-
(第1题)
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à 选择“系统聚类” à 拖国别至个案标注依据à 其余拖入变量框à点击“图” à勾选“谱系图”à 点击“继续”和“确定” 运行结果: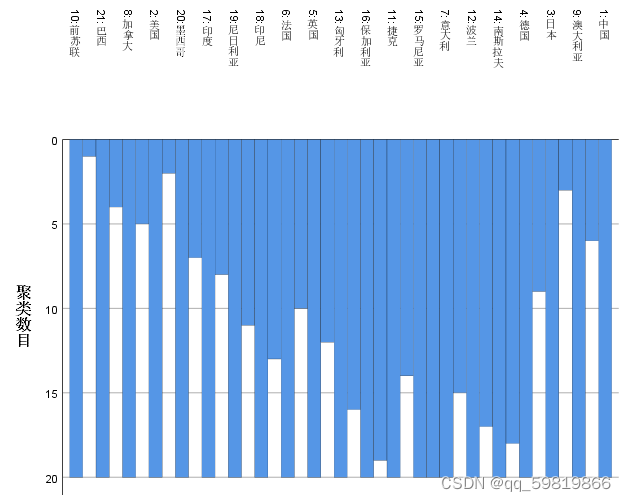 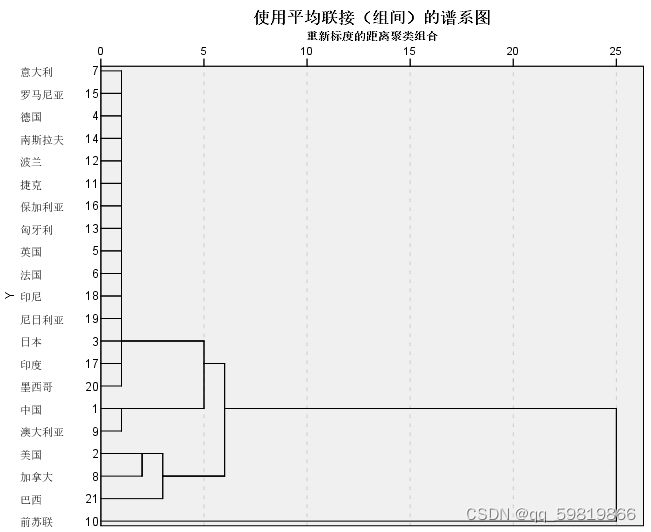
结果分析: 对于冰柱图,自下而上的观察进行分类,美国和墨西哥之间的冰柱对应的分类数是三,所以分类为{前苏联},{美国,加拿大,巴西}其余为一类。 对于谱系图分成三类则为{前苏联},{美国,加拿大,巴西}其余的为一类。 聚类分析就是按照相似性把对象进行分类的方法。
-
(第2题样本间用欧氏距离,并用系统聚类的2个方法对样本进行聚类)
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à 选择“系统聚类” à 拖国别至个案标注依据à 其余拖入变量框à点击“图” à勾选“谱系图”à点击“方法” à将聚类方法修改为“最近邻矩阵”或者“最远邻矩阵”à将区间框改为欧氏距离 à点击“继续”和“确定” 运行结果: 
结果分析:略
-
(第2题对五个变量进行聚类)
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à 选择“系统聚类” à 拖国别至个案标注依据, 其余拖入变量框à 将聚类改为变量à点击“图” à勾选“谱系图”à 点击“继续”和“确定” 运行结果: 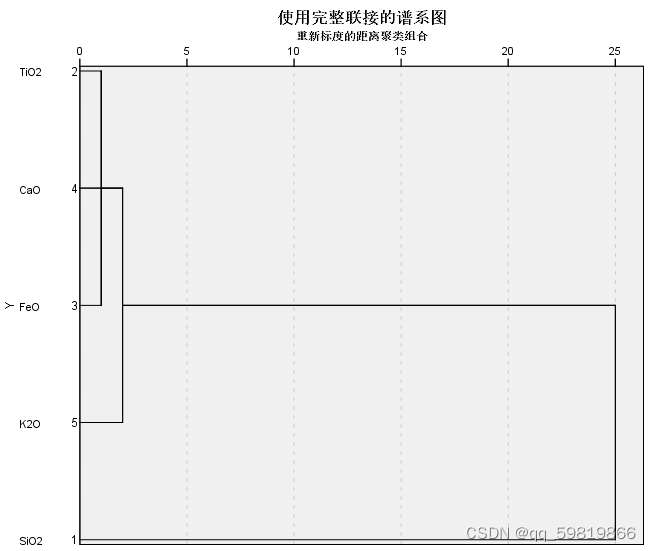
结果分析:略
-
(第1题)
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“分类” à选择“描述统计”并选择“描述” à 勾选“将标准化值另存为变量”à点击“确定” 选择“K-均值聚类” à 拖国别至个案标注依据à 标准化的数据拖入变量框à将聚类数改为3 à点击“选项”勾选统计框所有选项à 点击“继续”和“确定” 运行结果:
| ANOVA |
| |
聚类 |
误差 |
F |
显著性 |
| 均方 |
自由度 |
均方 |
自由度 |
| Zscore(森林面积(万公顷)) |
6.182 |
2 |
.424 |
18 |
14.570 |
.000 |
| Zscore(森林覆盖率) |
4.003 |
2 |
.666 |
18 |
6.006 |
.010 |
| Zscore(林木蓄积量(亿立方米)) |
8.534 |
2 |
.163 |
18 |
52.378 |
.000 |
| Zscore(草原面积(万公顷)) |
3.667 |
2 |
.704 |
18 |
5.212 |
.016 |
| 聚类成员 |
| 个案号 |
国别 |
聚类 |
距离 |
| 1 |
中国 |
1 |
1.456 |
| 2 |
美国 |
1 |
1.608 |
| 3 |
日本 |
2 |
1.325 |
| 4 |
德国 |
2 |
.842 |
| 5 |
英国 |
1 |
1.032 |
| 6 |
法国 |
2 |
.906 |
| 7 |
意大利 |
1 |
.944 |
| 8 |
加拿大 |
2 |
1.359 |
| 9 |
澳大利亚 |
1 |
2.355 |
| 10 |
前苏联 |
3 |
.000 |
| 11 |
捷克 |
2 |
.576 |
| 12 |
波兰 |
2 |
.877 |
| 13 |
匈牙利 |
1 |
.967 |
| 14 |
南斯拉夫 |
2 |
.534 |
| 15 |
罗马尼亚 |
2 |
.931 |
| 16 |
保加利亚 |
2 |
.627 |
| 17 |
印度 |
1 |
.826 |
| 18 |
印尼 |
2 |
2.172 |
| 19 |
尼日利亚 |
1 |
.829 |
| 20 |
墨西哥 |
1 |
.504 |
| 21 |
巴西 |
2 |
2.823 |
结果分析: 由方差分析表的p值可以判断出几个变量对分类的都是显著的,最后可以通过表可以知道三类则为{前苏联},{美国,加拿大,巴西}其余的为一类。
-
(第3题)
操作步骤: 打开spss软件,输入相关数据 à 在“变量视图”更改名称 à 点击“分析”à 点击“判别式” à 将分组变量拖入框中并且点击选择范围1到3 à 拖其余名称至自变量à 点击“统计”并勾选“费歇尔” à在“分类”中点击“合并组”和“个案结果” à勾选“谱系图”à 点击“继续”和“确定”其余拖入变量框à点击“图” à勾选“谱系图”à 点击“继续”和“确定” 运行结果: 
| 分类结果a,c |
| |
|
G |
预测组成员信息 |
总计 |
| |
|
高端 |
中端 |
低端 |
| 原始 |
计数 |
高端 |
5 |
0 |
0 |
5 |
| 中端 |
1 |
6 |
1 |
8 |
| 低端 |
0 |
0 |
7 |
7 |
| 未分组个案 |
0 |
1 |
0 |
1 |
| % |
高端 |
100.0 |
.0 |
.0 |
100.0 |
| 中端 |
12.5 |
75.0 |
12.5 |
100.0 |
| 低端 |
.0 |
.0 |
100.0 |
100.0 |
| 未分组个案 |
.0 |
100.0 |
.0 |
100.0 |
| 交叉验证b |
计数 |
高端 |
3 |
2 |
0 |
5 |
| 中端 |
1 |
4 |
3 |
8 |
| 低端 |
0 |
0 |
7 |
7 |
| % |
高端 |
60.0 |
40.0 |
.0 |
100.0 |
| 中端 |
12.5 |
50.0 |
37.5 |
100.0 |
| 低端 |
.0 |
.0 |
100.0 |
100.0 |
| a. 正确地对 90.0% 个原始已分组个案进行了分类。 |
| b. 仅针对分析中的个案进行交叉验证。在交叉验证中,每个个案都由那些从该个案以外的所有个案派生的函数进行分类。 |
| c. 正确地对 70.0% 个进行了交叉验证的已分组个案进行了分类。 |
| 分类函数系数 |
| |
G |
| 高端 |
中端 |
低端 |
| Q |
13.022 |
11.004 |
9.279 |
| C |
4.367 |
3.886 |
2.115 |
| P |
-.334 |
-.136 |
-.165 |
| (常量) |
-60.635 |
-52.853 |
-29.854 |
结果分析: 由第一个图可知,判定没有分组的数据为中端产品,即橙色的小圆圈离中端质心最近。 由第二个图可知,判别分析的正确率为百分之九十 由第三个图可知高端,中端,低端产品的分类函数分别为: Y1=13.022x1+4.367x2-0.332x3-60.635 Y2=11.004x1+3.886x2-0.136x3-52.853 Y3=9.279x1+2.115x2-0.165x3-29.854 代入数据Q,C,P分别为x1,x2,x3得到y2的绝对值最小,所以判别未知电视为中端产品 |