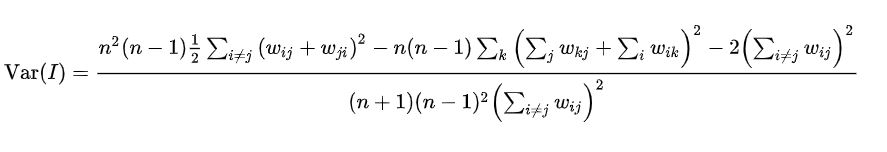在全局相关分析中,最常用的统计量就是Global Moran’I(全局莫兰指数),它主要是用来描述所有的空间单元在整个区域上与周边地区的平均关联程度。计算公式如下:
I
=
n
S
0
×
∑
i
=
1
n
∑
j
=
1
n
w
i
j
(
y
i
−
y
ˉ
)
(
y
j
−
y
ˉ
)
∑
i
=
1
n
(
y
i
−
y
ˉ
)
2
\mathit{I}=\frac{n}{S_{0}} \times \frac{\sum\limits_{i=1}^{n}\sum\limits_{j=1}^{n}{w_{ij}(\mathit{y_{i}}-\bar{\mathit{y}})(\mathit{y_{j}}-\bar{\mathit{y}})}}{\sum\limits_{i=1}^{n}(\mathit{y_{i}}-\bar{\mathit{y}})^{2}}
I=S0n×i=1∑n(yi−yˉ)2i=1∑nj=1∑nwij(yi−yˉ)(yj−yˉ) 其中,
S
0
=
∑
i
=
1
n
∑
j
=
1
n
w
i
j
S_{0}=\sum\limits_{i=1}^{n}\sum\limits_{j=1}^{n}w_{ij}
S0=i=1∑nj=1∑nwij,
n
\mathit{n}
n为空间单元总个数,
y
i
\mathit{y_{i}}
yi和
y
j
\mathit{y_{j}}
yj分别表示第
i
\mathit{i}
i个空间单元和第
j
\mathit{j}
j个空间单元的属性值,
y
ˉ
\bar{y}
yˉ为所有空间单元属性值的均值,
w
i
j
w_{ij}
wij为空间权重值。
对于莫兰指数的取值范围为什么在这个区间,emm,我查阅了很多文献,里面也没有提到。这里仅谈下我自己的理解:因为这个公式与概率论中学习到的相关系数计算公式十分接近的,皮尔逊相关系数计算的公式如下,大家可以对比一下:
r
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
∑
i
=
1
n
(
y
i
−
y
ˉ
)
2
\mathit{r}=\frac{\sum\limits_{i=1}^{n}(\mathit{x_{i}-\bar{x}})(\mathit{y_{i}}-\bar{y})}{\sqrt{\sum\limits_{i=1}^{n}(\mathit{x_{i}-\bar{x}})^{2}\sum\limits_{i=1}^{n}(\mathit{y_{i}-\bar{y}})^{2}}}
r=i=1∑n(xi−xˉ)2i=1∑n(yi−yˉ)2i=1∑n(xi−xˉ)(yi−yˉ)
根据上表,得出该四个区的一阶相邻空间权重矩阵
W
W
W为 根据公式
S
0
=
∑
i
=
1
n
∑
j
=
1
n
w
i
j
S_{0}=\sum\limits_{i=1}^{n}\sum\limits_{j=1}^{n}w_{ij}
S0=i=1∑nj=1∑nwij,此时
n
=
4
n=4
n=4,我们可以先将
S
0
S_{0}
S0求出来。不难看出,
S
0
S_{0}
S0其实就是空间权重矩阵中所有元素的和。在这里,这里我们构造的空间权重矩阵对应的
S
0
S_{0}
S0为10。
为了后续计算方便,令四个区县的属性值为10,20,30,40,分别对应
y
1
,
y
2
,
y
3
,
y
4
y_{1},y_{2},y_{3},y_{4}
y1,y2,y3,y4。则
y
ˉ
=
25
\bar{y}=25
yˉ=25,
∑
i
=
1
4
(
y
i
−
y
ˉ
)
2
=
500
\sum\limits_{i=1}^{4}(\mathit{y_{i}}-\bar{\mathit{y}})^{2}=500
i=1∑4(yi−yˉ)2=500
剩下的计算就只有
∑
i
=
1
4
∑
j
=
1
4
w
i
j
(
y
i
−
y
ˉ
)
(
y
j
−
y
ˉ
)
\sum\limits_{i=1}^{4}\sum\limits_{j=1}^{4}{w_{ij}(\mathit{y_{i}}-\bar{\mathit{y}})(\mathit{y_{j}}-\bar{\mathit{y}})}
i=1∑4j=1∑4wij(yi−yˉ)(yj−yˉ)这一块了。
由于区县自身与自身的空间权重值为0,所以我们只要关注自身与其他区县的相邻情况。考验排列组合的时候到啦,4个区县两两组合,非重复的组合方式共有6(
C
4
2
\mathrm{C}_4^2
C42)种。全部列出来如下所示:
江津区与巴南区、江津区与南川区、江津区与綦江区 巴南区与南川区、巴南区与綦江区、南川区与綦江区
以江津区与巴南区为例,其对应得属性值为
y
1
y_{1}
y1和
y
2
y_{2}
y2,两者相邻故
w
12
=
1
w_{12}=1
w12=1,则
w
12
(
y
1
−
y
ˉ
)
(
y
2
−
y
ˉ
)
=
(
10
−
25
)
(
20
−
25
)
=
75
w_{12}(y_{1}-\bar{y})(y_{2}-\bar{y})=(10-25)(20-25)=75
w12(y1−yˉ)(y2−yˉ)=(10−25)(20−25)=75
由于
W
W
W矩阵是对称的(即
w
i
j
=
w
j
i
w_{ij}=w_{ji}
wij=wji),所以实际上我们在求结果的时候相邻区县只计算一次再乘以2就可以。
从整个计算流程中,我们可知,这个公式之所以能够表示空间单元的相关性,关键还是在于
∑
i
=
1
n
∑
j
=
1
n
w
i
j
(
y
i
−
y
ˉ
)
(
y
j
−
y
ˉ
)
\sum\limits_{i=1}^{n}\sum\limits_{j=1}^{n}{w_{ij}(\mathit{y_{i}}-\bar{\mathit{y}})(\mathit{y_{j}}-\bar{\mathit{y}})}
i=1∑nj=1∑nwij(yi−yˉ)(yj−yˉ)这一步的计算。实质就是:空间单元的邻接权重指数
×
\times
×空间单元间属性值的偏差。前者对应着各地区在空间上的位置关系,后者对应着各地区属性值之间的差异,两者作乘积,再求和,就得到了所有地区在整个空间上的相关性程度。只有当
y
i
y_{i}
yi和
y
j
y_{j}
yj同时大于或者小于
y
ˉ
\bar{y}
yˉ时,莫兰指数才有可能为正;并且当
y
i
y_{i}
yi和
y
j
y_{j}
yj偏离平均值
y
ˉ
\bar{y}
yˉ越大时,莫兰指数的值就越大。
我们联系一下实际情况来深入理解上面这段话的含义。一个教室有很多个座位,一个座位对应一名学生的成绩。
y
i
y_{i}
yi代表
i
i
i座位学生的成绩,
y
j
y_{j}
yj代表
j
j
j座位学生的成绩。
从聚集的角度来看:
1.当
y
i
y_{i}
yi和
y
j
y_{j}
yj都大(小)于
y
ˉ
\bar{y}
yˉ时,即
i
i
i座位和
j
j
j座位的学生成绩都是要高(低)于整个班的平均成绩的,此时如果
i
i
i座位与
j
j
j座位相邻,即计算出莫兰指数一定是大于0的。换个方式来说,当莫兰指数大于0时,表示成绩越高(低)的学生越容易聚集在一起。(类比:学霸总和学霸玩,学渣总和学渣玩,此时成绩在空间上呈正相关性)
2.当
y
i
y_{i}
yi和
y
j
y_{j}
yj其中有一个小于平均水平
y
ˉ
\bar{y}
yˉ时,此时如果
i
i
i座位与
j
j
j座位相邻,即计算出莫兰指数一定是小于0的。换个方式,当莫兰指数小于0时,表示成绩越高(低)越不容易聚集在一起。(类比:有些学霸特别喜欢和学渣一起玩,此时成绩在空间上呈现负相关性)
当区域个数
n
n
n足够大时,莫兰指数近似服从正态分布,因此我们可以使用Z检验(也称U检验)对其进行验证。
Z
=
I
−
E
(
I
)
v
a
r
(
I
)
Z=\frac{I-E(I)}{\sqrt{var(I)}}
Z=var(I)I−E(I)
其均值和方差的计算方法如下所示:
E
(
I
)
=
−
1
n
−
1
E(I)=-\frac{1}{n-1}
E(I)=−n−11 期望与方差推导可参考文献:MORAN P A P. Notes on continuous stochastic phenomena.[J]. Biometrika,1950,37(1-2).有兴趣的小伙伴可以看下。以后,一般对莫兰指数检测直接都是利用软件计算的,故在此不再以例子进行说明。
特别说明:原假设
H
0
H_{0}
H0:所有研究对象在空间上随机分布
在显著性为0.05水平下,只要满足
∣
Z
∣
>
1.96
|Z|>1.96
∣Z∣>1.96(或者P值小于0.05)即可拒绝原假设
H
0
H_{0}
H0,则有充分理由认为莫兰指数显著。(1.96是正态分布的0.975分位数)