目录
四、Kubernetes蓝绿部署,金丝雀发布
1.概述
2.金丝雀发布过程
3.蓝绿发布
五、Service代理:kube-proxy组件详解
1.kube-proxy组件介绍
2.kube-proxy工作模式
四、Kubernetes蓝绿部署,金丝雀发布
1.概述
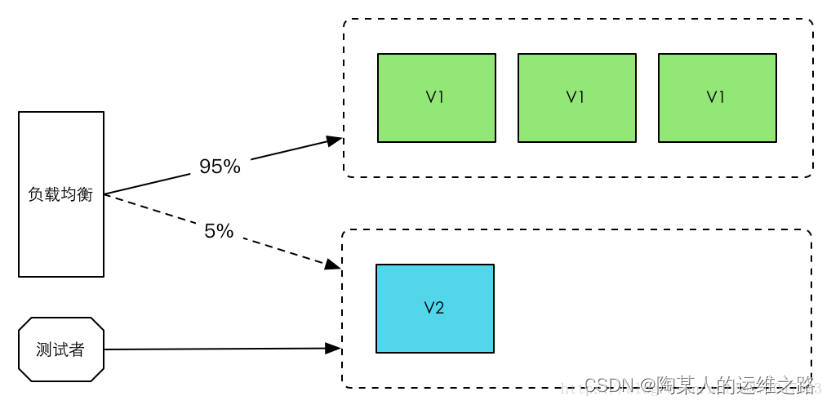
金丝雀发布(又称灰度发布、灰度更新):
金丝雀发布一般是先发1台机器,或者一个小比例,例如2%的服务器,主要做流量验证用,也称为金丝雀 (Canary) 测试,国内常称灰度测试。以前旷工下矿前,会先放一只金丝雀进去用于探测洞里是否有有毒气体,看金丝雀能否活下来,金丝雀发布由此得名。简单的金丝雀测试一般通过手工测试验证,复杂的金丝雀测试需要比较完善的监控基础设施配合,通过监控指标反馈,观察金丝雀的健康状况,作为后续发布或回退的依据。如果金丝测试通过,则把剩余的 V1 版本全部升级为 V2 版本。如果金丝雀测试失败,则直接回退金丝雀,发布失败。
蓝绿部署:
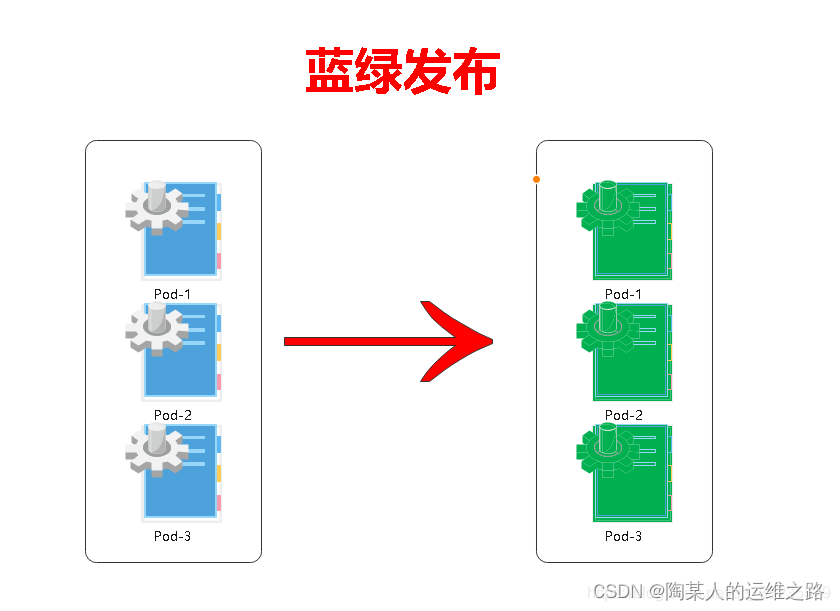
一些应用程序只需要部署一个新版本,并需要立即切到这个版本。因此,我们需要执行蓝/绿部署。在进行蓝/绿部署时,应用程序的一个新副本(绿)将与现有版本(蓝)一起部署。然后更新应用程序的入口/路由器以切换到新版本(绿)。然后,您需要等待旧(蓝)版本来完成所有发送给它的请求,但是大多数情况下,应用程序的流量将一次更改为新版本;Kubernetes不支持内置的蓝/绿部署。目前最好的方式是创建新的部署,然后更新应用程序的服务(如service)以指向新的部署;蓝绿部署是不停老版本,部署新版本然后进行测试,确认OK后将流量逐步切到新版本。蓝绿部署无需停机,并且风险较小。
2.金丝雀发布过程
通过deployement部署三个基于镜像myapp:v1的pod
[root@hd1 ~]# vim deploy-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-v1
spec:
replicas: 3
selector:
matchLabels:
app: myapp
version: v1
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
app: myapp
version: v1
spec:
containers:
- name: myapp
image: janakiramm/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
执行资源清单文件
[root@hd1 ~]# kubectl apply -f deploy-demo.yaml
查看pod如下:
[root@hd1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-v1-67fd9fc9c8-5ztqt 1/1 Running 0 4m14s
myapp-v1-67fd9fc9c8-9j8gq 1/1 Running 0 4m14s
myapp-v1-67fd9fc9c8-kz5s4 1/1 Running 0 4m14s
设置pod的service代理服务,并暴露到集群外部
[root@hd1 ~]# vim service_myapp.yaml
apiVersion: v1
kind: Service
metadata:
name: service-myapp
labels:
run: service-myapp
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30380
selector:
app: myapp
创建service资源
[root@hd1 ~]# kubectl apply -f service_myapp.yaml
查看资源
[root@hd1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-myapp NodePort 10.106.161.220 <none> 80:30380/TCP 10s
访问pod资源
[root@hd1 ~]# curl 192.168.0.11:30380| grep application
<h1>Welcome to V1 of the web application</h1>
上述显示结果表示此时的版本是v1版本
开启一个新的shell窗口,执行下面的命令进行观察
[root@hd1 ~]# kubectl get pod -w
在老的shell窗口通过金丝雀发布更新到v2版本:
修改deploy-demo.yaml文件将镜像的v1改成v2
[root@hd1 ~]# vi deploy-demo.yaml |grep image
image: janakiramm/myapp:v2
执行金丝雀发布把myapp这个容器的镜像更新到myapp:v2版本,更新镜像之后,创建一个新的pod就立即暂停,这就是我们说的金丝雀发布
root@hd1 ~]# kubectl apply -f deploy-demo.yaml && kubectl rollout pause deployment myapp-v1
此时查看pod的变化,发现有老pod和新pod一起运行

外面的用户访问pod资源的时候,其实有两个不同的版本
[root@hd1 ~]# curl 192.168.0.11:30380| grep application
<h1>Welcome to V1 of the web application</h1>
[root@hd1 ~]# curl 192.168.0.11:30380| grep application
<h1>Welcome to V1 of the web application</h1>
[root@hd1 ~]# curl 192.168.0.11:30380| grep application
<h1>Welcome to vNext of the web application</h1>
[root@hd1 ~]# curl 192.168.0.11:30380| grep application
<h1>Welcome to vNext of the web application</h1>
测试一段时间后,如果没有问题,继续升级
[root@hd1 ~]# kubectl rollout resume deployment myapp-v1
再次用curl命令发现全部都改成了v2版本
[root@hd1 ~]# curl 192.168.0.11:30380| grep application|grep application
<h1>Welcome to vNext of the web application</h1>
3.蓝绿发布
准备两套deployment 资源清单yaml文件
[root@hd1 ~]# vim myapp-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-v1
spec:
replicas: 2
selector:
matchLabels:
app: myapp
version: v1
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
app: myapp
version: v1
spec:
containers:
- name: myapp
image: janakiramm/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
[root@hd1 ~]# vim myapp-v2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-v2
spec:
replicas: 2
selector:
matchLabels:
app: myapp
version: v2
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
app: myapp
version: v2
spec:
containers:
- name: myapp
image: janakiramm/myapp:v2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
执行v1和v2的资源清单,蓝版本和绿版本同时运行
[root@hd1 ~]# kubectl apply -f myapp-v2.yaml
[root@hd1 ~]# kubectl apply -f myapp-v1.yaml
此时service 负责为v1版本蓝版本服务
[root@hd1 ~]# vim service_myapp.yaml
apiVersion: v1
kind: Service
metadata:
name: service-myapp
labels:
run: service-myapp
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30380
selector:
version: v1
执行service的资源清单
[root@hd1 ~]# kubectl apply -f service_myapp.yaml
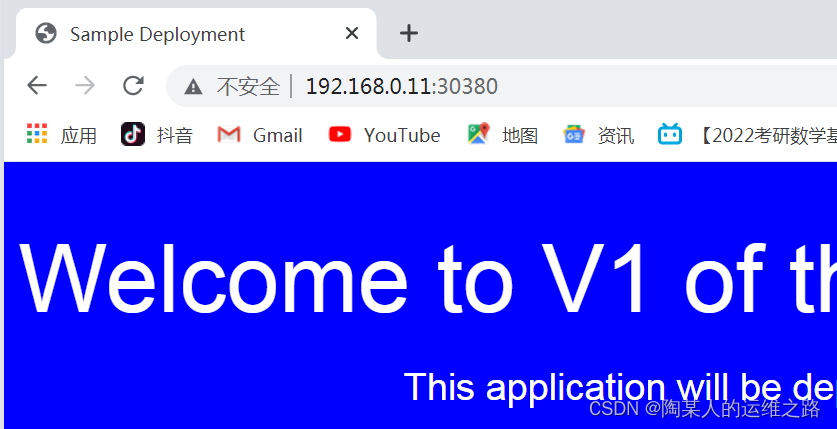
访问192.168.0.11:30380查看是否为蓝色
修改service_myapp.yaml如下
[root@hd1 ~]# vim service_myapp.yaml
apiVersion: v1
kind: Service
metadata:
name: service-myapp
labels:
run: service-myapp
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30380
selector:
version: v2
重新执行service的资源清单
[root@hd1 ~]# kubectl apply -f service_myapp.yaml
此时再次查看192.168.0.11:30380是否为绿色

五、Service代理:kube-proxy组件详解
1.kube-proxy组件介绍
Kubernetes service只是把应用对外提供服务的方式做了抽象,真正的应用跑在Pod中的container里,我们的请求转到kubernetes nodes对应的nodePort上,那么nodePort上的请求是如何进一步转到提供后台服务的Pod的呢? 就是通过kube-proxy实现的:
kube-proxy部署在k8s的每一个Node节点上,是Kubernetes的核心组件,我们创建一个 service 的时候,kube-proxy 会在iptables中追加一些规则,为我们实现路由与负载均衡的功能。
在k8s1.8之前,kube-proxy默认使用的是iptables模式,通过各个node节点上的iptables规则来实现service的负载均衡,但是随着service数量的增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降。
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP。kube-proxy的作用主要是负责service的实现,
具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
1、kube-proxy其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。
2、kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也可以称为是Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。
2.kube-proxy工作模式
1、iptables方式:
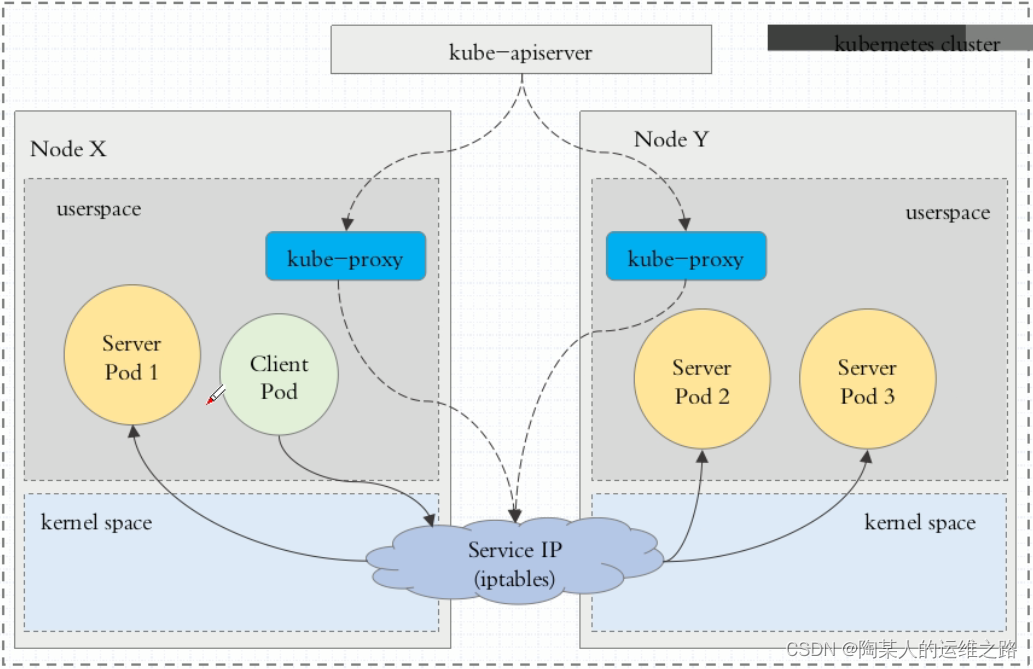
客户端IP请求时,直接请求本地内核service ip,根据iptables的规则直接将请求转发到到各pod上,因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折
iptables代理模式由Kubernetes 1.1版本引入,自1.2版本开始成为默认类型。
2、ipvs方式:

Kubernetes自1.9-alpha版本引入了ipvs代理模式,自1.11版本开始成为默认设置。客户端
请求时到达内核空间时,根据ipvs的规则直接分发到各pod上。kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
rr:轮询调度
lc:最小连接数
dh:目标哈希
sh:源哈希
sed:最短期望延迟
nq:不排队调度
如果某个服务后端pod发生变化,标签选择器适应的pod又多一个,适应的信息会立即反映到apiserver上,而kube-proxy一定可以watch到etc中的信息变化,而将它立即转为ipvs或者iptables中的规则,这一切都是动态和实时的,删除一个pod也是同样的原理。如图:

注:
以上不论哪种,kube-proxy都通过watch的方式监控着apiserver写入etcd中关于Pod的最新状态信息,它一旦检查到一个Pod资源被删除了或新建了,它将立即将这些变化,反应在iptables 或 ipvs规则中,以便iptables和ipvs在调度Clinet Pod请求到Server Pod时,不会出现Server Pod不存在的情况。自k8s1.11以后,service默认使用ipvs规则,若ipvs没有被激活,则降级使用iptables规则.