一个问题举例
假设有一个5天的收益数据,需要每3天求出一次平均值来达成某个需求:
| date |
revenue |
| 2023-05-01 |
10 |
| 2023-05-02 |
20 |
| 2023-05-03 |
30 |
| 2023-05-04 |
40 |
| 2023-05-05 |
50 |
1号、2号和3号的数据求一次平均值,2号、3号和4号的数据求一次平均值,3号、4号和5号的数据求一次平均值,这样的需求该如何计算?
pandas的Series有一个rolling方法,用来专门解决这种移动窗口聚合运算问题,举个简单的使用例子:
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50])
amount = series.rolling(3).mean()
print(amount)
输出如下
0 NaN
1 NaN
2 20.0
3 30.0
4 40.0
dtype: float64
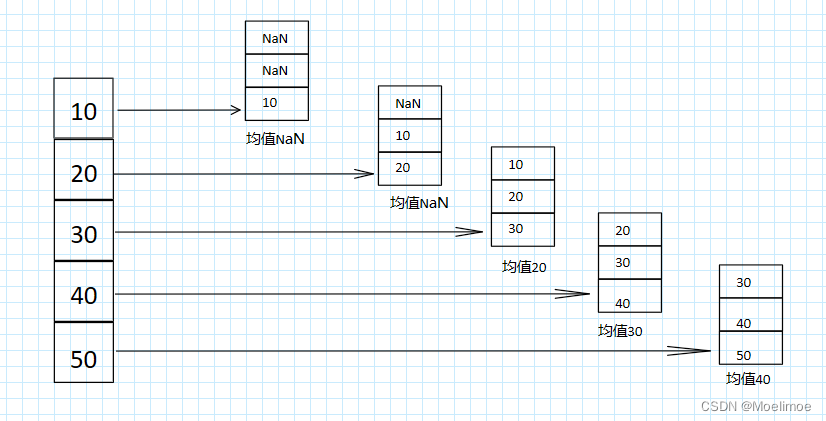
可以看到需求确实如我们所需要的,但是你可能又会说,前两个均值不应该是NaN,少于1天的时候求均值就使用已有天数的数据来计算,别担心,此时只需要指定rolling的参数min_period为1即可:
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50])
amount = series.rolling(3, min_periods=1).mean() # min_period可以指定窗口计算所需要最少的元素,这个值必须小于等于第一个参数窗口的大小3
print(amount)
0 10.0
1 15.0
2 20.0
3 30.0
4 40.0
dtype: float64
结果完美满足需求
然后欠缺考虑周全的产品可能又会跟你说,这里除了求均值,还想给它求个总和,既然都支持求均值了,当然聚合计算都得带上,
rolling方法后面还可以跟上使用求和、最大最小值、均值、方差等常用的聚合方法,除此之外,甚至可以使用agg自定义聚合函数,只要agg返回的值是一个数值:
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50])
amount = series.rolling(3, min_periods=1).agg(lambda x: x.loc[x > 20].sum()) # x就是一个Series,x.loc[x > 20]表示取这个series中大于20的数求和
print(amount)
0 0.0
1 0.0
2 30.0
3 70.0
4 120.0
dtype: float64
rolling方法的进一步介绍
rolling中还有一个center参数,可以指定移动窗口的中心位置作为基准对数据执行计算,center默认为False表示当前数据作为窗口的最后一个数作为基准选取计算的区域,为True的时候将以当前数据作为窗口的中心位置作为基准选取数据执行计算:
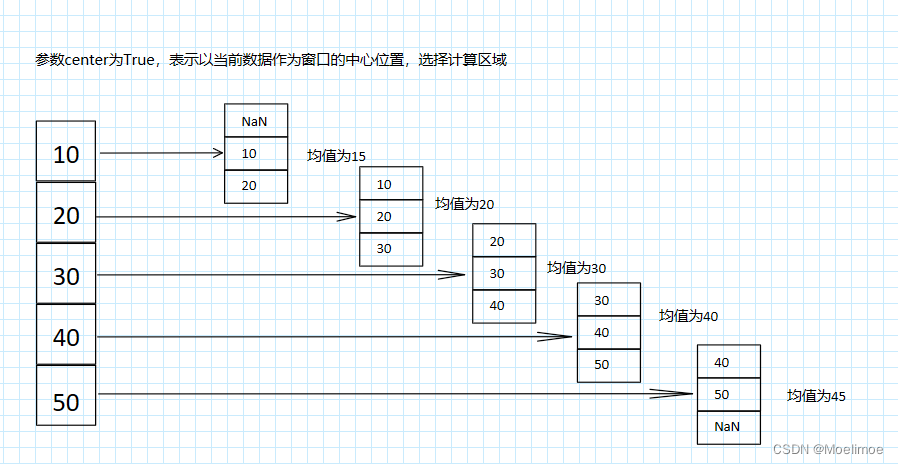
窗口大小是奇数时,如上图一样上下各平分一般窗口计算区域,如果窗口大小是偶数,上半窗口会多多一个数,比如窗口是4,那么上半区域是2个数,下半区域是1个数,加上自身一共4个数
rolling还可以支持对时间段窗口区域进行分析,这十分契合具体的使用场景,例如需求是统计一个在发生某初始化事件(initial)当天往后1天内发生消费(paid)数额超过30的数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(
np.array([
["a", "a", "b", "c", "d", "d"],
[np.nan, 10, 20, 30, np.nan, 50],
]).T,
index=pd.Index(pd.to_datetime(["2023-04-30", "2023-05-01", "2023-05-02", "2023-05-03", "2023-05-04", "2023-05-05"]), name="date"),
columns=["uid", "paid"]
)
print(df)
# uid paid
# date
# 2023-04-30 a NaN
# 2023-05-01 a 10.0
# 2023-05-02 b 30.0
# 2023-05-03 c 60.0
# 2023-05-04 d 50.0
# 2023-05-05 d 80.0
df["paid"] = df["paid"].rolling(
"3D"
).sum()
print(df)
# uid paid
# date
# 2023-04-30 a NaN
# 2023-05-01 a 10.0
# 2023-05-02 b 30.0
# 2023-05-03 c 60.0
# 2023-05-04 d 50.0
# 2023-05-05 d 80.0
df = df.where(lambda x: x["paid"] > 30).dropna().reset_index()
print(df)
# date uid paid
# 0 2023-05-03 c 60.0
# 1 2023-05-04 d 50.0
# 2 2023-05-05 d 80.0
支持指定时间窗口的条件:
index必须是python的时间类型
有关第一个参数的时间字符串表示,可以参考官方的这个链接:https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#offset-aliases
如果想让当前的数据作为窗口的开头怎么使用?
from pandas.api.indexers import FixedForwardWindowIndexer
使用FixedForwardWindowIndexer方法,指定window_size即可,具体使用方法及更多相关的窗口函数方法,可以参考官网给的说明:https://docs.scipy.org/doc/scipy/reference/signal.windows.html#module-scipy.signal.windows
实践中可能会遇到问题
计算的数值中有nan,而且需要把这些nan放到窗口计算中?
很简单,只需要把series中的nan替换成0即可:
import numpy as np
import pandas as pd
series = pd.Series([10, 20, 30, np.nan, 50])
series.replace(np.nan, 0, inplace=True)
amount = series.rolling(3, min_periods=1).mean()
print(amount)
# 输出
# 0 10.000000
# 1 15.000000
# 2 20.000000
# 3 16.666667
# 4 26.666667
# dtype: float64
那如果有一部分的无效数值需要保留,有一部分不需要,该如何处理?
比如,需求是2023-05-01之前的值不能参与计算,且你在一次处理中不能或不方便直接删除掉2023-05-01之前的数据:
import numpy as np
import pandas as pd
series = pd.Series([np.nan, 10, 20, 30, np.nan, 50]).replace(np.nan, 0)
series.index = pd.to_datetime(["2023-04-30", "2023-05-01", "2023-05-02", "2023-05-03", "2023-05-04", "2023-05-05"])
print(series)
# 2023-04-30 0.0
# 2023-05-01 10.0
# 2023-05-02 20.0
# 2023-05-03 30.0
# 2023-05-04 0.0
# 2023-05-05 50.0
# dtype: float64
# 对于不能把2023-05-01之前的数据计算时直接删除时,可以先替换成特殊值
series = series.where(
lambda col:
col.index >= pd.to_datetime("2023-05-01"), "invalid"
) # where第一个参数是给定符合的条件,这一部分数据不会变化,第二个参数是不符合第一个条件的数据会被替换成的值
print(series.loc[series != "invalid"])
# 2023-05-01 10.0
# 2023-05-02 20.0
# 2023-05-03 30.0
# 2023-05-04 0.0
# 2023-05-05 50.0
# dtype: object
# 然后计算时只排除特殊值
amount = series.loc[series != "invalid"].rolling(3, min_periods=1).mean() # rolling的mean方法计算时会尝试把数据转成数值来执行计算
print(amount)
# 2023-05-01 10.000000
# 2023-05-02 15.000000
# 2023-05-03 20.000000
# 2023-05-04 16.666667
# 2023-05-05 26.666667
# dtype: float64