一、数据集准备
1.数据加载
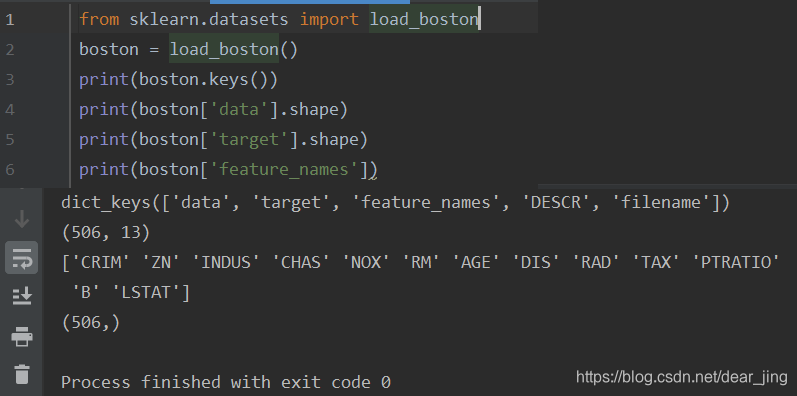
使用波士顿房价数据集(Boston House Price Dataset)下载地址。使用sklearn.datasets.load_boston即可加载
(scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包。sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理)
from sklearn.datasets import load_boston
boston = load_boston()
使用keys()查看字典关键字,其中data是我们要使用的输入数据(506组数据,每组数据有13个属性,13个属性的意义分别对应feature_names的13个值),target是目标值(或叫输出值,是我们要预测的值。506组数据,一组对应一个目标值)。
2.数据预处理
通过print(boston['data'])发现数据的数量级差别很大,为了能让梯度下降速度更快,需要做特征缩放(Feature Scaling)或均值归一化(Mean Normalization),这两个操作都是针对某一属性而不是所有数据的。
| 特征缩放 |
均值归一化 |
| x/max |
(x-mean)/(max-min) |
这里我们使用sklearn MinMaxScaler()函数。
from sklearn.preprocessing import MinMaxScaler
ss_input = MinMaxScaler()
ss_output = MinMaxScaler()
data_set_input = ss_input.fit_transform(boston['data'])
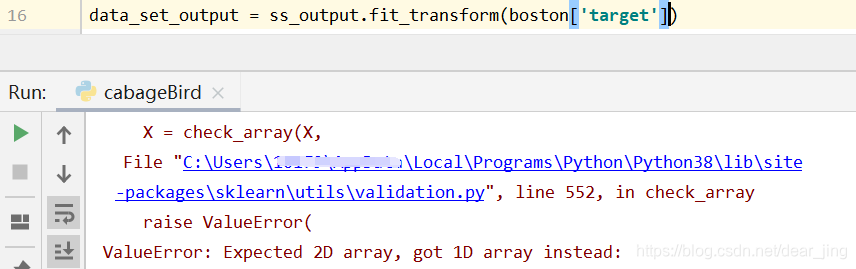
data_set_output = ss_output.fit_transform(boston['target'][:, np.newaxis])
boston['target'][:, np.newaxis]的作用是将一维数组转换为二维数组,不然会出现以下错误:
3.划分训练集、测试集
数据集划分有两种方法:
|
分为2类 |
分为3类 |
| 训练集 Training set |
70% |
60% |
| 交叉验证集 Cross Validation set |
|
20% |
| 测试集 Test set |
30% |
20% |
训练集:用来拟合模型中的参数
交叉验证集:用来选择合适的模型参数。模型中除了一些需要学习的参数,还有一些需要提前人为指定的参数,验证集就是为了选取效果最佳的模型所对应的参数
测试集:用来衡量从交叉验证集中选出的最优模型的性能
简单点,分为两类:
train_set_input = data_set_input[0:350, :]
train_set_output = data_set_output[0:350, :]
test_set_input = data_set_input[351:506, :]
test_set_output = data_set_output[351:506, :]
二、构建网络
构建最简单的网络:全连接,只有三层,输入—>14个神经元的隐藏层—>输出。由于有13个属性,所以输入单元有13个;1层隐藏层,隐藏层单元个数随便选的(隐藏层数量大于1层时,各隐藏层单元数目一般一样)。
激活函数选取: 常用的激活函数有ReLU()、Sigmoid()、Tanh()。
| ReLU |
Sigmoid |
Tanh |
| 使用较多 |
mean=0.5
输出只有正值 |
mean=0
输出有正有负 |
既然ReLU()是使用较多的,那隐藏层激活函数用ReLU();房价只有正值,所以输出层用 Sigmoid()。
from torch import nn
net = nn.Sequential(
nn.Linear(13, 14),
nn.ReLU(),
nn.Linear(14, 1),
nn.Sigmoid()
)
另一种方法:
注意:用这种方法时,需要将predict = net(input)换成predict = net.forward(input)
class net_structure(nn.Module):
def __init__(self,input_num,hidden_num,output_num):
super(net_structure,self).__init__()
self.net = nn.Sequential(
nn.Linear(input_num, hidden_num),
nn.ReLU(),
nn.Linear(hidden_num, output_num),
nn.Sigmoid()
)
def forward(self, input):
return self.net(input)
net = net_structure(13,14,1)
如果网络权重不初始化,pytorch有一套默认初始化机制,使用下面代码查看权重:
print(net.state_dict().keys())
三、定义损失函数和优化器
损失函数就是目标函数cost(在函数里都用loss表示。cost、loss意思一样,目标函数、损失函数、误差函数意思也一样)。nn.MSELoss()函数就是均方损失函数(y-y*)^2
优化器就是根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数值的作用。大家都说RMSprop()最好使,那就用这个。
cost = nn.MSELoss()
optimizer = torch.optim.RMSprop(net.parameters(), lr=0.01)
四、训练网络
网络输入只能是张量,数据集是numpy.ndarray(可以使用train_set_input.type()查看数据类型),需要使用torch.FloatTensor()进行类型转换。
变量声明:
1.max_epoch:迭代次数
2.iter_loss:每次迭代损失函数的平均值
3.batch_loss:一次迭代中所有样本的损失函数的值
梯度下降中,学习速率a乘的是每次迭代所有样本的目标函数cost,关于权重weight的导数,的和sum。因此每次迭代需要将“目标函数cost关于权重weight的导数的和sum”清零。
方法声明:
1.optimizer.zero_grad():清零
2.loss.backward():反向传播求梯度
3.optimizer.step():更新所有参数
4.iter_loss.append(np.average(np.array(batch_loss))):记录本次迭代误差函数的平均值
更详细的解释见:torch代码解析 为什么要使用optimizer.zero_grad()
max_epoch = 300
iter_loss = []
batch_loss = []
for i in range(max_epoch):
for n in range(train_set_input.shape[0]):
input = Variable(torch.FloatTensor(train_set_input[n, :]))
output = Variable(torch.FloatTensor(train_set_output[n, :]))
predict = net(input)
loss = cost(predict, output)
batch_loss.append(loss.data.numpy())
optimizer.zero_grad()
loss.backward()
optimizer.step()
iter_loss.append(np.average(np.array(batch_loss)))
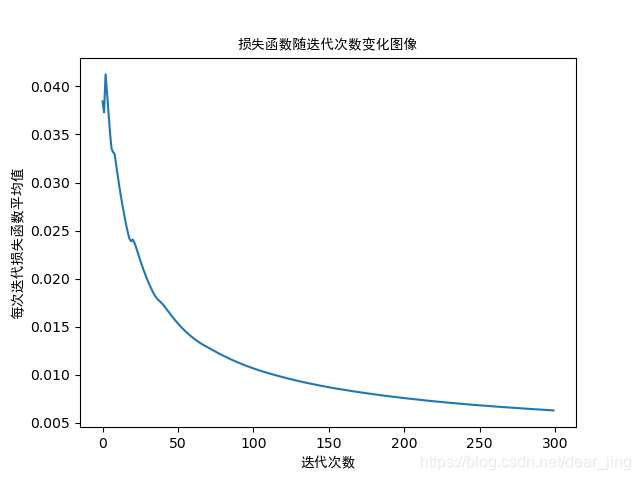
使用以下语句查看损失函数随迭代次数变化的图像:
from matplotlib.font_manager import FontProperties
x = np.arange(max_epoch)
y = np.array(iter_loss)
#为了能显示中文
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf')
plt.plot(x, y)
plt.title('损失函数随迭代次数变化图像', fontproperties=myfont)
plt.xlabel('迭代次数', fontproperties=myfont)
plt.ylabel('每次迭代损失函数平均值', fontproperties=myfont)
plt.show()
五、测试网络效果
predict_ass = []
for i in range(test_set_input.shape[0]):
input = Variable(torch.FloatTensor(test_set_input[i, :]))
predict_ass.append(net(input))
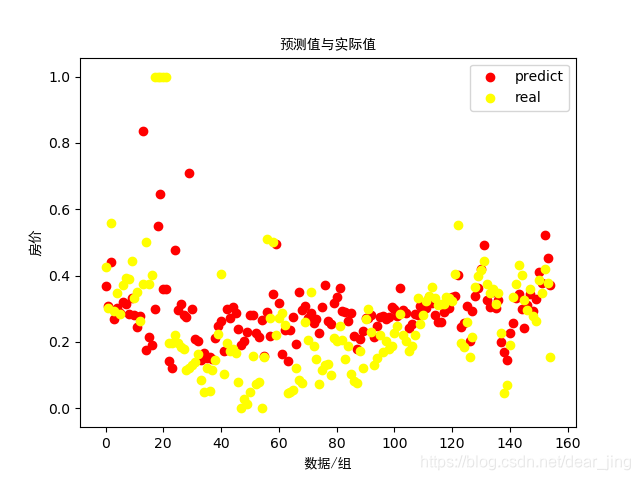
查看预测值和真实值:
x = np.arange(test_set_input.shape[0])
y1 = np.array(predict_ass)
y2 = np.array(test_set_output)
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf')
line1, = plt.plot(x, y1)
line2, = plt.plot(x, y2)
plt.legend([line1, line2], ["predict", "real"], loc=1)
plt.title('预测值与实际值', fontproperties=myfont)
plt.xlabel('数据/组', fontproperties=myfont)
plt.ylabel('房价', fontproperties=myfont)
plt.show()
预测效果不太好。
六、数据分析
1.确定一层隐藏层时,隐藏层单元个数与预测准确度的关系
为了确定隐藏层单元个数与预测准确度的关系,将数据集分为三类:训练集、验证集、测试集,对不同隐藏层单元个数求出训练集和验证集损失函数的值(横坐标为隐藏层单元个数,蓝色线为“训练集损失函数”,红色线为“验证集损失函数”)
当验证集损失函数>训练集损失函数时,说明模型出现过拟合(14个出现隐藏层单元出现了过拟合,可能这也是为什么拟合效果并不好的原因)

选取没有出现过拟合的隐藏层单元个数(以7、8、15、16为例)与14个隐藏层单元对比,发现不同隐藏层单元个数对损失函数的最小值影响没有区别,但7个和16个隐藏层单元预测效果较好。
| 隐藏层单元个数 |
14 |
7 |
8 |
15 |
16 |
| 损失函数 |
 |
 |
 |
 |
 |
| 测试网络效果 |
 |
 |
 |
 |
 |
2.确定两层隐藏层时,隐藏层单元个数与预测准确度的关系
同1,作图(图上横坐标意义是错的!!横坐标为隐藏层单元个数,红色线为“训练集损失函数”,蓝色线为“验证集损失函数”)

选取没有出现过拟合的隐藏层单元个数(4、7、10)与一层隐藏层16个单元对比,发现两层隐藏层损失函数值减小速度快于一层隐藏层,但7个和16个隐藏层单元预测效果较好
| 隐藏层单元个数 |
16 |
4 |
7 |
10 |
| 损失函数 |
 |
 |
 |
 |
| 测试网络效果 |
 |
 |
 |
 |
3.不同损失函数的区别
由于目前还没搞清楚不同损失函数的应用场景的区别,暂时将损失函数按文章《神经网络的损失函数》中提及的回归损失函数和分类损失函数两类分,以后学明白了再来修改。
由于这是一个预测问题,所以涉及到的损失函数有:nn.MSELoss(),nn.L1Loss(),nn.SmoothL1Loss()这三种,MBELoss()函数在PyTorch上没有,因此不做分析。
发现相比于nn.L1Loss(),nn.SmoothL1Loss()和nn.MSELoss()的最小值几乎一样;在达到最小值所用的时间上,nn.MSELoss()更快。

在使用同一个网络验证不同损失函数时,虽然每次使用的是同一个网络,但要定义三次,注意,不是声明三次!!!
附:完整代码
import numpy as np
import torch
from matplotlib.font_manager import FontProperties
from sklearn.datasets import load_boston
from sklearn.preprocessing import MinMaxScaler
from torch import nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
# 1-1 加载数据
boston = load_boston()
# 1-2 数据归一化
ss_input = MinMaxScaler()
ss_output = MinMaxScaler()
data_set_input = ss_input.fit_transform(boston['data'])
data_set_output = ss_output.fit_transform(boston['target'][:, np.newaxis])
# 1-3 划分数据集
train_set_input = data_set_input[0:350, :]
train_set_output = data_set_output[0:350, :]
test_set_input = data_set_input[351:506, :]
test_set_output = data_set_output[351:506, :]
# 2 构建网络
net = nn.Sequential(
nn.Linear(13, 14),
nn.ReLU(),
nn.Linear(14, 1),
nn.Sigmoid(),
)
# 3 定义优化器和损失函数
cost = nn.MSELoss()
optimizer = torch.optim.RMSprop(net.parameters(), lr=0.01)
# 4 训练网络
max_epoch = 300
iter_loss = []
batch_loss = []
for i in range(max_epoch):
optimizer.zero_grad()
for n in range(train_set_input.shape[0]):
input = Variable(torch.FloatTensor(train_set_input[n, :]))
output = Variable(torch.FloatTensor(train_set_output[n, :]))
predict = net(input)
loss = cost(predict, output)
batch_loss.append(loss.data.numpy())
loss.backward()
optimizer.step()
iter_loss.append(np.average(np.array(batch_loss)))
#5 测试网络效果
predict_ass = []
for i in range(test_set_input.shape[0]):
input = Variable(torch.FloatTensor(test_set_input[i, :]))
predict_ass.append(net(input))
# 图1
x = np.arange(max_epoch)
y = np.array(iter_loss)
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf')
plt.plot(x, y)
plt.title('损失函数随迭代次数变化图像', fontproperties=myfont)
plt.xlabel('迭代次数', fontproperties=myfont)
plt.ylabel('每次迭代损失函数平均值', fontproperties=myfont)
plt.show()
#图2
x = np.arange(test_set_input.shape[0])
y1 = np.array(predict_ass)
y2 = np.array(test_set_output)
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf')
line1 = plt.scatter(x, y1, c='red')
line2 = plt.scatter(x, y2, c='yellow')
plt.legend([line1, line2], ["predict", "real"], loc=1)
plt.title('预测值与实际值', fontproperties=myfont)
plt.xlabel('数据/组', fontproperties=myfont)
plt.ylabel('房价', fontproperties=myfont)
plt.show()
#ps 查看权重
print(net.state_dict().keys())
2020.9.5 更新
经过一段时间的学习,发现“附:训练模型、测试模型”中的代码有些地方存在问题:
-
梯度下降和梯度清零的位置
- 数据是逐个计算的,没有充分利用矢量运算的快速性
- 计算复杂
现修改如下:
- 先进行了梯度清零,然后进行梯度下降
- 采用矢量运算的方式,减少代码行数
- 增加了训练误差、测试误差的显示
(仍存在一些问题,如训练误差明显小于测试误差、数据集是否过少、科学方式调参等)
import numpy as np
import torch
from matplotlib.font_manager import FontProperties
from sklearn.datasets import load_boston
from sklearn.preprocessing import MinMaxScaler
from torch import nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
# 1-1 加载数据
boston = load_boston()
# 1-2 数据归一化
ss_input = MinMaxScaler()
ss_output = MinMaxScaler()
data_set_input = ss_input.fit_transform(boston['data'])
data_set_output = ss_output.fit_transform(boston['target'][:, np.newaxis])
# 1-3 划分数据集
train_set_input = data_set_input[0:350, :]
train_set_output = data_set_output[0:350, :]
test_set_input = data_set_input[351:506, :]
test_set_output = data_set_output[351:506, :]
# 2 构建网络
net = nn.Sequential(
nn.Linear(13, 14),
nn.ReLU(),
nn.Linear(14, 1),
nn.Sigmoid(),
)
# 3 定义优化器和损失函数
loss = nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
# 4 训练网络
max_epoch = 3000
l_arr = []
for i in range(max_epoch):
predict = net(torch.FloatTensor(train_set_input))
l = loss(torch.FloatTensor(train_set_output), predict)
optimizer.zero_grad()
l.backward()
optimizer.step()
l_arr.append(l.item())
#5 测试网络效果
predict = net(torch.FloatTensor(test_set_input))
test_loss = loss(torch.FloatTensor(test_set_output), predict)
print('train_loss:%.6f , test_loss:%.6f' % (torch.FloatTensor(l_arr).mean(), test_loss))
# 图1
x = np.arange(max_epoch)
y = np.array(l_arr)
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf')
plt.plot(x, y)
plt.title('损失函数随迭代次数变化图像', fontproperties=myfont)
plt.xlabel('迭代次数', fontproperties=myfont)
plt.ylabel('每次迭代损失函数平均值', fontproperties=myfont)
plt.show()
#图2
x = np.arange(test_set_input.shape[0])
y1 = np.array(predict.detach().numpy())
y2 = np.array(test_set_output)
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf')
line1 = plt.scatter(x, y1, c='red')
line2 = plt.scatter(x, y2, c='yellow')
plt.legend([line1, line2], ["predict", "real"], loc=1)
plt.title('预测值与实际值', fontproperties=myfont)
plt.xlabel('数据/组', fontproperties=myfont)
plt.ylabel('房价', fontproperties=myfont)
plt.show()
#ps 查看权重
for param in net.parameters():
print(param.shape)
print(param.data)
# train_loss:0.006195 , test_loss:0.024815

