学习前言
刚刚从大学毕业,近来闲来无事,开始了机器学习的旅程,深度学习是机器学习的重要一环,其可以使得机器自我尝试,并通过结果进行学习。

在机器学习的过程中,我自网上了解到大神morvanzhou,一个从土木工程转向了计算机的“聪明绝顶”的、英语特好的男人。
morvanzhou的python个人主页,请有兴趣的同学关注大神morvanzhou的python教程。
一、简介
DDPG的全称是Deep Deterministic Policy Gradient。
其中:
Deep指的是使用DQN中的经验池和双网络结构来使得神经网络能够有效学习。
Deterministic Policy Gradient指的是在DDPG中,Actor不再输出每个动作的概率,而是一个具体的动作,其更有助于神经网络在连续动作空间中的学习。
DDPG是DQN、Policy Gradient、Actor Critic三者的结合,在连续空间中的动作预测能力大大增强。
如果互联网的广大朋友们希望学习DDPG,一定要明白DQN中Q现实和Q估计的关系,Actor Critic中Actor和Critic之间的关系,大家可以看我其它的博文,有对这两个关系详细的解释。
DQN
Actor Critic
二、实现过程拆解
本文使用了OpenAI Gym中的Pendulum-v0游戏来验证算法的实用性。
该环境是一个基于连续动作的环境,其具有一个连续动作。
钟摆以随机位置开始,目标是将其向上摆动,使其保持直立。
其不具有终止状态,所以本文设立了进行下一世代的最大STEPS。
其仅具有一个动作,最大值为2,最小值为-2,用于决定其顺时针或者逆时针的用力情况。
1、神经网络的构建
对于DDPG而言,其一共需要构建四个神经网络,分别是Actor的现实网络,Actor的估计网络,Critic的现实网络,Critic的估计网络。
a、Actor网络部分
在Actor部分,通过输入状态来得到获得一个指定的连续动作。
其建立的神经网络结构如下:
神经网络的输入量是s,指的是环境的状态。
神经网络的输出量是a,指的是一个连续动作的预测情况。
Actor的现实网络接受的输入是s_,代表的是下一环境的状态。
Actor的估计网络接受的输入是s,代表的是当前环境的状态。
对Actor网络进行训练的时候,实际上训练的是Actor的估计网络。其学习过程需要结合critic网络进行学习,其学习过程首先通过当前环境获得当前估计网络预测的动作,再对预测动作进行随机化,将随机化后的动作传入critic网络获得其评分,最后使其评分的value值最大。
Actor部分的神经网络构建函数如下,仅一层,输入值为状态,输出值为连续动作的预测。
# 建立一个actor的层,s为输入量,scope为名称,输出量为-a_bound~a_bound中间的数
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
# a为-1~1的a_dim维向量
return tf.multiply(a, self.a_bound, name='scaled_a')
如下为actor网络用于学习的损失函数,此处的q为critic网络的输出,在下文会提到:
# 最大化当前环境的value
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
在实际调用中,分别需要创立两个网络,分别是:
1、用于训练的action估计网络,与DQN的Q估计类似。
2、无需训练的action现实网络,与DQN的Q现实类似。
# 建立这一步环境和下一步环境的actor网络,
# 这一步环境的actor网络可训练,下一步不可。
# 分别获得两个环境的动作预测结果
with tf.variable_scope('Actor'):
# 共建立两个网络
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
b、Critic网络部分
在Critic部分,通过输入状态和当前的动作来得到该环境下,预测动作的评分。
神经网络的输入量是s,a,指的是环境的状态与对应的动作。
神经网络的输出量是q,指的是该环境下,对应动作的评分value值。
Critic的现实网络接受的输入是s_,a_,代表的是下一环境的状态与动作。
Critic的估计网络接受的输入是s,a,代表的是当前环境的状态与动作。
对Critic网络进行训练的时候,实际上训练的是Critic的估计网络。其学习过程与DQN的Q值更新类似,存在q_target和q_eval。q_target = self.R + GAMMA * q_,代表的是实际的评分。q_eval是当前环境的状态与动作得到的评分,通过训练可以使得估计值越来越接近实际。
如下为critic网络的构建函数,利用a与s共同获得评分value,指的是在环境s下,动作a的评分value值。
# 建立一个critic的层,s、a为输入量,scope为名称
# 该层的输出与状态s和方向a有关,代表的是当处于状态s的时候,选择方向a的价值value
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
return tf.layers.dense(net, 1, trainable=trainable)
如下为critic网络用于学习的损失函数,计算q_eval和q_target的误差平方和,使其最小化:
# q_target 为当前环境实际评分加上GAMMA*q_,与DQN中相同。
q_target = self.R + GAMMA * q_
# 计算均方误差
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
# 首先训练critic部分,var_list代表被训练的变量
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
在实际调用中,分别需要创立两个网络,分别是:
1、用于训练的critic预测网络,与DQN的Q估计类似。
2、无需训练的critic实际网络,与DQN的Q现实类似。
# 建立这一步环境和下一步环境的critic网络,
# 利用这一步环境和这一步的action获得这一步的value估计值
# 这一步环境的critic网络可训练,下一步不可。
# 分别获得两个环境和action的评分预测结果
with tf.variable_scope('Critic'):
# 共建立两个网络
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
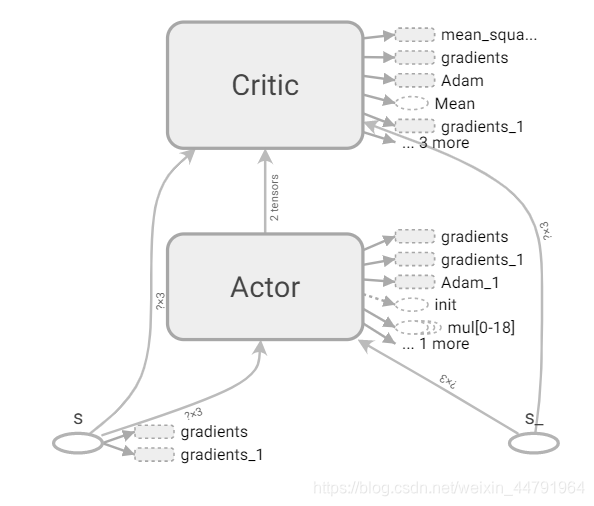
c、网络连接关系
网络的连接关系为:
2、动作的选择
Actor的预测网络可以直接输出预测动作,输入量为当前环境的状态。
def choose_action(self, s):
# 本例子进行的是一个连续值的预测,而非离散值。
# self.a是一个shape为[a_dim]的矩阵,a_dim此时为1,因此直接取出
return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
3、神经网络的学习
神经网络的学习过程是这样的:
1、进行现实网络与估计网络的软替换,由于现实网络是不会被优化器直接更新的,本文要将估计网络按照一定比例更新到现实网络中。
2、在记忆库中随机获得一定的记忆。
3、对Actor网络进行训练,实际上训练的是Actor的估计网络。其学习过程需要结合critic网络进行学习,其学习过程首先通过当前环境获得当前估计网络预测的动作,再对预测动作进行随机化,将随机化后的动作传入critic网络获得其评分,最后使其评分的value值最大。
4、对Critic网络进行训练,实际上训练的是Critic的估计网络。其学习过程与DQN的Q值更新类似,存在q_target和q_eval。q_target = self.R + GAMMA * q_,代表的是实际的评分。q_eval是当前环境的状态与动作得到的评分,通过训练可以使得估计值越来越接近实际。
def __init__(self, a_dim, s_dim, a_bound,GRAPH_GET =False):
# 记忆库的size
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
# pointer指向当前记忆所对应的位置,pointer%MEMORY_CAPACITY可以保证index始终在MEMORY_CAPACITY以内。
self.pointer = 0
# 创建会话
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
# 当前环境,下一步的环境
self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
# 评分
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
# 建立这一步环境和下一步环境的actor网络,
# 这一步环境的actor网络可训练,下一步不可。
# 分别获得两个环境的动作预测结果
with tf.variable_scope('Actor'):
# 共建立两个网络
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
# 建立这一步环境和下一步环境的critic网络,
# 利用这一步环境和这一步的action获得这一步的value估计值
# 这一步环境的critic网络可训练,下一步不可。
# 分别获得两个环境和action的评分预测结果
with tf.variable_scope('Critic'):
# 共建立两个网络
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
# 获得每个网络的collection,每个collection是内部变量的集合。
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# 网络参数的软替换,将当前环境的预测网络模型保留(1-Soft_replace_rate)到下一个环境的预测网络
self.soft_replace = [tf.assign(t, (1 - Soft_replace_rate) * t + Soft_replace_rate * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
# q_target 为当前环境实际评分加上GAMMA*q_,与DQN中相同。
q_target = self.R + GAMMA * q_
# 计算均方误差
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
# 首先训练critic部分,var_list代表被训练的变量
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
# 最大化当前环境的value
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
self.sess.run(tf.global_variables_initializer())
if GRAPH_GET == True:
tf.summary.FileWriter("logs/", self.sess.graph)
def learn(self):
# 每次学习的时候都进行一次软替换
# 将最新训练的结果赋予下一环境的预测组
self.sess.run(self.soft_replace)
# 随机获得一个索引
if self.pointer < MEMORY_CAPACITY:
indices = np.random.choice(self.pointer, size=BATCH_SIZE)
else:
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
# 取出记忆库中索引对应的一行
bt = self.memory[indices, :]
# 根据记忆前的排序将状态,动作,得分,下一步状态都取出。
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
三、具体实现代码
具体的实现代码仅一部分:
import tensorflow as tf
import numpy as np
import gym
MAX_EPISODES = 200 # 最大世代
MAX_EP_STEPS = 200 # 每一时代的最大步数
LR_A = 0.001 # actor学习率
LR_C = 0.002 # critic学习率
GAMMA = 0.9 # 评分衰减率
Soft_replace_rate = 0.01 # 软替换的比率
MEMORY_CAPACITY = 10000 # 记忆容器
BATCH_SIZE = 32 # 每一个batch的size
RENDER_THRESHOLD = -300 # 显示图像刷新的门限
RENDER = False
GRAPH = True #是否生成tensorboard的图像
env = gym.make('Pendulum-v0')
env = env.unwrapped
env.seed(1)
# 环境的维度
s_dim = env.observation_space.shape[0]
# ACTION的维度
a_dim = env.action_space.shape[0]
# ACTION的范围
a_bound = env.action_space.high
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound,GRAPH_GET =False):
# 记忆库的size
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
# pointer指向当前记忆所对应的位置,pointer%MEMORY_CAPACITY可以保证index始终在MEMORY_CAPACITY以内。
self.pointer = 0
# 创建会话
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
# 当前环境,下一步的环境
self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
# 评分
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
# 建立这一步环境和下一步环境的actor网络,
# 这一步环境的actor网络可训练,下一步不可。
# 分别获得两个环境的动作预测结果
with tf.variable_scope('Actor'):
# 共建立两个网络
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
# 建立这一步环境和下一步环境的critic网络,
# 利用这一步环境和这一步的action获得这一步的value估计值
# 这一步环境的critic网络可训练,下一步不可。
# 分别获得两个环境和action的评分预测结果
with tf.variable_scope('Critic'):
# 共建立两个网络
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
# 获得每个网络的collection,每个collection是内部变量的集合。
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# 网络参数的软替换,将当前环境的预测网络模型保留(1-Soft_replace_rate)到下一个环境的预测网络
self.soft_replace = [tf.assign(t, (1 - Soft_replace_rate) * t + Soft_replace_rate * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
# q_target 为当前环境实际评分加上GAMMA*q_,与DQN中相同。
q_target = self.R + GAMMA * q_
# 计算均方误差
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
# 首先训练critic部分,var_list代表被训练的变量
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
# 最大化当前环境的value
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
self.sess.run(tf.global_variables_initializer())
if GRAPH_GET == True:
tf.summary.FileWriter("logs/", self.sess.graph)
def choose_action(self, s):
# 本例子进行的是一个连续值的预测,而非离散值。
# self.a是一个shape为[a_dim]的矩阵,a_dim此时为1,因此直接取出
return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
def learn(self):
# 每次学习的时候都进行一次软替换
# 将最新训练的结果赋予下一环境的预测组
self.sess.run(self.soft_replace)
# 随机获得一个索引
if self.pointer < MEMORY_CAPACITY:
indices = np.random.choice(self.pointer, size=BATCH_SIZE)
else:
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
# 取出记忆库中索引对应的一行
bt = self.memory[indices, :]
# 根据记忆前的排序将状态,动作,得分,下一步状态都取出。
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
# 按照状态,动作,得分,下一步状态存入矩阵memory
transition = np.hstack((s, a, [r], s_))
# 状态是在不断替换的
index = self.pointer % MEMORY_CAPACITY
self.memory[index, :] = transition
self.pointer += 1
# 建立一个actor的层,s为输入量,scope为名称,输出量为-a_bound~a_bound中间的数
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
# a为-1~1的a_dim维向量
return tf.multiply(a, self.a_bound, name='scaled_a')
# 建立一个critic的层,s、a为输入量,scope为名称
# 该层的输出与状态s和方向a有关,代表的是当处于状态s的时候,选择方向a的价值value
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
return tf.layers.dense(net, 1, trainable=trainable)
# 输入量为动作的维度a_dim,环境状态的维度s_dim,动作的最大幅度a_bound
ddpg = DDPG(a_dim, s_dim, a_bound,GRAPH_GET=GRAPH)
# Explore_scope代表在记忆库不够强大时的探索范围
Explore_scope = 3
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
# 每满200步重新开始一个世代
for j in range(MAX_EP_STEPS):
# RENDER代表是否有图像
if RENDER:
env.render()
# 根据环境选择动作
a = ddpg.choose_action(s)
# 为动作选择增加随机性
a = np.clip(np.random.normal(a, Explore_scope), -2, 2)
# 获取下一步环境特点和分数
s_, r, done, info = env.step(a)
# 按照状态,动作,得分,下一步状态存入矩阵memory
ddpg.store_transition(s, a, r / 10, s_)
# 当记忆库足够大的时候减小Explore_scope值
if ddpg.pointer > MEMORY_CAPACITY:
Explore_scope *= .9995 # decay the action randomness
ddpg.learn()
# 环境更新
s = s_
# 加上当前得分
ep_reward += r
if j == MAX_EP_STEPS-1:
print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore_scope: %.2f' % Explore_scope, )
# 当得分大于RENDER_THRESHOLD时,开始显示画面
if ep_reward > RENDER_THRESHOLD:
RENDER = True
break
由于代码并不是自己写的,所以就不上传github了,不过还是欢迎大家关注我和我的github。
https://github.com/bubbliiiing/
希望得到朋友们的喜欢。
有不懂的朋友可以评论询问噢。