本次训练在centos7中完成,使用的训练脚本是
- https://github.com/Akegarasu/lora-scripts.git
- https://github.com/kohya-ss/sd-scripts.git
一、安装GPU环境
lora的训练环境对cuda版本要求比较高,在训练前我们需要确保我们已安装的cuda版本大于12或者等于11.8或者等于11.6
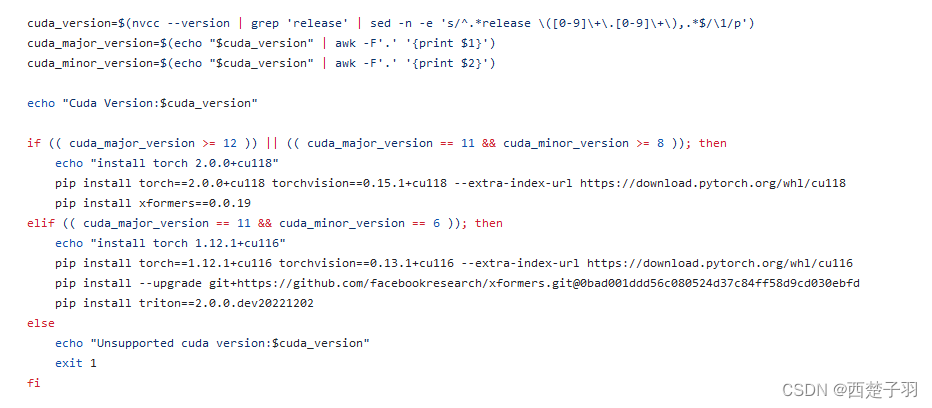
1.1 cuda版本号
查看cuda版本信息
[root@VM-0-7-centos ~]# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
1.2 驱动信息
查看安装的驱动信息
[root@VM-0-7-centos ~]# nvidia-smi
Sun Jun 25 20:39:56 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off| 00000000:00:08.0 Off | 0 |
| N/A 32C P8 9W / 70W| 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
如果没有输出以上信息先安装 CUDA 工具包
官网地址: https://developer.nvidia.com/cuda-downloads
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-rhel7-12-1-local-12.1.1_530.30.02-1.x86_64.rpm
sudo rpm -i cuda-repo-rhel7-12-1-local-12.1.1_530.30.02-1.x86_64.rpm
sudo yum clean all
sudo yum -y install nvidia-driver-latest-dkms
sudo yum -y install cuda
// 将CUDA的bin目录添加到PATH环境变量中
echo 'export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}' >> ~/.bashrc
source ~/.bashrc
二、准备图片素材
2.1 处理图片
我们利用stable diffusion webui来处理我们要训练的图片素材,/root/images/hutao/v2为源图片目录, /root/images/hutao/v2-5为处理后的图片存放位置
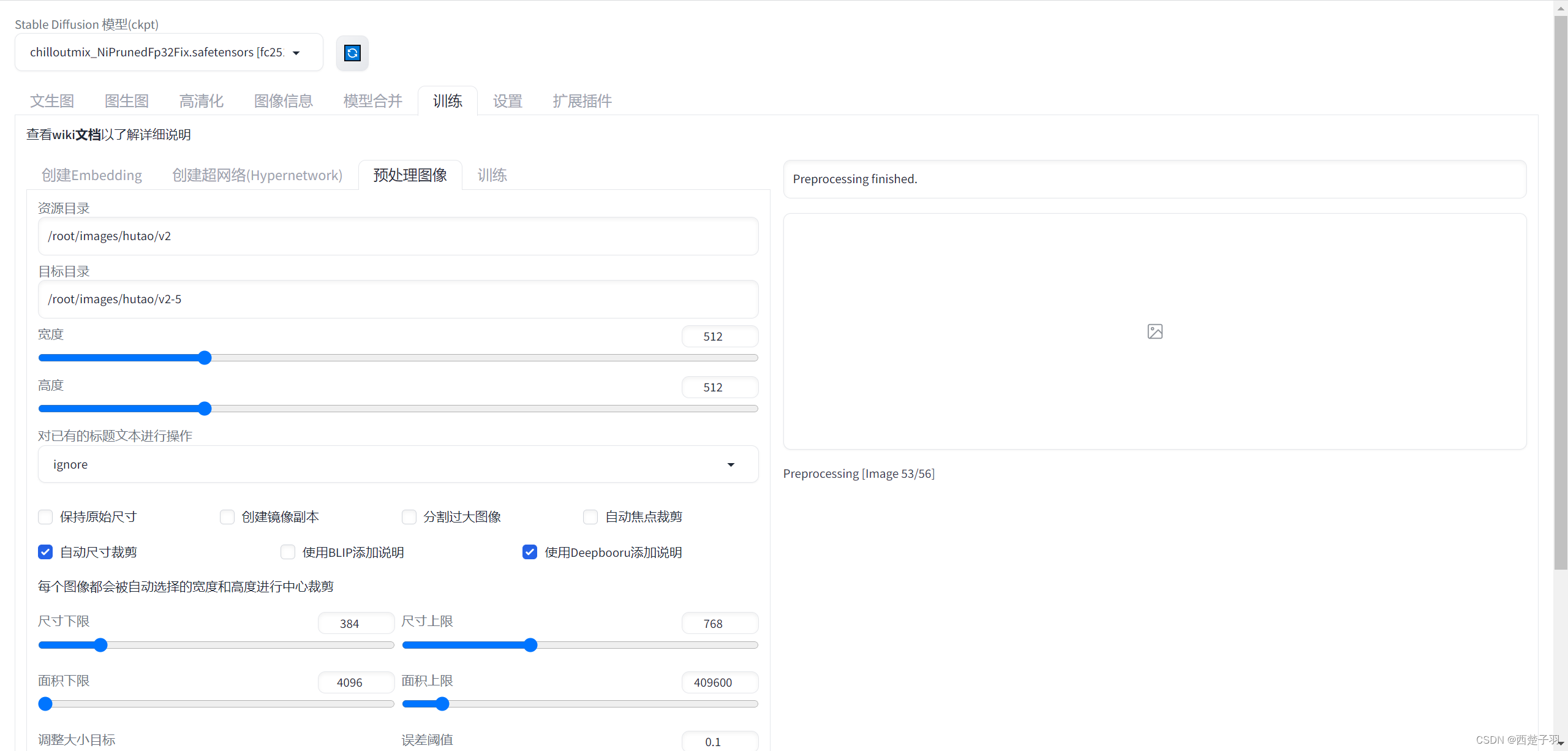
处理完之后每个图片会生成一个txt文件

2.2 处理tags
在stable diffusion webui中安装插件,对刚刚生成的图片tags进行处理
cd /root/stable-diffusion-webui/ && git clone https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor.git extensions/dataset-tag-editor
下载完之后重启webui界面

三、下载训练脚本
3.1 脚本下载
这里我们利用git命令下载源代码
// 下载lora-scripts
git clone https://github.com/Akegarasu/lora-scripts.git
// 进入文件夹
cd lora-scripts
// sd-scripts是个空文件夹删了重新下
rm -rf sd-scripts
// 下载sd-scripts
git clone https://github.com/kohya-ss/sd-scripts.git
新建文件夹存放我们刚刚处理的图片,文件叫名称为8_hutao,其中8代表每次训练过程中网络训练单张图片的次数,这个次数过大有可能导致训练时出现loss=nan的情况
3.2 安装训练环境
这里我修改了install.bash文件,创建的虚拟环境名为loraVenv
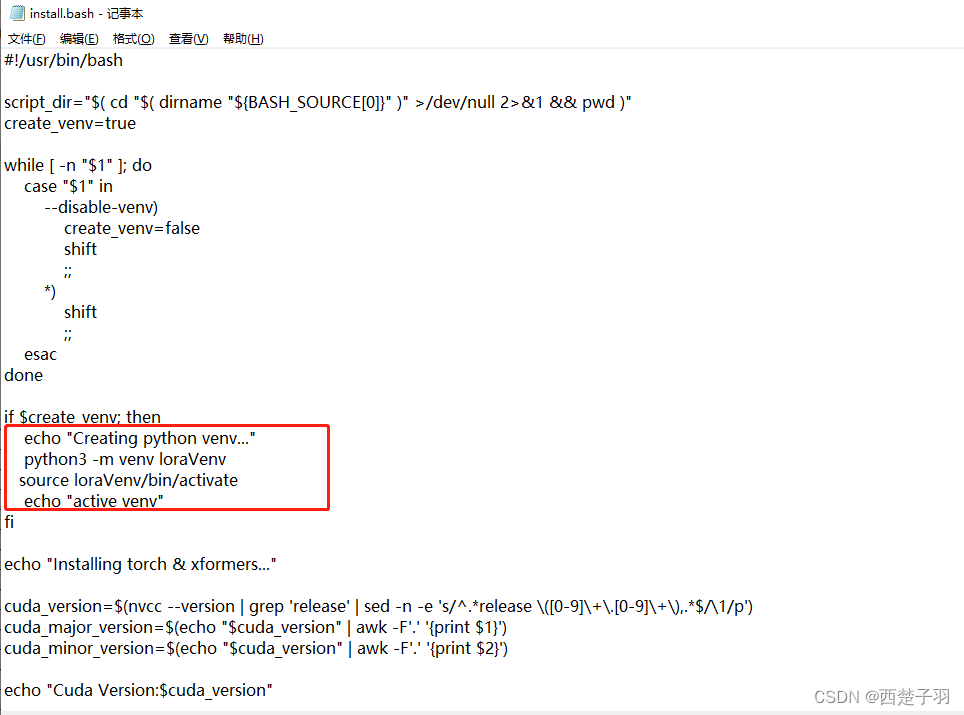
执行install.bash文件会安装我们训练时需要的环境
// 先授权否则可能提示没权限
chmod +x install.bash
// 安装相关依赖
./install.bash
命令运行完之后提示我

这里我们进入虚拟环境将版本更新到23.1.2
// 进入虚拟环境
[root@VM-0-7-centos lora-scripts]# source loraVenv/bin/activate
(loraVenv) [root@VM-0-7-centos lora-scripts]# pip install --upgrade pip
// 退出虚拟环境
(loraVenv) [root@VM-0-7-centos lora-scripts]# deactivate
3.3 下载底模
本次训练我们我们采用chilloutmix_NiPrunedFp32Fix.safetensors作为底模,这个模型主要用来画真人图像
cd /root/lora-scripts/sd-models
wget https://huggingface.co/naonovn/chilloutmix_NiPrunedFp32Fix/resolve/main/chilloutmix_NiPrunedFp32Fix.safetensors
3.4 修改训练参数
修改train.sh文件,我的训练素材在/root/images/train/100_hutao路径下,包含图片和tag
#!/bin/bash
# LoRA train script by @Akegarasu
# Train data path | 设置训练用模型、图片
pretrained_model="/root/lora-scripts/sd-models/chilloutmix_NiPrunedFp32Fix.safetensors" # base model path | 底模路径
is_v2_model=0 # SD2.0 model | SD2.0模型 2.0模型下 clip_skip 默认无效
parameterization=0 # parameterization | 参数化 本参数需要和 V2 参数同步使用 实验性功能
train_data_dir="/root/images/train" # train dataset path | 训练数据集路径
reg_data_dir="" # directory for regularization images | 正则化数据集路径,默认不使用正则化图像。
# Network settings | 网络设置
network_module="networks.lora" # 在这里将会设置训练的网络种类,默认为 networks.lora 也就是 LoRA 训练。如果你想训练 LyCORIS(LoCon、LoHa) 等,则修改这个值为 lycoris.kohya
network_weights="" # pretrained weights for LoRA network | 若需要从已有的 LoRA 模型上继续训练,请填写 LoRA 模型路径。
network_dim=64 # network dim | 常用 4~128,不是越大越好
network_alpha=32 # network alpha | 常用与 network_dim 相同的值或者采用较小的值,如 network_dim的一半 防止下溢。默认值为 1,使用较小的 alpha 需要提升学习率。
# Train related params | 训练相关参数
resolution="384,768" # image resolution w,h. 图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。
batch_size=1 # batch size
max_train_epoches=10 # max train epoches | 最大训练 epoch
save_every_n_epochs=2 # save every n epochs | 每 N 个 epoch 保存一次
train_unet_only=1 # train U-Net only | 仅训练 U-Net,开启这个会牺牲效果大幅减少显存使用。6G显存可以开启
train_text_encoder_only=0 # train Text Encoder only | 仅训练 文本编码器
stop_text_encoder_training=0 # stop text encoder training | 在第N步时停止训练文本编码器
noise_offset="0" # noise offset | 在训练中添加噪声偏移来改良生成非常暗或者非常亮的图像,如果启用,推荐参数为0.1
keep_tokens=0 # keep heading N tokens when shuffling caption tokens | 在随机打乱 tokens 时,保留前 N 个不变。
min_snr_gamma=0 # minimum signal-to-noise ratio (SNR) value for gamma-ray | 伽马射线事件的最小信噪比(SNR)值 默认为 0
# Learning rate | 学习率
lr="1e-4"
unet_lr="1e-4"
text_encoder_lr="1e-5"
lr_scheduler="cosine_with_restarts" # "linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup", "adafactor"
lr_warmup_steps=0 # warmup steps | 学习率预热步数,lr_scheduler 为 constant 或 adafactor 时该值需要设为0。
lr_restart_cycles=1 # cosine_with_restarts restart cycles | 余弦退火重启次数,仅在 lr_scheduler 为 cosine_with_restarts 时起效。
# Output settings | 输出设置
output_name="hutao_v1" # output model name | 模型保存名称
save_model_as="safetensors" # model save ext | 模型保存格式 ckpt, pt, safetensors
# Resume training state | 恢复训练设置
save_state=0 # save state | 保存训练状态 名称类似于 <output_name>-??????-state ?????? 表示 epoch 数
resume="" # resume from state | 从某个状态文件夹中恢复训练 需配合上方参数同时使用 由于规范文件限制 epoch 数和全局步数不会保存 即使恢复时它们也从 1 开始 与 network_weights 的具体实现操作并不一致
# 其他设置
min_bucket_reso=256 # arb min resolution | arb 最小分辨率
max_bucket_reso=1024 # arb max resolution | arb 最大分辨率
persistent_data_loader_workers=0 # persistent dataloader workers | 容易爆内存,保留加载训练集的worker,减少每个 epoch 之间的停顿
clip_skip=2 # clip skip | 玄学 一般用 2
# 优化器设置
optimizer_type="AdamW8bit" # Optimizer type | 优化器类型 默认为 AdamW8bit,可选:AdamW AdamW8bit Lion SGDNesterov SGDNesterov8bit DAdaptation AdaFactor
# LyCORIS 训练设置
algo="lora" # LyCORIS network algo | LyCORIS 网络算法 可选 lora、loha、lokr、ia3、dylora。lora即为locon
conv_dim=4 # conv dim | 类似于 network_dim,推荐为 4
conv_alpha=4 # conv alpha | 类似于 network_alpha,可以采用与 conv_dim 一致或者更小的值
dropout="0" # dropout | dropout 概率, 0 为不使用 dropout, 越大则 dropout 越多,推荐 0~0.5, LoHa/LoKr/(IA)^3暂时不支持
# 远程记录设置
use_wandb=0 # use_wandb | 启用wandb远程记录功能
wandb_api_key="" # wandb_api_key | API,通过https://wandb.ai/authorize获取
log_tracker_name="" # log_tracker_name | wandb项目名称,留空则为"network_train"
# ============= DO NOT MODIFY CONTENTS BELOW | 请勿修改下方内容 =====================
export HF_HOME="huggingface"
export TF_CPP_MIN_LOG_LEVEL=3
extArgs=()
launchArgs=()
if [[ $multi_gpu == 1 ]]; then launchArgs+=("--multi_gpu"); fi
if [[ $is_v2_model == 1 ]]; then
extArgs+=("--v2");
else
extArgs+=("--clip_skip $clip_skip");
fi
if [[ $parameterization == 1 ]]; then extArgs+=("--v_parameterization"); fi
if [[ $train_unet_only == 1 ]]; then extArgs+=("--network_train_unet_only"); fi
if [[ $train_text_encoder_only == 1 ]]; then extArgs+=("--network_train_text_encoder_only"); fi
if [[ $network_weights ]]; then extArgs+=("--network_weights $network_weights"); fi
if [[ $reg_data_dir ]]; then extArgs+=("--reg_data_dir $reg_data_dir"); fi
if [[ $optimizer_type ]]; then extArgs+=("--optimizer_type $optimizer_type"); fi
if [[ $optimizer_type == "DAdaptation" ]]; then extArgs+=("--optimizer_args decouple=True"); fi
if [[ $save_state == 1 ]]; then extArgs+=("--save_state"); fi
if [[ $resume ]]; then extArgs+=("--resume $resume"); fi
if [[ $persistent_data_loader_workers == 1 ]]; then extArgs+=("--persistent_data_loader_workers"); fi
if [[ $network_module == "lycoris.kohya" ]]; then
extArgs+=("--network_args conv_dim=$conv_dim conv_alpha=$conv_alpha algo=$algo dropout=$dropout")
fi
if [[ $stop_text_encoder_training -ne 0 ]]; then extArgs+=("--stop_text_encoder_training $stop_text_encoder_training"); fi
if [[ $noise_offset != "0" ]]; then extArgs+=("--noise_offset $noise_offset"); fi
if [[ $min_snr_gamma -ne 0 ]]; then extArgs+=("--min_snr_gamma $min_snr_gamma"); fi
if [[ $use_wandb == 1 ]]; then
extArgs+=("--log_with=all")
else
extArgs+=("--log_with=tensorboard")
fi
if [[ $wandb_api_key ]]; then extArgs+=("--wandb_api_key $wandb_api_key"); fi
if [[ $log_tracker_name ]]; then extArgs+=("--log_tracker_name $log_tracker_name"); fi
python -m accelerate.commands.launch ${launchArgs[@]} --num_cpu_threads_per_process=8 "./sd-scripts/train_network.py" \
--enable_bucket \
--pretrained_model_name_or_path=$pretrained_model \
--train_data_dir=$train_data_dir \
--output_dir="./output" \
--logging_dir="./logs" \
--log_prefix=$output_name \
--resolution=$resolution \
--network_module=$network_module \
--max_train_epochs=$max_train_epoches \
--learning_rate=$lr \
--unet_lr=$unet_lr \
--text_encoder_lr=$text_encoder_lr \
--lr_scheduler=$lr_scheduler \
--lr_warmup_steps=$lr_warmup_steps \
--lr_scheduler_num_cycles=$lr_restart_cycles \
--network_dim=$network_dim \
--network_alpha=$network_alpha \
--output_name=$output_name \
--train_batch_size=$batch_size \
--save_every_n_epochs=$save_every_n_epochs \
--mixed_precision="fp16" \
--save_precision="fp16" \
--seed="1337" \
--cache_latents \
--prior_loss_weight=1 \
--max_token_length=225 \
--caption_extension=".txt" \
--save_model_as=$save_model_as \
--min_bucket_reso=$min_bucket_reso \
--max_bucket_reso=$max_bucket_reso \
--keep_tokens=$keep_tokens \
--xformers --shuffle_caption ${extArgs[@]}
3.5 开始训练
直接运行train.sh文件,如果环境版本不对有可能报错
// 先授权否则可能提示没权限
[root@VM-0-7-centos lora-scripts]# chmod +x train.sh
// 进入虚拟环境
[root@VM-0-7-centos lora-scripts]# source loraVenv/bin/activate
// 开始
(loraVenv) [root@VM-0-7-centos lora-scripts]#./train.sh
慢慢等就行了
 训练完成
训练完成
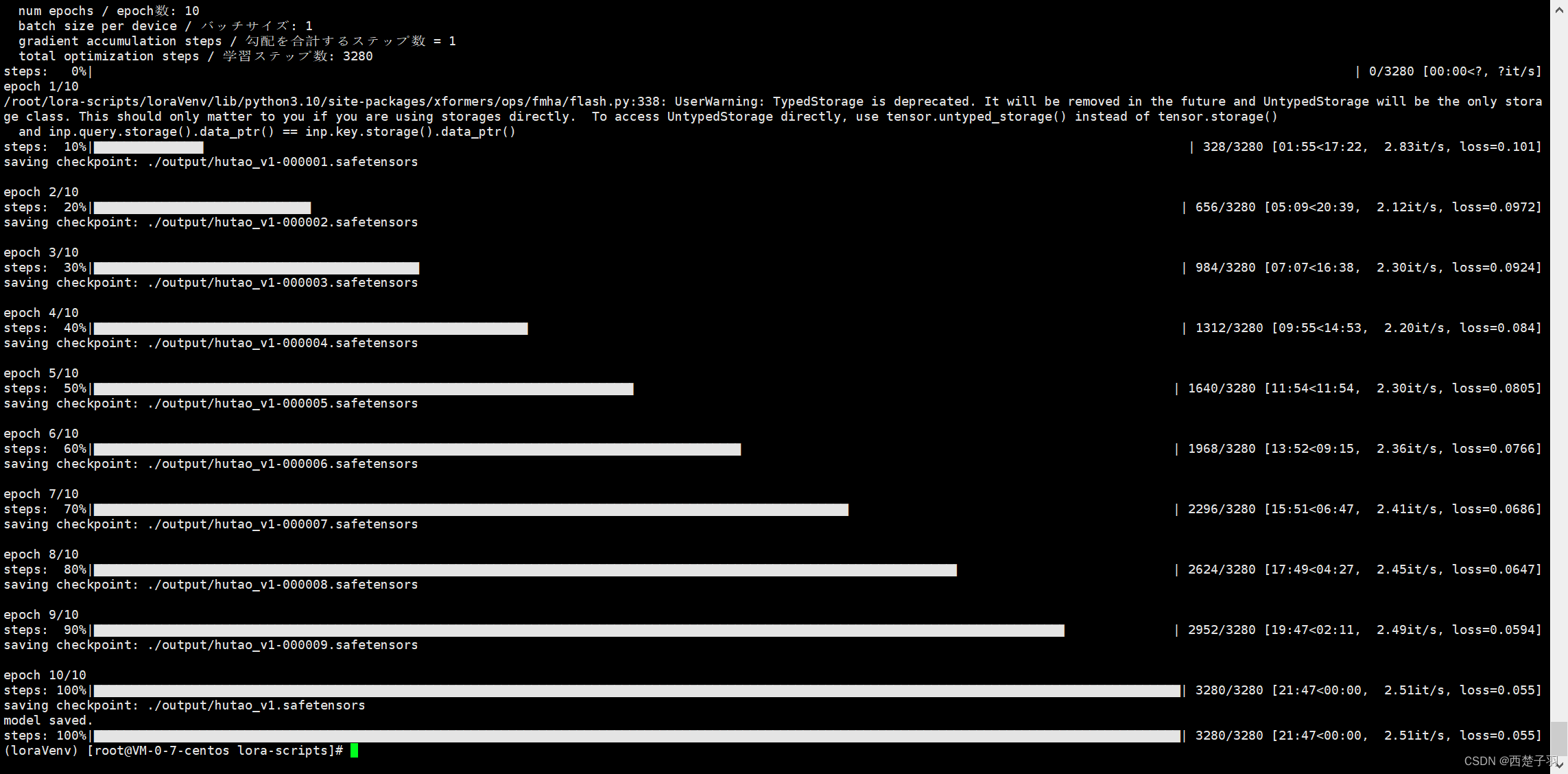
四、模型对比
我们将生成的10个模型文件放到/root/stable-diffusion-webui/models/Lora路径下,并且命名分别为000000、000001、000002…数字递增,在图片提示词的中填写hutao_v1-num:str,其中num代表模型,strt代表权重,X轴和Y轴都选择Prompt S/R(提示词搜索/替换)然后填入对应的值, 最后生成图片就能看到一张xy轴的表了

五、问题总结
- 我的cuda是12.1的版本,在执行./train.sh的时候出现了以下错误
CUDA SETUP: CUDA runtime path found: /usr/local/cuda/lib64/libcudart.so
CUDA exception! Error code: no CUDA-capable device is detected
CUDA exception! Error code: initialization error
CUDA SETUP: Highest compute capability among GPUs detected: None
CUDA SETUP: Detected CUDA version 121
CUDA SETUP: TODO: compile library for specific version: libbitsandbytes_cuda121_nocublaslt.so
CUDA SETUP: Defaulting to libbitsandbytes.so…
CUDA SETUP: CUDA detection failed. Either CUDA driver not installed, CUDA not installed, or you have multiple conflicting CUDA libraries!
CUDA SETUP: If you compiled from source, try again with make CUDA_VERSION=DETECTED_CUDA_VERSION for example, make CUDA_VERSION=113.
这个可能是bitsandbytes的版本问题,我们可以在kohya-ss/sd-scripts项目的Issues中找到相关解决方案,安装最新版本的bitsandbytes(requirements.txt文件中指定的版本是0.35.0)
// 进入虚拟环境
[root@VM-0-7-centos lora-scripts]# source loraVenv/bin/activate
// 卸载0.35.0版本
(loraVenv) [root@VM-0-7-centos lora-scripts]# pip uninstall bitsandbytes
// 安装最新版本
(loraVenv) [root@VM-0-7-centos lora-scripts]# pip install bitsandbytes
- 安装最新的bitsandbytes版本之后出现 ImportError: /lib64/libz.so.1: version `ZLIB_1.2.9’ not found 错误
解决方案:下载zlib-1.2.9版本
zlib-1.2.9下载地址:http://www.zlib.net/fossils/
// 下载压缩包
[root@VM-0-7-centos ~]# wget http://www.zlib.net/fossils/zlib-1.2.9.tar.gz
// 解压缩文件
[root@VM-0-7-centos ~]# tar -xvf zlib-1.2.9.tar.gz && cd zlib-1.2.9
// 编译安装
[root@VM-0-7-centos zlib-1.2.9]# ./configure && make && make install
// 删除旧的软连接 这里/lib64可以修改为自己的路径
[root@VM-0-7-centos zlib-1.2.9]# rm -rf /lib64/libz.so.1
// 创建新的软连接
[root@VM-0-7-centos zlib-1.2.9]# ln -s /usr/local/lib/libz.so.1.2.9 /lib64/libz.so.1
// 查看创建的软连接
[root@VM-0-7-centos zlib-1.2.9]# ls -l /lib64/libz.so.1
lrwxrwxrwx 1 root root 28 Jun 27 11:36 /lib64/libz.so.1 -> /usr/local/lib/libz.so.1.2.9
- 出现 /lib64/libstdc++.so.6: version `CXXABI_1.3.9’ not found 错误
解决方案
// 下载6.0.26版本
[root@VM-0-7-centos ~]# wget https://cdn.frostbelt.cn/software/libstdc%2B%2B.so.6.0.26
// 将下载的文件复制到lib64目录下
[root@VM-0-7-centos ~]# cp libstdc++.so.6.0.26 /usr/lib64/
[root@VM-0-7-centos ~]# cd /usr/lib64/
// 删除旧的软连接
[root@VM-0-7-centos ~]# rm -rf libstdc++.so.6
// 创建软连接
[root@VM-0-7-centos ~]# ln -s libstdc++.so.6.0.26 libstdc++.so.6
// 查看软连接是否创建成功
[root@VM-0-7-centos ~]# ls -l /usr/lib64/libstdc++.so.6
lrwxrwxrwx 1 root root 19 Jun 27 14:59 /usr/lib64/libstdc++.so.6 -> libstdc++.so.6.0.26
// 可以看到已经有1.3.9版本了
[root@VM-0-7-centos ~]# strings /usr/lib64/libstdc++.so.6 | grep 'CXXABI'
CXXABI_1.3
CXXABI_1.3.1
CXXABI_1.3.2
CXXABI_1.3.3
CXXABI_1.3.4
CXXABI_1.3.5
CXXABI_1.3.6
CXXABI_1.3.7
CXXABI_1.3.8
CXXABI_1.3.9
CXXABI_1.3.10
CXXABI_1.3.11
CXXABI_1.3.12
CXXABI_TM_1
CXXABI_FLOAT128
CXXABI_1.3
CXXABI_1.3.11
CXXABI_1.3.2
CXXABI_1.3.6
CXXABI_FLOAT128
CXXABI_1.3.12
CXXABI_1.3.9
CXXABI_1.3.1
CXXABI_1.3.5
CXXABI_1.3.8
CXXABI_1.3.4
CXXABI_TM_1
CXXABI_1.3.7
CXXABI_1.3.10
CXXABI_1.3.3
如果我们在虚拟环境loraVenv中不能正确输出ls -l /usr/lib64/libstdc++.so.6,那么按照刚刚的步骤重新创建软连接
4 在训练的过程中出现loss=nan的情况,有可能是学习率过高或者学习次数太多
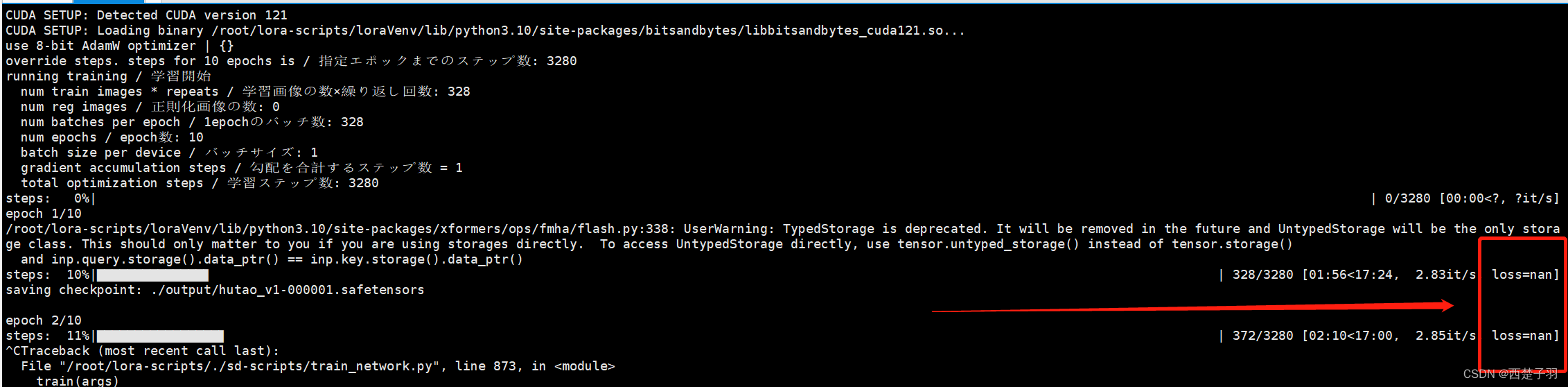
将学习率调小或者减少学习次数
# Learning rate | 学习率
lr="5e-5"
unet_lr="5e-5"
text_encoder_lr="6e-6"