转载 : https://zhuanlan.zhihu.com/p/98756147
原文:What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? (NIPS 2017)
深度学习模型给出的预测结果并不总是可靠的。在无人驾驶等安全性要求较高的领域中,完全依赖深度模型进行决策有可能导致灾难性的后果。如果能够让深度学习模型对于错误的预测给出一个较高的不确定性,我们就能判断一个预测结果可信程度。因此,我们需要对不确定性进行建模。
衡量不确定性最直观的方法就是方差。对于一组数据 ,其方差的计算公式如下:
,其方差的计算公式如下:
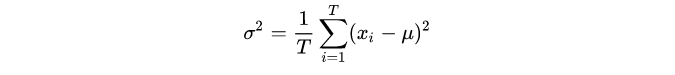
一个单独输出值是得不到方差的。如果说我们能够用同一个模型,对同一个样本进行T次预测,而且这T次的预测值各不相同,就能够计算方差。问题是同一个模型同一个样本,怎么得到不同的输出呢?概率学家就说了,我们让学到的模型参数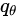 不是确定的值,而是一个分布,那么就可以从这个分布中采样,每一次采样,得到的weight都是不同的,这样结果也是不同的,目的就达到了。
不是确定的值,而是一个分布,那么就可以从这个分布中采样,每一次采样,得到的weight都是不同的,这样结果也是不同的,目的就达到了。
但是,怎么学习这样的分布呢?概率学家又说了,有现成的呀,dropout就是。使用了dropout来训练DNN时,模型的参数可以看成是服从一个伯努利分布。在预测的时候,仍然将dropout打开,预测T次,均值就是最终的预测值,而方差就是不确定度。这样就得到深度学习的不确定度了。这种方法也被称为MC Dropout贝叶斯神经网络。
但是,不确定性有两种。一种称之为偶然不确定性(Aleatoric Uncertainty),是由于观测数据中的固有噪声导致的。这种不确定性是无法被消除的。另外一种称之为感知不确定性(Epistemic Uncertainty),与模型相关,是由于训练不完全导致的。如果给它更多的训练数据来弥补现有模型知识上的不足,这种不确定性从理论上来说是可以消除的。MC Dropout只能得到关于模型的感知不确定性,而不能捕获数据的偶然不确定性,这是有问题的。这就是本文要解决的问题了。
贝叶斯神经网络
假定模型参数服从一个高斯先验分布: 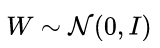 。给定观测数据集
。给定观测数据集 ![[公式]](https://img-blog.csdnimg.cn/20210301203406966.png) 时,可以使用贝叶斯推断来计算模型参数的后验分布
时,可以使用贝叶斯推断来计算模型参数的后验分布 ![[公式]](https://img-blog.csdnimg.cn/20210301203417894.png) 。对于回归任务,通常假定似然是一个高斯分布:
。对于回归任务,通常假定似然是一个高斯分布:![[公式]](https://img-blog.csdnimg.cn/20210301203433644.png) 。其中,
。其中, ![[公式]](https://img-blog.csdnimg.cn/20210301203445613.png) 为模型的输出,
为模型的输出, ![[公式]](https://img-blog.csdnimg.cn/20210301203454405.png) 为噪声项。而对于分类任务,则经常对输出进行归一化,用softmax对其进行压缩处理:
为噪声项。而对于分类任务,则经常对输出进行归一化,用softmax对其进行压缩处理: ![[公式]](https://img-blog.csdnimg.cn/202103012035033.png)
贝叶斯神经网络虽然很好定义,但是实际操作起来比较困难。主要原因在于边际分布 ![[公式]](https://img-blog.csdnimg.cn/202103012035328.png) 没法算。而这一项又是贝叶斯推断所必需的。因此只能通过近似的方法来逼近真实的参数分布。
没法算。而这一项又是贝叶斯推断所必需的。因此只能通过近似的方法来逼近真实的参数分布。
贝叶斯推断公式:
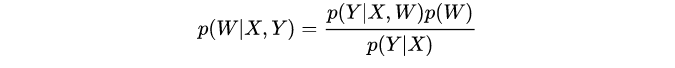
Dropout变分推断是一种常用的近似方法。这种方法在除了在训练时要使用dropout之外,在预测时,也要将dropout打开,执行T次预测取其平均值。理论证明这种方法等价于在最小化KL散度。
利用Dropout进行训练时,其最小化目标为
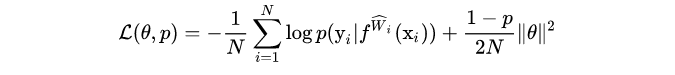
其中,第一项为负对数似然,第二项为正则化参数。p 为dropout中的随机失活率。 ![[公式]](https://img-blog.csdnimg.cn/20210301203712197.png) 。N为数据点个数。
。N为数据点个数。
在回归任务中,通常假设似然是一个高斯分布,那么负对数似然可以写为如下形式:
![[公式]](https://img-blog.csdnimg.cn/20210301203726530.png)
![[公式]](https://img-blog.csdnimg.cn/20210301203803709.png) 表示模型输出值的噪声,一定意义上衡量了输出的不确定程度。
表示模型输出值的噪声,一定意义上衡量了输出的不确定程度。
感知不确定性
感知不确定性是关于模型参数的。为了捕获这个不确定性,我们可以从模型参数的分布中采样多次,得到T 个模型,用这T个模型对同一个样本做预测,看看 T次的预测结果有多么的不稳定。
对于分类问题,T次预测的概率为:
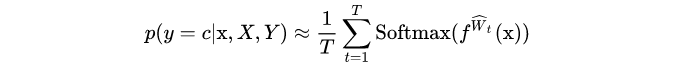
其中,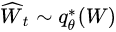 。不确定性可以用熵来衡量:
。不确定性可以用熵来衡量: ![[公式]](https://img-blog.csdnimg.cn/20210301203934254.png)
。
对于回归问题,不确定性可以用输出值的方差来表示: ![[公式]](https://img-blog.csdnimg.cn/20210301203942914.png)
其中, ![[公式]](https://img-blog.csdnimg.cn/2021030120395158.png) 表示输出的均值。
表示输出的均值。
偶然不确定性
偶然不确定性衡量的是数据本身存在的噪声,某种程度上衡量了一个instance的预测难度,因此可以将它看作是instance的一个函数:对于预测结果比较离谱的instance,这个函数值应该比较大;而对于容易预测的instance,相应的函数值应该较小。可以用以下的损失函数来对其进行建模,
![[公式]](https://img-blog.csdnimg.cn/202103012040417.png)
![[公式]](https://img-blog.csdnimg.cn/20210301204048322.png) 即表示Xi偶然不确定性。这里没有对模型参数执行变分推断,而是用了MAP,只能得到一组单一的模型参数值而不是一个分布,因而也无法捕获模型参数的感知不确定性。由此而实现了两种不确定性的分离。
即表示Xi偶然不确定性。这里没有对模型参数执行变分推断,而是用了MAP,只能得到一组单一的模型参数值而不是一个分布,因而也无法捕获模型参数的感知不确定性。由此而实现了两种不确定性的分离。
简单来说,感知不确定性是用多次预测结果的方差来决定的,在多次预测中,所用的模型参数都是不一样的,因此这种做法捕获了模型参数的感知不确定性。而偶然不确定性是由样本的特征决定的,和模型参数是无关的。
将两种不确定性结合
回归任务
为了将两种不确定性结合到同一个模型中,我们需要两组输出:一组是最终的预测结果 ![[公式]](https://img-blog.csdnimg.cn/20210301204523653.png) ,另一组是样本的偶然不确定性
,另一组是样本的偶然不确定性 ![[公式]](https://img-blog.csdnimg.cn/20210301204531657.png) 。即
。即
![[公式]](https://img-blog.csdnimg.cn/20210301204538575.png)
通过最小化以下的损失函数来训练模型:
![[公式]](https://img-blog.csdnimg.cn/20210301204546464.png)
在论文中的深度回归任务中,D 表示图片X中的像素点数量,i 为像素的索引。上面的损失包含了两部分:一部分是回归模型的残差,用于捕获模型参数的感知不确定性;另一部分是像素点的偶然不确定性,充当正则化项。注意到,在学习偶然不确定性时,其实是不需要标记的。
如果一个像素i 很难预测对,为了最小化整个损失, ![[公式]](https://img-blog.csdnimg.cn/20210301204716634.png) 会相应地变大,而
会相应地变大,而 ![[公式]](https://img-blog.csdnimg.cn/20210301204730716.png) 又会防止
又会防止 ![[公式]](https://img-blog.csdnimg.cn/20210301204724197.png) 变得无穷大。并不需要
变得无穷大。并不需要 ![[公式]](https://img-blog.csdnimg.cn/20210301204753724.png) 的ground truth。
的ground truth。
实际训练中, ![[公式]](https://img-blog.csdnimg.cn/20210301204812132.png) 其实相当于一项自适应的权重,对于难以预测的样本,数据中存在较多的固有噪声,这项权重比较小;而对于容易预测的样本,数据中存在的固有噪声比较少,这项权重会比较大。这会让模型在训练过程中区别地对待不同的样本。
其实相当于一项自适应的权重,对于难以预测的样本,数据中存在较多的固有噪声,这项权重比较小;而对于容易预测的样本,数据中存在的固有噪声比较少,这项权重会比较大。这会让模型在训练过程中区别地对待不同的样本。
分类任务
在分类任务中,对于一个像素i,模型会输出一个预测向量fi,然后再通过softmax操作得到一组概率Pi。假定预测向量服从一个高斯分布:
![[公式]](https://img-blog.csdnimg.cn/20210301204857512.png)
这里 ![[公式]](https://img-blog.csdnimg.cn/20210301204905807.png) 和
和 ![[公式]](https://img-blog.csdnimg.cn/20210301204912573.png) 是网络参数为 W 时的输出。相当于对向量
是网络参数为 W 时的输出。相当于对向量 ![[公式]](https://img-blog.csdnimg.cn/20210301204925533.png) 施加了一个方差为
施加了一个方差为 ![[公式]](https://img-blog.csdnimg.cn/20210301204935298.png) 的噪声。
的噪声。
训练模型的损失函数可以写为:
![[公式]](https://img-blog.csdnimg.cn/20210301204943528.png)
第二项实则为交叉熵损失函数化简后的结果。
交叉熵损失的简单推导:
假定一共有C个类别,像素i 属于类别c, ![[公式]](https://img-blog.csdnimg.cn/20210301205031889.png) ,那么像素 i 交叉熵损失为
,那么像素 i 交叉熵损失为
![[公式]](https://img-blog.csdnimg.cn/20210301205045192.png)
因为要执行T次预测,因此损失也要取T次的平均,由此得到了公式 (1)。
简单来说,贝叶斯神经网络或者MC Dropout能够捕获感知不确定性,额外添加的 ![[公式]](https://img-blog.csdnimg.cn/20210301204955130.png) 则用来捕获偶然不确定性。
则用来捕获偶然不确定性。