前言:
归并排序跟快速排序有异曲同工之妙,都是分治法的典型代表。但是这种分治法都有不小的弊端,就是需要占用大量的系统栈,很容易造成空间的大量浪费,所以就有用迭代来优化递归的操作。这次的归并排序,我采用迭代的方式来进行编写。
思路:
归并算法如其名,需要不断地归并。我们在学习数组的时候,应该学习到过合并两个有序的数组的时间复杂度是很低的,不断地二分并进行合并,这个算法的时间复杂度仅为O(nlogn),但是合并数组的时候是需要一个额外的相当于原数组大小的空间的,所以空间复杂度并不是很好O(n)
所以最先的最先,我们要先开辟一块空间
int *b = (int*)malloc((length+5) * sizeof(int));
//加上一些偏移量以防越界,同时,要记得最后要free掉这片空间
//这个free不重视要出大问题的,接下来会说
开始写这个排序最先想到的莫非就是如何不断地二分。既然我们选择的是自下而上的进行迭代,我们一开始的1个1个的比较从而形成2个,2个比较的情况,因此我们的两层循环其实就已经都定下来了:(offset是偏移量的意思)
for (offset = 1; offset < length; offset *=2)
for (left = 0; left < length; left += 2 * offset)
由于是二分,所以偏移量自下而上的是1,2,4,8···,也就是说 偏移量的变化是 offset *=2
然后left和接下来的right是在原数组中进行滑动的下标,用来比较的。
接下来,我们需要思考一下left 和right有哪些情况。其实,这里主要的问题就是怕越界,因此我们为了方便表示,重新定义三个变量,来处理可能越界的问题:
int low = left;
int mid = min(left + offset, length);
int high = min(left + 2 * offset, length);
(left+offset 相当于右比较框的第一个元素;left+2*offset 相当于同样长的第三个比较框的第一个元素)
这里的mid,是左边比较框的最右端再往右一个单位,因此可能会超出数组长度,需要在len和left+offset 中选择较小的一个;
这里的mid,同时也是右边比较框的第一个元素,high是右边比较框的最右端再往右一个单位,与上面同理,有可能越界,所以在left + 2 * offset 和 len 选择较小的一个。这样,再为了方便重新定义几个量来表示,就很清晰明了了:
int left1 = low, right1 = mid;
int left2 = mid, right2 = high;
接下来的部分其实比较简单,就是两个有序数组进行比较,并归并入新数组的过程:
//确定指针没跑到下一个区间去
while (left1 < right1 && left2 < right2)
b[i++] = a1[left1] < a1[left2] ? a1[left1++] : a1[left2++];
//下头两个while只执行一个,把剩下的元素全搬进去
while (left1 < right1)
b[i++] = a1[left1++];
while (left2 < right2)
b[i++] = a1[left2++];
当整个数组比较完以后,我们开辟的b数组中,就是合并过一次的数组了,我们需要把a和b换个位置。
int* temp = a1;
a1 = b;
b = temp;
至此呢,大概已经完成了,但是,不注意free要出现的大问题来了:
如果上面那个交换的代码交换了奇数次,如果我们free(b),我们就会free一片静态内存了,这是不被允许的。如下图所示:
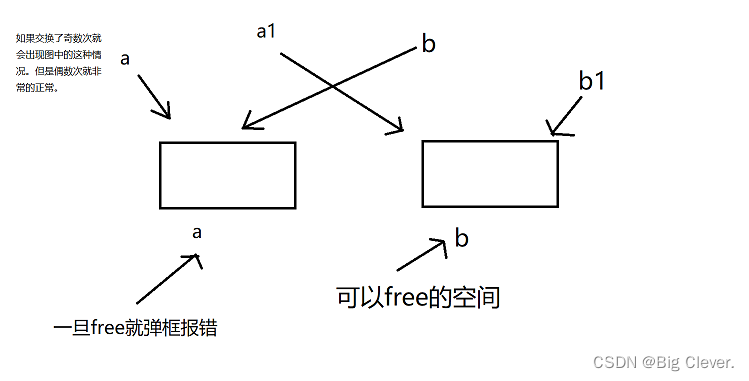
为了解决这个问题,我们一开始就需要定义指针来指向空间,最后用来做校验。当然,释放的时候我们为了保险直接释放b1就行了,绝对没问题。
这边我们应该这么写:
if (b != b1)
{
for (int i = 0; i < length; i++)
{
a[i] = a1[i];
}
}
free(b1);
肯定有人会跟我有一样的问题,为什么不能再改变指针的位置直接成功呢?就像下面一样:
if (b != b1)
{
a = a1;
}
free(b1);
这个时候我们用地址找一下,就很容易明白了:
一开始的地址:
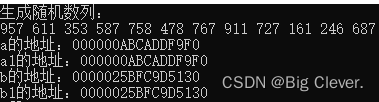
处理完的地址:

我们会发现其实他所有的地址全都指向了一开始开辟的,最后要被释放掉的动态区域b!
那么为什么编译器不报错呢?这里应该和我在别处了解到的别的一样:编译器会做一定的保留。
所以并不会直接报错,但是会出现意料之外的情况。因此,我们不能改动地址,而应该用赋值操作,来使a数组,与a1数组同步(像我上面讲的,a1一定是有序的那一个,而我们最后需要的是a数组)
核心代码:
这边的核心代码为了阅读以及复制方便,我就只保留 归并排序 的内容了,我的一些试错及写出来的体验和心得就放在下面的测试代码中了,想具体了解的,可以移步到下面了。
void MergeSort(int *a,int length)
{
int* a1 = a;
int *b = (int*)malloc((length+5) * sizeof(int));
int* b1 = b;
int offset;//offset是每次归并的两个小数组的偏移量
for (offset = 1; offset < length; offset *=2)
{
int left;
int i=0; //i是给新数组准备的下标
for (left = 0; left < length; left += 2 * offset)
{
int low = left, mid = min(left + offset, length), high = min(left + 2 * offset, length);
int left1 = low, right1 = mid;
int left2 = mid, right2 = high;
while (left1 < right1 && left2 < right2)
b[i++] = a1[left1] < a1[left2] ? a1[left1++] : a1[left2++];
while (left1 < right1)
b[i++] = a1[left1++];
while (left2 < right2)
b[i++] = a1[left2++];
}
int* temp = a1;
a1 = b;
b = temp;
}
if (b != b1)
{
for (int i = 0; i < length; i++)
{
a[i] = a1[i];
}
}
free(b1);
}
整体测试代码:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define N 30
//之前写过了,就不再全写一遍了
void generate_random_number(int*, int, int);
void swap(int*, int*);
//自下而上迭代
void MergeSort(int *a,int length)
{
int* a1 = a;//如果觉得这一步是多余的,那xd你和我一开始觉得一样,但其实这个是必要的!往下看。
int *b = (int*)malloc((length+5) * sizeof(int));
int* b1 = b;
int offset;//offset是每次归并的两个小数组的偏移量
for (offset = 1; offset < length; offset *=2)
{
int left;
int i=0; //i是给新数组准备的下标
//left是每次进行归并的左边小数组,right是右边的;每次归并完两个,整体向右挪动两倍的offset
//注释掉的是写的错的代码。错在没有考虑数组指针越界的情况,其实也就一行 right = min(left+offset,length)
//for (left = 0,right = left + offset,i = 0; left < length && right < length; left += offset * 2, right = left + offset)
//{
// int left1 = left;
// int right1 = right;
// while (right1 < left + 2*offset && left1 < right)//指针没跑到下一个区间去
// {
// if (a[left1] <= a[right1])
// b[i++] = a[left1++];
// else
// b[i++] = a[right1++];
// }
// //下头两个while只执行一个,把剩下的元素全搬进去
// while (left1 < right)
// b[i++] = a[left1++];
// while(right1 < left + 2 * offset)
// b[i++] = a[right1++];
//}
for (left = 0; left < length; left += 2 * offset)
{ //下这两步都是为了确保数组下标不会越界
int low = left, mid = min(left + offset, length), high = min(left + 2 * offset, length);
int left1 = low, right1 = mid;
int left2 = mid, right2 = high;
//确定指针没跑到下一个区间去
while (left1 < right1 && left2 < right2)
b[i++] = a1[left1] < a1[left2] ? a1[left1++] : a1[left2++];
//下头两个while只执行一个,把剩下的元素全搬进去
while (left1 < right1)
b[i++] = a1[left1++];
while (left2 < right2)
b[i++] = a1[left2++];
}
int* temp = a1;
a1 = b;
b = temp;
/* 不容易,我终于想懂了!
上面这一步实现交换,使得有序的序列肯定是a所指的地址,但是最后a的地址不一定能回到arr,可能在b上
但是,free函数只能释放动态开辟的内存,也就是只能释放原先b所指的内存空间,如果释放到a,直接严重弹框报错
外头我画了张图
根据log2(length)算出来的不同值,下面的交换步骤可能只进行奇数次,因此还需要多一些步骤才可以完全实现
如果只进行奇数次的话,我函数传参时传入的虽然是真实地址,但是他指向了我在函数中开辟的临时堆空间。
这块堆空间在函数进行完以后会释放掉,因此如果进行奇数次的话,我们在函数结束以后,原函数的地址是一片未知区域!
如果确定只进行偶数次,是可以不要下面步骤的
*/
}
/*
上面的解释也告诉我们,为什么要在函数开头看似无用的新建一个a变量和b1指向我们传入的和创建的地址,也是我们在最后要保证能找到我们一开始的地址
记录了以后我们可以简便的使用 b != b1 来进行判断。
*/
if (b != b1)
{
for (int i = 0; i < length; i++)
{
a[i] = a1[i];
}
}
free(b1);
}
int main()
{
int arr[N + 10] = { 0 };
generate_random_number(arr, 0, 1024);
MergeSort(arr,N);
printf("MergeSort排序后数列:\n");
for (int i = 0; i < N; i++)
printf("%d ", arr[i]);
printf("\n");
return 0;
}
测试结果:

至此,归并排序完成
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)