffe1e9: "COLORTERM=truecolor"
0x7fffffffe1fd: "DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/1000/bus"
0x7fffffffe233: "DESKTOP_SESSION=/usr/share/xsessions/plasma"
0x7fffffffe25f: "DISPLAY=:0"
procfs
procfs 文件系统是 Linux 内核提供的虚拟文件系统,为访问系统内核数据的操作提供接口。之所以说是虚拟文件系统,是因为它不占用存储空间,而只是占用了内存。用户可以通过 procfs 查看有关系统硬件及当前正在运行进程的信息,甚至可以通过修改其中的某些内容来改变内核的运行状态。
/proc/cmdline
在启动时传递给内核的相关参数信息,通常由 lilo 或 grub 等启动管理工具提供:
$ cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-4.14-x86_64 root=UUID=8e79a67d-af1b-4203-8c1c-3b670f0ec052 rw quiet resume=UUID=a220ecb1-7fde-4032-87bf-413057e9c06f
/proc/cpuinfo
记录 CPU 相关的信息:
$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i5-4210H CPU @ 2.90GHz
stepping : 3
microcode : 0x24
cpu MHz : 1511.087
cache size : 3072 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt dtherm ida arat pln pts
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass
bogomips : 5788.66
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
power management:
...
/proc/crypto
已安装的内核所使用的密码算法及算法的详细信息:
$ cat /proc/crypto
name : ccm(aes)
driver : ccm_base(ctr(aes-aesni),cbcmac(aes-aesni))
module : ccm
priority : 300
refcnt : 2
selftest : passed
internal : no
type : aead
async : no
blocksize : 1
ivsize : 16
maxauthsize : 16
geniv : <none>
...
/proc/devices
已加载的所有块设备和字符设备的信息,包含主设备号和设备组(与主设备号对应的设备类型)名:
$ cat /proc/devices
Character devices:
1 mem
4 /dev/vc/0
4 tty
4 ttyS
5 /dev/tty
5 /dev/console
...
/proc/interrupts
X86/X86_64 系统上每个 IRQ 相关的中断号列表,多路处理器平台上每个 CPU 对于每个 I/O 设备均有自己的中断号:
$ cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 15 0 0 0 IR-IO-APIC 2-edge timer
1: 46235 1277 325 156 IR-IO-APIC 1-edge i8042
8: 0 1 0 0 IR-IO-APIC 8-edge rtc0
...
NMI: 0 0 0 0 Non-maskable interrupts
LOC: 7363806 5569019 6138317 5442200 Local timer interrupts
SPU: 0 0 0 0 Spurious interrupts
...
/proc/kcore
系统使用的物理内存,以 ELF 核心文件(core file)格式存储:
$ sudo file /proc/kcore
/proc/kcore: ELF 64-bit LSB core file x86-64, version 1 (SYSV), SVR4-style, from 'BOOT_IMAGE=/boot/vmlinuz-4.14-x86_64 root=UUID=8e79a67d-af1b-4203-8c1c-3b670f0e'
/proc/meminfo
系统中关于当前内存的利用状况等的信息:
$ cat /proc/meminfo
MemTotal: 12226252 kB
MemFree: 4909444 kB
MemAvailable: 8776048 kB
Buffers: 288236 kB
Cached: 3953616 kB
...
/proc/mounts
每个进程自身挂载名称空间中的所有挂载点列表文件的符号链接:
$ cat /proc/mounts
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
sys /sys sysfs rw,nosuid,nodev,noexec,relatime 0 0
dev /dev devtmpfs rw,nosuid,relatime,size=6106264k,nr_inodes=1526566,mode=755 0 0
...
/proc/modules
当前装入内核的所有模块名称列表,可以由 lsmod 命令使用。其中第一列表示模块名,第二列表示此模块占用内存空间大小,第三列表示此模块有多少实例被装入,第四列表示此模块依赖于其它哪些模块,第五列表示此模块的装载状态:Live(已经装入)、Loading(正在装入)和 Unloading(正在卸载),第六列表示此模块在内核内存(kernel memory)中的偏移量:
$ cat /proc/modules
fuse 118784 3 - Live 0xffffffffc0d9b000
ccm 20480 3 - Live 0xffffffffc0d95000
rfcomm 86016 4 - Live 0xffffffffc0d7f000
bnep 24576 2 - Live 0xffffffffc0d78000
...
/proc/slabinfo
保存着监视系统中所有活动的 slab 缓存的信息:
$ sudo cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
fuse_request 0 20 400 20 2 : tunables 0 0 0 : slabdata 1 1 0
fuse_inode 1 39 832 39 8 : tunables 0 0 0 : slabdata 1 1 0
drm_i915_gem_request 765 1036 576 28 4 : tunables 0 0 0 : slabdata 37 37 0
...
/proc/[pid]
在 /proc 文件系统下,还有一些以数字命名的目录,这些数字是进程的 PID 号,而这些目录是进程目录。目录下的所有文件如下,然后会介绍几个比较重要的:
$ cat - &
[1] 1060
$ ls /proc/1060/
attr comm fd maps ns personality smaps syscall
autogroup coredump_filter fdinfo mem numa_maps projid_map smaps_rollup task
auxv cpuset gid_map mountinfo oom_adj root stack timers
cgroup cwd io mounts oom_score sched stat timerslack_ns
clear_refs environ limits mountstats oom_score_adj schedstat statm uid_map
cmdline exe map_files net pagemap setgroups status wchan
/proc/[pid]/cmdline
启动当前进程的完整命令:
$ cat /proc/1060/cmdline
cat-
/proc/[pid]/exe
指向启动当前进程的可执行文件的符号链接:
$ file /proc/1060/exe
/proc/1060/exe: symbolic link to /usr/bin/cat
/proc/[pid]/root
当前进程运行根目录的符号链接:
$ file /proc/1060/root
/proc/1060/root: symbolic link to /
/proc/[pid]/mem
当前进程所占用的内存空间,由open、read和lseek等系统调用使用,不能被用户读取。但可通过下面的 /proc/[pid]/maps 查看。
/proc/[pid]/maps
这个文件大概是最常用的,用于显示进程的内存区域映射信息:
$ cat /proc/1060/maps
56271b3a5000-56271b3ad000 r-xp 00000000 08:01 24904069 /usr/bin/cat
56271b5ac000-56271b5ad000 r--p 00007000 08:01 24904069 /usr/bin/cat
56271b5ad000-56271b5ae000 rw-p 00008000 08:01 24904069 /usr/bin/cat
56271b864000-56271b885000 rw-p 00000000 00:00 0 [heap]
7fefb66cd000-7fefb6a1e000 r--p 00000000 08:01 24912207 /usr/lib/locale/locale-archive
7fefb6a1e000-7fefb6bd1000 r-xp 00000000 08:01 24905238 /usr/lib/libc-2.27.so
7fefb6bd1000-7fefb6dd0000 ---p 001b3000 08:01 24905238 /usr/lib/libc-2.27.so
7fefb6dd0000-7fefb6dd4000 r--p 001b2000 08:01 24905238 /usr/lib/libc-2.27.so
7fefb6dd4000-7fefb6dd6000 rw-p 001b6000 08:01 24905238 /usr/lib/libc-2.27.so
7fefb6dd6000-7fefb6dda000 rw-p 00000000 00:00 0
7fefb6dda000-7fefb6dff000 r-xp 00000000 08:01 24905239 /usr/lib/ld-2.27.so
7fefb6fbd000-7fefb6fbf000 rw-p 00000000 00:00 0
7fefb6fdc000-7fefb6ffe000 rw-p 00000000 00:00 0
7fefb6ffe000-7fefb6fff000 r--p 00024000 08:01 24905239 /usr/lib/ld-2.27.so
7fefb6fff000-7fefb7000000 rw-p 00025000 08:01 24905239 /usr/lib/ld-2.27.so
7fefb7000000-7fefb7001000 rw-p 00000000 00:00 0
7ffde5659000-7ffde567a000 rw-p 00000000 00:00 0 [stack]
7ffde5748000-7ffde574b000 r--p 00000000 00:00 0 [vvar]
7ffde574b000-7ffde574d000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
/proc/[pid]/stack
这个文件表示当前进程的内核调用栈信息,只有在内核编译启用 CONFIG_STACKTRACE 选项,才会生成该文件:
$ sudo cat /proc/1060/stack
[<ffffffff8e08fa2e>] do_signal_stop+0xae/0x1f0
[<ffffffff8e090ec1>] get_signal+0x191/0x580
[<ffffffff8e02ae56>] do_signal+0x36/0x610
[<ffffffff8e003669>] exit_to_usermode_loop+0x69/0xa0
[<ffffffff8e0039d1>] do_syscall_64+0xf1/0x100
[<ffffffff8e800081>] entry_SYSCALL_64_after_hwframe+0x3d/0xa2
[<ffffffffffffffff>] 0xffffffffffffffff
/proc/[pid]/auxv
该文件包含了传递给进程的解释器信息,即 auxv(AUXiliary Vector),每一项都是由一个 unsigned long 长度的 ID 加上一个 unsigned long 长度的值构成:
$ xxd -e -g8 /proc/1060/auxv
00000000: 0000000000000021 00007ffde574b000 !.........t.....
00000010: 0000000000000010 00000000bfebfbff ................
00000020: 0000000000000006 0000000000001000 ................
00000030: 0000000000000011 0000000000000064 ........d.......
00000040: 0000000000000003 000056271b3a5040 ........@P:.'V..
00000050: 0000000000000004 0000000000000038 ........8.......
00000060: 0000000000000005 0000000000000009 ................
00000070: 0000000000000007 00007fefb6dda000 ................
00000080: 0000000000000008 0000000000000000 ................
00000090: 0000000000000009 000056271b3a7260 ........`r:.'V..
000000a0: 000000000000000b 00000000000003e8 ................
000000b0: 000000000000000c 00000000000003e8 ................
000000c0: 000000000000000d 00000000000003e8 ................
000000d0: 000000000000000e 00000000000003e8 ................
000000e0: 0000000000000017 0000000000000000 ................
000000f0: 0000000000000019 00007ffde5678349 ........I.g.....
00000100: 000000000000001a 0000000000000000 ................
00000110: 000000000000001f 00007ffde5679fef ..........g.....
00000120: 000000000000000f 00007ffde5678359 ........Y.g.....
00000130: 0000000000000000 0000000000000000 ................
每个值具体是做什么的,可以用下面的办法显示出来,对比看一看,更详细的可以查看 /usr/include/elf.h 和 man ld.so:
$ LD_SHOW_AUXV=1 cat -
AT_SYSINFO_EHDR: 0x7ffd16be5000
AT_HWCAP: bfebfbff
AT_PAGESZ: 4096
AT_CLKTCK: 100
AT_PHDR: 0x55eb4c59a040
AT_PHENT: 56
AT_PHNUM: 9
AT_BASE: 0x7f61506e8000
AT_FLAGS: 0x0
AT_ENTRY: 0x55eb4c59c260
AT_UID: 1000
AT_EUID: 1000
AT_GID: 1000
AT_EGID: 1000
AT_SECURE: 0
AT_RANDOM: 0x7ffd16bd0ce9
AT_HWCAP2: 0x0
AT_EXECFN: /bin/cat
AT_PLATFORM: x86_64
值得一提的是,AT_SYSINFO_EHDR 所对应的值是一个叫做的 VDSO(Virtual Dynamic Shared Object) 的地址。在 ret2vdso 漏洞利用方法中会用到(参考章节6.1.6)。
/proc/[pid]/environ
该文件包含了进程的环境变量:
$ strings /proc/1060/environ
GS_LIB=/home/firmy/.fonts
KDE_FULL_SESSION=true
VIRTUALENVWRAPPER_WORKON_CD=1
VIRTUALENVWRAPPER_HOOK_DIR=/home/firmy/.virtualenvs
LANG=zh_CN.UTF-8
...
/proc/[pid]/fd
该文件包含了进程打开文件的情况:
$ ls -al /proc/1060/fd
total 0
dr-x------ 2 firmy firmy 0 6月 7 23:37 .
dr-xr-xr-x 9 firmy firmy 0 6月 7 23:37 ..
lrwx------ 1 firmy firmy 64 6月 7 23:44 0 -> /dev/pts/3
lrwx------ 1 firmy firmy 64 6月 7 23:44 1 -> /dev/pts/3
lrwx------ 1 firmy firmy 64 6月 7 23:44 2 -> /dev/pts/3
/proc/[pid]/status
该文件包含了进程的状态信息:
$ cat /proc/1060/status
Name: cat
Umask: 0022
State: T (stopped)
Tgid: 1060
Ngid: 0
Pid: 1060
PPid: 1035
TracerPid: 0
Uid: 1000 1000 1000 1000
Gid: 1000 1000 1000 1000
FDSize: 256
Groups: 3 7 10 56 90 91 93 95 96 98 1000
...
/proc/[pid]/task
一个目录,包含当前进程的每一个线程的相关信息,每个线程的信息分别放在一个由线程号(tid)命名的目录中:
$ ls /proc/1060/task/
1060
$ ls /proc/1060/task/1060/
attr clear_refs cwd fdinfo maps net oom_score projid_map setgroups stat uid_map
auxv cmdline environ gid_map mem ns oom_score_adj root smaps statm wchan
cgroup comm exe io mountinfo numa_maps pagemap sched smaps_rollup status
children cpuset fd limits mounts oom_adj personality schedstat stack syscall
/proc/[pid]/syscall
该文件包含了进程正在执行的系统调用:
$ sudo cat /proc/1060/syscall
0 0x0 0x7fefb6fdd000 0x20000 0x22 0xffffffff 0x0 0x7ffde5677d48 0x7fefb6b07901
第一个值是系统调用号,后面跟着是六个参数,最后两个值分别是堆栈指针和指令计数器的值。
参考资料
1.5.1 C 语言基础
从源代码到可执行文件
我们以经典著作《The C Programming Language》中的第一个程序 “Hello World” 为例,讲解 Linux 下 GCC 的编译过程。
#include <stdio.h>
main()
{
printf("hello, world\n");
}
$gcc hello.c
$./a.out
hello world
以上过程可分为4个步骤:预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)和链接(Linking)。

预编译
gcc -E hello.c -o hello.i
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<command-line>"
......
extern int printf (const char *__restrict __format, ...);
......
main() {
printf("hello, world\n");
}
预编译过程主要处理源代码中以 “#” 开始的预编译指令:
- 将所有的 “#define” 删除,并且展开所有的宏定义。
- 处理所有条件预编译指令,如 “#if”、“#ifdef”、“#elif”、“#else”、“#endif”。
- 处理 “#include” 预编译指令,将被包含的文件插入到该预编译指令的位置。注意,该过程递归执行。
- 删除所有注释。
- 添加行号和文件名标号。
- 保留所有的 #pragma 编译器指令。
编译
gcc -S hello.c -o hello.s
.file "hello.c"
.section .rodata
.LC0:
.string "hello, world"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
leaq .LC0(%rip), %rdi
call puts@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 7.2.0"
.section .note.GNU-stack,"",@progbits
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件。
汇编
$ gcc -c hello.s -o hello.o
或者
$gcc -c hello.c -o hello.o
$ objdump -sd hello.o
hello.o: file format elf64-x86-64
Contents of section .text:
0000 554889e5 488d3d00 000000e8 00000000 UH..H.=.........
0010 b8000000 005dc3 .....].
Contents of section .rodata:
0000 68656c6c 6f2c2077 6f726c64 00 hello, world.
Contents of section .comment:
0000 00474343 3a202847 4e552920 372e322e .GCC: (GNU) 7.2.
0010 3000 0.
Contents of section .eh_frame:
0000 14000000 00000000 017a5200 01781001 .........zR..x..
0010 1b0c0708 90010000 1c000000 1c000000 ................
0020 00000000 17000000 00410e10 8602430d .........A....C.
0030 06520c07 08000000 .R......
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # b <main+0xb>
b: e8 00 00 00 00 callq 10 <main+0x10>
10: b8 00 00 00 00 mov $0x0,%eax
15: 5d pop %rbp
16: c3 retq
汇编器将汇编代码转变成机器可以执行的指令。
链接
gcc hello.o -o hello
$ objdump -d -j .text hello
......
000000000000064a <main>:
64a: 55 push %rbp
64b: 48 89 e5 mov %rsp,%rbp
64e: 48 8d 3d 9f 00 00 00 lea 0x9f(%rip),%rdi # 6f4 <_IO_stdin_used+0x4>
655: e8 d6 fe ff ff callq 530 <puts@plt>
65a: b8 00 00 00 00 mov $0x0,%eax
65f: 5d pop %rbp
660: c3 retq
661: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
668: 00 00 00
66b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
......
目标文件需要链接一大堆文件才能得到最终的可执行文件(上面只展示了链接后的 main 函数,可以和 hello.o 中的 main 函数作对比)。链接过程主要包括地址和空间分配(Address and Storage Allocation)、符号决议(Symbol Resolution)和重定向(Relocation)等。
gcc 技巧
通常在编译后只会生成一个可执行文件,而中间过程生成的 .i、.s、.o 文件都不会被保存。我们可以使用参数 -save-temps 永久保存这些临时的中间文件。
$ gcc -save-temps hello.c
$ ls
a.out hello.c hello.i hello.o hello.s
这里要注意的是,gcc 默认使用动态链接,所以这里生成的 a.out 实际上是共享目标文件。
$ file a.out
a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=533aa4ca46d513b1276d14657ec41298cafd98b1, not stripped
使用参数 --verbose 可以输出 gcc 详细的工作流程。
gcc hello.c -static --verbose
东西很多,我们主要关注下面几条信息:
$ /usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/cc1 -quiet -v hello.c -quiet -dumpbase hello.c -mtune=generic -march=x86-64 -auxbase hello -version -o /tmp/ccj1jUMo.s
as -v --64 -o /tmp/ccAmXrfa.o /tmp/ccj1jUMo.s
/usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/collect2 -plugin /usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/liblto_plugin.so -plugin-opt=/usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/lto-wrapper -plugin-opt=-fresolution=/tmp/cc1l5oJV.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_eh -plugin-opt=-pass-through=-lc --build-id --hash-style=gnu -m elf_x86_64 -static /usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/../../../../lib/crt1.o /usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/../../../../lib/crti.o /usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/crtbeginT.o -L/usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0 -L/usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/../../../../lib -L/lib/../lib -L/usr/lib/../lib -L/usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/../../.. /tmp/ccAmXrfa.o --start-group -lgcc -lgcc_eh -lc --end-group /usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/crtend.o /usr/lib/gcc/x86_64-pc-linux-gnu/7.2.0/../../../../lib/crtn.o
三条指令分别是 cc1、as 和 collect2,cc1 是 gcc 的编译器,将 .c 文件编译为 .s 文件,as 是汇编器命令,将 .s 文件汇编成 .o 文件,collect2 是链接器命令,它是对命令 ld 的封装。静态链接时,gcc 将 C 语言运行时库的 5 个重要目标文件 crt1.o、crti.o、crtbeginT.o、crtend.o、crtn.o 和 -lgcc、-lgcc_eh、-lc 表示的 3 个静态库链接到可执行文件中。
更多的内容我们会在 1.5.3 中专门对 ELF 文件进行讲解。
C 语言标准库
C 运行库(CRT)是一套庞大的代码库,以支撑程序能够正常地运行。其中 C 语言标准库占据了最主要地位。
常用的标准库文件头:
- 标准输入输出(stdio.h)
- 字符操作(ctype.h)
- 字符串操作(string.h)
- 数学函数(math.h)
- 实用程序库(stdlib.h)
- 时间/日期(time.h)
- 断言(assert.h)
- 各种类型上的常数(limits.h & float.h)
- 变长参数(stdarg.h)
- 非局部跳转(setjmp.h)
glibc 即 GNU C Library,是为 GNU 操作系统开发的一个 C 标准库。glibc 主要由两部分组成,一部分是头文件,位于 /usr/include;另一部分是库的二进制文件。二进制文件部分主要是 C 语言标准库,有动态和静态两个版本,动态版本位于 /lib/libc.so.6,静态版本位于 /usr/lib/libc.a。
在漏洞利用的过程中,通常我们通过计算目标函数地址相对于已知函数地址在同一个 libc 中的偏移,来获得目标函数的虚拟地址,这时我们需要让本地的 libc 版本和远程的 libc 版本相同,可以先泄露几个函数的地址,然后在 libcdb.com 中进行搜索来得到。
整数表示
默认情况下,C 语言中的数字是有符号数,下面我们声明一个有符号整数和无符号整数:
int var1 = 0;unsigned int var2 = 0;
- 有符号整数
- 可以表示为正数或负数
-
int 的范围:-2,147,483,648 ~ 2,147,483,647
- 无符号整数
- 只能表示为零或正数
-
unsigned int 的范围:0 ~ 4,294,967,295
signed 或者 unsigned 取决于整数类型是否可以携带标志 +/-:
- Signed
- Unsigned
- unit
- unsigned int
- unsigned long
在 signed int 中,二进制最高位被称作符号位,符号位被设置为 1 时,表示值为负,当设置为 0 时,值为非负:
- 0x7FFFFFFF = 2147493647
- 01111111111111111111111111111111
- 0x80000000 = -2147483647
- 10000000000000000000000000000000
- 0xFFFFFFFF = -1
- 11111111111111111111111111111111
二进制补码以一种适合于二进制加法器的方式来表示负数,当一个二进制补码形式表示的负数和与它的绝对值相等的正数相加时,结果为 0。首先以二进制方式写出正数,然后对所有位取反,最后加 1 就可以得到该数的二进制补码:
eg: 0x00123456
= 1193046
= 00000000000100100011010001010110
~= 11111111111011011100101110101001
+= 11111111111011011100101110101010
= -1193046 (0xFFEDCBAA)
编译器需要根据变量类型信息编译成相应的指令:
- 有符号指令
- IDIV:带符号除法指令
- IMUL:带符号乘法指令
- SAL:算术左移指令(保留符号)
- SAR:右移右移指令(保留符号)
- MOVSX:带符号扩展传送指令
- JL:当小于时跳转指令
- JLE:当小于或等于时跳转指令
- JG:当大于时跳转指令
- JGE:当大于或等于时跳转指令
- 无符号指令
- DIV:除法指令
- MUL:乘法指令
- SHL:逻辑左移指令
- SHR:逻辑右移指令
- MOVZX:无符号扩展传送指令
- JB:当小于时跳转指令
- JBE:当小于或等于时跳转指令
- JA:当大于时跳转指令
- JAE:当大于或等于时跳转指令
32 位机器上的整型数据类型,不同的系统可能会有不同:
| C 数据类型 |
最小值 |
最大值 |
最小大小 |
| char |
-128 |
127 |
8 bits |
| short |
-32 768 |
32 767 |
16 bits |
| int |
-2 147 483 648 |
2 147 483 647 |
16 bits |
| long |
-2 147 483 648 |
2 147 483 647 |
32 bits |
| long long |
-9 223 372 036 854 775 808 |
9 223 372 036 854 775 807 |
64 bits |
固定大小的数据类型:
-
int [# of bits]_t
-
uint[# of bits]_t
- uint8_t, uint16_t, uint32_t
-
有符号整数
-
无符号整数
更多信息在 stdint.h 和 limits.h 中:
man stdint.h
cat /usr/include/stdint.h
man limits.h
cat /usr/include/limits.h
了解整数的符号和大小是很有用的,在后面的相关章节中我们会介绍整数溢出的内容。
格式化输出函数
C 标准中定义了下面的格式化输出函数(参考 man 3 printf):
#include <stdio.h>
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int dprintf(int fd, const char *format, ...);
int sprintf(char *str, const char *format, ...);
int snprintf(char *str, size_t size, const char *format, ...);
#include <stdarg.h>
int vprintf(const char *format, va_list ap);
int vfprintf(FILE *stream, const char *format, va_list ap);
int vdprintf(int fd, const char *format, va_list ap);
int vsprintf(char *str, const char *format, va_list ap);
int vsnprintf(char *str, size_t size, const char *format, va_list ap);
-
fprintf() 按照格式字符串的内容将输出写入流中。三个参数为流、格式字符串和变参列表。
-
printf() 等同于 fprintf(),但是它假定输出流为 stdout。
-
sprintf() 等同于 fprintf(),但是输出不是写入流而是写入数组。在写入的字符串末尾必须添加一个空字符。
-
snprintf() 等同于 sprintf(),但是它指定了可写入字符的最大值 size。当 size 大于零时,输出字符超过第 size-1 的部分会被舍弃而不会写入数组中,在写入数组的字符串末尾会添加一个空字符。
-
dprintf() 等同于 fprintf(),但是它输出不是流而是一个文件描述符 fd。
-
vfprintf()、vprintf()、vsprintf()、vsnprintf()、vdprintf() 分别与上面的函数对应,只是它们将变参列表换成了 va_list 类型的参数。
格式字符串
格式字符串是由普通字符(ordinary character)(包括 %)和转换规则(conversion specification)构成的字符序列。普通字符被原封不动地复制到输出流中。转换规则根据与实参对应的转换指示符对其进行转换,然后将结果写入输出流中。
一个转换规则有可选部分和必需部分组成:
%[ 参数 ][ 标志 ][ 宽度 ][ .精度 ][ 长度 ] 转换指示符
| 字符 |
描述 |
d, i
|
有符号十进制数值 int。’%d‘ 与 ‘%i‘ 对于输出是同义;但对于 scanf() 输入二者不同,其中 %i 在输入值有前缀 0x 或 0 时,分别表示 16 进制或 8 进制的值。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空 |
u |
十进制 unsigned int。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空 |
f, F
|
double 型输出 10 进制定点表示。’f‘ 与 ‘F‘ 差异是表示无穷与 NaN 时,’f‘ 输出 ‘inf‘, ‘infinity‘ 与 ‘nan‘;’F‘ 输出 ‘INF‘, ‘INFINITY‘ 与 ‘NAN‘。小数点后的数字位数等于精度,最后一位数字四舍五入。精度默认为 6。如果精度为 0 且没有 # 标记,则不出现小数点。小数点左侧至少一位数字 |
e, E
|
double 值,输出形式为 10 进制的([-]d.ddd e[+/-]ddd). E 版本使用的指数符号为 E(而不是e)。指数部分至少包含 2 位数字,如果值为 0,则指数部分为 00。Windows 系统,指数部分至少为 3 位数字,例如 1.5e002,也可用 Microsoft 版的运行时函数 _set_output_format 修改。小数点前存在 1 位数字。小数点后的数字位数等于精度。精度默认为 6。如果精度为 0 且没有 # 标记,则不出现小数点 |
g, G
|
double 型数值,精度定义为全部有效数字位数。当指数部分在闭区间 [-4,精度] 内,输出为定点形式;否则输出为指数浮点形式。’g‘ 使用小写字母,’G‘ 使用大写字母。小数点右侧的尾数 0 不被显示;显示小数点仅当输出的小数部分不为 0 |
x, X
|
16 进制 unsigned int。’x‘ 使用小写字母;’X‘ 使用大写字母。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空 |
o |
8 进制 unsigned int。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空 |
s |
如果没有用 l 标志,输出 null 结尾字符串直到精度规定的上限;如果没有指定精度,则输出所有字节。如果用了 l 标志,则对应函数参数指向 wchar_t 型的数组,输出时把每个宽字符转化为多字节字符,相当于调用 wcrtomb 函数 |
c |
如果没有用 l 标志,把 int 参数转为 unsigned char 型输出;如果用了 l 标志,把 wint_t 参数转为包含两个元素的 wchart_t 数组,其中第一个元素包含要输出的字符,第二个元素为 null 宽字符 |
p |
void * 型,输出对应变量的值。printf("%p", a) 用地址的格式打印变量 a 的值,printf("%p", &a) 打印变量 a 所在的地址 |
a, A
|
double 型的 16 进制表示,”[−]0xh.hhhh p±d”。其中指数部分为 10 进制表示的形式。例如:1025.010 输出为 0x1.004000p+10。’a‘ 使用小写字母,’A‘ 使用大写字母 |
n |
不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量 |
% |
‘%‘ 字面值,不接受任何除了 参数 以外的部分 |
| 字符 |
描述 |
n$ |
n 是用这个格式说明符显示第几个参数;这使得参数可以输出多次,使用多个格式说明符,以不同的顺序输出。如果任意一个占位符使用了 参数,则其他所有占位符必须也使用 参数。例:printf("%2$d %2$#x; %1$d %1$#x",16,17) 产生 “17 0x11; 16 0x10“ |
| 字符 |
描述 |
+ |
总是表示有符号数值的 ‘+‘ 或 ‘-‘ 号,缺省情况是忽略正数的符号。仅适用于数值类型 |
| 空格 |
使得有符号数的输出如果没有正负号或者输出 0 个字符,则前缀 1 个空格。如果空格与 ‘+‘ 同时出现,则空格说明符被忽略 |
- |
左对齐。缺省情况是右对齐 |
# |
对于 ‘g‘ 与 ‘G‘,不删除尾部 0 以表示精度。对于 ‘f‘, ‘F‘, ‘e‘, ‘E‘, ‘g‘, ‘G‘, 总是输出小数点。对于 ‘o‘, ‘x‘, ‘X‘, 在非 0 数值前分别输出前缀 0, 0x 和 0X表示数制 |
0 |
如果 宽度 选项前缀为 0,则在左侧用 0 填充直至达到宽度要求。例如 printf("%2d", 3) 输出 “3“,而 printf("%02d", 3) 输出 “03“。如果 0 与 - 均出现,则 0 被忽略,即左对齐依然用空格填充 |
是一个用来指定输出字符的最小个数的十进制非负整数。如果实际位数多于定义的宽度,则按实际位数输出;如果实际位数少于定义的宽度则补以空格或 0。
精度是用来指示打印字符个数、小数位数或者有效数字个数的非负十进制整数。对于 d、i、u、x、o 的整型数值,是指最小数字位数,不足的位要在左侧补 0,如果超过也不截断,缺省值为 1。对于 a, A, e, E, f, F 的浮点数值,是指小数点右边显示的数字位数,必要时四舍五入;缺省值为 6。对于 g, G 的浮点数值,是指有效数字的最大位数。对于 s 的字符串类型,是指输出的字节的上限,超出限制的其它字符将被截断。如果域宽为 *,则由对应的函数参数的值为当前域宽。如果仅给出了小数点,则域宽为 0。
| 字符 |
描述 |
hh |
对于整数类型,printf 期待一个从 char 提升的 int 整型参数 |
h |
对于整数类型,printf 期待一个从 short 提升的 int 整型参数 |
l |
对于整数类型,printf 期待一个 long 整型参数。对于浮点类型,printf 期待一个 double 整型参数。对于字符串 s 类型,printf 期待一个 wchar_t 指针参数。对于字符 c 类型,printf 期待一个 wint_t 型的参数 |
ll |
对于整数类型,printf 期待一个 long long 整型参数。Microsoft 也可以使用 I64
|
L |
对于浮点类型,printf 期待一个 long double 整型参数 |
z |
对于整数类型,printf 期待一个 size_t 整型参数 |
j |
对于整数类型,printf 期待一个 intmax_t 整型参数 |
t |
对于整数类型,printf 期待一个 ptrdiff_t 整型参数 |
例子
printf("Hello %%"); // "Hello %"
printf("Hello World!"); // "Hello World!"
printf("Number: %d", 123); // "Number: 123"
printf("%s %s", "Format", "Strings"); // "Format Strings"
printf("%12c", 'A'); // " A"
printf("%16s", "Hello"); // " Hello!"
int n;
printf("%12c%n", 'A', &n); // n = 12
printf("%16s%n", "Hello!", &n); // n = 16
printf("%2$s %1$s", "Format", "Strings"); // "Strings Format"
printf("%42c%1$n", &n); // 首先输出41个空格,然后输出 n 的低八位地址作为一个字符
这里我们对格式化输出函数和格式字符串有了一个详细的认识,后面的章节中我们会介绍格式化字符串漏洞的内容。
- 汇编语言
- 3.3 X86 汇编基础
- [3.3.2 寄存器 Registers](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.2 寄存器 Registers)
- 3.3.3 内存和寻址模式 Memory and Addressing Modes
- [3.3.3.1 声明静态数据区域](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.3.1 声明静态数据区域)
- [3.3.3.2 内存寻址](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.3.2 内存寻址)
- [3.3.3.3 操作后缀](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.3.3 操作后缀)
- 3.3.4 指令 Instructions
- [3.3.4.1 数据移动指令](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.4.1 数据移动指令)
- [3.3.4.2 逻辑运算指令](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.4.2 逻辑运算指令)
- [3.3.4.3 流程控制指令](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.4.3 流程控制指令)
- 3.3.5 调用约定 Calling Convention
- [3.3.5.1 调用者约定 Caller Rules](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.5.1 调用者约定 Caller Rules)
- [3.3.5.2 被调用者约定 Callee Rules](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.3.5.2 被调用者约定 Callee Rules)
- 3.4 x64 汇编基础
- [3.4.1 导语](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.4.1 导语)
- [3.4.2 寄存器 Registers](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.4.2 寄存器 Registers)
- [3.4.3 寻址模式 Addressing modes](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.4.3 寻址模式 Addressing modes)
- 3.4.4 通用指令 Common instructions
- [3.4.5 汇编和 gdb](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.4.5 汇编和 gdb)
- 3.5 ARM汇编基础
- [3.5.1 引言](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.5.1 引言)
- [3.5.2 ARM 的 GNU 汇编程序指令表](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.5.2 ARM 的 GNU 汇编程序指令表)
- [3.5.3 寄存器名称](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.5.3 寄存器名称)
- [3.5.4 汇编程序特殊字符/语法](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.5.4 汇编程序特殊字符/语法)
- [3.5.5 arm程序调用标准](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.5.5 arm程序调用标准)
- [3.5.6 寻址模式](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.5.6 寻址模式)
- [3.5.7 机器相关指令](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#3.5.7 机器相关指令)
- 3.6 MIPS汇编基础
- 数据类型和常量
- 寄存器
- 程序结构
- 数据声明
- 代码
- 注释
- 变量声明
- [读取/写入 ( Load/Store )指令](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#读取/写入 ( Load/Store )指令)
- 间接和立即寻址
- 算术指令
- 流程控制
- [系统调用和 I / O( 针对 SPIM 模拟器 )](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#系统调用和 I / O( 针对 SPIM 模拟器 ))
- [补充 : MIPS 指令格式](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#补充 : MIPS 指令格式)
- [补充 : MIPS 常用指令集](https://www.bookstack.cn/read/CTF-All-In-One/doc-1.5.2_assembly.md#补充 : MIPS 常用指令集)
- 参考资料
汇编语言
3.3 X86 汇编基础
3.3.2 寄存器 Registers
现代 ( 386及以上的机器 )x86 处理器有 8 个 32 位通用寄存器, 如图 1 所示.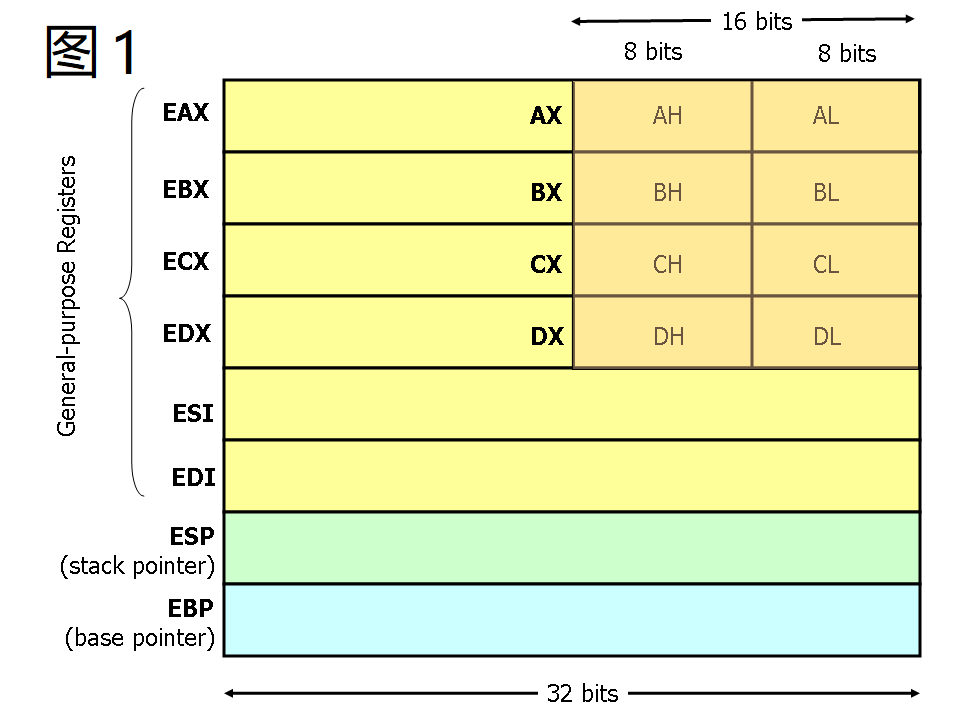
这些寄存器的名字都是有点历史的, 例如 EAX 过去被称为 累加器, 因为它被用来作很多算术运算, 还有 ECX 被称为 计数器 , 因为它被用来保存循环的索引 ( 就是循环次数 ). 尽管大多是寄存器在现代指令集中已经失去了它们的特殊用途, 但是按照惯例, 其中有两个寄存器还是有它们的特殊用途 —-ESP 和 EBP.
对于 EAS, EBX, ECX 还有 EDX 寄存器, 它们可以被分段开来使用. 例如, 可以将 EAX 的最低的 2 位字节视为 16 位寄存器 ( AX ). 还可以将 AX 的最低位的 1 个字节看成 8 位寄存器来用 ( AL ), 当然 AX 的高位的 1 个字节也可以看成是一个 8 位寄存器 ( AH ). 这些名称有它们相对应的物理寄存器. 当两个字节大小的数据被放到 DX 的时候, 原本 DH, DL 和 EDX 的数据会受到影响 ( 被覆盖之类的 ). 这些 “ 子寄存器 “ 主要来自于比较久远的 16 位版本指令集. 然而, 姜还是老的辣, 在处理小于 32 位的数据的时候, 比如 1 个字节的 ASCII 字符, 它们有时会很方便.
3.3.3 内存和寻址模式 Memory and Addressing Modes
3.3.3.1 声明静态数据区域
你可以用特殊的 x86 汇编指令在内存中声明静态数据区域 ( 类似于全局变量 ). .data指令用来声明数据. 根据这条指令, .byte, .short 和 .long 可以分别用来声明 1 个字节, 2 个字节和 4 个字节的数据. 我们可以给它们打个标签, 用来引用创建的数据的地址. 标签在汇编语言中是非常有用的, 它们给内存地址命名, 然后编译器 和链接器 将其 “ 翻译 “ 成计算机理解的机器代码. 这个跟用名称来声明变量很类似, 但是它遵守一些较低级别的规则. 例如, 按顺序声明的位置将彼此相邻地存储在内存中. 这话也许有点绕, 就是按照顺序打的标签, 这些标签对应的数据也会按照顺序被放到内存中.
一些例子 :
.data
var :
.byte 64 ;声明一个字节型变量 var, 其所对应的数据是64
.byte 10 ;声明一个数据 10, 这个数据没有所谓的 " 标签 ", 它的内存地址就是 var+1.
x :
.short 42 ;声明一个大小为 2 个字节的数据, 这个数据有个标签 " x "
y :
.long 30000 ;声明一个大小为 4 个字节的数据, 这个数据标签是 " y ", y 的值被初始化为 30000
与高级语言不同, 高级语言的数组可以具有多个维度并且可以通过索引来访问, x86 汇编语言的数组只是在内存中连续的” 单元格 “. 你只需要把数值列出来就可以声明一个数组, 比如下面的第一个例子. 对于一些字节型数组的特殊情况, 我们可以使用字符串. 如果要在大多数的内存填充 0, 你可以使用.zero指令.
例子 :
s :
.long 1, 2, 3 ;声明 3 个大小为 4 字节的数据 1, 2, 3. 内存中 s+8 这个标签所对应的数据就是 3.
barr:
.zero 10 ;从 barr 这个标签的位置开始, 声明 10 个字节的数据, 这些数据被初始化为 0.
str :
.string "hello" ;从 str 这个标签的位置开始, 声明 6 个字节的数据, 即 hello 对应的 ASCII 值, 这最后还跟有一个 nul(0) 字节.


3.3.3.2 内存寻址
现代x86兼容处理器能够寻址高达 2^32 字节的内存 : 内存地址为 32 位宽. 在上面的示例中,我们使用标签来引用内存区域,这些标签实际上被 32 位数据的汇编程序替换,这些数据指定了内存中的地址. 除了支持通过标签(即常数值)引用存储区域之外,x86提供了一种灵活的计算和引用内存地址的方案 :最多可将两个32位寄存器和一个32位有符号常量相加,以计算存储器地址. 其中一个寄存器可以选择预先乘以 2, 4 或 8.
寻址模式可以和许多 x86 指令一起使用 ( 我们将在下一节对它们进行讲解 ). 这里我们用mov指令在寄存器和内存中移动数据当作例子. 这个指令有两个参数, 第一个是数据的来源, 第二个是数据的去向.
一些mov的例子 :
mov (%ebx), %eax ;从 EBX 中的内存地址加载 4 个字节的数据到 EAX, 就是把 EBX 中的内容当作标签, 这个标签在内存中对应的数据放到 EAX 中
;后面如果没有说明的话, (%ebx)就表示寄存器ebx中存储的内容
mov %ebx, var(,1) ; 将 EBX 中的 4 个字节大小的数据移动的内存中标签为 var 的地方去.( var 是一个 32 位常数).
mov (%esi, %ebx, 4), %edx ;将内存中标签为 ESI+4*EBX 所对应的 4 个字节大小的数据移动到 EDX中.
一些错误的例子:
mov (%ebx, %ecx, -1), %eax ;这个只能把寄存器中的值加上一遍.
mov %ebx,(%eax, %esi, %edi, 1) ;在地址计算中, 最多只能出现 2 个寄存器, 这里却有 3 个寄存器.
3.3.3.3 操作后缀
通常, 给定内存地址的数据类型可以从引用它的汇编指令推断出来. 例如, 在上面的指令中, 你可以从寄存器操作数的大小来推出其所占的内存大小. 当我们加载一个 32 位的寄存器的时候, 编译器就可以推断出我们用到的内存大小是 4 个字节宽. 当我们将 1 个字节宽的寄存器的值保存到内存中时, 编译器可以推断出我们想要在内存中弄个 1 字节大小的 “ 坑 “ 来保存我们的数据.
然而在某些情况下, 我们用到的内存中 “ 坑 “ 的大小是不明确的. 比如说这条指令 mov $2,(%ebx). 这条指令是否应该将 “ 2 “ 这个值移动到 EBX 中的值所代表的地址 “ 坑 “ 的单个字节中 ? 也许它表示的是将 32 位整数表示的 2 移动到从地址 EBX 开始的 4 字节. 既然这两个解释都有道理, 但计算机汇编程序必须明确哪个解释才是正确的, 计算机很单纯的, 要么是错的要么是对的. 前缀 b, w, 和 l 就是来解决这个问题的, 它们分别表示 1, 2 和 4 个字节的大小.
举几个例子 :
movb $2, (%ebx) ;将 2 移入到 ebx 中的值所表示的地址单元中.
movw $2, (%ebx) ;将 16 位整数 2 移动到 从 ebx 中的值所表示的地址单元 开始的 2 个字节中;这话有点绕, 所以我故意在里面加了点空格, 方便大家理解.
movl $2,(%ebx) ;将 32 位整数 2 移动到 从 ebx中的值表示的地址单元 开始的 4 个字节中.
3.3.4 指令 Instructions
机器指令通常分为 3 类 : 数据移动指令, 逻辑运算指令和流程控制指令. 在本节中, 我们将讲解每一种类型的 x86 指令以及它们的重要示例. 当然, 我们不可能把 x86 所有指令讲得特别详细, 毕竟篇幅和水平有限. 完整的指令列表, 请参阅 intel 的指令集参考手册.
我们将使用以下符号 :
<reg32 任意的 32 位寄存器 (%eax, %ebx, %ecx, %edx, %esi, %edi, %esp 或者 %eb)
<reg16 任意的 16 位寄存器 (%ax, %bx, %cx 或者 %dx)
<reg8 任意的 8 位寄存器 (%ah, %al, %bh, %bl, %ch, %cl, %dh, %dl)
<reg 任意的寄存器
<mem 一个内存地址, 例如 (%eax), 4+var, (%eax, %ebx, 1)
<con32 32 位常数
<con16 16 位常数
<con8 8 位常数
<con 任意 32位, 16 位或者 8 位常数
在汇编语言中, 用作立即操作数 的所有标签和数字常量 ( 即不在诸如3 (%eax, %ebx, 8)这样的地址计算中 ) 总是以美元符号 $ 为前缀. 需要的时候, 前缀 0x 表示十六进制数, 例如$ 0xABC. 如果没有前缀, 则默认该数字为十进制数.
3.3.4.1 数据移动指令
mov 指令将数据从它的第一个参数 ( 即寄存器中的内容, 内存单元中的内容, 或者一个常数值 ) 复制到它的第二个参数 ( 即寄存器或者内存单元 ). 当寄存器到寄存器之间的数据移动是可行的时候, 直接地从内存单元中将数据移动到另一内存单元中是不行的. 在这种需要在内存单元中传递数据的情况下, 它数据来源的那个内存单元必须首先把那个内存单元中的数据加载到一个寄存器中, 然后才可以通过这个寄存器来把数据移动到目标内存单元中.
mov <reg, <reg
mov <reg, <mem
mov <mem, <reg
mov <con, <reg
mov <con, <mem
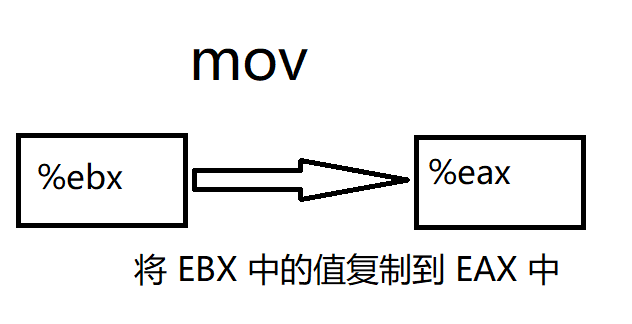
mov %ebx, %eax ;将 EBX 中的值复制到 EAX 中
mov $5, var(,1) ;将数字 5 存到字节型内存单元 " var "
push指令将它的参数移动到硬件支持的栈内存顶端. 特别地, push 首先将 ESP 中的值减少 4, 然后将它的参数移动到一个 32 位的地址单元 ( %esp ). ESP ( 栈指针 ) 会随着不断入栈从而持续递减, 即栈内存是从高地址单元到低地址单元增长.
push <reg32
push <mem
push <con32
push %eax ;将 EAX 送入栈
push var(,1) ;将 var 对应的 4 字节大小的数据送入栈中
pop指令从硬件支持的栈内存顶端移除 4 字节的数据, 并把这个数据放到该指令指定的参数中 ( 即寄存器或者内存单元 ). 其首先将内存中 ( %esp ) 的 4 字节数据放到指定的寄存器或者内存单元中, 然后让 ESP + 4.
pop <reg32
pop <mem
pop %edi ;将栈顶的元素移除, 并放入到寄存器 EDI 中.
pop (%ebx) ;将栈顶的元素移除, 并放入从 EBX 开始的 4 个字节大小的内存单元中.
重点内容 : 栈栈是一种特殊的存储空间, 特殊在它的访问形式上, 它的访问形式就是最后进入这个空间的数据, 最先出去, 也就是 “先进后出, 后进先出”.
lea指令将其第一个参数指定的内存单元 放入到 第二个参数指定的寄存器中. 注意, 该指令不加载内存单元中的内容, 只是计算有效地址并将其放入寄存器. 这对于获得指向存储器区域的指针或者执行简单的算术运算非常有用.
也许这里你会看得一头雾水, 不过你不必担心, 这里有更为通俗易懂的解释.汇编语言中 lea 指令和 mov 指令的区别 ?MOV 指令的功能是传送数据,例如 MOV AX,[1000H],作用是将 1000H 作为偏移地址,寻址找到内存单元,将该内存单元中的数据送至 AX;LEA 指令的功能是取偏移地址,例如 LEA AX,[1000H],作用是将源操作数 [1000H] 的偏移地址 1000H 送至 AX。理解时,可直接将[ ]去掉,等同于 MOV AX,1000H。再如:LEA BX,[AX],等同于 MOV BX,AX;LEA BX,TABLE 等同于 MOV BX,OFFSET TABLE。但有时不能直接使用 MOV 代替:比如:LEA AX,[SI+6] 不能直接替换成:MOV AX,SI+6;但可替换为:MOV AX,SI``ADD AX,6两步完成。
参考链接
lea <mem, <reg32
lea (%ebx,%esi,8), %edi ;EBX+8*ESI 的值被移入到了 EDI
lea val(,1), %eax ;val 的值被移入到了 EAX
3.3.4.2 逻辑运算指令
add 指令将两个参数相加, 然后将结果存放到第二个参数中. 注意, 参数可以是寄存器,但参数中最多只有一个内存单元. 这话有点绕, 我们直接看语法 :
add <reg, <reg
add <mem, <reg
add <reg, <mem
add <con, <reg
add <con, <mem
add $10, %eax ;EAX 中的值被设置为了 EAX+10.
addb $10, (%eax) ;往 EAX 中的值 所代表的内存单元地址 加上 1 个字节的数字 10.
sub指令将第二个参数的值与第一个相减, 就是后面那个减去前面那个, 然后把结果存储到第二个参数. 和add一样, 两个参数都可以是寄存器, 但两个参数中最多只能有一个是内存单元.
sub <reg, <reg
sub <mem, <reg
sub <con, <reg
sub <con, <mem
sub %ah, %al ;AL 被设置成 AL-AH
sub $216, %eax ;将 EAX 中的值减去 216
inc 指令让它的参数加 1, dec 指令则是让它的参数减去 1.
inc <reg
inc <mem
dec <reg
dec <mem
dec %eax ;EAX 中的值减去 1
incl var(,1) ;将 var 所代表的 32 位整数加上 1.
imul 指令有两种基本格式 : 第一种是 2 个参数的 ( 看下面语法开始两条 ); 第二种格式是 3 个参数的 ( 看下面语法最后两条 ).
2 个参数的这种格式, 先是将两个参数相乘, 然后把结果存到第二个参数中. 运算结果 ( 即第二个参数 ) 必须是一个寄存器.
3 个参数的这种格式, 先是将它的第 1 个参数和第 2 个参数相乘, 然后把结果存到第 3 个参数中, 当然, 第 3 个参数必须是一个寄存器. 此外, 第 1 个参数必须是一个常数.
imul <reg32, <reg32
imul <mem, <reg32
imul <con, <reg32, <reg32
imul <con, <mem, <reg32
imul (%ebx), %eax ;将 EAX 中的 32 位整数, 与 EBX 中的内容所指的内存单元, 相乘, 然后把结果存到 EAX 中.
imul $25, %edi, %esi ;ESI 被设置为 EDI * 25.
idiv只有一个操作数,此操作数为除数,而被除数则为 EDX : EAX 中的内容(一个64位的整数), 除法结果 ( 商 ) 存在 EAX 中, 而所得的余数存在 EDX 中.
idiv <reg32
idiv <mem
idiv %ebx ;用 EDX : EAX 的值除以 EBX 的值. 商存放在 EAX 中, 余数存放在 EDX 中.
idivw (%ebx) ;将 EDX : EAX 的值除以存储在 EBX 所对应内存单元的 32 位值. 商存放在 EAX 中, 余数存放在 EDX 中.
-
and, or, xor 按位逻辑 与, 或, 异或 运算
这些指令分别对它们的参数进行相应的逻辑运算, 运算结果存到第一个参数中.
and <reg, <reg
and <mem, <reg
and <reg, <mem
and <con, <reg
and <con, <mem
or <reg, <reg
or <mem, <reg
or <reg, <mem
or <con, <reg
or <con, <mem
xor <reg, <reg
xor <mem, <reg
xor <reg, <mem
xor <con, <reg
xor <con, <mem
and $0x0F, %eax ;只留下 EAX 中最后 4 位数字 (二进制位)
xor %edx, %edx ;将 EDX 的值全部设置成 0
对参数进行逻辑非运算, 即翻转参数中所有位的值.
not <reg
not <mem
not %eax ;将 EAX 的所有值翻转.
取参数的二进制补码负数. 直接看例子也许会更好懂.
neg <reg
neg <mem
neg %eax ;EAX → -EAX
这两个指令对第一个参数进行位运算, 移动的位数由第二个参数决定, 移动过后的空位拿 0 补上.被移的参数最多可以被移 31 位. 第二个参数可以是 8 位常数或者寄存器 CL. 在任意情况下, 大于 31 的移位都默认是与 32 取模.
shl <con8, <reg
shl <con8, <mem
shl %cl, <reg
shl %cl, <mem
shr <con8, <reg
shr <con8, <mem
shr %cl, <reg
shr %cl, <mem
shl $1, %eax ;将 EAX 的值乘以 2 (如果最高有效位是 0 的话)
shr %cl, %ebx ;将 EBX 的值除以 2n, 其中 n 为 CL 中的值, 运算最终结果存到 EBX 中.
3.3.4.3 流程控制指令
x86 处理器有一个指令指针寄存器 ( EIP ), 该寄存器为 32 位寄存器, 它用来在内存中指示我们输入汇编指令的位置. 就是说这个寄存器指向哪个内存单元, 那个单元存储的机器码就是程序执行的指令. 通常它是指向我们程序要执行的 下一条指令. 但是你不能直接操作 EIP 寄存器, 你需要流程控制指令来隐式地给它赋值.
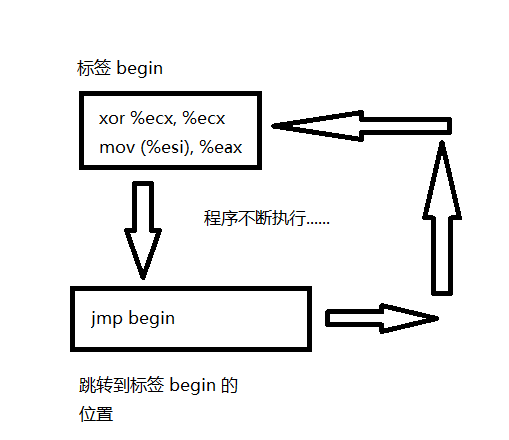
我们使用符号 <label 来当作程序中的标签. 通过输入标签名称后跟冒号, 可以将标签插入 x86 汇编代码文本中的任何位置. 例如 :
mov 8(%ebp), %esi
begin:
xor %ecx, %ecx
mov (%esi), %eax
该代码片段中的第二段被套上了 “ begin “ 这个标签. 在代码的其它地方, 我们可以用 “ begin “ 这个标签从而更方便地来引用这段指令在内存中的位置. 这个标签只是用来更方便地表示位置的, 它并不是用来代表某个 32 位值.
jmp <label
jmp begin ;跳转到打了 " begin " 这个标签的地方
这些指令是条件跳转指令, 它们基于一组条件代码的状态, 这些条件代码的状态存放在称为机器状态字 ( machine status word ) 的特殊寄存器中. 机器状态字的内容包括关于最后执行的算术运算的信息. 例如, 这个字的一个位表示最后的结果是否为 0. 另一个位表示最后结果是否为负数. 基于这些条件代码, 可以执行许多条件跳转. 例如, 如果最后一次算术运算结果为 0, 则 jz 指令就是跳转到指定参数标签. 否则, 程序就按照流程进入下一条指令.
许多条件分支的名称都是很直观的, 这些指令的运行, 都和一个特殊的比较指令有关, cmp( 见下文 ). 例如, 像 jle 和 jne 这种指令, 它们首先对参数进行 cmp 操作.
je <label ;当相等的时候跳转
jne <label ;当不相等的时候跳转
jz <label ;当最后结果为 0 的时候跳转
jg <label ;当大于的时候跳转
jge <label ;当大于等于的时候跳转
jl <label ;当小于的时候跳转
jle <label ;当小于等于的时候跳转
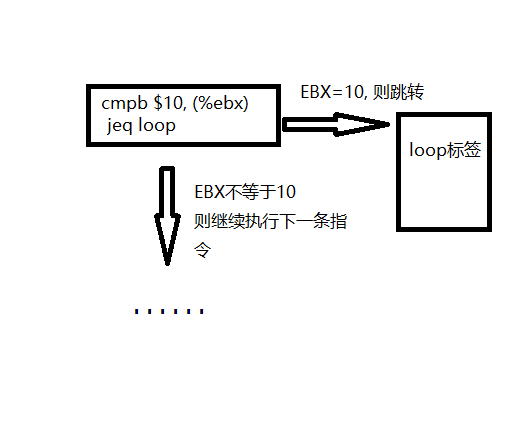
cmp %ebx, %eax
jle done
;如果 EAX 的值小于等于 EBX 的值, 就跳转到 " done " 标签, 否则就继续执行下一条指令.
比较两个参数的值, 适当地设置机器状态字中的条件代码. 此指令与sub指令类似,但是cmp不用将计算结果保存在操作数中.
cmp <reg, <reg
cmp <mem, <reg
cmp <reg, <mem
cmp <con, <reg
cmpb $10, (%ebx)
jeq loop
;如果 EBX 的值等于整数常量 10, 则跳转到标签 " loop " 的位置.
这两个指令实现子程序的调用和返回. call 指令首先将当前代码位置推到内存中硬件支持的栈内存上 ( 请看 push 指令 ), 然后无条件跳转到标签参数指定的代码位置. 与简单的 jmp 指令不同, call 指令保存了子程序完成时返回的位置. 就是 call 指令结束后, 返回到调用之前的地址.
ret 指令实现子程序的返回. 该指令首先从栈中取出代码 ( 类似于 pop 指令 ). 然后它无条件跳转到检索到的代码位置.
call <label
ret
3.3.5 调用约定 Calling Convention
为了方便不同的程序员去分享代码和运行库, 并简化一般子程序的使用, 程序员们通常会遵守一定的约定 ( Calling Convention ). 调用约定是关于如何从例程调用和返回的协议. 例如,给定一组调用约定规则,程序员不需要检查子例程的定义来确定如何将参数传递给该子例程. 此外,给定一组调用约定规则,可以使高级语言编译器遵循规则,从而允许手动编码的汇编语言例程和高级语言例程相互调用.
我们将讲解被广泛使用的 C 语言调用约定. 遵循此约定将允许您编写可从 C ( 和C ++ ) 代码安全地调用的汇编语言子例程, 并且还允许您从汇编语言代码调用 C 函数库.
C 调用约定很大程度上取决于使用硬件支持的栈内存. 它基于 push, pop, call 和 ret 指令. 子程序的参数在栈上传递. 寄存器保存在栈中, 子程序使用的局部变量放在栈中. 在大多数处理器上实现的高级过程语言都使用了类似的调用约定.
调用约定分为两组. 第一组规则是面向子例程的调用者 ( Caller ) 的, 第二组规则面向子例程的编写者, 即被调用者 ( Callee ). 应该强调的是, 错误地遵守这些规则会导致程序的致命错误, 因为栈将处于不一致的状态; 因此, 在你自己的子例程中实现调用约定的时候, 务必当心.
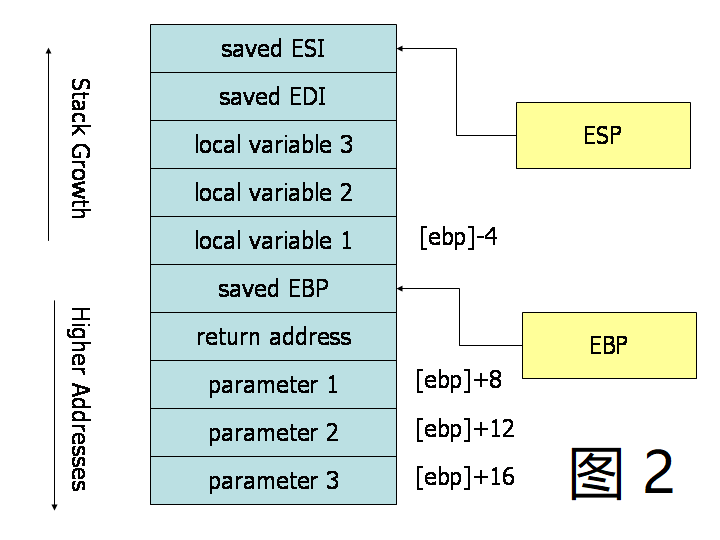
将调用约定可视化的一种好方法是, 在子例程执行期间画一个栈内存附近的图. 图 2 描绘了在执行具有三个参数和三个局部变量的子程序期间栈的内容. 栈中描绘的单元都是 32 位内存单元, 因此这些单元的内存地址相隔 4 个字节. 第一个参数位于距基指针 8 个字节的偏移处. 在栈参数的上方 ( 和基指针下方 ), call 指令在这放了返回地址, 从而导致从基指针到第一个参数有额外 4 个字节的偏移量. 当 ret 指令用于从子程序返回时, 它将跳转到栈中的返回地址.
3.3.5.1 调用者约定 Caller Rules
要进行子程序调用, 调用者应该 :
- 在调用子例程之前, 调用者应该保存指定调用者保存 ( Caller-saved )的某些寄存器的内容. 调用者保存的寄存器是 EAX, ECX, EDX. 由于被调用的子程序可以修改这些寄存器, 所以如果调用者在子例程返回后依赖这些寄存器的值, 调用者必须将这些寄存器的值入栈, 然后就可以在子例程返回后恢复它们.
- 要把参数传递给子例程, 你可以在调用之前把参数入栈. 参数的入栈顺序应该是反着的, 就是最后一个参数应该最先入栈. 随着栈内存地址增大, 第一个参数将存储在最低的地址, 在历史上, 这种参数的反转用于允许函数传递可变数量的参数.
- 要调用子例程, 请使用
call指令. 该指令将返回地址存到栈上, 并跳转到子程序的代码. 这个会调用子程序, 这个子程序应该遵循下面的被调用者约定.
子程序返回后 ( 紧跟调用指令后 ), 调用者可以期望在寄存器 EAX 中找到子例程的返回值. 要恢复机器状态 ( machine state ), 调用者应该 :
- 从栈中删除参数, 这会把栈恢复到调用之前的状态.
- 把 EAX, ECX, EDX 之前入栈的内容给出栈, 调用者可以假设子例程没有修改其它寄存器.
下面的代码就是个活生生的例子, 它展示了遵循约定的函数调用. 调用者正在调用一个带有 3 个整数参数的函数 myFunc. 第一个参数是 EAX, 第二个参数是常数 216; 第三个参数位于 EBX 的值所代表的内存地址.
push (%ebx) ;最后一个参数最先入栈
push $216 ;把第二个参数入栈
push %eax ;第一个参数最后入栈
call myFunc ;调用这个函数 ( 假设以 C 语言的模式命名 )
add $12, %esp
注意, 在调用返回后, 调用者使用 add 指令来清理栈内存. 我们栈内存中有 12 个字节 ( 3 个参数, 每个参数 4 个字节 ), 然后栈内存地址增大. 因此, 为了摆脱掉这些参数, 我们可以直接往栈里面加个 12.
myFunc 生成的结果现在可以有用于寄存器 EAX. 调用者保存 ( Caller-saved ) 的寄存器 ( ECX, EDX ) 的值可能已经被修改. 如果调用者在调用之后使用它们,则需要在调用之前将它们保存在堆栈中并在调用之后恢复它们. 说白了就是把栈这个玩意当作临时存放点.
3.3.5.2 被调用者约定 Callee Rules
子例程的定义应该遵循子例程开头的以下规则 :
- 1.将 EBP 的值入栈, 然后用下面的指示信息把 ESP 的值复制到 EBP 中 :
push %ebp
mov %esp, %ebp
这个初始操作保留了基指针 EBP. 按照约定, 基指针作为栈上找到参数和变量的参考点. 当子程序正在执行的时候, 基指针保存了从子程序开始执行是的栈指针值的副本. 参数和局部变量将始终位于远离基指针值的已知常量偏移处. 我们在子例程的开头推送旧的基指针值,以便稍后在子例程返回时为调用者恢复适当的基指针值. 记住, 调用者不希望子例程修改基指针的值. 然后我们把栈指针移动到 EBP 中, 以获取访问参数和局部变量的参考点.
- 2.接下来, 通过在栈中创建空间来分配局部变量. 回想一下, 栈会向下增长, 因此要在栈顶部创建空间, 栈指针应该递减. 栈指针递减的数量取决于所需局部变量的数量和大小. 例如, 如果需要 3 个局部整数 ( 每个 4 字节 ), 则需要将堆栈指针递减 12, 从而为这些局部变量腾出空间 ( 即sub $12, %esp ). 和参数一样, 局部变量将位于基指针的已知偏移处.
- 3.接下来, 保存将由函数使用的 被调用者保存的 ( Callee-saved ) 寄存器的值. 要存储寄存器, 请把它们入栈. 被调用者保存 ( Callee-saved ) 的寄存器是 EBX, EDI 和 ESI ( ESP 和 EBP 也将由调用约定保留, 但在这个步骤中不需要入栈 ).
在完成这 3 步之后, 子例程的主体可以继续. 返回子例程的时候, 必须遵循以下步骤 :
- 将返回值保存在 EAX 中.
- 恢复已经被修改的任何被调用者保存 ( Callee-saved ) 的寄存器 ( EDI 和 ESI ) 的旧值. 通过出栈来恢复它们. 当然应该按照相反的顺序把它们出栈.
- 释放局部变量. 显而易见的法子是把相应的值添加到栈指针 ( 因为空间是通过栈指针减去所需的数量来分配的 ). 事实上呢, 解除变量释放的错误的方法是将基指针中的值移动到栈指针 :
mov %ebp, %esp. 这个法子有效, 是因为基指针始终包含栈指针在分配局部变量之前包含的值.
- 在返回之前, 立即通过把 EBP 出栈来恢复调用者的基指针值. 回想一下, 我们在进入子程序的时候做的第一件事是推动基指针保存它的旧值.
- 最后, 通过执行
ret 指令返回. 这个指令将从栈中找到并删除相应的返回地址 ( call 指令保存的那个 ).
请注意, 被调用者的约定完全被分成了两半, 简直是彼此的镜像. 约定的前半部分适用于函数开头, 并且通常被称为定义函数的序言 ( prologue ) .这个约定的后半部分适用于函数结尾, 因此通常被称为定义函数的结尾 ( epilogue ).
这是一个遵循被调用者约定的例子 :
;启动代码部分
.text
;将 myFunc 定义为全局 ( 导出 ) 函数
.globl myFunc
.type myFunc, @function
myFunc :
;子程序序言
push %ebp ;保存基指针旧值
mov %esp, %ebp ;设置基指针新值
sub $4, %esp ;为一个 4 字节的变量腾出位置
push %edi
push %esi ;这个函数会修改 EDI 和 ESI, 所以先给它们入栈
;不需要保存 EBX, EBP 和 ESP
;子程序主体
mov 8(%ebp), %eax ;把参数 1 的值移到 EAX 中
mov 12(%ebp), %esi ;把参数 2 的值移到 ESI 中
mov 16(%ebp), %edi ;把参数 3 的值移到 EDI 中
mov %edi, -4(%ebp) ;把 EDI 移给局部变量
add %esi, -4(%ebp) ;把 ESI 添加给局部变量
add -4(%ebp), %eax ;将局部变量的内容添加到 EAX ( 最终结果 ) 中
;子程序结尾
pop %esi ;恢复寄存器的值
pop %edi
mov %ebp, %esp ;释放局部变量
pop %ebp ;恢复调用者的基指针值
ret
子程序序言执行标准操作, 即在 EBP ( 基指针 ) 中保存栈指针的副本, 通过递减栈指针来分配局部变量, 并在栈上保存寄存器的值.
在子例程的主体中, 我们可以看到基指针的使用. 在子程序执行期间, 参数和局部变量都位于与基指针的常量偏移处. 特别地, 我们注意到, 由于参数在调用子程序之前被放在栈中, 因此它们总是位于栈基指针 ( 即更高的地址 ) 之下. 子程序的第一个参数总是可以在内存地址 ( EBP+8 ) 找到, 第二个参数在 ( EBP+12 ), 第三个参数在 ( EBP+16). 类似地, 由于在设置基指针后分配局部变量, 因此它们总是位于栈上基指针 ( 即较低地址 ) 之上. 特别是, 第一个局部变量总是位于 ( EBP-4 ), 第二个位于 ( EBP-8 ), 以此类推. 这种基指针的常规使用, 让我们可以快速识别函数内部局部变量和参数的使用.
函数结尾基本上是函数序言的镜像. 从栈中恢复调用者的寄存器值, 通过重置栈指针来释放局部变量, 恢复调用者的基指针值, 并用 ret 指令返回调用者中的相应代码位置, 从哪来回哪去.
维基百科 X86 调用约定
3.4 x64 汇编基础
3.4.1 导语
x86-64 (也被称为 x64 或者 AMD64) 是 64 位版本的 x86/IA32 指令集. 以下是我们关于 CS107 相关功能的概述.
3.4.2 寄存器 Registers
下图列出了常用的寄存器 ( 16个通用寄存器加上 2 个特殊用途寄存器 ). 每个寄存器都是 64 bit 宽, 它们的低 32, 16, 8 位都可以看成相应的 32, 16, 8 位寄存器, 并且都有其特殊名称. 一些寄存器被设计用来完成某些特殊目的, 比如 %rsp 被用来作为栈指针, %rax 作为一个函数的返回值. 其他寄存器则都是通用的, 但是一般在使用的时候, 还是要取决于调用者 ( Caller-owned )或者被调用者 ( Callee-owned ). 如果函数 binky 调用了 winky, 我们称 binky 为调用者, winky 为被调用者. 例如, 用于前 6 个参数和返回值的寄存器都是被调用者所有的 ( Callee-owned ). 被调用者可以任意使用这些寄存器, 不用任何预防措施就可以随意覆盖里面的内容. 如果 %rax 存着调用者想要保留的值, 则 Caller 必须在调用之前将这个 %rax 的值复制到一个 “ 安全 “ 的位置. 被调用者拥有的 ( Callee-owned ) 寄存器非常适合一些临时性的使用. 相反, 如果被调用者打算使用调用者所拥有的寄存器, 那么被调用者必须首先把这个寄存器的值存起来, 然后在退出调用之前把它恢复. 调用者拥有的 ( Caller-owned ) 寄存器用于保存调用者的本地状态 ( local state ), 所以这个寄存器需要在进一步的函数调用中被保留下来.
3.4.3 寻址模式 Addressing modes
正由于它的 CISC 特性, X86-64 支持各种寻址模式. 寻址模式是计算要读或写的内存地址的表达式. 这些表达式用作mov指令和访问内存的其它指令的来源和去路. 下面的代码演示了如何在每个可用的寻址模式中将 立即数 1 写入各种内存位置 :
movl $1, 0x604892 ;直接写入, 内存地址是一个常数
movl $1, (%rax) ;间接写入, 内存地址存在寄存器 %rax 中
movl $1, -24(%rbp) ;使用偏移量的间接写入
;公式 : (address = base %rbp + displacement -24)
movl $1, 8(%rsp, %rdi, 4) ;间接写入, 用到了偏移量和按比例放大的索引 ( scaled-index )
;公式 : (address = base %rsp + displ 8 + index %rdi * scale 4)
movl $1, (%rax, %rcx, 8) ;特殊情况, 用到了按比例放大的索引 ( scaled-index ), 假设偏移量 ( displacement ) 为 0
movl $1, 0x8(, %rdx, 4) ;特殊情况, 用到了按比例放大的索引 ( scaled-index ), 假设基数 ( base ) 为 0
movl $1, 0x4(%rax, %rcx) ;特殊情况, 用到了按比例放大的索引 ( scaled-index ), 假设比例 ( scale ) 为0
3.4.4 通用指令 Common instructions
先说下指令后缀, 之前讲过这里就重温一遍 : 许多指令都有个后缀 ( b, w, l, q ) , 后缀指明了这个指令代码所操纵参数数据的位宽 ( 分别为 1, 2, 4 或 8 个字节 ). 当然, 如果可以从参数确定位宽的时候, 后缀可以被省略. 例如呢, 如果目标寄存器是 %eax, 则它必须是 4 字节宽, 如果是 %ax 寄存器, 则必须是 2 个字节, 而 %al 将是 1 个字节. 还有些指令, 比如 movs 和 movz 有两个后缀 : 第一个是来源参数, 第二个是去路. 这话乍一看让人摸不着头脑, 且听我分析. 例如, movzbl 这个指令把 1 个字节的来源参数值移动到 4 个字节的去路.
当目标是子寄存器 ( sub-registers ) 时, 只有子寄存器的特定字节被写入, 但有一个例外 : 32 位指令将目标寄存器的高 32 位设置为 0.
mov 和 lea 指令
到目前为止, 我们遇到的最频繁的指令就是 mov, 而它有很多变种. 关于 mov 指令就不多说了, 和之前 32 位 x86 的没什么区别. lea 指令其实也没什么好说的, 上一节都有, 这里就不废话了.
这里写几个比较有意思的例子 :
mov 8(%rsp), %eax ;%eax = 从地址 %rsp + 8 读取的值
lea 0x20(%rsp), %rdi ;%rdi = %rsp + 0x20
lea (%rdi,%rdx,1), %rax ;%rax = %rdi + %rdx
在把较小位宽的数据移动复制到较大位宽的情况下, movs 和 movz 这两个变种指令用于指定怎么样去填充字节, 因为你是一个小东西被移到了一个大空间, 肯定还有地方是空的, 所以空的地方要填起来, 拿 0 或者 符号扩展 ( sign-extend ) 来填充.
movsbl %al, %edx ;把 1 个字节的 %al, 符号扩展 复制到 4 字节的 %edx
movzbl %al, %edx ;把 1 个字节的 %al, 零扩展 ( zero-extend ) 复制到 4 字节的 %edx
有个特殊情况要注意, 默认情况下, 将 32 位值写入寄存器的 mov 指令, 也会将寄存器的高 32 位归零, 即隐式零扩展到位宽 q. 这个解释了诸如 mov %ebx, %ebx 这种指令, 这些指令看起来很奇怪, 但实际上这是用于从 32 位扩展到 64 位. 因为这个是默认的, 所以我们不用显式的 movzlq 指令. 当然, 有一个 movslq 指令也是从 32 位符号扩展到 64 位.
cltq 指令是一个在 %rax 上运行的专用移动指令. 这个没有参数的指令在 %rax 上进行符号扩展, 源位宽为 L, 目标位宽为 q.
cltq ;在 %rax 上运行,将 4 字节 src 符号扩展为 8 字节 dst,用于 movslq %eax,%rax
算术和位运算
二进制的运算一般是两个参数, 其中第二个参数既是我们指令运算的来源, 也是去路的来源, 就是说我们把运算结果存在第二个参数里. 我们的第一个参数可以是立即数常数, 寄存器或者内存单元. 第二个参数必须是寄存器或者内存. 这两个参数中, 最多只有一个参数是内存单元, 当然也有的指令只有一个参数, 这个参数既是我们运算数据的来源, 也是我们运算数据的去路, 它可以是寄存器或者内存. 这个我们上一节讲了, 这里回顾一下. 许多算术指令用于有符号和无符号类型,也就是带符号加法和无符号加法都使用相同的指令. 当需要的时候, 参数设置的条件代码可以用来检测不同类型的溢出.
add src, dst ;dst = dst + src
sub src, dst ;dst = dst - src
imul src, dst ;dst = dst * src
neg dst ;dst = -dst ( 算术取反 )
and src, dst ;dst = dst & src
or src, dst ;dst = dst | src
xor src, dst ;dst = dst ^ src
not dst ;dst = ~dst ( 按位取反 )
shl count, dst ;dst <<= count ( 按 count 的值来左移 ), 跟这个相同的是`sal`指令
sar count, dst ;dst = count ( 按 count 的值来算术右移 )
shr count, dst ;dst = count ( 按 count 的值来逻辑右移 )
;某些指令有特殊情况变体, 这些变体有不同的参数
imul src ;一个参数的 imul 指令假定 %rax 中其他参数计算 128 位的结果, 在 %rdx 中存储高 64 位, 在 %rax 中存储低 64 位.
shl dst ;dst <<= 1 ( 后面没有 count 参数的时候默认是移动 1 位, `sar`, `shr`, `sal` 指令也是一样 )
这些指令上一节都讲过, 这里稍微提一下.
流程控制指令
有一个特殊的 %eflags 寄存器, 它存着一组被称为条件代码的布尔标志. 大多数的算术运算会更新这些条件代码. 条件跳转指令读取这些条件代码之后, 再确定是否执行相应的分支指令. 条件代码包括 ZF( 零标志 ), SF( 符号标志 ), OF( 溢出标志, 有符号 ) 和 CF( 进位标志, 无符号 ). 例如, 如果结果为 0 , 则设置 ZF, 如果操作溢出 ( 进入符号位 ), 则设置 OF.
这些指令一般是先执行 cmp 或 test 操作来设置标志, 然后再跟跳转指令变量, 该变量读取标志来确定是采用分支代码还是继续下一条代码. cmp 或 test 的参数是立即数, 寄存器或者内存单元 ( 最多只有一个内存参数 ). 条件跳转有 32 中变体, 其中几种效果是一样的. 下面是一些分支指令.
cmpl op2, op1 ;运算结果 = op1 - op2, 丢弃结果然后设置条件代码
test op2, op1 ;运算结果 = op1 & op2, 丢弃结果然后设置条件代码
jmp target ;无条件跳跃
je target ;等于时跳跃, 和它相同的还有 jz, 即jump zero ( ZF = 1 )
jne target ;不相等时跳跃, 和它相同的还有 jnz, 即 jump non zero ( ZF = 0 )
jl target ;小于时跳跃, 和它相同的还有 jnge, 即 jump not greater or equal ( SF != OF )
jle target ;小于等于时跳跃, 和它相同的还有 jng, 即 jump not greater ( ZF = 1 or SF != OF )
jg target ;大于时跳跃, 和它相同的还有 jnle, 即 jump not less or equal ( ZF = 0 and SF = OF )
jge target ;大于等于时跳跃, 和它相同的还有 jnl, 即 jump not less ( SF = OF )
ja target ;跳到上面, 和它相同的还有 jnbe, 即 jump not below or equal ( CF = 0 and ZF = 0 )
jb target ;跳到下面, 和它相同的还有 jnae, 即 jump not above or equal ( CF = 1 )
js target ;SF = 1 时跳跃
jns target ;SF = 0 时跳跃
其实你也会发现这里大部分上一节都讲过, 这里我们可以再来一遍巩固一下.
setx和movx
还有两个指令家族可以 读取/响应 当前的条件代码. setx 指令根据条件 x 的状态将目标寄存器设置为 0 或 1. cmovx 指令根据条件 x 是否成立来有条件地执行 mov. x 是任何条件变量的占位符, 就是说 x 可以用这些来代替 : e, ne, s, ns. 它们的意思上面也都说过了.
sete dst ;根据 零/相等( zero/equal ) 条件来把 dst 设置成 0 或 1
setge dst ;根据 大于/相等( greater/equal ) 条件来把 dst 设置成 0 或 1
cmovns src, dst ;如果 ns 条件成立, 则继续执行 mov
cmovle src, dst ;如果 le 条件成立, 则继续执行 mov
对于 setx 指令, 其目标必须是单字节寄存器 ( 例如 %al 用于 %rax 的低字节 ). 对于 cmovx 指令, 其来源和去路都必须是寄存器.
函数调用与栈
%rsp 寄存器用作 “ 栈指针 “; push 和 pop 用于添加或者删除栈内存中的值. push 指令只有一个参数, 这个参数是立即数常数, 寄存器或内存单元. push 指令先把 %rsp 的值递减, 然后将参数复制到栈内存上的 tompost. pop 指令也只有一个参数, 即目标寄存器. pop 先把栈内存最顶层的值复制到目标寄存器, 然后把 %rsp 递增. 直接调整 %rsp, 以通过单个参数添加或删除整个数组或变量集合也是可以的. 但注意, 栈内存是朝下增长 ( 即朝向较低地址 ).
push %rbx ;把 %rbx 入栈
pushq $0x3 ;把立即数 3 入栈
sub $0x10, %rsp ;调整栈指针以空出 16 字节
pop %rax ;把栈中最顶层的值出栈到寄存器 %rax 中
add $0x10, %rsp ;调整栈指针以删除最顶层的 16 个字节
函数之间是通过互相调用返回来互相控制的. callq 指令有一个参数, 即被调用的函数的地址. 它将返回来的地址入栈, 这个返回来的地址即 %rip 当前的值, 也即是调用函数后的下一条指令. 然后这个指令让程序跳转到被调用的函数的地址. retq 指令把刚才入栈的地址给出栈, 让它回到 %rip 中, 从而让程序在保存的返回地址处重新开始, 就是说你中途跳到别的地方去, 你回来的时候要从你跳的那个地方重新开始.
当然, 你如果要设置这种函数间的互相调用, 调用者需要将前六个参数放入寄存器 %rdi, %rsi, %rdx, %rcx, %r8 和 %r9 ( 任何其它参数都入栈 ), 然后再执行调用指令.
mov $0x3, %rdi ;第一个参数在 %rdi 中
mov $0x7, %rsi ;第二个参数在 %rsi 中
callq binky ;把程序交给 binky 控制
当被调用者那个函数完事的时候, 这个函数将返回值 ( 如果有的话 ) 写入 %rax, 然后清理栈内存, 并使用 retq 指令把程序控制权交还给调用者.
mov $0x0, %eax ;将返回值写入 %rax
add $0x10, %rsp ;清理栈内存
retq ;交还控制权, 跳回去
这些分支跳转指令的目标通常是在编译时确定的绝对地址. 但是, 有些情况下直到运行程序的时候, 我们才知道目标的绝对内存地址. 例如编译为跳转表的 switch 语句或调用函数指针时. 对于这些, 我们先计算目标地址, 然后把地址存到寄存器中, 然后用 分支/调用( branch/call ) 变量 je *%rax 或 callq *%rax 从指定寄存器中读取目标地址.
当然还有更简单的方法, 就是上一节讲的打标签.
3.4.5 汇编和 gdb
调试器 ( debugger ) 有许多功能, 这可以让你可以在程序中追踪和调试代码. 你可以通过在其名称上加个 $ 来打印寄存器中的值, 或者使用命令 info reg 转储所有寄存器的值 :
(gdb) p $rsp
(gdb) info reg
disassemble 命令按照名称打印函数的反汇编. x 命令支持 i 格式, 这个格式把内存地址的内容解释为编码指令 ( 解码 ).
(gdb) disassemble main //反汇编, 然后打印所有 main 函数的指令
(gdb) x/8i main //反汇编, 然后打印开始的 8 条指令
你可以通过在函数中的直接地址或偏移量为特定汇编指令设置断点.
(gdb) b *0x08048375
(gdb) b *main+7 //在 main+7个字节这里设置断点
你可以用 stepi 和 nexti 命令来让程序通过指令 ( 而不是源代码 ) 往前执行.
(gdb) stepi
(gdb) nexti
3.5 ARM汇编基础
3.5.1 引言
本章所讲述的是在 GNU 汇编程序下的 ARM 汇编快速指南,而所有的代码示例都会采用下面的结构:
[< 标签 label :] {<指令 instruction or directive } @ 注释 comment
在 GNU 程序中不需要缩进指令。程序的标签是由冒号识别而与所处的位置无关。 就通过一个简单的程序来介绍:
.section .text, "x"
.global add @给符号添加外部链接
add:
ADD r0, r0, r1 @添加输入参数
MOV pc, lr @从子程序返回
@程序结束
它定义的是一个返回总和函数 “ add ”,允许两个输入参数。通过了解这个程序实例,想必接下来这类程序的理解我们也能够很好的的掌握。
3.5.2 ARM 的 GNU 汇编程序指令表
在 GNU 汇编程序下的 ARM 指令集涵括如下:
| GUN 汇编程序指令 |
描述 |
.ascii "<string>" |
将字符串作为数据插入到程序中 |
.asciz "<string>" |
与 .ascii 类似,但跟随字符串的零字节 |
.balign <power_of_2> {,<fill_value>{,<max_padding>} } |
将地址与 <power_of_2> 字节对齐。 汇编程序通过添加值 <fill_value> 的字节或合适的默认值来对齐. 如果需要超过 <max_padding> 这个数字来填充字节,则不会发生对齐( 类似于armasm 中的 ALIGN ) |
.byte <byte1> {,<byte2> } … |
将一个字节值列表作为数据插入到程序中 |
.code <number_of_bits> |
以位为单位设置指令宽度。 使用 16 表示 Thumb,32 表示 ARM 程序( 类似于 armasm 中的 CODE16 和 CODE32 ) |
.else |
与.if和 .endif 一起使用( 类似于 armasm 中的 ELSE ) |
.end |
标记程序文件的结尾( 通常省略 ) |
.endif |
结束条件编译代码块 - 参见.if,.ifdef,.ifndef( 类似于 armasm 中的 ENDIF ) |
.endm |
结束宏定义 - 请参阅 .macro( 类似于 armasm 中的 MEND ) |
.endr |
结束重复循环 - 参见 .rept 和 .irp(类似于 armasm 中的 WEND ) |
.equ <symbol name>, <vallue> |
该指令设置符号的值( 类似于 armasm 中的 EQU ) |
.err |
这个会导致程序停止并出现错误 |
.exitm |
中途退出一个宏 - 参见 .macro( 类似于 armasm 中的 MEXIT ) |
.global <symbol> |
该指令给出符号外部链接( 类似于 armasm 中的 MEXIT )。 |
.hword <short1> {,<short2> }... |
将16位值列表作为数据插入到程序中( 类似于 armasm 中的 DCW ) |
.if <logical_expression> |
把一段代码变成前提条件。 使用 .endif 结束代码块( 类似于 armasm中的 IF )。 另见 .else |
.ifdef <symbol> |
如果定义了 <symbol>,则包含一段代码。 结束代码块用 .endif, 这就是个条件判断嘛, 很简单的. |
.ifndef <symbol> |
如果未定义 <symbol>,则包含一段代码。 结束代码块用 .endif, 同上. |
.include "<filename>" |
包括指定的源文件, 类似于 armasm 中的 INCLUDE 或 C 中的#include |
.irp <param> {,<val 1>} {,<val_2>} ... |
为值列表中的每个值重复一次代码块。 使用 .endr 指令标记块的结尾。 在里面重复代码块,使用 \<param> 替换关联的代码块值列表中的值。 |
.macro <name> {<arg_1>} {,< arg_2>} ... {,<arg_N>} |
使用 N 个参数定义名为<name>的汇编程序宏。宏定义必须以 .endm 结尾。 要在较早的时候从宏中逃脱,请使用 .exitm。 这些指令是类似于 armasm 中的 MACRO,MEND 和MEXIT。 你必须在虚拟宏参数前面加 \. |
.rept <number_of_times> |
重复给定次数的代码块。 以.endr结束。 |
<register_name> .req <register_name> |
该指令命名一个寄存器。 它与 armasm 中的 RN 指令类似,不同之处在于您必须在右侧提供名称而不是数字(例如,acc .req r0) |
.section <section_name> {,"<flags> "} |
启动新的代码或数据部分。 GNU 中有这些部分:.text代码部分;.data初始化数据部分和.bss未初始化数据部分。 这些部分有默认值flags和链接器理解默认名称(与armasm指令AREA类似的指令)。 以下是 ELF 格式文件允许的 .section标志:a 表示 allowable sectionw 表示 writable sectionx 表示 executable section |
.set <variable_name>, <variable_value> |
该指令设置变量的值。 它类似于 SETA。 |
.space <number_of_bytes> {,<fill_byte> } |
保留给定的字节数。 如果指定了字节,则填充零或 <fill_byte>(类似于 armasm 中的 SPACE) |
.word <word1> {,<word2>}... |
将 32 位字值列表作为数据插入到程序集中(类似于 armasm 中的 DCD)。 |
3.5.3 寄存器名称
通用寄存器:
%r0 - %r15
fp 寄存器:
%f0 - %f7
临时寄存器:
%r0 - %r3, %r12
保存寄存器:
%r4 - %r10
堆栈 ptr 寄存器:
%sp
帧 ptr 寄存器:
%fp
链接寄存器:
%lr
程序计数器:
%ip
状态寄存器:
$psw
状态标志寄存器:
xPSR
xPSR_all
xPSR_f
xPSR_x
xPSR_ctl
xPSR_fs
xPSR_fx
xPSR_fc
xPSR_cs
xPSR_cf
xPSR_cx
3.5.4 汇编程序特殊字符/语法
内联评论字符: ‘@’
行评论字符: ‘#’
语句分隔符: ‘;’
立即操作数前缀: ‘#’ 或 ‘$’
3.5.5 arm程序调用标准
参数寄存器 :%a0 - %a4(别名为%r0 - %r4)
返回值regs :%v1 - %v6(别名为%r4 - %r9)
3.5.6 寻址模式
addr 绝对寻址模式
%rn 寄存器直接寻址
[%rn] 寄存器间接寻址或索引
[%rn,#n] 基于寄存器的偏移量
上述 “rn” 指任意寄存器,但不包括控制寄存器。
3.5.7 机器相关指令
| 指令 |
描述 |
| .arm |
使用arm模式进行装配 |
| .thumb |
使用thumb模式进行装配 |
| .code16 |
使用thumb模式进行装配 |
| .code32 |
使用arm模式进行组装 |
| .force_thumb Force |
thumb模式(即使不支持) |
| .thumb_func |
将输入点标记为thumb编码(强制bx条目) |
| .ltorg |
启动一个新的文字池 |
3.6 MIPS汇编基础
数据类型和常量
- 数据类型:
- 指令全是32位
- 字节(8位),半字(2字节),字(4字节)
- 一个字符需要1个字节的存储空间
- 整数需要1个字(4个字节)的存储空间
- 常量:
- 按原样输入的数字。例如 4
- 用单引号括起来的字符。例如 ‘b’
- 用双引号括起来的字符串。例如 “A string”
寄存器
两种格式用于寻址:
- 使用寄存器号码,例如
$ 0 到 $ 31
- 使用别名,例如
$ t1,$ sp
- 特殊寄存器 Lo 和 Hi 用于存储乘法和除法的结果
- 不能直接寻址; 使用特殊指令
mfhi( “ 从 Hi 移动 ” )和 mflo( “ 从 Lo 移动 ” )访问的内容
- 栈从高到低增长
| 寄存器 |
别名 |
用途 |
$0 |
$zero |
常量0(constant value 0) |
$1 |
$at |
保留给汇编器(Reserved for assembler) |
$2-$3 |
$v0-$v1 |
函数调用返回值(values for results and expression evaluation) |
$4-$7 |
$a0-$a3 |
函数调用参数(arguments) |
$8-$15 |
$t0-$t7 |
暂时的(或随便用的) |
$16-$23 |
$s0-$s7 |
保存的(或如果用,需要SAVE/RESTORE的)(saved) |
$24-$25 |
$t8-$t9 |
暂时的(或随便用的) |
$26~$27 |
$k0~$k1 |
保留供中断/陷阱处理程序使用 |
$28 |
$gp |
全局指针(Global Pointer) |
$29 |
$sp |
堆栈指针(Stack Pointer) |
$30 |
$fp |
帧指针(Frame Pointer) |
$31 |
$ra |
返回地址(return address) |
再来说一说这些寄存器 :
- zero 它一般作为源寄存器,读它永远返回 0,也可以将它作为目的寄存器写数据,但效果等于白写。为什么单独拉一个寄存器出来返回一个数字呢?答案是为了效率,MIPS 的设计者只允许在寄存器内执行算术操作,而不允许直接操作立即数。所以对最常用的数字 0 单独留了一个寄存器,以提高效率
- at 该寄存器为给编译器保留,用于处理在加载 16 位以上的大常数时使用,编译器或汇编程序需要把大常数拆开,然后重新组合到寄存器里。系统程序员也可以显式的使用这个寄存器,有一个汇编 directive 可被用来禁止汇编器在 directive 之后再使用 at 寄存器。
- v0, v1.这两个很简单,用做函数的返回值,大部分时候,使用 v0 就够了。如果返回值的大小超过 8 字节,那就需要分配使用堆栈,调用者在堆栈里分配一个匿名的结构,设置一个指向该参数的指针,返回时 v0 指向这个对应的结构,这些都是由编译器自动完成。
- a0-a3. 用来传递函数入参给子函数。看一下这个例子:
ret = strncmp("bear","bearer",4)参数少于 16 字节,可以放入寄存器中,在 strncmp 的函数里,a0 存放的是 “bear” 这个字符串所在的只读区地址,a1 是 “bearer” 的地址,a2 是 4.
- t0-t9 临时寄存器 s0-s8 保留寄存器这两种寄存器需要放在一起说,它们是 mips 汇编里面代码里见到的最多的两种寄存器,它们的作用都是存取数据,做计算、移位、比较、加载、存储等等,区别在于,t0-t9 在子程序中可以使用其中的值,并不必存储它们,它们很适合用来存放计算表达式时使用的“临时”变量。如果这些变量的使用要要跳转到子函数之前完成,因为子函数里很可能会使用相同的寄存器,而且不会有任何保护。如果子程序里不会调用其它函数那么建议尽量多的使用t0-t9,这样可以避免函数入口处的保存和结束时的恢复。相反的,s0-s8 在子程序的执行过程中,需要将它们存储在堆栈里,并在子程序结束前恢复。从而在调用函数看来这些寄存器的值没有变化。
- k0, k1. 这两个寄存器是专门预留给异常处理流程中使用。异常处理流程中有什么特别的地方吗?当然。当 MIPS CPU 在任务里运行的时候,一旦有外部中断或者异常发生,CPU 就会立刻跳转到一个固定地址的异常 handler 函数执行,并同时将异常结束后返回到任务的指令地址记录在 EPC 寄存器(Exception Program Counter)里。习惯性的,异常 handler 函数开头总是会保持现场即 MIPS 寄存器到中断栈空间里,而在异常返回前,再把这些寄存器的值恢复回去。那就存在一个问题,这个 EPC 里的值存放在哪里?异常 handler 函数的最后肯定是一句
jr x,X 是一个 MIPS 寄存器,如果存放在前面提到的 t0,s0 等等,那么 PC 跳回任务执行现场时,这个寄存器里的值就不再是异常发生之前的值。所以必须要有时就可以一句 jr k0指令返回了。k1 是另外一个专为异常而生的寄存器,它可以用来记录中断嵌套的深度。CPU 在执行任务空间的代码时,k1 就可以置为 0,进入到中断空间,每进入一次就加 1,退出一次相应减 1,这样就可以记录中断嵌套的深度。这个深度在调试问题的时候经常会用到,同时应用程序在做一次事情的时候可能会需要知道当前是在任务还是中断上下文,这时,也可以通过 k1 寄存器是否为 0 来判断。
- sp 指向当前正在操作的堆栈顶部,它指向堆栈中的下一个可写入的单元,如果从栈顶获取一个字节是 sp-1 地址的内容。在有 RTOS 的系统里,每个 task 都有自己的一个堆栈空间和实时 sp 副本,中断也有自己的堆栈空间和 sp 副本,它们会在上下文切换的过程中进行保存和恢复。
- gp 这是一个辅助型的寄存器,其含义较为模糊,MIPS 官方为该寄存器提供了两个用法建议,一种是指向 Linux 应用中位置无关代码之外的数据引用的全局偏移量表;在运行 RTOS 的小型嵌入式系统中,它可以指向一块访问较为频繁的全局数据区域,由于MIPS 汇编指令长度都是 32bit,指令内部的 offset 为 16bit,且为有符号数,所以能用一条指令以 gp 为基地址访问正负 15bit 的地址空间,提高效率。那么编译器怎么知道gp初始化的值呢?只要在 link 文件中添加 _gp 符号,连接器就会认为这是 gp 的值。我们在上电时,将 _gp 的值赋给 gp 寄存器就行了。话说回来,这都是 MIPS 设计者的建议,不是强制,楼主还见过一种 gp 寄存器的用法,来在中断和任务切换时做 sp 的存储过渡,也是可以的。
- fp 这个寄存器不同的编译器对其解释不同,GNU MIPS C 编译器使用其作为帧指针,指向堆栈里的过程帧(一个子函数)的第一个字,子函数可以用其做一个偏移访问栈帧里的局部变量,sp 也可以较为灵活的移动,因为在函数退出之前使用 fp 来恢复;还要一种而 SGI 的 C 编译器会将这个寄存器直接作为 s8,扩展了一个保留寄存器给编译器使用。
- ra 在函数调用过程中,保持子函数返回后的指令地址。汇编语句里函数调用的形式为:
jal function_X这条指令 jal(jump-and-link,跳转并链接) 指令会将当期执行运行指令的地址 +4 存储到 ra 寄存器里,然后跳转到 function_X 的地址处。相应的,子函数返回时,最常见的一条指令就是jr rara 是一个对于调试很有用的寄存器,系统的运行的任何时刻都可以查看它的值以获取 CPU 的运行轨迹。
最后,如果纯写汇编语句的话,这些寄存器当中除了 zero 之外,其它的基本上都可以做普通寄存器存取数据使用(这也是它们为什么会定义为“通用寄存器”,而不像其它的协处理器、或者外设的都是专用寄存器,其在出厂时所有的功能都是定死的),那为什么有这么多规则呢 ?MIPS 开发者们为了让自己的处理器可以运行像 C、Java 这样的高级语言,以及让汇编语言和高级语言可以安全的混合编程而设计的一套 ABI(应用编程接口),不同的编译器的设计者们就会有据可依,系统程序员们在阅读、修改汇编程序的时候也能根据这些约定而更为顺畅地理解汇编代码的含义。
程序结构
- 本质上只是带有数据声明的纯文本文件,程序代码 ( 文件名应以后缀 .s 结尾,或者.asm )
- 数据声明部分后跟程序代码部分
数据声明
- 数据以
.data 为标识
- 声明变量后,即在内存中分配空间
代码
- 放在用汇编指令
.text 标识的文本部分中
- 包含程序代码( 指令 )
- 给定标签
main 代码执行的起点 ( 和 C 语言一样 )
- 程序结束标志(见下面的系统调用)
注释
# 后面的任何内容都会被视为注释
#给出程序名称和功能描述的注释
#Template.s
#MIPS汇编语言程序的Bare-bones概述
.data #变量声明遵循这一行
#...
.text#指令跟随这一行
main:#表示代码的开始(执行的第一条指令)
#...
#程序结束,之后留空,让SPIM满意.
变量声明
声明格式:
name:storage_type value(s)
使用给定名称和指定值为指定类型的变量创建空间
value (s) 通常给出初始值; 对于.space,给出要分配的空格数
注意:标签后面跟冒号(
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)




