逆向爬虫12 selenium小进阶+案例
一、关于验证码
如何处理验证码:
1. 直接把浏览器里面的cookie拿出来直接用.
2. 手动编写验证码识别的功能(深度学习)
3. 第三方打码平台(收费), 超级鹰, 图鉴
除了超级鹰外,图鉴也是一个非常好用的第三方平台验证码识别工具,下面给出官方python代码示例:
1. 图鉴官方python代码示例
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
if __name__ == "__main__":
img_path = "C:/Users/Administrator/Desktop/file.jpg" # 换成你要识别的验证码图片
result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3) # 换成你的账号和密码
print(result)
2. 使用图鉴登录图鉴
之前用 selenium+超级鹰 成功解决了超级鹰的登录,这里使用 requests+图鉴 来解决图鉴的登录
使用 requests模块 就必须抓包了解网页的加载请求过程,这里我们先认为进行一次登录,通过 F12 开发者工具来观察加载顺序
- 下图是登录时的
HTTP请求头 信息,从中可以得知登录的 url链接 ,方法是 POST请求
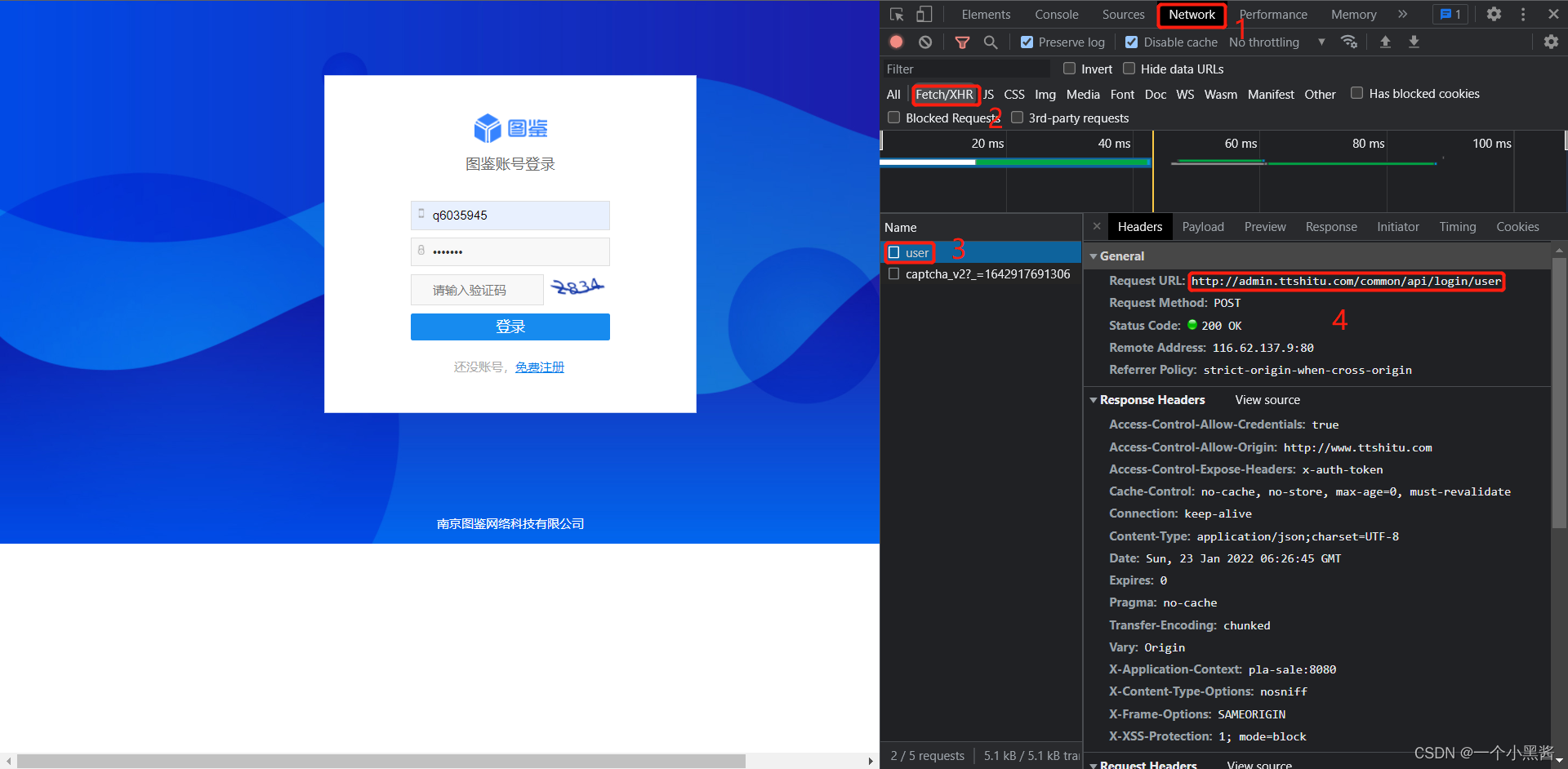
- 下图是该POST请求所携带的参数,其中
captcha 是验证码,imgId 是验证码图片ID,两者如果匹配则允许登录,下面我们就要想方设法获取到这两个参数。

- 清掉抓包缓存内容,刷新下页面,获得下图,验证码刷新了,且重新发起了个
GET请求 ,猜测该请求是用来获取验证码图片的
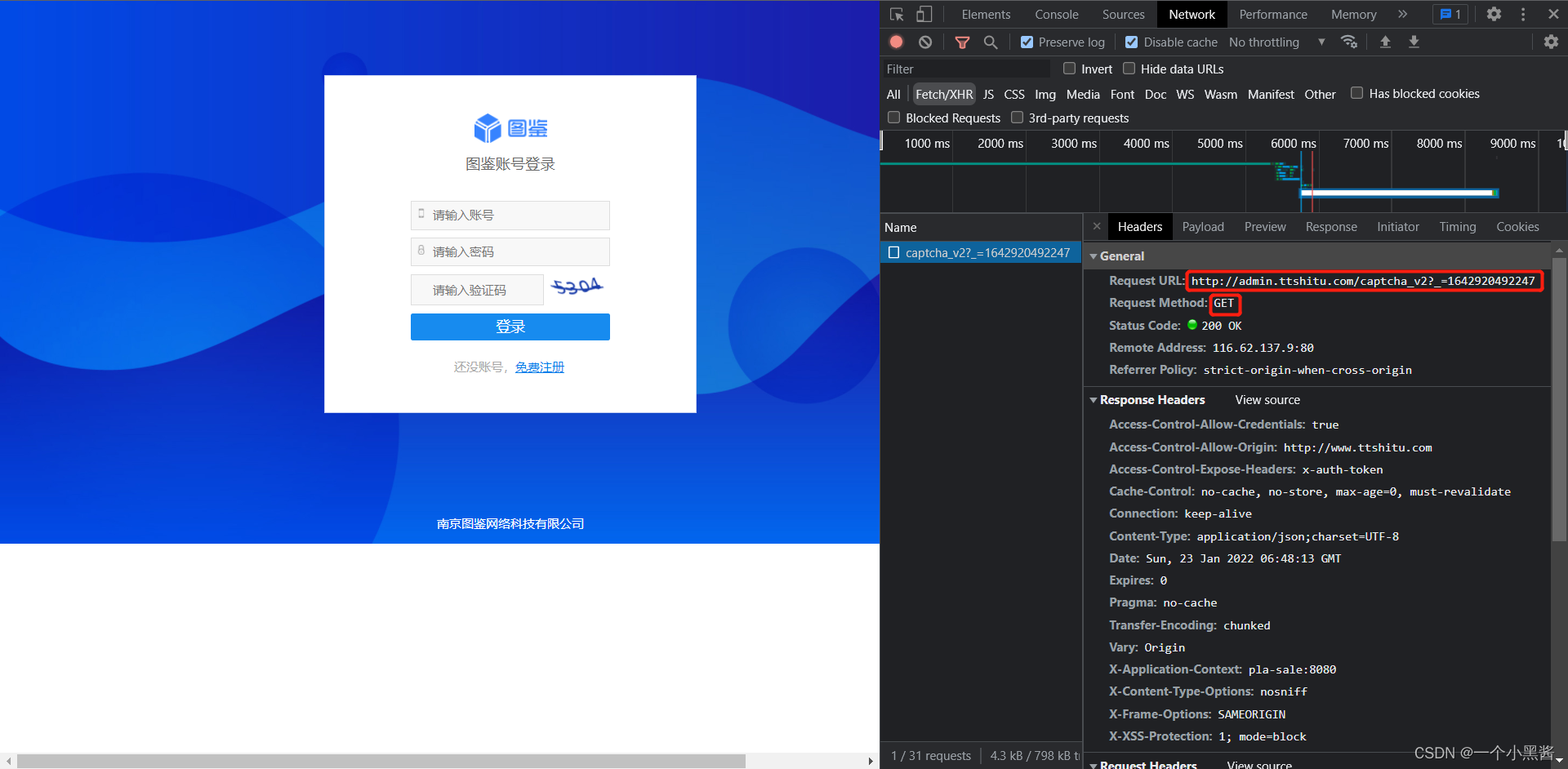
- 进入响应预览中看到下图,果然是和图片相关,且包含
imgId参数,其中 img参数 就是验证码图像的 base64 编码字符串
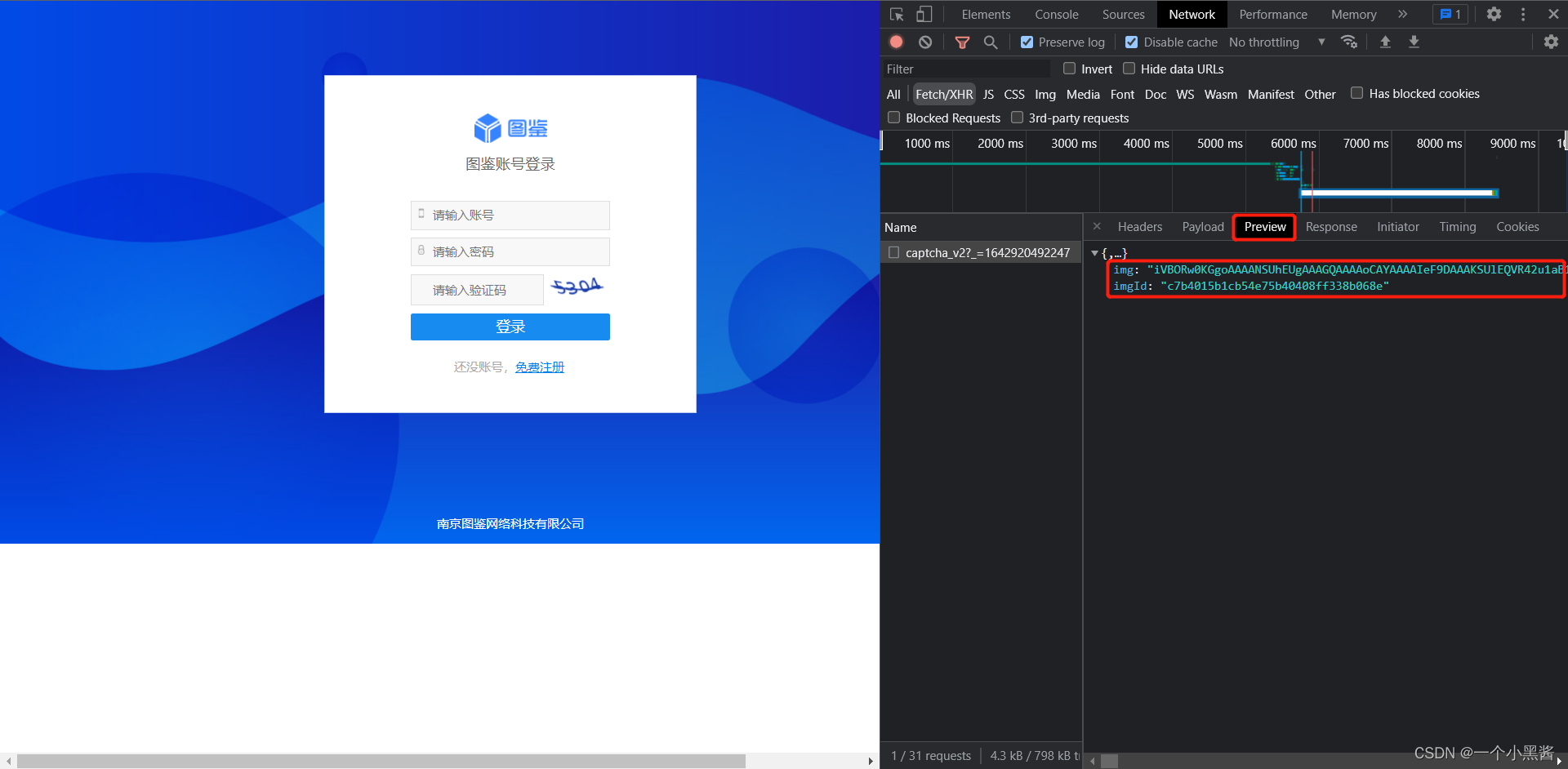
因此使用 requests+图鉴 登录图鉴网站的步骤是:
- 使用
GET请求 获取到验证码图片信息,http://admin.ttshitu.com/captcha_v2
- 把验证码发送给图鉴,获得识别结果
- 把识别结果和
imgId 填入 POST请求 参数中,并登录,http://admin.ttshitu.com/common/api/login/user
"""
1. 使用GET请求获取到验证码图片信息,http://admin.ttshitu.com/captcha_v2
2. 把验证码发送给图鉴,获得识别结果
3. 把识别结果和imgId填入POST请求参数中,并登录,http://admin.ttshitu.com/common/api/login/user
"""
import requests
import json
def base64_api(uname, pwd, img, typeid):
data = {"username": uname, "password": pwd, "typeid": typeid, "image": img}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
def login():
# 请求到图片的地址,提取到图片的b64以及图片的imgId
verify_url = "http://admin.ttshitu.com/captcha_v2"
session = requests.session()
resp = session.get(verify_url)
img = resp.json()
result = base64_api(uname='q6035945', pwd='q6035945', img=img['img'], typeid=3)
data = {
"captcha": result, # 验证码
"imgId": img['imgId'], # 通过抓包获取imgId
"developerFlag": False,
"needCheck": True,
"password": "xxxxxx",
"userName": "xxxxxx",
}
login_url = "http://admin.ttshitu.com/common/api/login/user" # 登录url
resp = session.post(login_url, json=data) # 这里不是data=data,是json=data
print(resp.text)
if __name__ == "__main__":
login()
3. selenium如何获取cookies
from selenium.webdriver import Chrome
import requests
web = Chrome()
web.get("http://www.baidu.com")
cookies = web.get_cookies()
print(cookies) # cookies中只有name和value有用
# cookie_dic = {}
# for dic in cookies:
# key = dic['name']
# value = dic['value']
# cookie_dic[key] = value
cookie_dic = {dic['name']: dic['value'] for dic in cookies} # 字典生成式代替上面5行内容
print(cookie_dic)
# 当你已经有了一个字典形式的cookie,可以直接把这个字典作为参数传递个requests
headers = {} # 直接把cookies当成参数传递即可(必须是字典)
requests.get("http://www.baidu.com", headers=headers, cookies=cookie_dic)
二、关于等待
在selenium中有三种等待方案
1. time.sleep()
这个没啥说的,就是干等。不论元素是否加载出来,都要等
2. web.implicitly_wait()
这个比上面那个人性化很多。如果元素加载出来了。就继续,如果没加载出来,此时会等待一段时间。
注意,此设置是全局设置。一次设置后,后面的加载过程都按照这个来。(爬虫用的会多一些)
3. WebDriverWait()
这个比较狠,单独等一个xxxx元素,如果出现了。就过,如果不出现。超时后, 直接报错。
# 显示等待
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By # 提取页面内容的
from selenium.webdriver.support import expected_conditions as EC
ele = WebDriverWait(web, 10, 0.5).until(
EC.presence_of_element_located((By.XPATH, "/html/body/div[5]/div[2]/div[1]/div/div"))
)
三、登录Boss直聘
在复现这个功能的时候,遇到了两个问题:
- 验证按钮的
xpath 是动态加载的,每次都是不一样的,因此在 F12工具 中需要复制 full xpath
- 人机验证的方式有不止点选图片字符一种,还有一种是再点一次,因此验证阶段写了
try 捕获异常
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import time
import requests
import json
# 事件链
from selenium.webdriver.common.action_chains import ActionChains
def base64_api(uname, pwd, img, typeid):
data = {"username": uname, "password": pwd, "typeid": typeid, "image": img}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
web = Chrome()
web.implicitly_wait(3)
web.get("https://login.zhipin.com/?ka=header-login")
web.find_element(By.XPATH, '//*[@id="wrap"]/div[2]/div[3]/div[2]/div[2]').click() # 切换到手机密码登录
web.find_element(By.XPATH, '//*[@id="wrap"]/div[2]/div[1]/div[2]/div[1]/form/div[3]/span[2]/input').send_keys('123456789') # 输入手机号
web.find_element(By.XPATH, '//*[@id="wrap"]/div[2]/div[1]/div[2]/div[1]/form/div[4]/span/input').send_keys('123456789') # 输入密码
web.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[2]/div[1]/form/div[5]/div[1]/div').click() # 点击人机验证按钮
time.sleep(2)
try:
# 常规验证方式,点选图片中的文字
verify_div = web.find_element(By.XPATH, '/html/body/div[5]/div[2]/div[1]/div/div')
verify_div.screenshot('tu.png')
tu = verify_div.screenshot_as_base64
result = base64_api(uname='q6035945', pwd='q6035945', img=tu, typeid=27)
for p in result.split("|"):
x = int(p.split(",")[0])
y = int(p.split(",")[1]) # perform(): 提交事件
ActionChains(web).move_to_element_with_offset(verify_div, xoffset=x, yoffset=y).click().perform()
time.sleep(1)
web.find_element(By.XPATH, '/html/body/div[5]/div[2]/div[1]/div/div/div[3]/a/div').click()
except Exception as e:
# 另一种验证方式,再点一次验证按钮
web.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[2]/div[1]/form/div[5]/div[1]/div/div[1]/div[1]/span').click()
finally:
# 完成验证后点击登录
time.sleep(2)
web.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[2]/div[1]/form/div[6]/button').click()
四、用selenium+lxml完成数据抓取
利用selenium 访问网页获取到网页 html 代码,再利用 lxml 解析得到指定内容。
from selenium.webdriver import Chrome
# 显示等待
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By # 提取页面内容的
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
def get_page_source(url):
web.get(url)
el = WebDriverWait(web, 10, 0.5).until( # until 结束等待的条件
EC.presence_of_element_located((By.XPATH, '/html/body/div[1]/div[3]/div/div[3]/ul/li[1]/div/div[1]/div[1]/div/div[1]/span[1]/a'))
)
page_source = web.page_source
web.quit()
return page_source
def get_job_name(page_source):
tree = etree.HTML(page_source)
job_names = tree.xpath('/html/body/div[1]/div[3]/div/div[3]/ul/li/div/div[1]/div[1]/div/div[1]/span[1]/a/text()')
print(job_names)
if __name__ == "__main__":
web = Chrome()
url = "https://www.zhipin.com/job_detail/?query=python&city=101020100&industry=&position="
page_source = get_page_source(url)
get_job_name(page_source)
五、登录12306
复现这个功能的时候遇到以下问题:12306的验证码功能消失了,代码变简单了
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.common.action_chains import ActionChains
# 如果你的浏览器版本是88以前, 要去执行一段js代码
# web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
# "source": """
# navigator.webdriver = undefined
# Object.defineProperty(navigator, 'webdriver', {
# get: () => undefined
# })
# """
# })
# 88以后的版本用下面的方案
opt = Options()
opt.add_argument("--disable-blink-features=AutomationControlled")
web = Chrome(options=opt)
web.get("https://kyfw.12306.cn/otn/resources/login.html")
web.implicitly_wait(5)
web.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div[1]/input').send_keys("12345678901")
web.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div[2]/input').send_keys("1234567890")
web.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div[4]/a').click()
time.sleep(1)
btn = web.find_element(By.XPATH, '/html/body/div[1]/div[4]/div[2]/div[2]/div/div/div[2]/div/div[1]/span')
ActionChains(web).drag_and_drop_by_offset(btn, xoffset=300, yoffset=0).perform()
# ActionChains(web).click_and_hold().move_by_offset()