论文标题:
Riddle of Wordle: Mining the Secret of Number Scores & Solution Words
Wordle之谜:挖掘数字得分和解字词的秘密
前言
从论文浅整理一下思路,纯在想到什么说什么。没见过文章可能会有点懵。论文的原文大概在O奖论文集里能翻到。
老规矩我依旧是队伍中的编程手,比赛时候没怎么碰过文章。
我们是中文写完后整体翻译的英文,以下部分内容来自论文中文版的ctrl+cv。
排版很乱。
一、题目重述
Homer是棒球运动中的术语,是非正式的美式英语单词。令人惊讶的是,Homer(本垒打)在剑桥词典网站的搜索次数超过79000次,在5月5日这一天内被搜索65401次。就这样,Homer成为《剑桥词典》的2022年度词汇。可能你会好奇其中的原因,这就要从海外非常火的一款猜词游戏Wordle说起了。在2022年,在线益智游戏Wordle在社交媒体刷屏。而Wordle那天的答案是Homer,这难倒了不熟悉这个单词的非美国用户。
Wordle是目前《纽约时报》每日提供的一个热门谜题。Wordle的受欢迎程度不断提高,目前已有60多种语言版本。玩家可以选择的模式有“常规模式”或"困难模式"。玩家试图在六次或更少的尝试中猜测一个五字词来解决这个难题,每次猜测都会得到反馈,方块的颜色会发生变化(绿色、黄色、灰色)。注意:每个猜测都必须是英语中的一个实词。不被比赛认可为文字的猜测是不被允许的。

拟解决的问题
- 开发一个模型来解释报道结果的数量变化,并创建2023年3月1日报告结果的数量预测区间。分析单词的属性对玩家的模式选择的影响程度。
- 开发一个模型来预测报告结果的分布。分析模型和预测存在的不确定性因素。
- 开发一个模型来分类解答词难度。识别与每个分类相关联单词的属性。
- 描述数据集的其他有趣特征。
(大致能看出来,三个问题,最后一个语文建模。后来我们发现把前三个问踩过的坑扔到第四问,就够了。)
我们的工作:
我们共提出了三个模型来挖掘报告结果数据的信息。
本文的其余部分组织如下。第二部分介绍了本文的前提假设与合理解释。第三节提及了文中使用的公式中的常用变量。第四节进行了建模前对的数据预处理工作。第五节建立了报告数量区间预测模型,并探索了单词属性与模式选择的关系。第六节建立了报告结果分布预测模型。第七节建立了词汇难度分类模型。第八节继续探索数据集的有趣特征。第九节和第十节分别对模型的灵敏度进行分析,进一步评估模型的优缺点。最后,第十一节给出了结论。
二、模型和计算
1.数据预处理
这套数据有几个词不是五个字母,但因为都是发生过的统计,我们直接翻到了过去这些期词汇的统计修改了一下。还有529号study的结果目测就有问题,我们取前后几天的均值修正了一下。这里怎么处理问题都不大。
2.报告数量区间预测模型
**我们希望在已有数据的基础上建立一种数学模型,用于描述Twitter上报告结果数量随时间变化的过程和预测未来一定时间内的热度,且模型对于变化过程具有解释性。该问题是近年来常受到讨论的热度预测问题。
通过查阅文献[4],我们得知业界目前两类常用的热度预测算法,包括基于节点行为动力学的时序模型和深度学习类方法。但是它们并不适用于本文所研究的情形。主要因为如下两个原因:
- 现有数据集中并不包含报告人是谁、所有时间内总共有多少人等具体信息,基于该数据集无法建立节点模型;
- 深度学习等技术不具有良好的可解释性,并且大都需要更多的训练数据才能达到较好的预测效果。
因此,我们从统计学角度出发,基于非齐次泊松过程和3阶高斯回归(3rd-order gaussian regression)建立了wordle报告数量预测模型。**
(这一问从建立模型到计算求解我几乎全程没参与,因为我没学过信息论,从这个模型提出开始我就不懂了。我贴一些原文的内容和记忆中当时的一些处理办法。)
一眼需要时间预测模型。当时建模队友恰好在复习信息论(和开学考期末和解),这个趋势画出来特别像对数正态分布的曲线。刚开始的时候上涨很快,后期逐渐下降,最后能剩下的都是坚持在玩的老玩家。当时建模哥觉得这个很符合实际,并且会挺新颖的,就顺着这个研究下去了。后来发现有地方解释不了,报告数量的分布在时间上并非均匀的,而对数正态分布没有考虑时间因素。卡在这里很久,一度考虑过要不要换一个预测模型。后来还是顺着拟合的路走下去了。
基于高斯回归的趋势预测模型
在本数据集中,报告数量的时间序列存在明显的趋势迹象。我们尝试了多种回归算法对报告数量随时间的变化趋势进行拟合,其中效果最好的是3阶高斯回归。
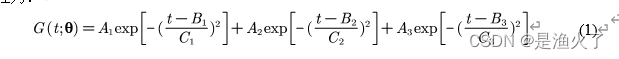
(如果我没记错,这个是从matlab的cftool里挨个试出来的。就是简单的拟合了一下,我们也没有做过多的说明)
然后考虑预测区间,也就是每天的随机波动。
基于非齐次泊松过程的报告数量预测模型
泊松分布描述了在事件发生速率为常数的条件下,一段时间内一定数量事件发生的概率,因此可以描述一天内上传的一定数量的报告的概率。我们假设每一天的报告数量均服从于泊松分布,则这些泊松分布在时间上组成了一个非齐次泊松过程,即到达强度随时间变化的泊松过程。

真的按照这个公式来计算区间,会发现预测的效果没有那么理想。后期较为平稳的部分有一些地方反倒波动比较大,出现非常离谱的尖刺。为了消掉后期区间的尖刺,需要进行一定的比例放缩,也就是基于热度松弛函数的随机过程修正部分。这部分先找到了一个可以消掉尖刺的函数,然后根据这个函数去找适合它的定义,还真找到了这个热度松弛现象。

(我个人觉得这一问模型套模型的解法,整个论文写下来,松弛函数这里显得很秀。其实只是为了得到一个比较好看的预测结果凑出来的罢了)
最后我们预测出来的大致是这样。上面松弛函数乘进去直接让前面的预测区间更大,后面的更小。看起来就跟实际比较像了。
(其实这个结果得出来的特别波折,但是论文写出来的逻辑相当流畅,把解释不了的地方避重就轻的一带而过,能解释出来的部分狠狠夸了一波。展现出来的就是这种,很厉害但又有点云里雾里的感觉。)

分析单词的属性对玩家困难模式选择的影响程度这里,我们把能想到的所有属性都列了一遍。画出来散点图发现除了时间以外都没什么关系。然后就大胆写上了,也没去刻意寻找什么关系。

3.猜词结果分布预测模型
为了预测未来报告结果的分布,我们首先对数据特征进行了提取与构建。接着,我们搭建BP神经网络模型,将7个数据特征作为输入,输出7种猜词结果的分布。最后,采取Bagging算法对多个BP神经网络进行集成,通过硬投票机制得出最终预测结果,降低预测结果的泛化误差。
(第一问的模型还没建的时候,建模哥就跟我说,这个数据量太适合BP神经网络了。于是他在那边想办法搞定上一问,我在这边炼丹。)
后来引入背包算法的原因是不管怎么调,单个神经网络输出的准确率,都只有40%不到。看起来很离谱,于是我们抓出来几次跑出来的结果,发现预测不准的词汇相对来说并不固定,也就是说纯纯是这个词本身的问题,而不是变量抓的不准。
于是建模哥提出来投票,一个网络预测不准就让一堆网络一起预测。
让100个神经网络投票以后,误差依旧不太小,但没之前那么离谱了。
还有一个小细节就是,我们的训练集和测试集不是纯随机选的,而是固定的前85%的数据作为总训练集。相当于用完全相同的数据训练出不同的网络。这样比随机抽的训练集误差更小一些。
其实最后结果也不是相当理想,所以我们把每一个词汇的每一个猜词次数预测误差的分布具体拆开统计,大部分误差其实都不大。最后得出来的结论是”我们对预测结果绝对误差不超过5%有80%以上的信心”。这写完以后我们仨都乐了,确实不太像人话。但要是直接说绝对误差不超过20%那也显得我们做的太拉胯了。
最后这个ERRIE的结果分布,我们仗着神经网络不可能完全复现,预测了10次左右,找最接近的几个值取了个平均。按照误差的统计分布来看,这样基本拿到的结果就是准的了。
3.词汇难度分类模型
为了能对solution words进行合理的分类,我们首先根据用户的猜词次数分布并基于K-Means聚类算法对难度进行划分。接着,我们基于Pearson相关系数来探索单词属性与难度划分的关联,构建了单词难度分类模型。最后,按照此关联性对新的单词进行难度分类。
我们做到这一问的时候,已经是最后一个中午了,而且深度学习的结果刚出来,还没有写文章。前面做的确实慢了一些。
刚开始我们也受了网上各种言论和b站那个大神的信息熵预测视频的影响,本来打算用信息熵。当时我还开玩笑说,这题纯纯给你们通信人出的。最开始我们捋出来一套解法,拿动态规划进行的步骤模拟。
单词的不确定度来自于字母的不确定度和位置的不确定度。如果我们拿到绿色方框,就可以一次性消除掉该位置和该字母的所有不确定性;如果拿到黄色方框,可以消除掉字母的不确定性,只剩位置的不确定性;如果拿到灰色方框,则某个字母一定不会存在,也可以消除掉一些不确定性。用动态规划的思想迭代,最后拿到每次预测的难度。
大概是这么个想法,后来没用这个的原因,一个是太难了,最后一个晚上了,程序都不一定能写完,更别说论文;另一个原因是建模哥说的,他说始终感觉,C题是对数据的处理,而不是对过程的追踪(大概是这个意思)。动态规划这种解法不像是用在这道题的。
其实当时我们觉得前两问的模型都很low,一心想在第三问整个花活。确实也纠结了一下要不要用聚类分类,总感觉太平庸了。最后还是选择了相信建模哥的直觉,用的最简单的kmeans。
难度直接反映在猜词次数上,于是我们通过猜词次数得到了四个聚类。聚类这样做没问题,分类用什么向量的问题上我们也纠结过。我倾向于直接使用上一问预测的分布次数进行分类,还能反过来证明第二问算出来的结果是对的;建模哥觉得这个不是单词的本质属性,只是外部表现而已,应该用单词的属性来分类。
最后听建模哥的意见,用相关系数把属性和猜词次数联系起来,然后用属性分类。
对于未来的solution word而言,我们可以通过计算它与各个典型样本的相似度判断其难度。由于我们在第6.2节中建立了对未来日期给定solution word的猜词次数分布预测模型,所以我们对于词汇难度有两种判断依据。一种是基于预测的猜词次数分布,一种是基于solution word的属性向量 。
 (其实单纯从得到的结果看,直接用猜词次数分类的结果比这个要好一些,但少一个Pearson系数模型,而且变量不是单词本身属性这一点,大概可能描述起来会有逻辑上的漏洞。)
(其实单纯从得到的结果看,直接用猜词次数分类的结果比这个要好一些,但少一个Pearson系数模型,而且变量不是单词本身属性这一点,大概可能描述起来会有逻辑上的漏洞。)
碎碎念
在组队找人,以及和朋友们唠到哪个位置最容易的时候,很多人跟我说,论文是最难的,因为最后的结果就是论文展示的。而建模位置是最好划水的,只需要给出一个模型就好。
但其实我感觉,建模位置是最后决定获奖高度的因素。对文章中用到的模型,优点缺点适用范围这些细节全部了解。并且有一定的数学敏感度,知道什么情况下是模型整个有问题,什么情况下微调就可以。以及可以对自己建立的一切模型作出合理的数学解释而不是套教程的话。建模手有这种功底的话,我觉得拿到满意的成绩只是时间问题。
很佩服我队伍中的建模手。我是半程加入这个队伍的,建模哥应该是已经打了很多年的数模了。我的数模水平可能也只够在编程位上,常用的模型大部分都只听过个名字,优缺点和使用场景一概不知。甚至编程语言也只会matlab一种,python还是编程哥教我的。
建模哥非常包容我的无知,不管是训练时候还是正式比赛的时候,所有的模型都是他建的,一部分论文也是他写的,并且能把握着整道题的时间。比赛时,我的工作只负责,听懂,实现,出数出图,就可以。听不懂的地方建模哥就会直接动手写程序了。我没有凭空想出模型的本事,最多只是在建模提出的模型基础上凭我的感觉进行一些优化。
这种情况下,在建模哥拿到第二个国赛省一的时候也没有打算放弃,也没有产生过优化掉队伍中什么人的想法。很佩服这份坚持,时间会证明一切不是假的。
我的思路中始终没有论文姐姐的影子,不是因为划水,是因为她几乎从头忙到尾,和我基本上没有交流。(指思路上,不是整个比赛期间。论文姐姐平时温柔极了。)我和建模哥研究结果拉胯怎么补救,她帮我们找相关的论文;我们拖到晚上才把模型中文版敲定,她默默熬夜翻译排版;还有帮我们找得到的数据画什么图效果好看。细节拉满。
ok,谨以此篇记录我本科期间最大的奖。
