传送门
北京理工大学2022年大三上学期开了一门《汇编语言与接口技术》,本文为系列笔记中的一篇。
为什么要先学计组知识呢,因为汇编是和硬件紧密结合的语言,没有硬件,哪来汇编?所以先学一些硬件非常有助于汇编的学习。
汇编语言笔记——微机结构基础、汇编指令基础
汇编语言笔记——汇编程序开发、汇编大作业
汇编语言笔记——接口技术与编程
北京理工大学汇编语言复习重点(可打印)
计算机系统基础
概述
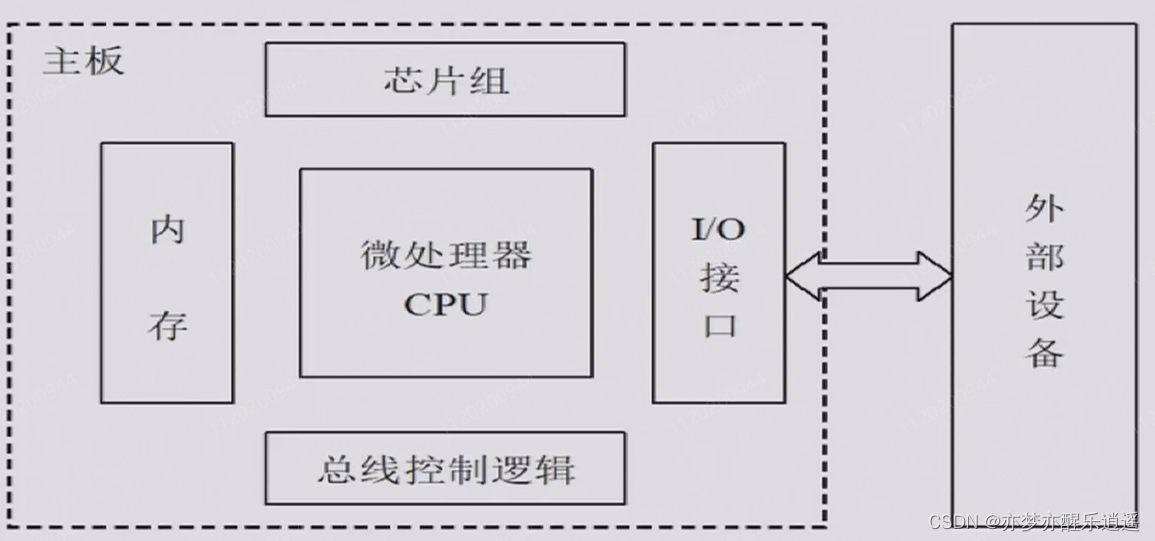
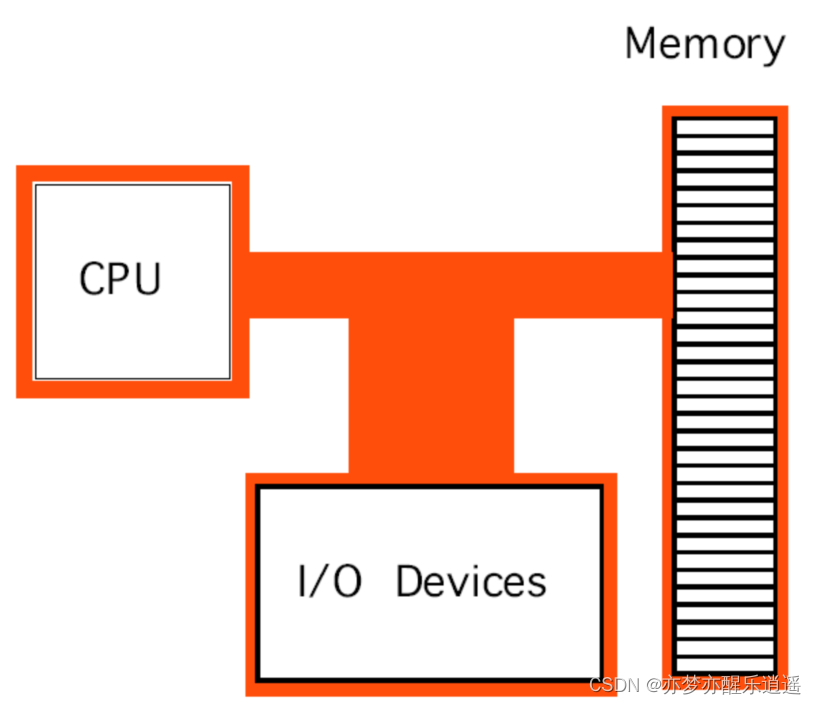
冯诺依曼框架的计算机系统核心在于计算和信息储存分离,具体如下:
- 总的来说,CPU是核心,负责计算,处理内
- 存相当于草稿纸,储存临时用的数据
- 芯片组负责大量辅助功能
- I/O接口负责与外部设备通信
- 而总线则负责连通各种部件。
接下来就对这个框架进行介绍。
微处理器/中央处理器(CPU)
概述

处理器一般有32位和64位,分别使用不同的架构。
从下图可以看出,x86和32位并没有必然关系。
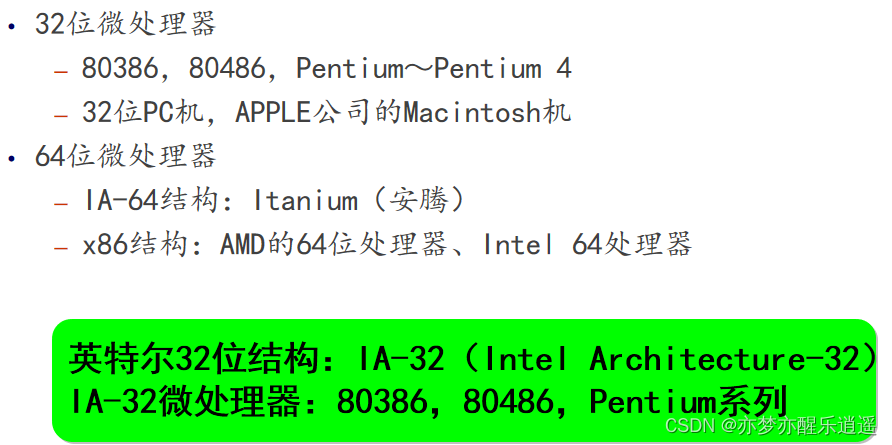
平时说的x86,或者64位处理器,都是通用微处理器。
通用微处理器功能比较多,而专用微处理器可能更多的针对某一类任务,比如单片机(MCU)通常用于控制,数字信号处理器(DSP)用于精确地操控数字信号。

性能指标与总线
- 主频。CPU内部的频率,代表CPU的处理速度。
- 外频。CPU和外部(通常指内存)的通信频率,影响通信速度,如果通信速度太慢,会限制性能。
- 倍频。主频=外频×倍频

前端总线(Front Side Bus)
总线不仅仅是一条,曾经有一种南北桥架构,使用前端总线,连接顺序为:
CPU——总线——前端总线(FSB)——北桥——内存
问题来了,总线和前端总线的区别?
前端总线是总线的一个分支,可以采用一些技术(HT,QPI)把总线频率放大,实现前端总线的加速(比如4倍速)。
带宽
位宽:一次传输的bit位数量
频率:单位时间(秒)内的传输次数
带宽就是信息传输的速度,带宽=位宽×频率
算的时候还要注意bit和byte,一般来说都要÷8把bit变成byte
下图中,FSB频率就是4倍外频。
计算峰值性能=FSB频率×位宽÷8

数据总线DB/地址总线AB/控制总线CB
系统总线具体说,有三种功能的总线。
DB(Data Bus),AB(Address Bus ),CB(Control Bus)
数据总线传输各种数据,一般用位宽衡量,表示一次可以传输的bit位数。
地址总线专门用于传输地址,和寻址操作密切联系。具体说,
寻址空间
=
2
A
B
B
y
t
e
寻址空间=2^{AB} Byte
寻址空间=2ABByte,每一个二进制组合对应一个Byte。如果是20位AB那可寻址空间就是
2
20
=
1
M
B
2^{20}=1MB
220=1MB
如果一台电脑的AB是32位,即可寻址空间为
2
32
=
4
G
B
2^{32}=4GB
232=4GB,但是其内存是16GB的,那么将会有12G的内存被浪费,因为根本找不过去。

CPU软件特性与指令集
CPU有三种工作模式,实模式,保护模式,虚拟实模式,表面上是三种模式,实际上是三种不同的指令执行模式。
CPU的工作内容就是一条一条的指令,自然CPU就有指令集,好比编程语言之于函数库。好的指令集能让CPU工作效率变高。
复杂指令集(CISC)
Complex Instruction Set Computing
复杂指令集的设计理念比较朴素:
- 一个程序中,指令是顺序执行的
- 一条指令中,操作是顺序串行执行的
很显然,这样执行起来简单,且不容易出错,但是运行效率比较低,资源利用率差。
Intel生产的x86和(IA-32架构)和其他CPU,比如AMD,VIA,x86-64都是CISC架构。
典型的CISC技术如下:
- MMX技术。一条指令可以对多条数据操作(SIMD,Single Instruction Multiple Data)。同时增加了针对多媒体的指令。
- SSE技术。是MMX的扩展,指令可以对浮点数操作
- 3DNOW技术。是MMX的扩展,支持浮点数的矢量计算,隶属于AMD,与SSE互不兼容
精简指令集(RISC)
Reduced Instruction Set Computing
对指令集进行简化,目标就是快速,简单,适合流水线操作。
经典的RISC是MIPS
其他技术
- 超线程技术。把一个物理处理器内核虚拟成两个独立的逻辑处理器内核进行并行操作。
- 超标量。同时执行多条指令,物理基础是多个执行硬件,是真正地并行。
- 超长指令字。VIEW技术,用多个相同部件拼接执行超长指令。其衍生出EPIC架构,这是64位架构。
- 动态执行技术。让CPU执行更加智能。
多核CPU
为什么多核?单核发展到了极限。
- 功耗限制
- 互连线延时
- 设计复杂度
多核的物理实现比较简单,就在一个CPU上堆核心就好了,但是其配套的软硬件支持才是难点。
- 并行编程模型。多核之间如何进行并行?
- 片上网络(Networks on Chip,NOC)。总线速度太慢,多核之间如何进行快速通信?
- 存储层次等。
主板
计算机内部的功能组件都是集中在主板上的。
主板最开始是AT标准,后面更新换代,变成了ATX(AT eXtended),后面Intel想更新BTX,但是碍于兼容问题以及更新成本,只能作罢。
接下来就逐一介绍主板上的内容
CPU
略过。
芯片组
芯片组是主板复杂功能的基石,和主板的性能上限密切相关联。
主板控制芯片组
芯片组的核心。控制局部总线、内存和各种扩展卡。
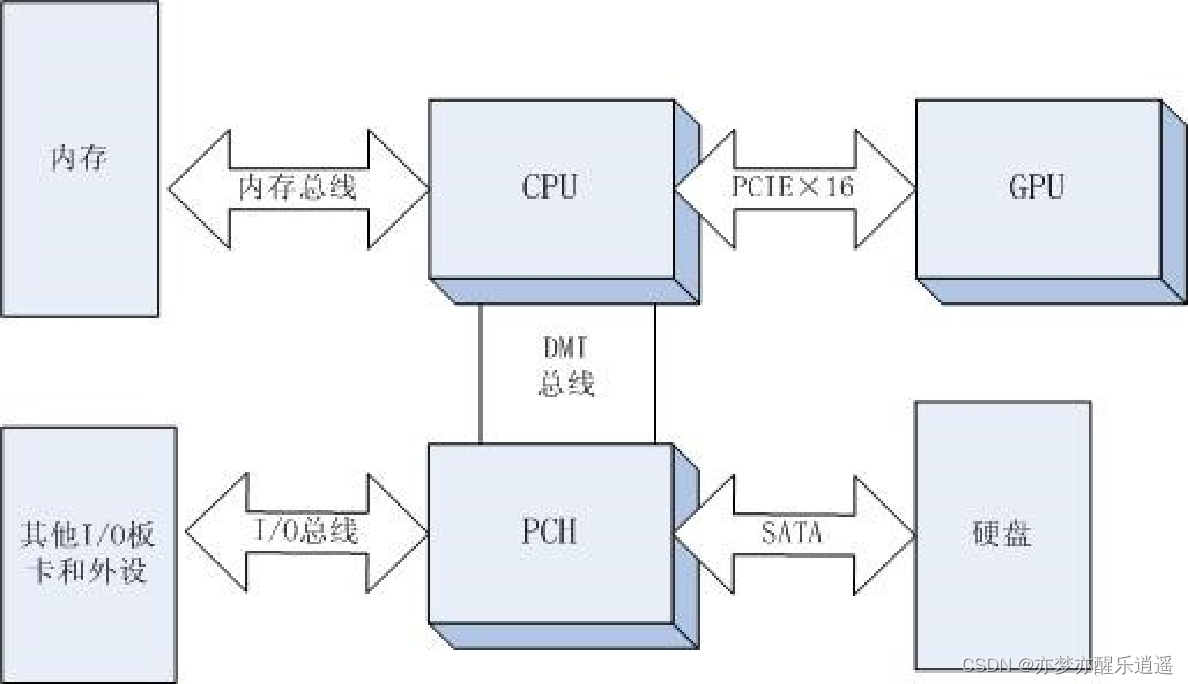
南北桥体系结构

CPU通过前端总线链接北桥芯片(MCH,Memory Control Hub),北桥芯片连接内存和GPU以及南桥芯片(ICH,I/O Control Hub)。北桥芯片负责控制主板内部的空间。
南桥芯片再链接I/O设备和硬盘。
南桥芯片相当于控制连接主板外的空间。

单芯片组体系结构
因为北桥芯片是控制主板内部空间的,所以随着CPU越来越强,北桥芯片的功能被集成到了CPU内去。
微型计算机的体系结构模式变成了CPU+南桥的单芯片组体系结构模式,称平台控制中心PCH(Platform Controller Hub)。
BIOS芯片
BIOS(Basic Input Output System)
BIOS本身是一个固定程序,这些都是很关键的程序。比如开机的时候就会启动BIOS芯片中的程序。
以前的BIOS都是ROM,不可修改,现在是Flash ROM,可以用软件修改。
CMOS芯片
CMOS记录了电脑中的关键信息。
CMOS不是永久储存,所以没电以后信息就没了。
如果需要清除CMOS中的信息,比如忘记了开机密码而无法启动系统等。一般可以通过主板上有专门的跳线来解决这个问题。一般的方法是先关闭电源,把CMOS跳线短接一会儿,然后还原,重新开机即可
多通道内存技术
当CPU和内存之间的通道只有一个,增加再多的内存也不会影响到读写速度。
如果同时增加通道数和内存数,比如2通道2内存,就可以实现并行访问,相当于带宽翻倍。
关于外置适配器
I/O总线与I/O设备之间是要有一个关卡的,这个关卡一般是主板内部的芯片,但是有时候也会是适配器。
适配器是插在主板上的卡,如果你嫌弃主板芯片组不太行,就可以插适配器,相当于扩充芯片组的性能。
但是无论是适配器还是芯片组,负责的都是控制着在I/O总线与I/O设备之间传递信息。
插槽
主板上除了芯片组外,还包括多种跳线、开关、电池、电容、电阻以及各种插槽。主板上的插槽主要包括CPU插槽、内存插槽、扩展槽以及各种I/O接口等。
储存器原理

储存器中储存的数据,从1bit,到字节,字,双字,四字,占据不同大小的储存单元,但是其储存原则相同。
高低的概念
最高位/最低位:在任何储存都适用
MSB,Most Significant Bit, LSB ,Least Significant Bit
高字节/第字节:适用于字。
高字/低字:适用于双字
储存方式
出于效率的考虑,储存的最小单元不是Bit而是Byte,一个Byte对应于一个储存器地址。
地址和内容都是用16进制来表示。
前后缀
可以看到,这个0ED66025H,实际上他是ED66025
前面加0,只是在编程或者交流的时候和变量名做区分,并不会影响到实际储存。
同理,后面加H也只是告诉你是16进制,实际储存不会吧H存进去。
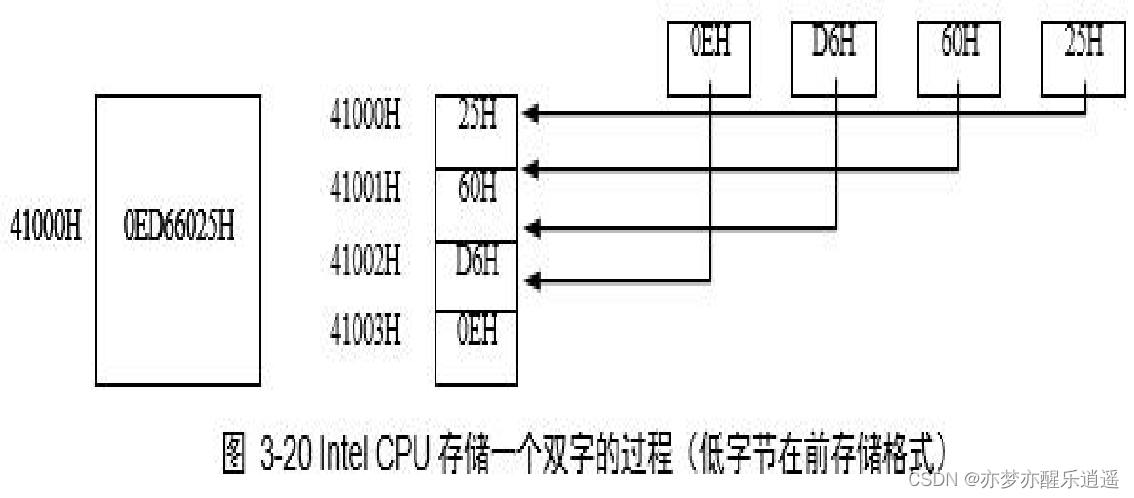
储存顺序
而储存的顺序,Intel采用小端方案,低字节在低地址,高字节在高地址。也就是说,内存中是先读到低字节的。
比如下图,虽然平时在纸上写的时候是先写高字节,但是存的时候以及你读的时候都是先读低字节。
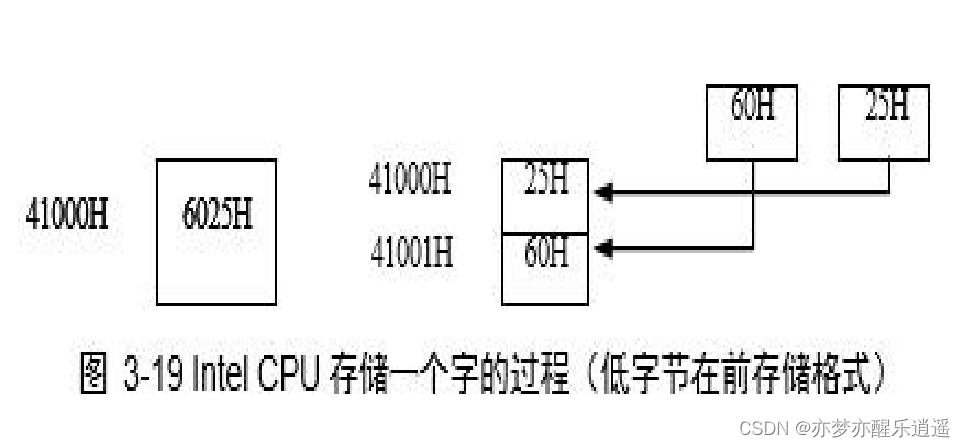
例题
读起来挺别扭,但是记住两个原则:
- 两位16进制=1Byte
- 先找到基地址,然后选定区间,最后倒着读。实际上程序也是这么读的。

中央处理器的发展历史
略
微处理器管理模式
微处理器基本结构
CPU内部也是分单元的。

80386大体分成三部分:总线接口单元(BIU),中央处理单元(CPU),储存器管理单元(MMU)。
由此可见,CPU和处理器并不等同,好比GPU之于显卡,变成了一个通用的混用名词。
具体到结构图,如下。比较复杂,分块解释。
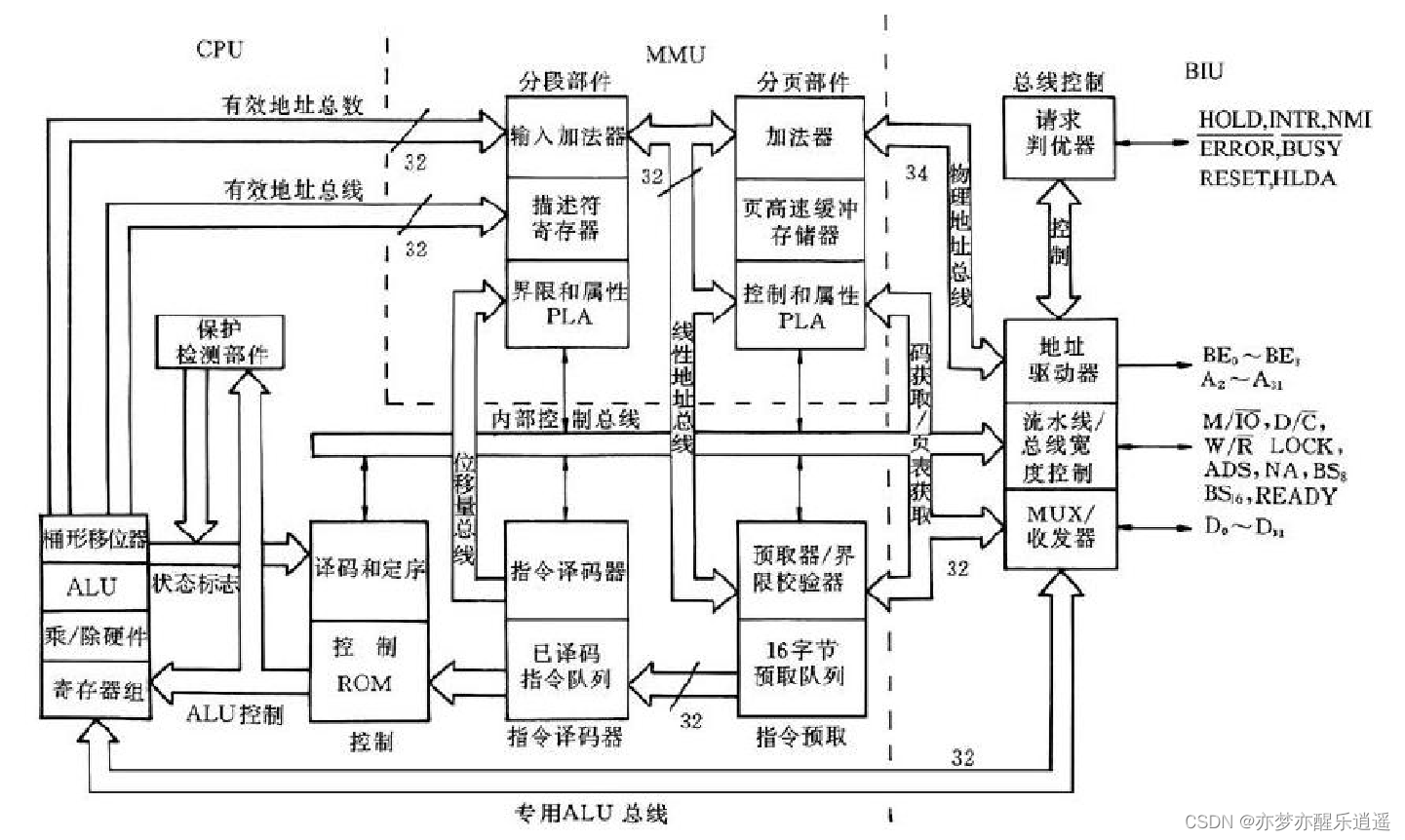
1、总线接口部件(Bus Interface Unit,BIU):
与外部环境联系,包括从存储器中预取指令、读写数据,从I/O端口读写数据,以及其他的控制功能。
2、中央处理部件(Central Process Unit,CPU):
指令部件:完成指令预取和指令译码。
执行部件:执行从已译码指令队列中取出的指令。
3、存储管理部件(MMU):
分段部件:实现段式存储管理。
分页部件:实现保护模式下的分页模型。
CPU工作模式
实模式
这是比较古老的模式了。
两个重大特点:
- 不管实际地址线有多宽,只使用低20位地址线,即寻址空间为1M,很小。
- 内存分区,用内存段首地址+偏移访问。
- 任何区域都可以被访问,分区但不设禁区
- 不支持并行
保护模式
现在最常用的就是保护模式了。
保护模式基本是把实模式的缺点都优化了。
- 使用32位地址线,支持4G内存,PentiumCPU以后扩展到36位,64G内存
- 内存分页+分段
- 提供基于权限的内存保护机制
- 支持并行
- 引入虚拟内存(即用磁盘虚拟出内存来,虽然速度慢,但是可以保证很多大内存程序的运行)
虚拟8086模式(V86模式)
类似于虚拟机。
实际上运行在保护模式上,只是虚拟出一个实模式。你即使把实模式搞坏了,也只是搞坏了我规定出来的区域。
64位模式
现在CPU都是64位的了,主流的就是AMD64以及Intel EM64T和IA-64。
IA-64不兼容32位,市场占用不多。
EM64T基于IA-32,所以可以兼容32位,16位程序。这种兼容本质上是把多出来的位屏蔽,浪费掉了。
EM64T有两个子模式:
- 兼容模式。
- 纯64位模式。最高效,但是需要纯64位操作系统,64位基础应用程序,驱动,且开发出的程序还要进行一些修改以适应64位。
寄存器
寄存器在CPU里,和CPU是同频的,速度最快。
程序设计人员能接触到的都是可见寄存器组。这里说的也都是可见的。
通用寄存器
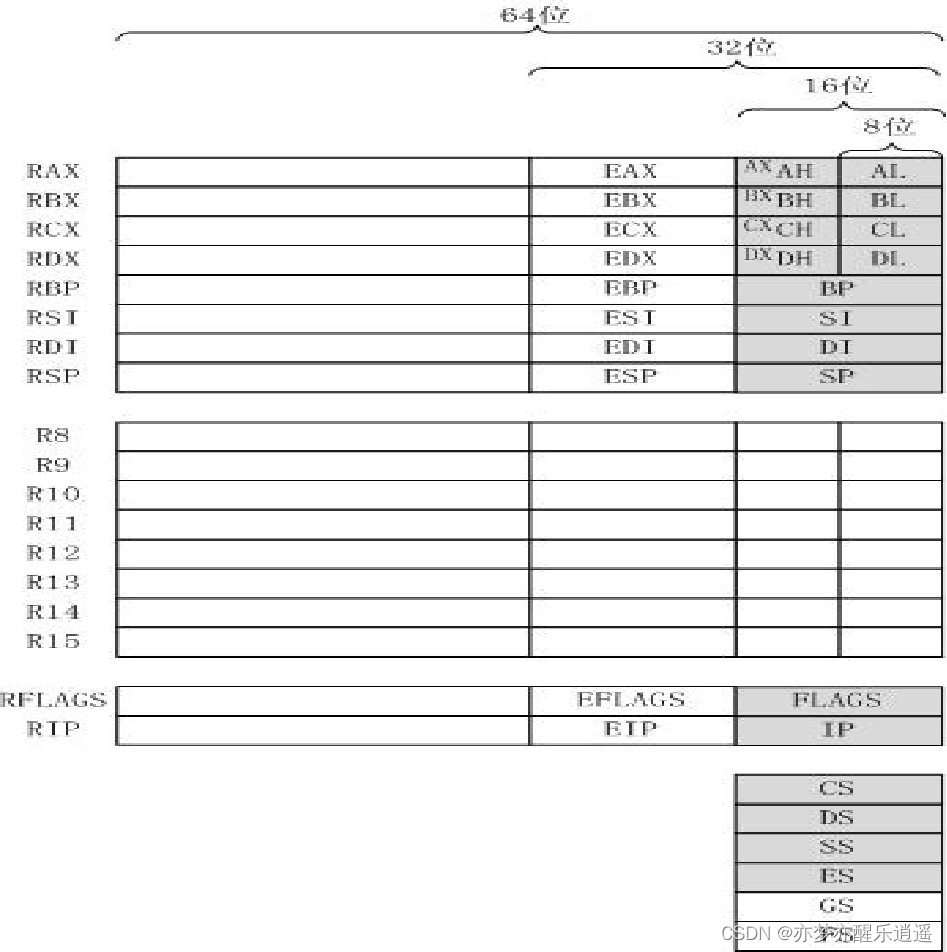
通用指可以传送和暂存数据,参与运算,保存结果。
除此之外,还是有一些特殊功能的。
由此可见,RAX这种R**只是一个总称,比如RAX下面有RAX,EAX,AX,分别对应64,32,16位。而那个X也是总称,继续把这一个字分解为高低字节:AH(High),AL(Low),这两个是8位寄存器。
下面英文我是这么理解的:
- A:Add,加(实际上不止加)
- B:Base,基地址
- C:Counter,计数
- S/D:Destination,代表目标,Start代表起始
- P:这个是结尾,代表pos偏移量,很显然,偏移是不可能有8位的
- I:Instruction,代表和指令相关
比如RSI和RDI,一个是指令的起始位置,一个是指令的最终位置。
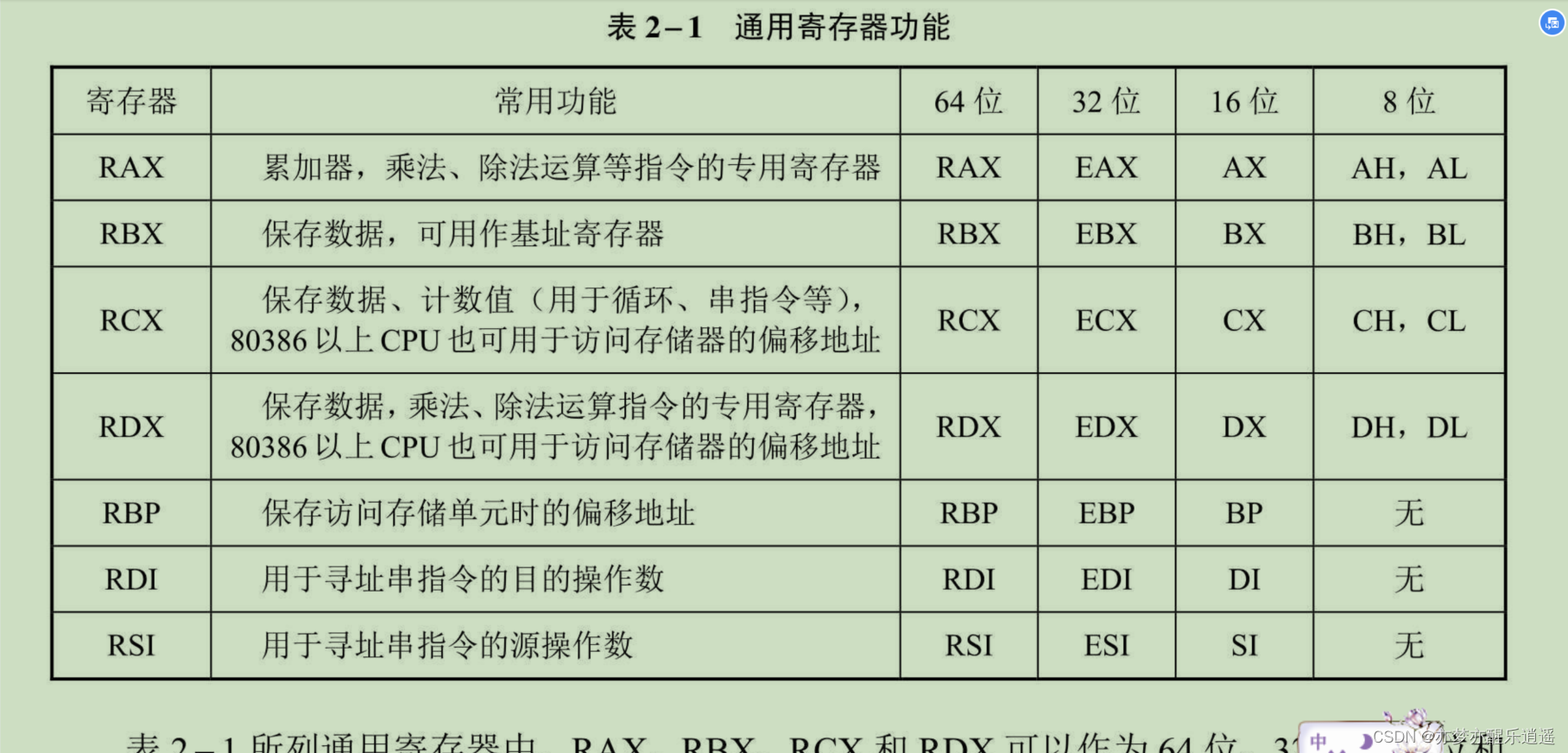
上面的寄存器是一脉相承过来的,而64位系统里又进行了扩展,R8-R15,这些寄存器都是64位的,但是其32,16位版本没有标志符,所以访问的时候要额外加控制字区分。
专用寄存器
指令指针寄存器(IP/EIP/RIP)
指向下一条指令。
根据系统以及模式的不同,三个寄存器中会进行选择性的使用一种。
堆栈指针寄存器(SP/ESP/RSP)
指向栈顶单元。
同样根据系统和模式不同会使用不同的寄存器。
标志寄存器
一个寄存器,但是每一位都有意义。

很多人会迷惑,这0和1到底怎么记,其实0就是正常情况,1是非正常情况。0是常态,只有发生了特定变化才会变成1。,我个人猜测这种情况和电路本身有关,我将1看做激活态,这个状态是要费电的。
- D0:进位标志CF(Carry Flag),0代表没有进位(正常情况),1代表执行结果进位
- D2:奇偶标志PF(Parity Flag),Intel微处理器采用奇校验。0代表执行结果的低八位中有奇数个1(正常情况)。比如11011010B有5个1,则PF=0
- D6:零标志ZF(Zero Flag),0代表结果非0(正常情况),1代表结果为0
- D7:符号标志SF(Signal Flag),0代表非负(正常情况),1代表结果是负数。D6和D7配合起来可以精确判断结果是正负还是0。
- D10:方向标志DF(Direction Flag),针对字符串操作指令中地址变化方向。0代表增址(正常情况),1代表减址
- D11:溢出标志OF(Overflow Flag),带符号数运算的时候,不溢出为0,溢出为1
- D21:微处理器标识标志ID(Identification),相当于一个CPU指针,使用CPUID指令可以获取CPU信息,常有软件利用CPUID作为机器码,可以用于保护版权,但是虚拟机出现后这种方法就被破解了。
段寄存器与16位CPU的内存寻址
段寄存器都是XS的写法,S代表Segment,表示段。一个段对应内存中的一段空间,段寄存器中存放其基地址。
自从80386开始,增加了GS和FS两个。所以程序可以同时访问6个段。
- CS:Code 代码段寄存器
- DS:Data 数据段寄存器
- SS:Stack 堆栈段寄存器
- ES:Extra 附加数据段寄存器
- GS:
- FS:
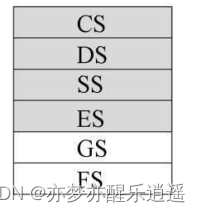
实模式下,段寄存器只有16位(64K),但是其地址总线是20位(最大寻址空间1M),那如何用16位表示20位?
两个16位就可以表示一个20位。
实模式下,段寄存器存放段基址的高16位地址,然后加上第二个16位就行。
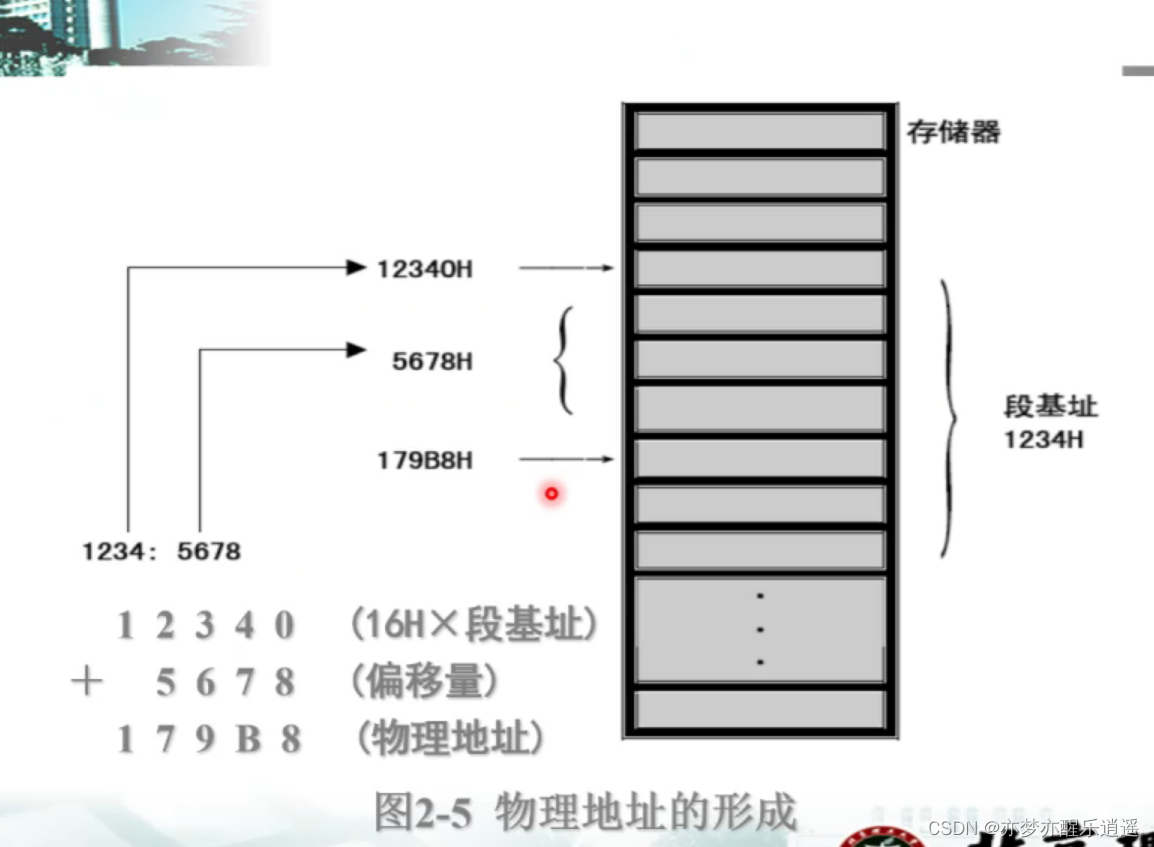
刚开始没有保护模式的时候,用的是16位段寄存器,配合低四位地址构成物理地址
等地址总线拓宽以后,32位CPU出来以后,保护模式也就有了,但是考虑到兼容,16位段寄存器还得保留,但是可以做一些改进,总的来说,就是用另一些结构(GDT,LDT)作为中介,形成间接的段访问。
记住,在保护模式下,段寄存器的目标一直都是在LDT/GDT中选择段描述符。你现在可能不懂,后面如果迷惑了,请回来看一看这句话。
控制寄存器
略
调试寄存器
略
全局描述符表寄存器(GDTR)与段选择符
(Global Descriptor Table Registr)
GDTR伴随着32位CPU以及保护模式而出现。保护模式下,16位段寄存器发挥了另外的作用。
我们从物理内存开始倒着讲,这个顺序和前面比较连贯。
首先是段描述符。
段描述符是一个数据结构,用于向处理器提供有关一个段的位置大小访问控制的信息状态信息。很多全局的信息都是存在GDT中的
段描述符是曾经的16位段寄存器的加强版(但是不是段寄存器,也不是寄存器,只是内存中的数据结构)每个段描述符SD(Segment Descripter)的长度是8个字节,含有3个主要字段:段基地址、段限长、段属性。SD加起来有64位,其中有32位的基地址,也就是说,SD的寻址空间有
2
32
=
4
G
B
2^{32}=4GB
232=4GB,这才符合32位系统的威力。
其次是DT,GDT,LDT。
段描述符存在哪里呢,在DT(Descriptor Table)中,DT可以有很多,根据共有还是私有分为GDT(Global)和LDT(Local)
一个DT最多可以储存
2
13
=
8196
2^{13}=8196
213=8196个段描述符,换算成字节,就是
2
16
B
=
64
K
B
2^{16}B=64KB
216B=64KB的空间,即一个DT最多占用64K的内存空间,用于给内存分段。(GDT只有一个,LDT可以多个)
终于轮到段寄存器了。
在保护模式中,段寄存器又叫段选择子(段选择符)。DT里面储存了对应于4G内存的段信息,但是程序运行的时候,具体要选择哪个段读取成了问题。这个时候,通过段寄存器就可以选择DT中的一个段描述符。理论上,
2
13
2^{13}
213个段描述符,只需要13位Index位就可以描述,那剩下三位肯定是要利用一下。于是,有一位T1位用于区分GDT还是LDT,有两位RPL位用于标示权限(0,1,2,3四级权限)

这里还需要具体说一下如何把段选择子的13位映射到DT中去。因为一个段描述符是8个字节,所以实际选择的时候,段选择子的13位二进制数还要乘以8才行。
最后再说一下GDTR和LDTR。
这两个东西和段寄存器有什么关系?实际上,段寄存器用于选择DT上的一个段描述符,但是DT去哪里找呢?所以,GDTR储存了GDT的基地址,LDTR同理(只不过是间接的)。有人会困惑,为什么只能有
2
13
2^{13}
213个段描述符(64KB),看一眼GDTR的48位都有什么:
有32位的DT基地址,用于找到DT位置,有16位的DT限长,表示DT最大只能有
2
16
2^{16}
216即64KB大,是不是对应前面的空间。
不得不说,这真是一个神奇的巧合,13位的段选择基址+
2
1
3
2^13
213个段描述符+16位的段描述符表限长,刚好匹配

所以,整个寻址模式有如下步骤:
- 寻找GDTR。使用LGDT(Load GDT)指令将GDT的基地址装入GDTR,前32位就是基址,同时后16位还可以确定GDT有多大,可以存多少个段描述符。注意,是后(16位+1)/8个段描述符。之所以要+1,是因为限长为0总得有意义吧,所以就统一加一,这样限长为0代表长度实际是1,最大0xFFFF实际是0x10000,还能凑个二进制整。
- 寻找段描述符。使用段选择子,生成段描述符在GDTR上的偏移量(要×8),用这个偏移量+GDTR基地址就是段描述符基地址。
- 寻找内存段。读取8字节的段描述符,用32位找到内存基地址,搭配其他32位辅助信息使用这块内存。
用这道题举例:
首先注意+1
其次就是16进制除法,建议变成二进制
2
1
0
2
3
=
2
7
=
80
H
\dfrac{2^10}{2^3}=2^7=80H
23210=27=80H。

GDTR是唯一的,但是位置不固定,所以才有地址指向,LGDT命令需要在进入保护模式前就运行,进入以后GDT的位置就不能变了,这也是LGDT必须在进入保护模式前执行的原因。
局部描述符表寄存器(LDTR)
GDTR给全局使用,LDTR,每一个任务运行时,都有自己的值存在LDTR中。可见LDT的数量远大于GDT,所以LDTR中并不直接储存LDT的基址与大小,与GDTR完全不同。
LDTR是16位,从位数上看像是段寄存器,实际上的使用和段寄存器一样(从GDTR中找描述符)。但是他的宏观目标和GDTR一样:都是寻找一个DT的位置和大小,只不过LDTR是间接寻找,GDTR是直接寻找。
LDTR中也是存了一个段选择符,从GDT中选择LDT描述符(没错,LDT可以说是嵌套在GDT体系中的),获取LDT的基地址和大小等信息。也就是说,相比于GDTR直接锁定一个GDT,LDTR可以通过GDT间接锁定一个LDT。
下图给出了流程:
- GDTR确定了GDT的位置和大小
- 用LDTR作为段选择符,选择GDT中的一个LDT描述符
- 用LDT描述符确定LDT的位置和大小。
- 用段寄存器在LDT中选择内存的描述符(图里没有,我补充的)
- 用LDT中的段描述符寻找物理内存
整个流程比GDTR寻址过程多了两步,这是因为LDTR是以GDT作为跳板间接指定LDT的,前三步合起来实现了这一个宏观目标。
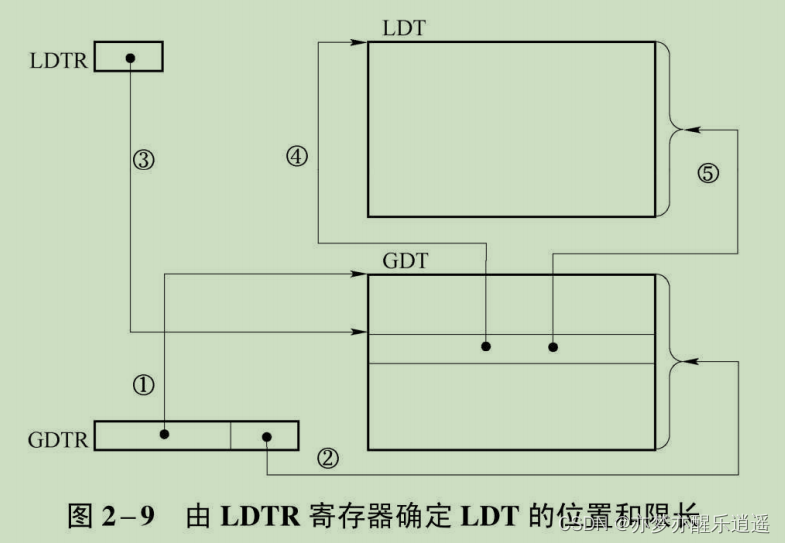
LLDT命令在保护模式中执行,每次切换程序,LDTR都要切换GDT中到该程序对应的LDT描述符。
中断描述符表寄存器(IDTR)
IDTR类似于GDTR,也是48位,在保护模式下用。
基地址32位,指向IDT
与GDTR的区别在于,虽然有16位限长,但是实际上用不了那么多。因为CPU最多支持256个中断,所以是浪费了一些位的。也就是说,IDT最多存256个门描述符(相比于段描述符就是换了个说法),这不是物理的限制,而是逻辑的限制。
每一个门描述符,都指向中断门
这里有一个问题,段寄存器只负责在LDT和GDT中选段,所以似乎是没有IDT的段选机制的。实际上,系统中断不需要你用寄存器选,自有其他机制实现中断描述符的选择。
实模式是如何使用系统中断的呢,是用中断向量表。区别在于,IDT位置可变,中断向量表固定在00000H。
中段描述符表和GDT一样只有一个,所以LIDT也是进入保护模式前装入的。
任务寄存器(TR,Task Register)
TR用于保护模式的任务切换机制。
TR是16位的,也是在GDT上选段,只不过选的是TSS描述符。一个TSS描述符对应内存中一片TSS区域,储存其基址与大小。TR比较纯粹,16位全用了,所以进行GDT偏移的时候,不需要乘8(但段寄存器的13位Index还要乘8),如下:

TSS(Task State Segment)是任务状态段,储存在内存中,一个TSS对应一个程序,储存了启动任务所需的各种信息。
TR用于多任务切换,每次任务切换,TR就重新装载。

内存管理
其实内存管理和寄存器是紧密相关的,能把前面的理解了,内存管理其实已经没什么障碍了。
实模式下分段管理
8086有20位地址总线,但是段寄存器只有16位。
所以段寄存器实际上储存了物理地址的高16位,搭配16位的偏移量实现1M空间的寻址。因此,每一个内存段的首地址必须是16的倍数,而且段的最大长度只能是64K(因为16位偏移量的限制)

计算方式也很简单,从这里可以看出,段与段之间其实是有可能重叠,相邻的,因为段基址之间的差距只有16,但是段长却可以达到64K
实际寻址中,CS存放代码段基址,DS存放数据段基址,SS存放堆栈段基址。
16位偏移量从何而来?可能存在某个寄存器中,或者通过操作数寻址得来。
如果是寄存器,一定是配套的,CS对应IP,SS对应SP
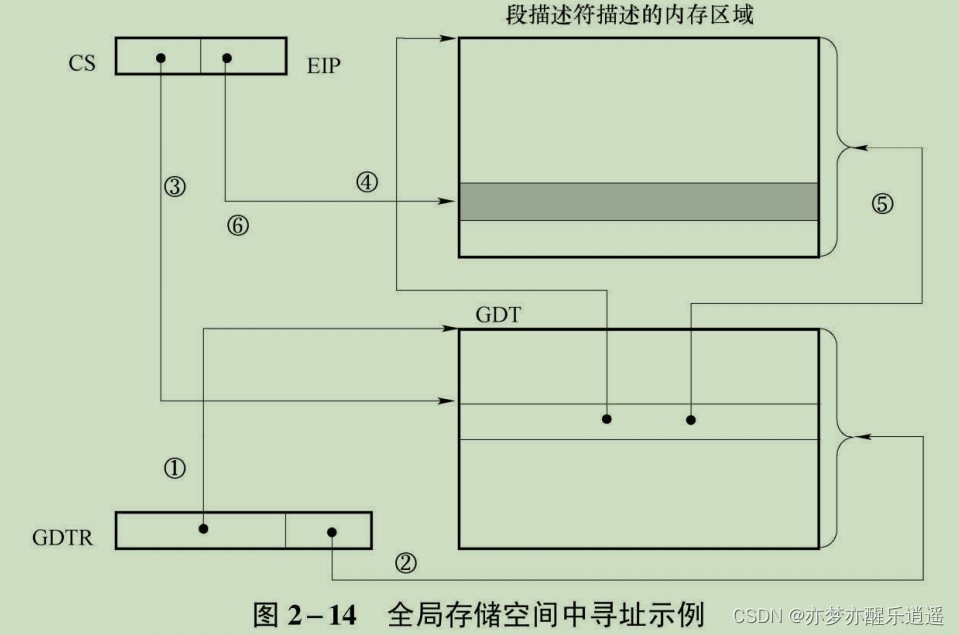
保护模式下分段管理
保护模式下的逻辑地址同样是段基址:偏移量。
只不过段基址变成了段选择子,用于在GDT中选择描述符,因此这种地址表示方式叫做虚拟地址,对应的空间叫做虚拟地址空间。
解释一下我们之前说的64TB空间怎么来的。比如 CS:EIP,CS是16位,EIP有32位,去掉两位RPL,剩下46位,
2
46
=
64
T
B
2^{46}=64TB
246=64TB。
CS:EIP整体寻址流程(假设T1=0,默认GDT)
- CS:EIP是虚拟地址
- GDTR锁定GDT表的位置和大小
- CS的Index从GDT中选一个段描述符,从里面解析出内存中对应的区域基址与大小
- 解析后的基址+EIP偏移量就是实际物理地址
段描述符
GDT/LDT中都会有段描述符,一个段描述符有8字节,共64位。分32位基址,20位限长,8位访问权限,4位属性。
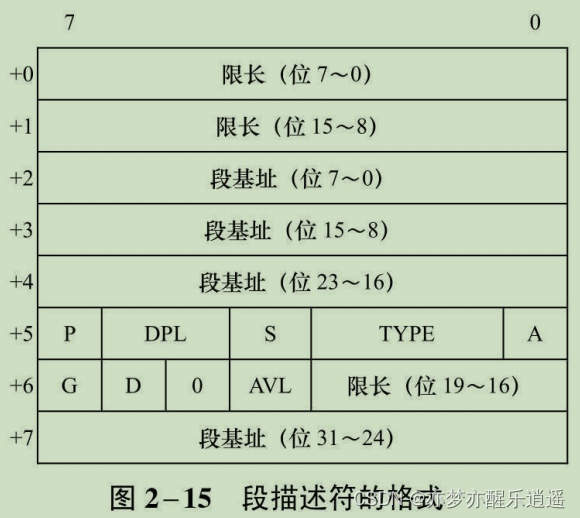
- 为什么这么稀碎,可能有历史原因,出于兼容性考虑。
- 段限长+1才是真正的限长。
- S(System),S=0代表系统段描述符,用户不可用,1代表代码段、数据段、堆栈段,用户可用
- E(Executable),在S=1的前提下,E=1代表代码段,可执行,E=0代表数据段、堆栈段,不可执行
- DPL。特权级,格式同RPL
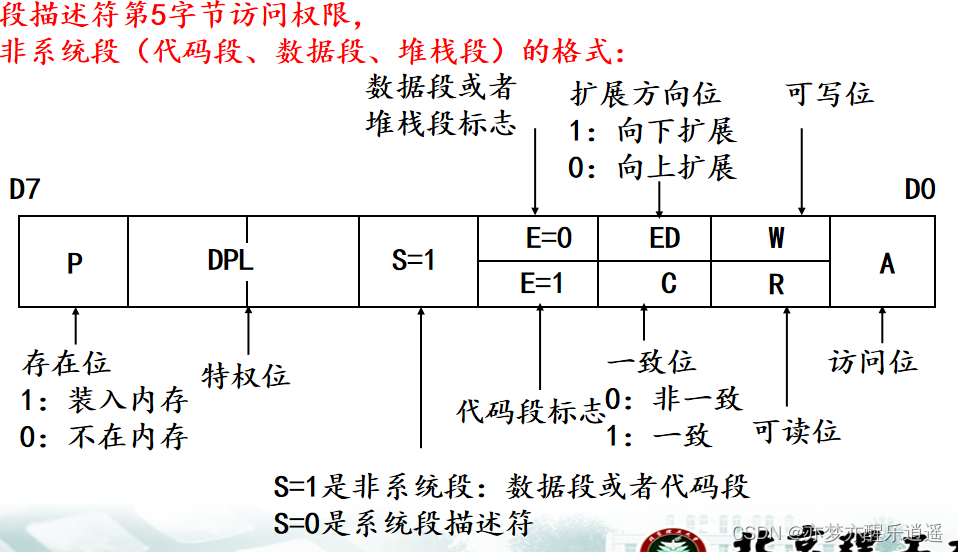
- G(Granularity),粒度,为限长的单位,G=0是默认的Byte字节为单位,G=1以页为单位,一页占用
2
12
2^{12}
212,4KB的空间

段实际限长=(段限长值+1)×粒度-1
因为粒度为0的时候,+1-1抵消了,所以看起来就是段限长值。

表格内容很多,考试会给出表格,只需要会读就可以了,一定要区分好某个符号是占几位以及其含义,接下来举例:
出题的时候,一般会给出一大堆段寄存器,从CS到GS,然后给一个GDTR,再给出GDT的局部内容。

分析CS:
- CS为001B,即0000 0000 0001 1011,Index=3,T1=0代表GDT,RPL=3
- Index×8以后得出0x18H,这就是GDT内的偏移量了,配合GDT的基址可以得到该段的位置:E003F018H,从GDT中找出如下段描述符,对应段描述符结构表进行解析:
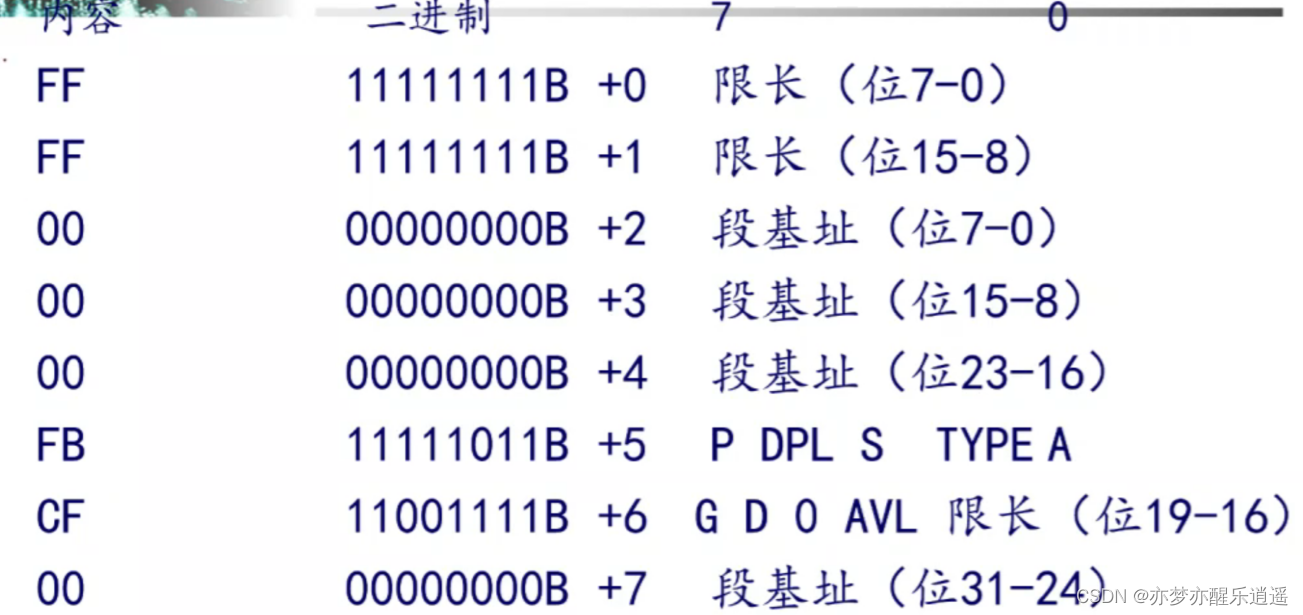
- 段基址和限长是小端表示,注意看好了顺序。
- 限长需要结合G(粒度)判断段大小。

- 之后判断其他段,重点是D,P,DPL,S,E。

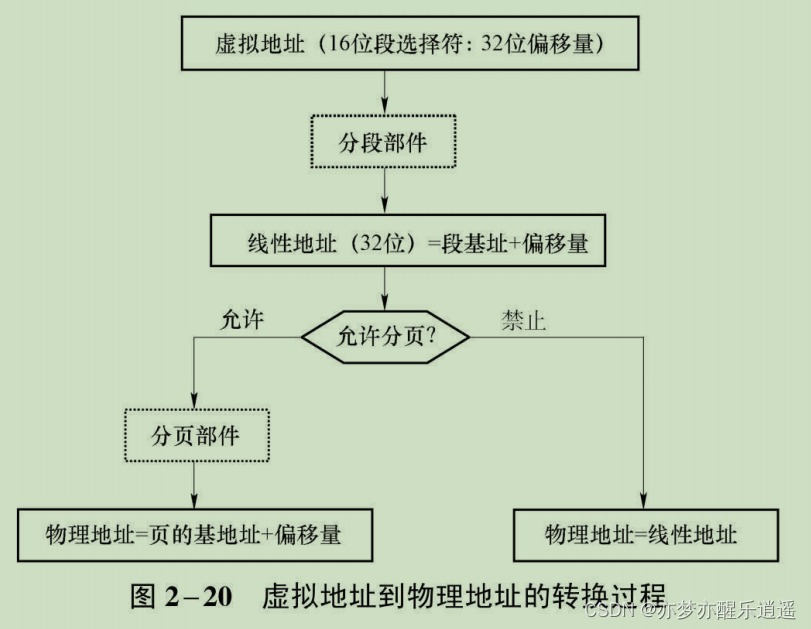
32位CPU系统中三者的转换
下图就是我们上面各种参数的流程化。
首先把16位段选择符转成段描述符,解析出线性地址。
之后根据G是0还是1,判断是否分页
页式内存管理
分页
分页可以理解为将段再次细化,而且每个页的大小都是固定的,一般是4KB。
这样做有两个好处:
- 储存管理粒度更小,效率更高,可以选择性将一段的部分页装入内存,而段只能一次性全部装入。
- 免去一些太过精细的操作,提高操作效率。
缺点就是会浪费一点内存,但是显然好处更多。
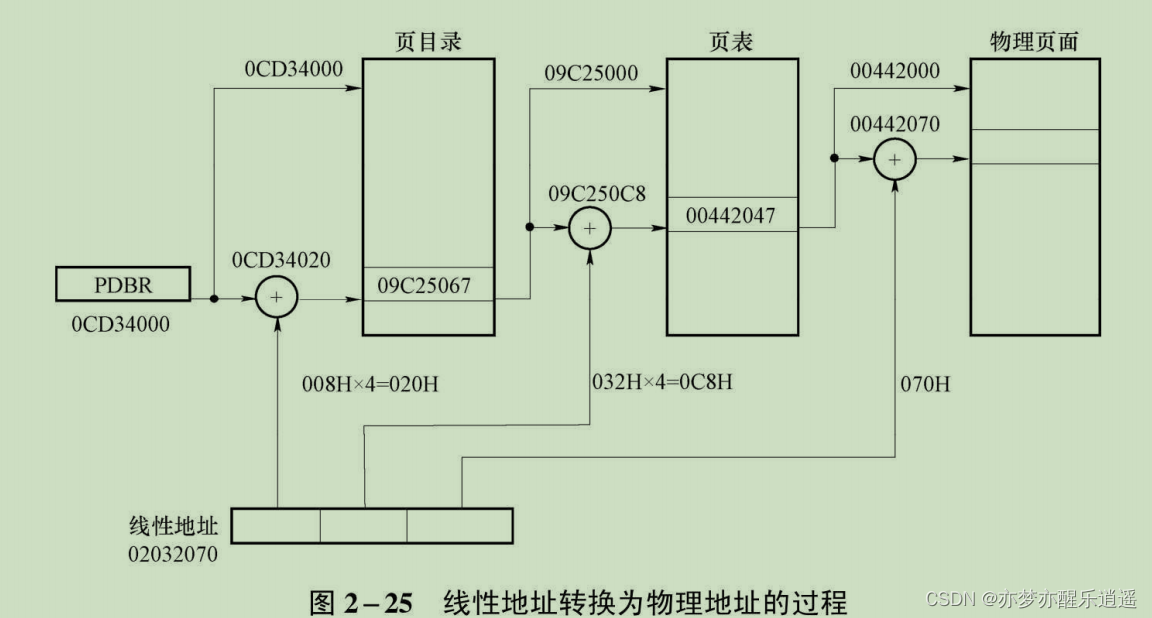
线性地址转换为物理地址的过程

可以看到,这是逐层递进的寻址。
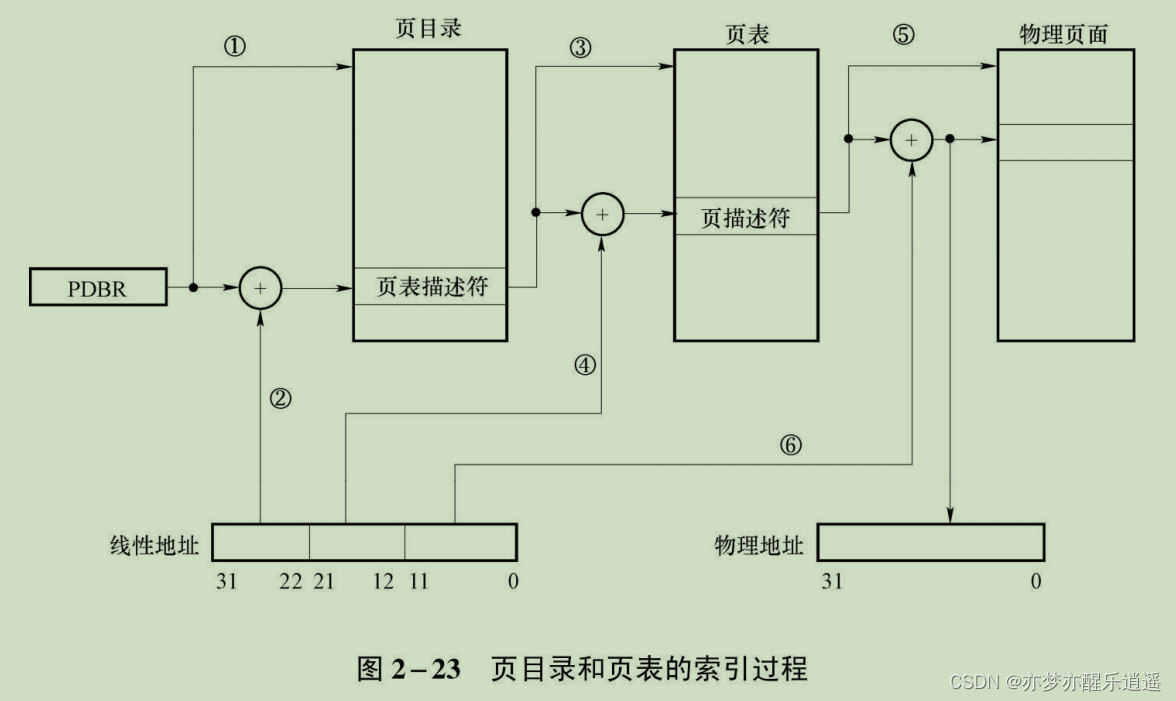
举例子:
- 页目录索引解析:取前10位0000 0010 00 即008H,然后×4偏移(20H)+页目录基址就可以得到页表描述符。其为32位,这也是前面×4偏移的原因,前20位为页表基址,其他位记录了各种描述信息。

- 从页表描述符中取前20位(前5个16进制数)基址+页表索引×4可得页描述符,页描述符同样是32位,所以和页表描述符统称为页表项。
- 从页描述符再取20位基址+页内索引=物理地址。注意业内索引不用乘,因为一个页内索引只对应1字节。
任务
任务执行环境
在多任务环境下,每个任务都有属于自己的任务状态段TSS,TSS中包含启动任务所必需的信息,如用户可访问的寄存器等 。
回顾前面的知识,一个16位的TS从GDT中选择一个TSS描述符,一个TSS描述符对应一个TSS。
TSS是任务状态段,但并不等同于任务执行环境,里面包含了一个共享的代码段,共享数据段,但是不同的优先级有不同的堆栈段:
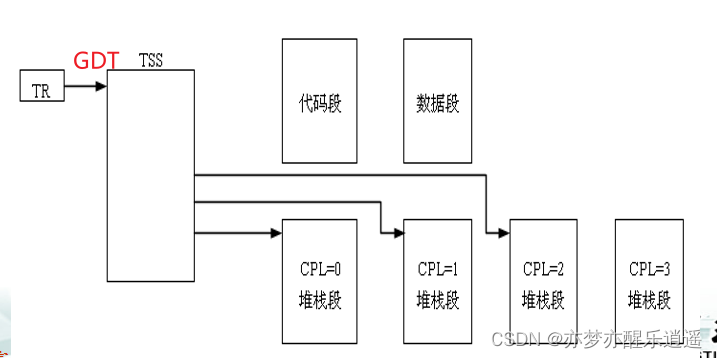
任务状态段(TSS)
基本和别的没啥区别,本质上他就是GDT中的一个段,只不过有些值是固定的,比如S=0,还有就是B字段。
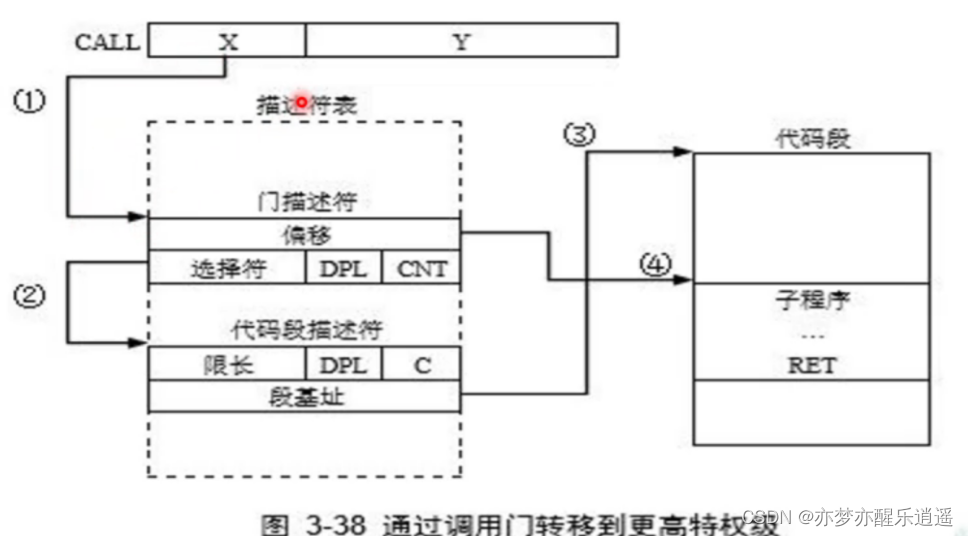
门
门用于转换,比如不同任务之间的调用,比如用户程序调用系统程序,转换过程中会考虑特权级。

门使用门描述符描述,是描述控制转移的入口点,是系统描述符,所以S=0。
调用门
描述符中,类型字段为4或者C表示调用门
调用们描述的是子程序的入口,所谓程序入口,就是程序的某一行代码,比如c语言的main。
所以调用门的选择符必须实现代码段选择符,同时偏移记录了代码段内偏移,两个结合可以定位到某一代码段的某一行代码去。
通过Call,可以实现段间,段内的同级甚至高级调用。比如系统调用。
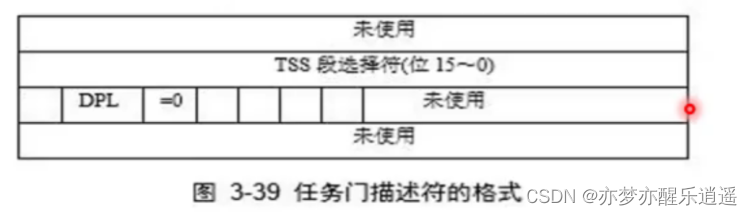
任务门
任务门用于任务切换,任务门中的选择子指向TSS描述符。
中断门和陷阱门
略过,在第7章会讲到。
任务切换
直接任务切换
直接用
段间跳转指令JMP X:Y,或者段间调用指令CALL X:Y,这两个都可以直接指定一个TSS,但是需要进行权限检查,如果权限不足,那就只能通过任务门间接跳转
还可以使用中断。
间接任务切换
通过任务门实现。
保护
保护模式的保护,就在这里。
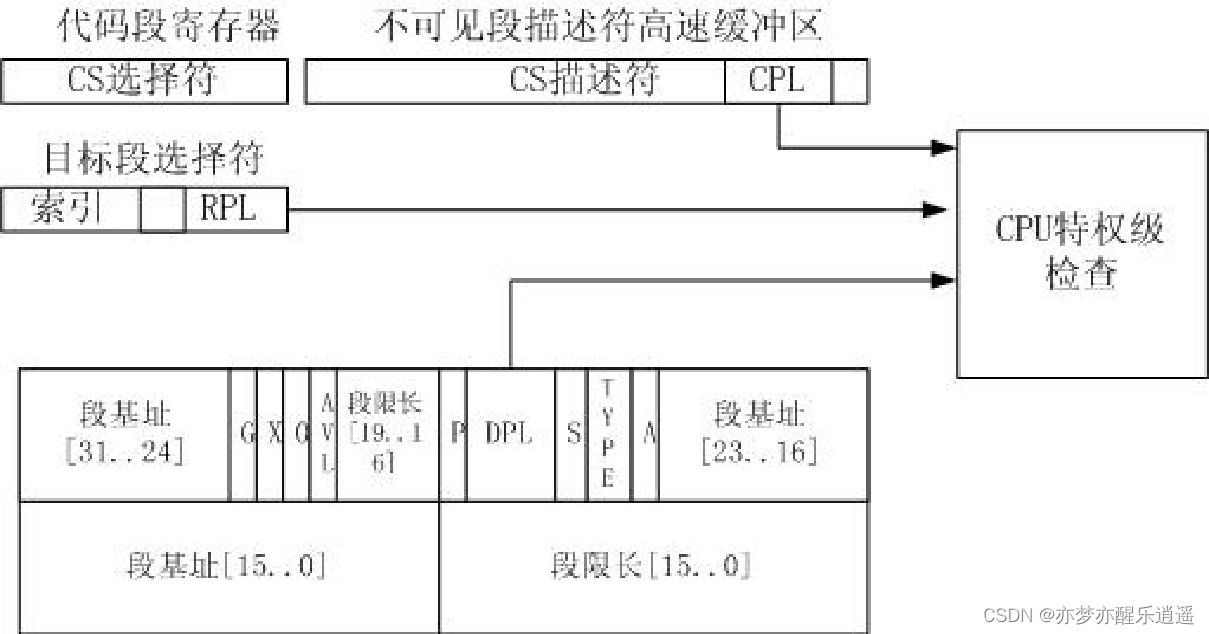
数据访问保护
- 类型检查。检查段描述符的段类型是否与目标一致。比如装入CS的时候,段描述符的E必须是1,表示为可执行段,这才能装入CS,而装入DS,SS,E必须为0。还有就是只有可写的数据段选择符,才能被加载到SS中。
- 限长,类型和属性检查。
- 特权级检查,重点。

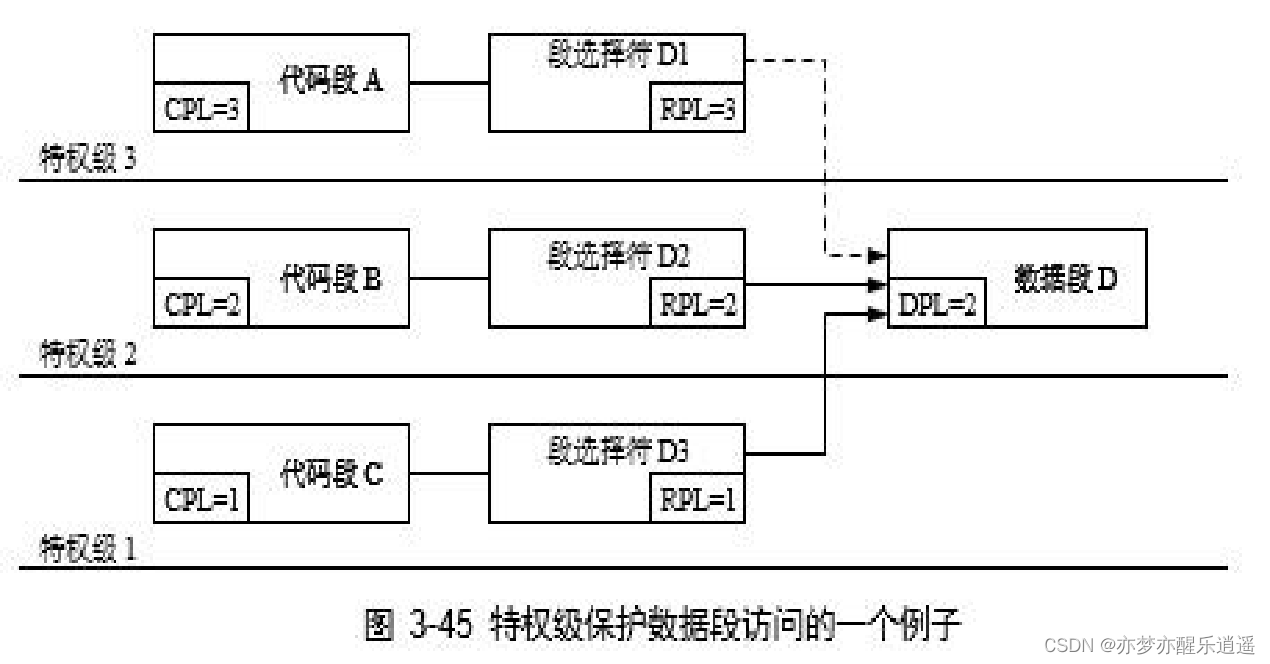
举例:
下图中,最上面的不可以访问,其他两个可以访问。
注意这里DPL是数据段的DPL。
对程序的保护
DPL指代码段的DPL。
直接转移保护
不考虑RPL,因为RPL和CPL一致。
高优先级不直接调用低优先级。同优先级可以直接调用,低优先级调用高优先级之前要经过一致性检验。

举例:
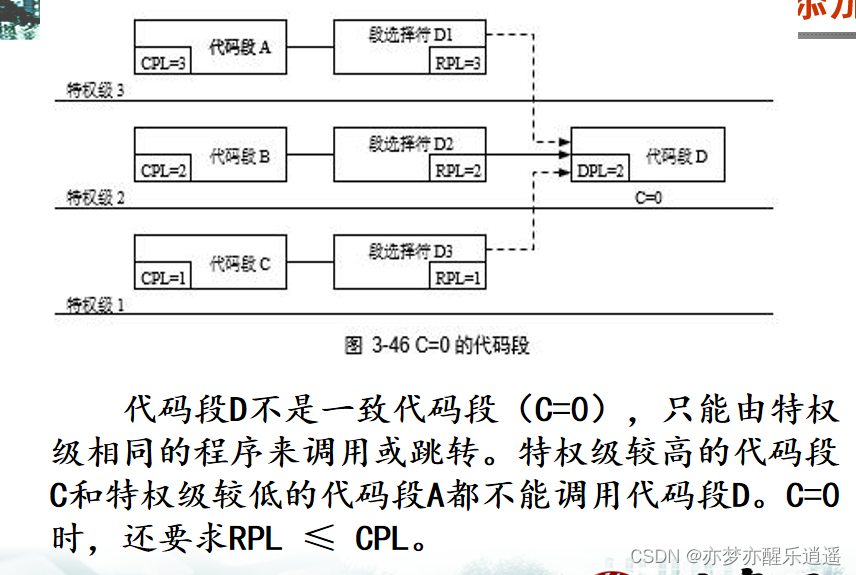
C=1。很多系统调用就是C=1,因此可以被优先级更低的用户程序调用。
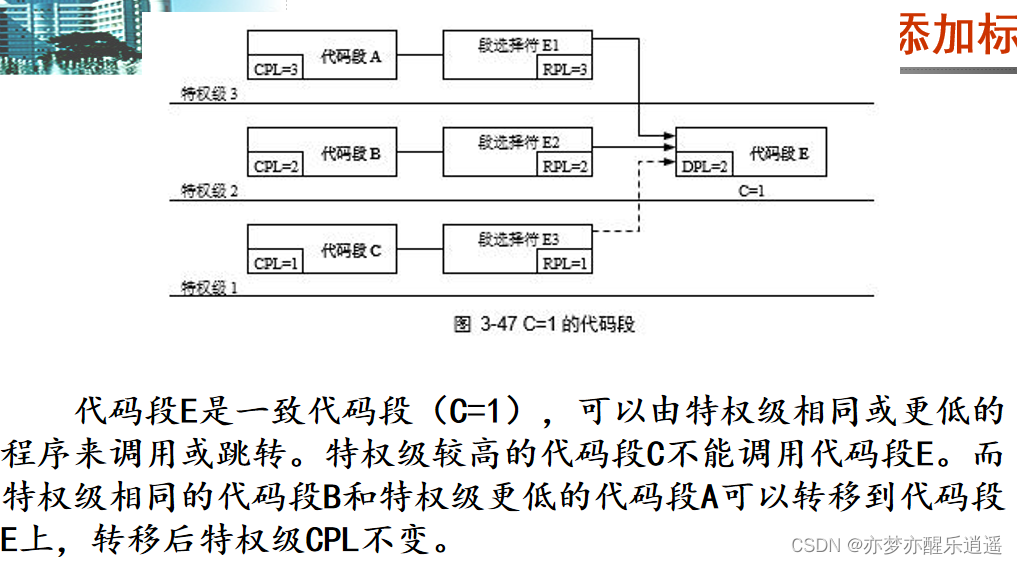
间接转移保护
略过
输入输出保护
略过
特权级综合例题

JMP命令对应CS代码段寄存器。取CS的最后两位得到CPL=3
目标的段基址为000A,解析出RPL=2,Index=1,T1=0,所以取GDT的第二个段描述符。
经过解析,得到该代码段的DPL=0,即CPL>DPL,所以这个相当于低优先级代码调用高优先级代码,所以要检查C(此时E=1,对应代码段,存在C这个字段),是否一致。结果C=0,所以不能跳转。

指令系统(重点)

计算机执行程序,要用01机器码,而指令是机器码的一层封装。
指令一般分为三部分,操作符(操作码),目标操作数,源操作数。大多数情况下操作数只是给出地址,具体的内容需要寻址。
数据寻址方式
CPU操作数寻址
操作数来自于CPU内部。所以是没有物理地址的,因为都在CPU。
立即寻址
可以理解为常数。因为操作数直接就包含在指令中,其实不用寻址。

寄存器寻址
操作数储存在寄存器中,指定寄存器名字可以寻址确定操作数。
寄存器可以是通用8-32位寄存器,也可以是段寄存器。但是不能对CS赋值(代码段寄存器不能作为目标)

储存器操作数寻址
操作数来自于RAM,内存。
在写法上,与CPU的不同在于间接寻址都要在外面套括号。比如MOV AX, [BX]
直接寻址(两种写法)
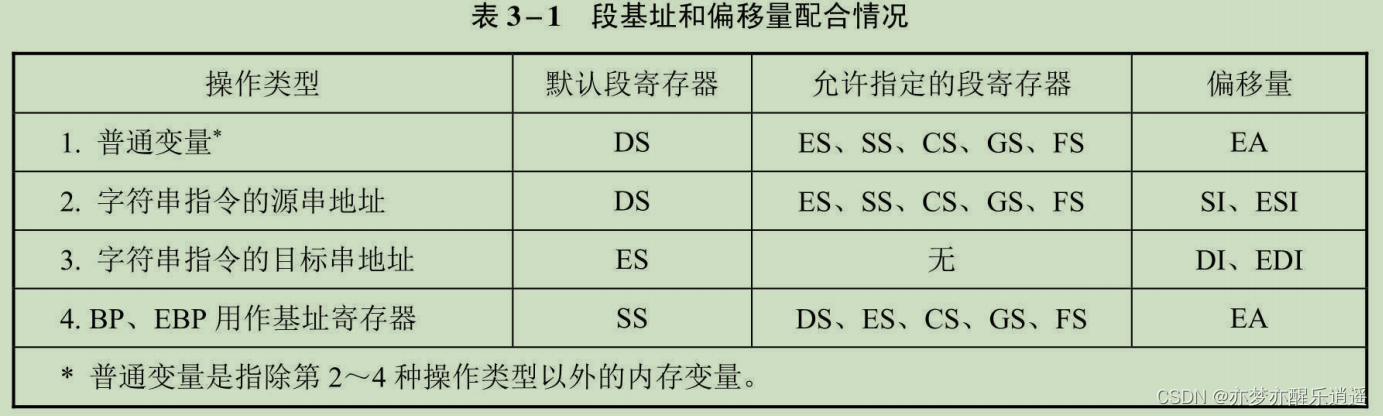
把操作数的地址包含在指令中,就是直接寻址。这个地址是逻辑地址,是段超越前缀格式——段寄存器名:储存器寻址。

需要注意的是,段基址和寄存器偏移量需要配合。不过如果偏移量不是寄存器,那就随意指定段寄存器了。
具体做法就是用【】将地址数值括起来,如果不指定段寄存器,就默认DS,即从DS段中取00404011H偏移量开始,对应的4字节数据送到EAX里。之所以是4字节,是因为EAX有4字节,程序会从给定物理地址开始读取相应数量的字节。

因为直接给数字比较麻烦,参考C语言中的变量思想,于是可以用内存变量名储存地址数字。
VAR变量大致有DB,DW,DD三种,分别对应Byte,Word,Double Word,1,2,4字节。
实际上,没人会用数字直接去写,只有反汇编的时候才会有数字出现。

注意,要么写成MOV AX,[10H],要么写成MOV AX,VAR
不存在MOV AX,[VAR]这种写法。
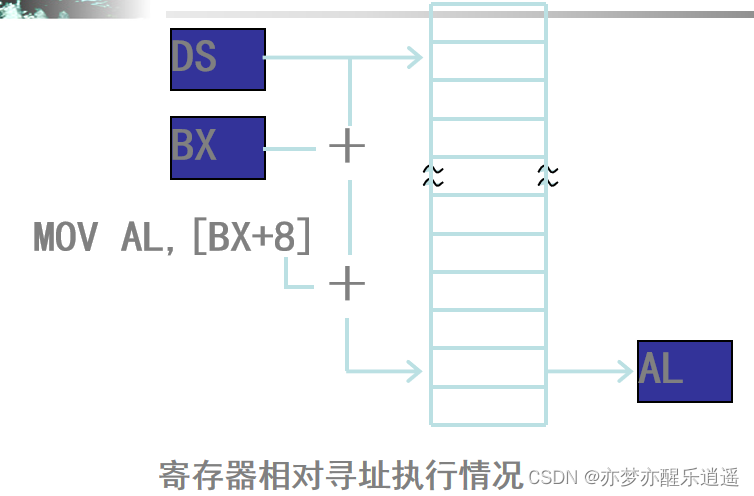
寄存器间接寻址
将寄存器中的数据视作地址,去内存中寻找操作数。
注意区分:
- MOV AX,BX ,用BX中的值作为操作数(CPU级别 寄存器寻址)
- MOV AX,[BX],去内存中间接寻找操作数(储存器级别 寄存器间接寻址)
偏移量可用寄存器:
16位寻址的时候,寄存器只能是基址寄存器BX,BP(对SS),以及变址寄存器SI,DI,给出一个偏移,会根据寄存器对应关系确定其段寄存器。
32位寻址可以使用任意通用寄存器。
偏移量寄存器与段寄存器的搭配:
BP、EBP、ESP,则默认与SS段寄存器配合。
使用其它通用寄存器,则默认与DS段寄存器配合。
均允许使用段超越前缀。

寄存器相对寻址(两种写法)
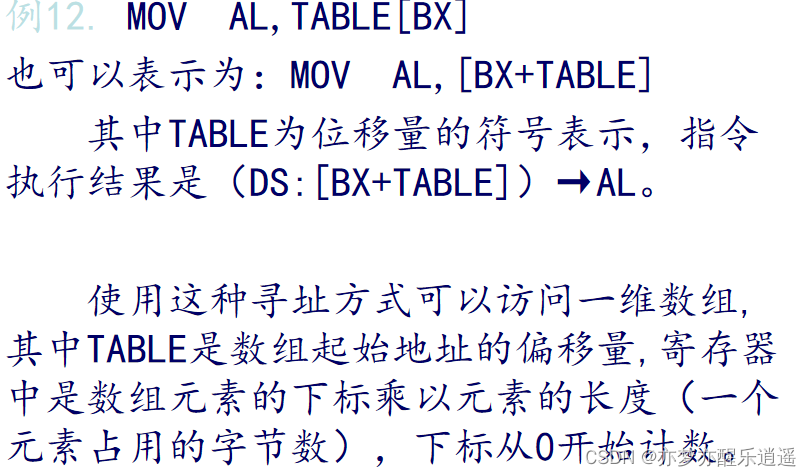
MOV AX,TABLE [寄存器]
在寄存器间接寻址的基础上,再加一个相对偏移量(下图为8),所以可用寄存器以及寄存器搭配,与寄存器间接寻址方法一样:

但是从另一种角度看,实际也可以看做以8为段内基地址,在加上BX代表的偏移。一维数组就是这么工作的,TABLE给出数组首地址,寄存器储存了数组下标×元素长度(元素相对于数组首地址的字节偏移量)。
从上面看,TABLE可以是常数,自然也可以是VAR型。
注意,如果TABLE是使用VAR变量而不是常数,那么VAR变量在作为相对偏移的同时,还确定了目标空间的长度。
比如TABLE是DW类型的,那么就会去取一个字(2字节)的空间送到目标操作数,所以目标操作数应当是一个字(2字节)
基址变址寻址方式(重点考实模式)
相当于把前面的TABLE用寄存器内容代替。
基址寄存器——TABLE,可以用BX,BP
变址寄存器——前面的寄存器,可以用SI,DI
注意,一定是前面写基址寄存器,后面写变址寄存器。

可选寄存器:
16位情况下,就前面提到的,BX,BP,SI,DI
32位可以使用除ESP以外任何两个通用寄存器。
相对基址变址方法
经常用于二维数组。
如果ARY是2字节,第一个元素为00,第二个元素就得02,20也可以。

比例变址寻址方法
这种也很适合表示数组。系数就代表了元素的大小。

小结


(1)
AX不能当偏移,得BX,EX
(2)
溢出了(1280是10进制,1280H是16进制,但是即使只有10进制,1280也不是一字节可以放得下的)
(3)
两个都不能判断字节数,BYTE PTR[BX]
(4)
立即数不能给段寄存器,只能给通用寄存器。万一没有立即数这个空间。
所以只能用AX这类的。
(5)
[BX]指向内存,VAR是存在内存的,两个内存之间不可以直接赋值
(6)
和5一样
(7)
常数不作为目标操作数
(8)
基址+变址,都是变址就错了
(9)
CS不可直接赋值,只能用JMP
(10)
还没学TODO
数据运算指令
数据传送指令
通用数据传送

解释:
- 常数肯定不能被赋值
- 不可以随意用常数指定段寄存器,至少应该先送到寄存器中(段寄存器不可以给段寄存器赋值)
- CS是代码段,不可写
- 两个内存不能传

如果两个操作数都不能确定大小,就需要显示指定,比如WORD PRT表示,BX指向内存为WORD。或者用movq这种指令。此外还有movsx,movzx。
MOV AL,5
MOV DS,AX
MOV [BX],AX
MOV ES:VAR,12
MOV WORD PTR [BX],10
MOV EAX,EBX
mov其实就是赋值,有时候也会用到交换,汇编给出了最快的交换指令XCHG,两个操作数不能是立即数,也不能都是内存,其他情况都可以。


堆栈操作指令

但是实际上我们不直接对这些寄存器做加减,甚至不直接和段寄存器以及内存中段打交道,而是对操作数进行push和pop。
push是直接push一个数(寄存器或者立即数,但是立即数的大小难以确定,在286以上才支持),而不是操作SS和SP。pop一样,将一定字节的数存在DST中。
SRC和DST都可以是寄存器/储存器。


常见指令序列:
PUSH AX
PUSH BX
……
PUSH 1234H ;80286以上可用
POP DX
……
POP BX
POP AX
注意堆栈的初始设置/堆栈异常。
IO指令
IO指令用于外设与内部之间的数据传送。
(1).输入指令 IN
格式: IN ACR,PORT
功能:把外设端口(PORT)的内容传送给累加器(ACR)。
说明:可以传送8位、16位、32位,相应的累加器选择AL、AX、EAX。
ACR只能是累加器,AL,AX,EAX,RAX
PORT是数值,或者寄存器,与MOV不同,这里用数值本身作为端口地址,效果是地址,但是形式是数值。所以端口用起来更像寄存器。
如果端口号超过一个字节(256),就得先放到DX寄存器中,再写到IN指令中。
IN AL,61H ;AL ←(61H端口)
IN AX,20H ;AX ←(20H端口)
MOV DX,3F8H ,超过一个字节的PORT,必须用DX
IN AL,DX ;AL ←(3F8H端口)
IN EAX,DX ;EAX ←(DX所指向的端口)
(2).输出指令 OUT
格式:OUT PORT,ACR
功能:把累加器的内容传送给外设端口。
说明:对累加器和端口号的选择限制同IN指令。
例.
MOV AL,0
OUT 61H,AL ;61H端口← (AL)
;关掉PC扬声器
MOV DX,3F8H
OUT DX,AL ;3F8H端口 ← (AL)
;向COM1端口输出一个字符
地址传送指令
传送有效地址指令 LEA
格式:LEA REG,SRC
功能:把源操作数的有效地址送给指定的寄存器。
说明:源操作数必须是存储器操作数。
因为要计算SRC的地址送到目标寄存器中,所以SRC必须是内存寻址,DST一定是寄存器。可以理解为先把地址计算出来丢到寄存器,以后用的时候就很方便。LEA实际上是计算,但是不会影响标志位。
例.
LEA SI,TAB
LEA BX,TAB [SI]
LEA DI,ASCTAB [BX] [SI]
二进制算数运算指令
类型转换指令
一般是低位到高位的扩展。将符号位扩展到高位:
符号位为0,扩展的就是0,符号位为1,扩展的就是1,总之是带符号的扩展。符号扩展可以用movs代替,如果想要零扩展,前面有movz命令。
字节扩展成字指令 CBW
格式:CBW
功能:把AL寄存器中的符号位值扩展到AH中
MOV AL,FFH
例. MOV AL,5
CBW ;(AH)= 0,AL值不变
MOV AL,98H
CBW ;(AX)= 0FF98H,AL值不变
除了上面这种,还可以进行各种类型的转换。
(2).字扩展成双字指令 CWD
格式: CWD
功能:把AX的符号位值扩展到DX中
(3).双字扩展成四字指令 CDQ
格式:CDQ (386以上)
功能: EAX符号位扩展到EDX中
(4).AX符号位扩展到EAX指令 CWDE
格式: CWDE (386以上)
功能: AX寄存器符号位扩展到EAX高16位
加法指令
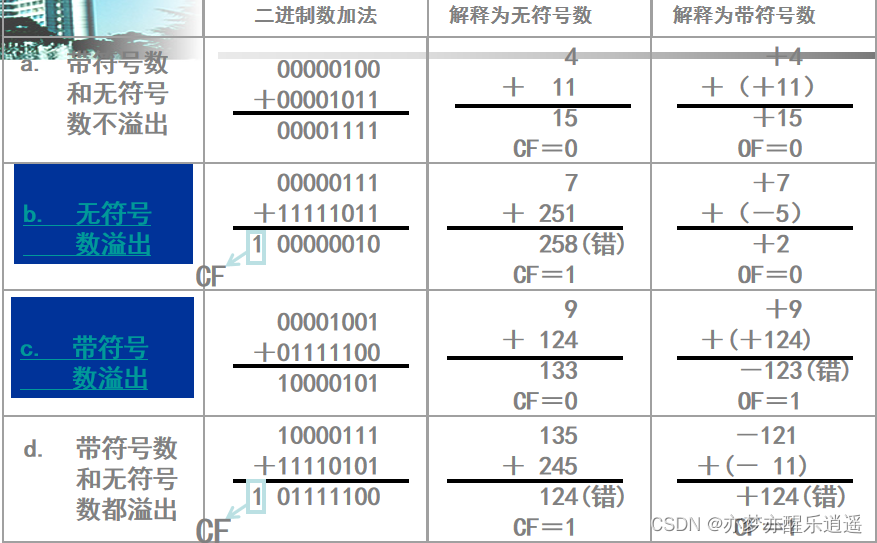
二进制加减法适用于有符号和无符号数。也就是说,ADD命令不管二进制数代表有符号数还是无符号数,这是人规定的,而如何判断就要通过标志寄存器了。
(1).加法指令 ADD
格式: ADD DST,SRC
功能:(DST)+(SRC)→ DST
说明:对操作数的限定同MOV指令。
标志:影响OF、SF、ZF、AF、PF、CF标志
例. ADD AL,BL
ADD CL,6
ADD WORD PTR[BX],56
ADD EDX,EAX
从下图中看,CF=1的时候,代表无符号数溢出,OF=1的时候,代表有符号数溢出。
(2).带进位加法指令 ADC
格式: ADC DST,SRC
功能:(DST)+(SRC)+ CF → DST
说明: 对操作数的限定同MOV指令,该指令适用于多字节或多字的加法运算。
标志: 影响OF、SF、ZF、AF、PF、CF标志
例. ADC AX,35
;(AX)= (AX)+35+CF
ADC就是在加法的式子里增加了CF项。可以用多个ADC指令,将很长的几节无符号数看成整体递推相乘。
(3).加1指令 INC
格式:INC DST
功能:(DST)+1→DST
标志:除不影响CF标志外,影响其它五个算术运算特征标志。
例. INC BX
例.实现+2操作:ADD AX,2 与INC AX INC AX 不等同,如果溢出,两次递增的CF位会在第二次丢失
inc不影响CF,这一点就和AX不等同。但是对其他标志位是有影响的。
(4).互换并加法指令 XADD(486以上)
格式:XADD DST,SRC
功能: (DST)+(SRC)→TEMP
(DST)→SRC
TEMP→DST
说明:TEMP是临时变量。该指令执行后,原DST的内容在SRC中,和在DST中。
标志:影响OF、SF、ZF、AF、PF、CF。
其实就是在求和的同时保留DST到SRC中。
减法指令
减法类似加法。
- SUB正常减,如果无符号数溢出(减出负数),则CF=1,有符号数溢出(上下都有可能),则OF=1。
- SBB带借位减法,(DST)-(SRC)-CF → DST,和ADC类似,一般配合多字节无符号数使用。
- DEC为自减,同样不影响CF。
(4).比较指令 CMP
格式:CMP DST,SRC
功能:(DST)-(SRC),影响标志位。
说明:这条指令执行相减操作后只根据结果设置标志位,并不改变两个操作数的原值,其它要求同SUB。CMP指令常用于比较两个数的大小。
标志:影响OF、SF、ZF、AF、PF、CF标志
(5).求补指令 NEG
格式: NEG DST(DST应当代表有符号数)
功能:对目标操作数(含符号位)求反加1,并且把结果送回目标。即:实现0-(DST)→DST
说明:利用NEG指令可实现求一个数的相反数。
标志:影响OF、SF、ZF、AF、PF、CF标志。
对CF和OF的影响如下:
a.对操作数所能表示的最小负数(例若操作数是8位则为-128)求补,原操作数不变,但OF被置1(对-128求反会出现有符号溢出,即OF=1。之所以源操作数不变,是因为1000 0000取反加一还是1000 0000)
b.当操作数为0时,清0 CF。
c.对非0操作数求补后,置1 CF。
例. 实现0 -(AL)的运算
NEG AL
例. EAX中存放一负数,求该数的绝对值
NEG EAX
多字节相加例子

下面程序中,整体思路就是,对最低字节使用ADD指令,其他字节使用ADC。个人感觉,可以先把CF置零,之后直接用循环把所有字节用ADC处理。
具体到代码,sum,first,second分别指向三个数的最高字节,是VAR变量,用于储存器直接寻址。
关于写法:
- SECOND+2,而不是[SECOND+2],即使其+2,也仍然是VAR直接寻址,不可以加方括号。(存疑?TODO)
- 另一个点,为什么不能写成SECOND+BX?存疑?TODO
- INC,DEC可否换成ADD?不可以,因为不能影响CF
最后,这个程序的缺陷在于最高位进位没有考虑到,理论做法应该是给SUM留4字节。或者,3字节情况下可以判断最后一个字节计算后的OF/CF,来判断溢出。
LEA DI,SUM ;把和的地址指针送给DI寄存器
ADD DI,2 ;+2偏移后DI指向和的低字节
MOV BX,2 ;BX负责偏移
MOV AL,FIRST[BX] ;取FIRST的低字节(本例为33H)
ADD AL,SECOND+2 ;两个低字节相加,和①在AL中,进位反映在CF中
MOV [DI],AL ;把低字节和存到DI指向的单元(本例为SUM+2单元)
DEC DI ;修改和指针,使其指向中字节
DEC BX
;修改加数指针,使其指向中字节
MOV AL,FIRST[BX] ;取FIRST的中字节(本例为22H)
ADC AL,SECOND+1 ;两个中字节相加且加CF,和②在AL中,进位反映在CF中
MOV [DI],AL ;把中字节和存到DI指向的单元(本例为SUM+1单元)
DEC DI ;修改和指针,使其指向高字节
DEC BX
;修改加数指针,使其指向高字节
MOV AL,FIRST[BX] ;取FIRST的高字节(本例为11H)
ADC AL,SECOND ;两个高字节相加且加CF,和③在AL中,进位反映在CF中
MOV [DI],AL ;把高字节和存到DI指向的单元(本例为SUM单元)
乘法指令
(1).无符号乘法指令 MUL
格式:MUL SRCreg/m
功能:实现两个无符号二进制数乘。
说明:该指令只含一个源操作数, 另一个乘数必须事前放在累加器中。可以实现8位、16位、32位无符号数乘。
具体操作为:
字节型乘法:(AL)×(SRC)8→AX
字型乘法: (AX)×(SRC)16→DX:AX
双字型乘法:(EAX)×(SRC)32→EDX:EAX
标志比较特殊,仅仅是代表高半部分有没有被影响:对CF和OF的影响是:若乘积的高半部分(例字节型乘法结果的AH)为0则对CF和OF清0,否则置CF和OF为1,代表高半部分被影响,结果如果还保持原来的长度,那就要进行截断了。
最关键的事情就是如何区分不同位的乘。在汇编中,不会给你自动匹配累加器的大小,所以即使你累加器指定了AL,然后再把立即数当MUL的操作数,也是不可以的。即,操作数和累加器大小要匹配。
累加器指定大小后,操作数只能有两种可能,立即数是不被允许的:
- 要么是同大小的寄存器
- 要么就是声明指向区域大小的储存器寻址。
例.
MOV AL,8
MUL BL ;(AL)×(BL),结果在AX中
MOV AX,1234H
MUL WORD PTR [BX] ;(AX)×([BX]),结果在DX:AX中
MOV AL,80H
SUB AH,AH ;清0 AH(清零方法之一,还有MOV AH,0,逻辑运算,甚至可以用0去乘)
MUL BX ;(AX)×(BX),结果在DX:AX中
(2).带符号乘法指令 IMUL
功能:实现两个带符号二进制数乘。
格式1:IMUL SRCreg/m
说明:这种格式的指令除了是实现两个带符号数相乘且结果为带符号数外,其它与MUL指令相同。所有的80X86 CPU都支持这种格式。
其实MUL和IMUL的区别仅仅是处理与解释方式不同,传进来的操作数是一视同仁的。
除法指令
进行二进制除法前,需要先将被除数的低半段放到累加器中,高半段放到另一个指定的辅助寄存器中。
之后指定SRC即可计算结果。
结果的商存放在低半段中(累加器),余数放在高半段中(辅助寄存器)
关于指定宽度的要求,对于DIV和IDIV来说,与乘法是一样的。
结果的标志位是不确定的,无意义。若除数为0或商超出操作数所表示的范围(其实也是除数太小导致的,所以统一叫除零错误)(例如字节型除法的商超出8位)会产生除法错中断,尽量提前判断避免这种情况,防止除数为0或者除数太小。
具体操作:余数在高部分,商在低部分
- (AX)÷(SRC)8
- (DX:AX)÷(SRC)16
- (EDX:EAX)÷(SRC)32
//单字节
例. 实现1000÷25的无符号数除法。
MOV AX,1000
MOV BL,25
DIV BL
;(AX)÷(BL)、商在AL中、余数在AH中
//字
例. 实现1000÷512的无符号数除法。
MOV AX,1000
SUB DX,DX ; 清0 DX
MOV BX,512
DIV BX
;(DX:AX)÷(BX)、商在AX中、余数在DX中
例. 实现(-1000)÷(+25)的带符号数除法。
MOV AX,-1000
MOV BL,25
IDIV BL
;(AX)÷(BL)、商在AL中、余数在AH中
例. 实现1000÷(-512)的带符号数除法。
MOV AX,1000
CWD ; AX的符号扩展到DX
MOV BX,-512
IDIV BX
;(DX:AX)÷(BX)、商在AX中、余数在DX中
位运算指令
逻辑运算指令
逻辑非是一元运算符,其实不算计算,所以不会影响标志位。
但是其他二元计算,都会影响标志位。因为按位的逻辑运算肯定不会溢出,所以CF和OF一定是0。但是其他位不定。
AND指令和TEST都是按位与,但是逻辑与最后把结果存在DST,而TEST仅做计算,不影响操作数。
XOR指令玩法很多:
- 加密解密。x对一个key连用两次XOR指令,结果还是x,所以异或经常用于加密和解密。
- 与1异或相当于按位取反
- 自己与自己异或相当于清零
- 异或可以用来交换两个数,其不需要第三个数承载
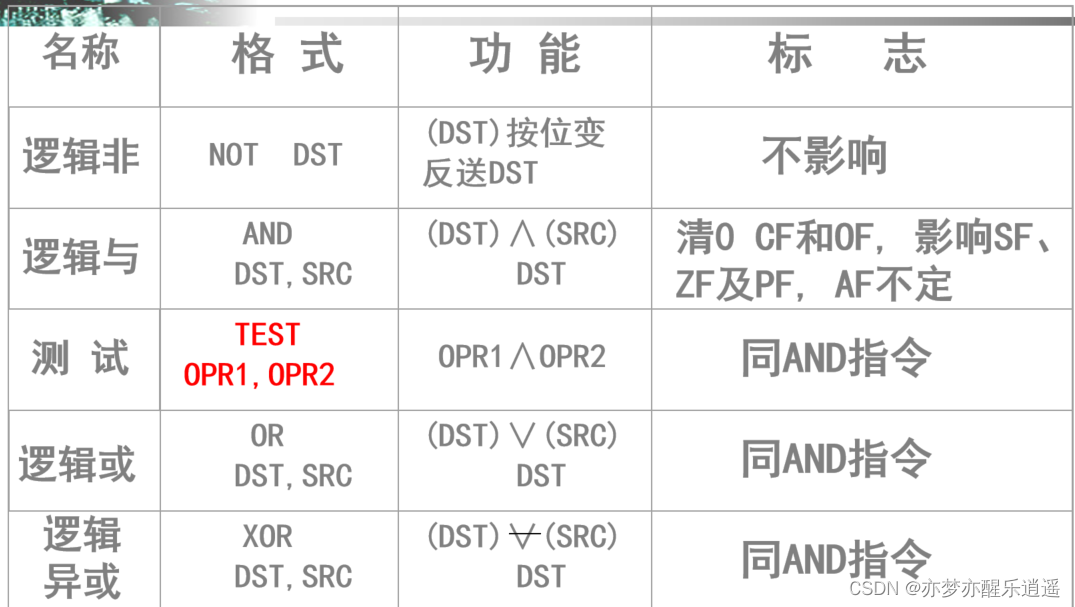
位测试指令
test。
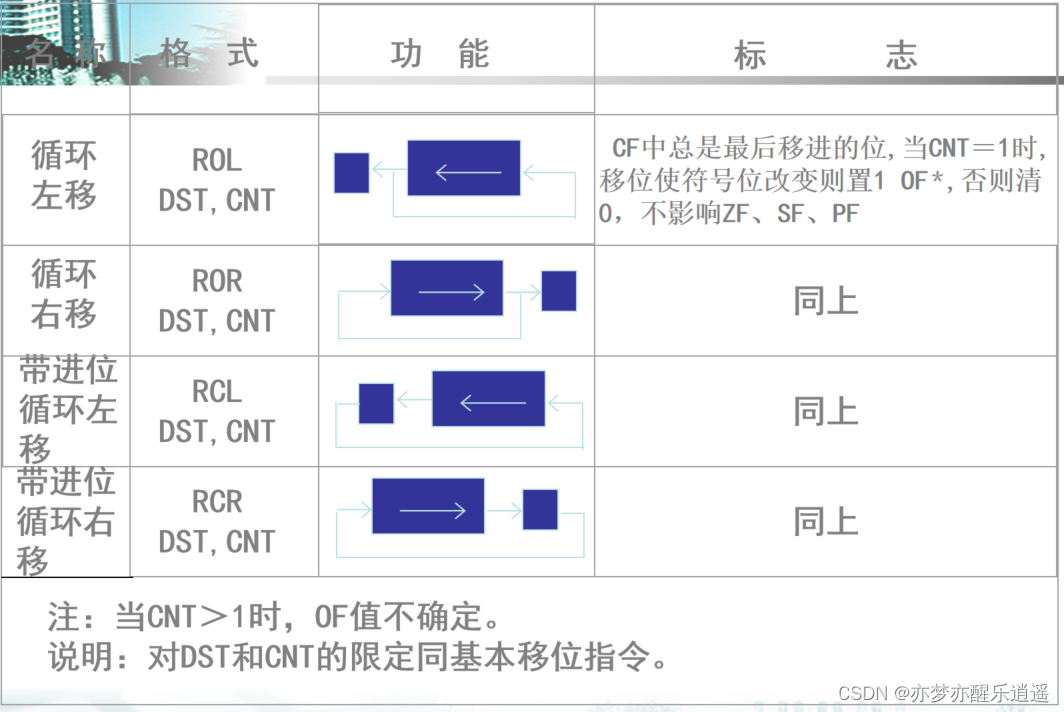
基本移位指令
SHL和SAL一样。SHR和SAR不同,SH代表shift,逻辑,SA代表arithmetic,算数移位。
关于DST和CNT的限制:
- DST一般都是寄存器,如果是储存器操作数可能需要指定大小。
- CNT,1就直接写,不是1就存CL后再移动(286以后的可以直接写立即数)

例. 设无符号数X在AL中,用移位指令实现X×10的运算。
MOV AH,0 ;为了保证不溢出,将AL扩展为字
SHL AX,1 ;求得2X
MOV BX,AX ;暂存2X
MOV CL,2 ;设置移位次数
SHL AX,CL ;求得8X
ADD AX,BX ;10X=8X+2X
循环移位指令
循环移动因为不存在补位,所以也就不存在逻辑还是算数了。所以循环移位就是ROL和ROR(Rotation)
带进位和普通循环的区别是,普通循环是直接把移出位弄到补充位上了,带进位的是先把这一次移出的位放到CF,然后把上一次的CF放到补充位上。是用CF做一个缓冲。
例. 把CX:BX:AX一组寄存器中的48位数据左移一个二进制位。
SHL AX,1 ;此时CF是这次移出的位
RCL BX,1 ;此时将CF中位(上一次移出的位)补充到这一次的末尾
RCL CX,1
在没有溢出的情况下,以上程序实现了2×( CX:BX:AX)→CX:BX:AX的功能。
程序控制指令
以前的寻址是数据寻址。本章的寻址是程序寻址,对应的是CS段与IP指针的变化。
程序寻址
段内直接转移
分为短转移和近转移。两种转移的机制都是相对跳转。区别仅仅在于给出的立即数是8位或者16位的。

段内间接跳转
把有效地址存在寄存器或者内存中,跳转到这个内容指向的地方。
相比于段内直接跳转,间接跳转是直接把16位的转向地址赋给了IP,而不是偏移。
具体说明。
设:(DS)= 2000H,(BX)=0300H (IP)=0100H,(20300H)=000BH (20301H)=0005H
例1. JMP BX ;
执行后(IP)=(BX)= 0300H
例2. JMP WORD PTR [BX]
说明:式中WORD PTR [BX]表示BX指向一个字型内存单元。
- 这条指令执行时,先按照操作数寻址方式得到存放转移地址的内存单元:10H ×(DS)+(BX)= 20306H
- 再从该单元中得到转移地址:
EA=(20306H)= 050BH
- 于是,(IP)=EA=050BH,下一次便执行CS:50BH处的指令,实现了段内间接转移。
10H ×(CS)+(050bh)= 20306H
段间直接转移
段间转移肯定要一次性把CS和IP都赋值,所以需要32位立即数。
请注意赋值顺序。字节0是JMP,字节1到字节4从低到高,先储存偏移量低再储存偏移量高。之后段基址也是如此,符合小端法储存。
如果把4个字节反写,就是CS:IP了。比如JMP 12 34 56 78实际上对应78 56: 34 12

段间间接转移
类似于段内间接,就是从寄存器或者内存中去找跳转目标。
具体数据说明:
设:(DS)= 2000H,(BX)= 0300H
(IP)= 0100H,
(20300H)= 0
(20301H)= 05H
(20302H)= 10H
(20303H)= 60H
则: JMP DWORD PTR [BX]
说明:式中DWORD PTR [BX]表示BX指向一个双字变量。
这条指令执行时,先按照与操作数有关的寻址方式得到存放转移地址的内存单元:
10H×(DS)+(BX)= 20300H
再把该单元中的低字送给IP,高字送给CS,即0500H →IP,6010H→CS,下一次便执行6010:0500H处的指令,实现了段间间接转移。
转移指令
无条件转移JMP
JMP DST
如我们前面所描述的,DST是程序寻址的任何一种方式。
- 段内转移(IP)
- 段内直接短转移 JMP SHORT LABEL
- 段内直接转移 JMP LABEL 或 JMP NEAR PTR LABEL
- 段内间接转移 JMP REG/M
- 段间转移(CS:IP)
- 段间直接转移 JMP FAR PTR LABEL
- 段间间接转移 JMP DWORD PTR M
举例:
可以看到如下规律:
- 段内短转移和近转移,都是偏移量,对应有符号数。其他转移是地址,对应无符号数。
- JMP后跟立即数/LABEL默认为近转移,JMP后跟寄存器或者内存,默认段内间接转移。
- 段间间接转移不可以用寄存器寻址(段内可以)。段内和段间都不可以用立即数寻址。
- 段间转移以及非默认段内转移(SHORT)都需要声明,比如FAR PTR对应LABEL,DWORD PTR对应内存
① 段内直接短转移
格式:JMP SHORT LABEL
例.
JMP SHORT B1 ;无条件转移到B1标号处
A1: ADD AX,BX
B1: …
② 段内直接转移
格式:JMP LABEL
或: JMP NEAR PTR LABEL
例.
JMP B2
A2: ADD AX,CX
…
B2: SUB AX,CX
③ 段内间接转移
格式:JMP REG/M
例.
LEA BX,B2
JMP BX
A2: ADD AX,CX
…
B2: SUB AX,CX
④ 段间直接转移
例. CODE1 SEGMENT
…
JMP FAR PTR B3
…
CODE1 ENDS
CODE2 SEGMENT
…
B3: SUB AX,BX
…
CODE2 ENDS
⑤ 段间间接转移
例. V DD B3
C1 SEGMENT
…
JMP DWORD PTR V
…
C1 ENDS
C2 SEGMENT
…
B3: SUB AX,CX
…
C2 ENDS
条件转移
在直接转移前,针对符号位进行条件判断。
条件转移的写法是JCC LABEL,其中的Condition有多种,但是主要还是S,Z/E(以及后面的复杂组合),因为条件大多数是判断大小的。
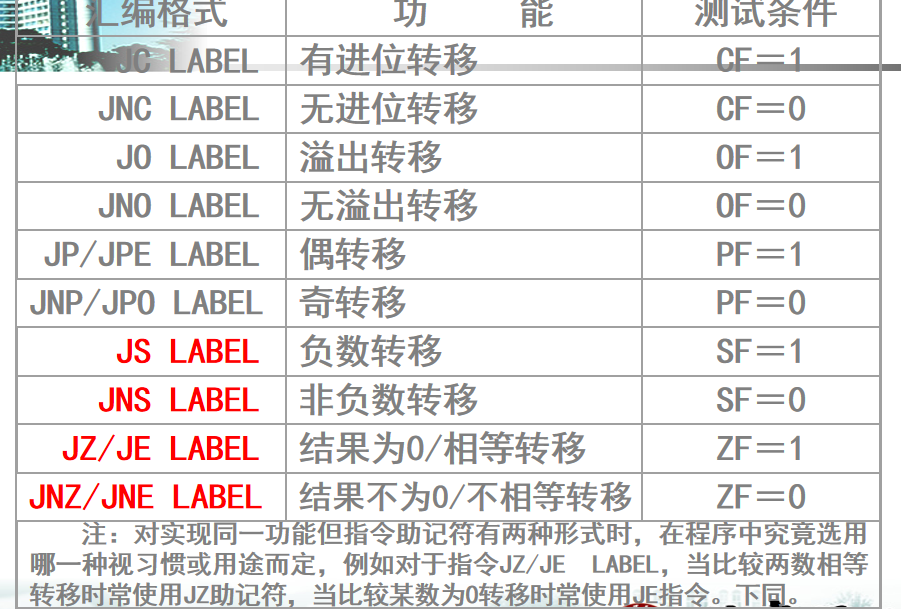
例. 比较AX和BX寄存器中的内容,若相等执行ACT1,不等执行ACT2。
CMP AX,BX
JE ACT1
ACT2: .
.
.
ACT1: …
对于有符号数跳转,用G和L,对应Greater和Less。
对于无符号数跳转,用A和B,对应Above和Below。

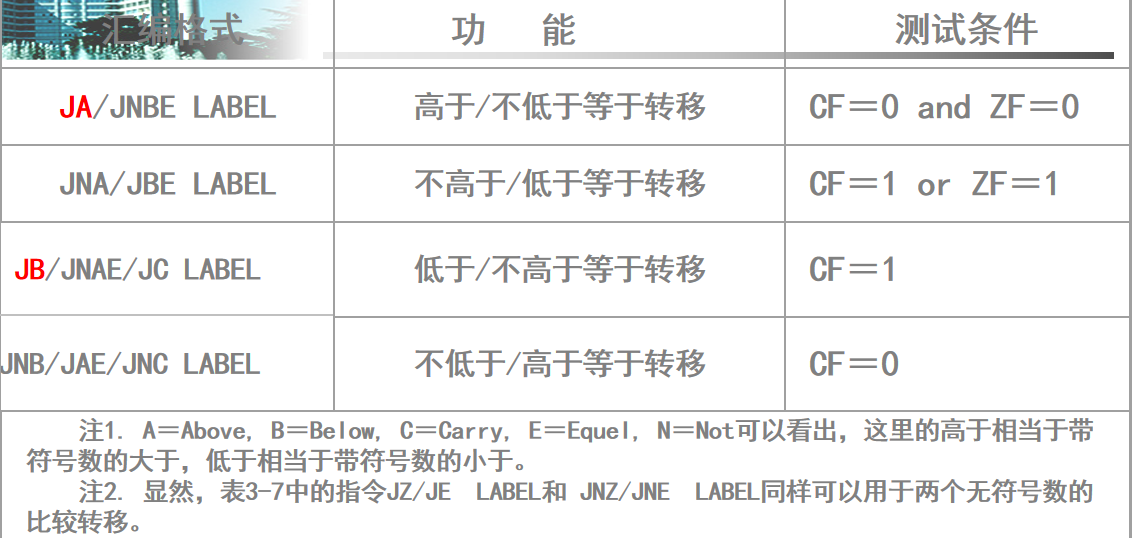
这里要单独拿出来测试条件进行分析,比如CMP B,A后用JG跳转,为什么ZF=0且SF=OF就是大于了?
当ZF=0,则说明cmp结果非0,必然有大有小
当SF=OF,如果SF=OF=0,则说明A-B非负,而且没有溢出,这是正常的结果。如果SF=OF=1,说明结果为负,但是OF=1代表这是溢出后为负,那么说明溢出前为正,必然是因为A是大正数,B是负数,导致相减后溢出的,这也是A>B的情况。
综上,JG命令考虑到了正常的相减以及极端情况下带溢出的相减。其他命令的分析也类似,考试的时候会给出测试条件,让你分析合理性。
最后就是CX测试指令,一般只会在循环中判断CX的值,如果是0就转移,如果不是0就继续。且只能用于短转移。
具体有JCXZ和JECXZ。
举例
例.设M=(EDX:EAX),N=(EBX:ECX),比较两个64位数,若M>N,则转向DMAX,否则转向DMIN。
要区分有符号和无符号,对应的JCC要变。
首先判断高位数大小,如果大就直接走MAX,小就走MIN,否则高位相等。
再比较低位,因为高位是相等的,无论是正数还是负数,后半截始终是和整体大小保持一致的。
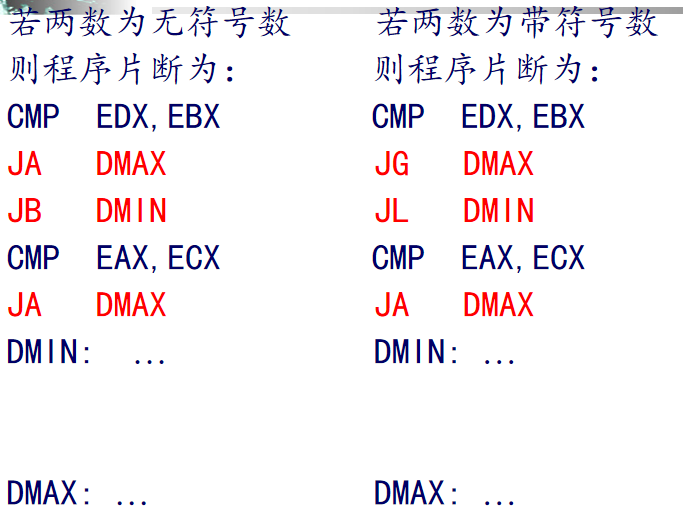
循环指令
LOOP,使用CX或者ECX作为默认计数器,隐形地执行DO LOOP循环。
MOV CX,2
MOV AX,1
LAB:
ADD AX,AX
LOOP LAB
LOOP看起来和CX没关系,但是实际上每次执行LOOP语句都会把CX-1,然后判断CX是否为0,如果是0就退出循环。这实际上就是个do loop,CX定多少,就执行多少次循环。
那么有一种有趣的现象出现了,假如赋值CX=0,那么就会执行很多次:
第一次执行后,
C
X
=
C
X
−
1
=
2
16
−
1
CX=CX-1=2^{16}-1
CX=CX−1=216−1,之后继续执行
2
16
−
1
2^{16}-1
216−1次,总共就是
2
16
2^{16}
216次,很有趣,这是do loop的特殊性质,先执行,再减,再判断。
MOV CX,0
MOV AX,1
LAB:
ADD AX,AX
LOOP LAB
最后给出一个带特殊跳转判断的累乘:
×N其实就是N次累加。
这个例子还想说明的事情就是溢出,乘法很容易溢出,还有就是N是负数的情况(CX默认为正),总的来说,其实程序可能出现的漏洞还是挺多的,破坏一个程序很容易,但是要想让他为你所用,就需要一定的技术含量了。
例. 用累加的方法实现M×N,并把结果保存到RESULT单元。
MOV AX,0 ;清0累加器
MOV BX,M
CMP BX,0
JZ TERM ;被乘数为0转
MOV CX,N
JCXZ TERM ;乘数为0转
L1:
ADD AX,BX
LOOP L1
TERM:
MOV RESULT,AX ;保存结果
子程序调用及返回指令
跳转和调用的区别在于,调用要先跳转,再返回。
调用使用CALL命令。基本和跳转用法类似,但是有一点点不同。
段内调用
与JMP相同,例外是不支持SHORT寻址,也就是说都是NEAR PTR或者16位寄存器。
在跳转前,先会将16位IP压栈。
具体无非就是用LABEL(直接)或者REG/M(间接),和JMP用法相同,CALL默认NEAR PTR。
直接跳转:
CALL LABEL
CALL NEAR PTR LABEL
间接:
例. 可以把子程序入口地址的偏移量送给通用寄存器或内存单元,通过它们实现段内间接调用。
CALL WORD PTR BX
;子程序入口地址的偏移量在BX中
CALL WORD PTR [BX]
;子程序入口地址的偏移量在数据段的BX所指
;向的内存单元中
CALL WORD PTR [BX][SI]
;子程序入口地址的偏移量在数据段的BX+SI
;所指向的内存单元中
段间调用
段间调用就是在压栈的时候多压入CS字。
用法同样如JMP
直接调用:
CALL FAR PTR PROCEDURE
间接调用:(段间不可以用寄存器寻址,所以只能内存寻址)
CALL DWORD PTR VAR
CALL DWORD PTR [BX]
返回
一般返回用RET即可,会恢复IP和CS。
至于段内返回还是段间返回(决定了是否额外弹出CS字段),不需要人去管,汇编会产生不同的机器码。你也可以手动写成RETF(F:far)
除RET以外,还有RET
i
m
m
16
imm_{16}
imm16
这是因为,有时候在执行调用前会构造栈帧传参(用栈传参),那么要想恢复原来的状态,不仅仅要把栈中的返回地址弹出到IP和CS中,还要把参数清理掉,即给RET增加偏移量,这个偏移量是16位的。比如使用栈传入了2个int型数,那么在ret的时候就要用 RET 8
中断调用及返回指令
中断
所谓中断,就是对当前程序的中断。之所以要中断,可能是因为缺少数据(比如Input函数等待输入),也可能是某个资源被占用了,现在卡住了。总之,中断场景无处不在,中断与等待密切相关,先中断,再恢复。
中断本身也都是程序,被称作中断子程序,一般有256个,这些程序可以对当前程序可能面临的各种异常情况进行处理,每一类中断程序都可以处理一种异常,比如标号为3的中断用于处理断点。
这里给出一些概念:
- 中断向量:中断处理子程序的入口地址。在PC机中规定中断处理子程序为FAR型,所以每个中断向量占用4个字节,写法同JMP的段间跳转。
- 中断类型号:IBM PC机共支持256种中断,相应编号为0~255,把这些编号称为中断类型号。
- 256种中断有256个中断向量。把这些中断向量按照中断类型号由小到大的顺序排列,形成中断向量表。表长为4×256= 1024字节,该表从内存的0000:0000地址开始存放,从内存最低端开始存放
可见,n类中断的IP位置为4n,CS位置为4n+2
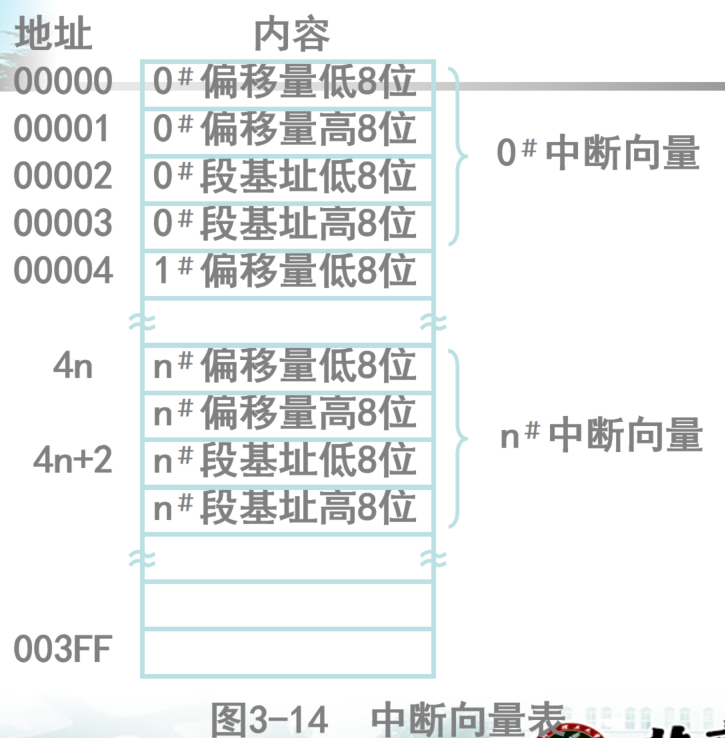
中断调用
INT n
n对应中断类型号。中断调用需要保留断点信息,即FLAGS,CS,IP。
注意INT 80和INT 50H是等价的,注意区分立即数的进制。
INT 21H
21H为系统功能调用中断,执行时把当前的FLAGS、CS、IP值依次压入堆栈,并从中断向量表的84H处取出21H类中断向量,其中(84H)→IP,(86H)→CS,转去执行中断处理子程序。
例. INT 3 ;断点中断
中断返回
IRET(I:interrupt)
弹出栈内保存的信息,返回断点。这个基本不用,因为中断返回是写在中断程序中的,不用你操心。
处理机控制指令
指令可以控制处理机状态,不用细究
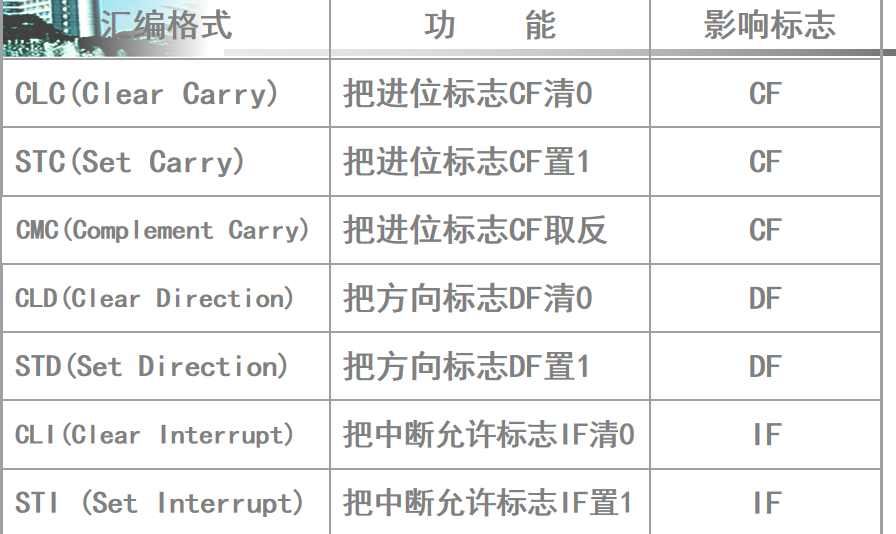
标志位控制指令
标志位是不可以直接赋值的,只能通过指令处理。
STX/CLX命令。X可以是D(对应DF),C(CF)。CL是清0,ST是置1。
其他(略)
略过
块操作指令
块操作指令和串指令,分不清,总之就是批量处理数据,而且是在两个内存之间批量倒。比如以前一个mov只能转移一个数据,现在可以连续转移100个数据。
具体过程为,先确定两个段基址,然后确定两个段起始偏移。之后确定重复次数,重复搬运。
这一块不太重要,只需要掌握几个基本命令即可。
MOVS示例
串传送指令 MOVS:
显式格式:MOVS DST,SRC(一般不用显示指令,因为这个和寄存器寻址看起来一样,容易混淆,实际上在串指令中,这两个都对应内存地址)
隐含格式:MOVSB MOVSW MOVSD
功能:源→目标,即([SI])→ES:[DI],且自动修改SI、DI指针。
修改SI,DI指针,方向由DF决定,0就是正常,1就是反向;大小由MOVSX的X决定,如果是MOVSB使SI、DI各减1; MOVSW使SI、DI各减2; MOVSD使SI、DI各减4。
REP指令,为什么不用LOOP?实际上这两个感觉没啥区别,大概REP比较方便,不需要指定标签,当然也只针对一个命令。
例:把自AREA1开始的100个字数据传送到AREA2开始的区域中。
MOV AX,SEG(AREA1)//先把段基址以AX为介质,加载到DS,ES中
MOV DS,AX
MOV AX,SEG(AREA2)
MOV ES,AX
LEA SI,AREA1 //将段偏移初始化
LEA DI,AREA2
MOV CX,100 //循环次数
CLD //保证DF=0
REP MOVSW //重复移动,每次移动一个word
;100个字数据传送完毕后执行下一条指令
LODS、STOS示例
MOVS是直接把一个内存中数据送到另一个区域,一般搭配REP指令。
如果想要在中间对数据进行处理,就需要寄存器缓冲。先从SRC取出到寄存器,处理后再从寄存器送到DST,搭配LOOP指令。
取串指令 LODS
显式格式:LODS SRC
隐含格式:LODSB LODSW LODSD
功能:源→累加器,即([SI]) →AL(或AX、EAX),且自动修改SI指针。
说明:若DF=0,则LODSB(或LODSW、LODSD)使SI加1(或2、4);若DF=1,则LODSB(或LODSW、LODSD)使SI减1(或2、4)。若地址长度是32位的,则SI相应为ESI。
存串指令 STOS
显式格式:STOS DST
隐含格式:STOSB STOSW STOSD
功能:累加器→目标,即(AL(或AX、EAX))→ES:[DI],且自动修改DI指针。
说明:若DF=0,则STOSB(或STOSW、STOSD)使DI加1(或2、4);若DF=1,则STOSB(或STOSW、STOSD)使DI减1(或2、4)。若地址长度是32位的,则DI相应为EDI。
例:把自NUM1开始的未压缩BCD码字符串转换成ASCII码,并放到NUM2中,字符串长度为8字节。设DS、ES已按要求设置。
LEA SI,NUM1
LEA DI,NUM2
MOV CX,8 //循环8次
CLD //确保DF=0
LOP:
LODSB //取Byte到AL
OR AL,30H
STOSB //把AL送到DST
LOOP LOP