该文章参考宋宝华老师的内存管理课程,详细可以去听阅码场宋老师的课程。
● 内存与I/O的交换
● page cache
● free命令的详细解释
● read、write和mmap
● file-backed的页面和匿名页
● swap以及zRAM
● 页面回收和LRU
1、page cache 的概念
CPU 读取 IO , MEM 在功能上其实是充当了一个 cache的角色,会很快。


read write 一个文件的交互过程如下:

第一次读,内存中没有内容,内核会给其申请一页,然后从disk中,读取1页内容到内存中的这1页(伴随IO),然后再返回到用户态的程序。注意,不管你app读几个字节,都会从磁盘中读取至少1页。
当你第二次读,就会很快。因为没有IO的过程。注意:当你在用户层读写一个文件的时候,虽然你只读了10个字节,但是在Linux里面,它是按页来读的,读到page cache , 只不过在给 用户空间 返回的时候是按照你请求的数据来返回的。
第一次写,内存中没有内容,内核会给其申请一页,然后从disk中,读取1页内容到内存中的这1页(伴随IO),然后再将内容写到page cache中。注意,并没有直接写到disk 中(除非是direct io),至于什么时候写回,就是内核 dirty data 管理的机制了。
注意,第一次写,其实伴随着一次读的过程。
总之,page cache 不命中,就会从disk中读取内容到 page cache,这个IO过程是比较慢的。
当我们拷贝一个文件 到 disk 中,其实并没有马上写到 disk ,所以我们才会进行 umount , sync(把 dirty data写回) 等等这些操作。
在 Linux 中读写文件,一般有两种方法,read write 这种方法伴随着有 user_buf 《------》 page cache 内存拷贝的过程。

还有一种 内存映射的方法来做,这样就没有内存拷贝的过程了。

其实就是一段VMA。


#include <sys/mman.h>
#include <stdlib.h>
#include <fcntl.h>
#include <stdio.h>
int main(int argc, char **argv)
{
char *m;
int i;
int fd = open("./hello.py", O_RDWR, S_IRUSR);
if (fd == -1) {
perror("hello.py failed\n");
exit(-1);
};
#define MAP_SIZE 50
m = mmap(0, MAP_SIZE, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
if (m == MAP_FAILED) {
perror("mmap /dev/sda failed\n");
exit(-1);
}
printf("%s\n", m);
*m='a';
*(m+1)='b';
m[2]='c';
printf("%s\n", m);
munmap(m, MAP_SIZE);
close(fd);
}


这就是 Linux 中 修改文件的另一种方法,其实,对用户空间而言,文件就想一种内存,因为所有的操作都是一种内存中的操作,操作的是page cache , read / write /mmap 都是操作的page cache。
mmap的好处就是 少了1次内存拷贝。但是有很多很多的文件,都不支持 mmap, 比如串口设备文件 ,键盘等等,只有能够变成内存的东西才可以mmap。
这就能让我们理解了,我们在读写完U盘的时候,不能直接拔掉,而是要先执行 sync ,再umount拔掉,其实就是把 dirty data 写回的过程。
2、free 命令解析
假设电脑有 2G 的内存,那这 2G 内存是怎么被瓜分的呢?


free 命令(早期的free命令)
第1行是从 buddy 级别来看的,因为buddy 不关心你的用户是谁,只要用了就是占用了。used 是系统中所有被使用的内存,free 是 系统中所有空闲的内存 , total = used + free
第2行是从物理内存条的角度来看,因为 page cache是可以回收的,可以踢出去的。buffers 和 cached 都是 page cache ,但是由于 page cache 是可以回收的,所以第2行的内容 还会有一个 used 和 free 。 这里的 free 是把 buffers 和 cached 加上了。
buffers 和 cached 的区别是什么呢?

这里解释一下,EXT4 文件系统在实际访问 disk 中的文件时,会访问到 metadata , 就是指向具体数据位置的指针,这时候产生的page cache
也是计算到 buffers的。

buffers 和 cached 在Linux 中是没有本质区别的,只是两种不同的统计方式。这两种都是 page cache ,访问裸分区也会有page cache的。
所以目前,新的free 命令 就不区分 buffers和cached了,注意这里的 available < free + buff/cache , 这是因为什么的?

我们还是看看 meminfo吧
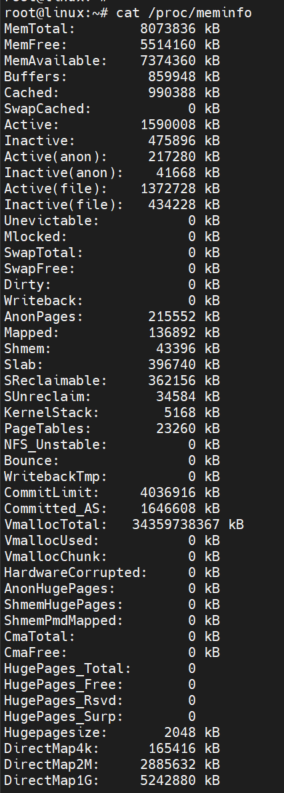
查看 Documentation/filesystems/proc.txt 可以看到 Memavailable 是一个估计值,并不是百分百等于的。Memavailable ≈ MemFree + buffers + cached ,当然也会和 SReclaimable 和 有关系

这里举一个例子,当访问了一段裸硬盘之后,free 命令的第一行 变化会比较明显,而第二行不明显,因为第二行是排除了 buffers 和 cache 的数据。

代码段的本质:其实就是page cache ,将代码段 mmap 到内存,然后 PC指针 运行。这和 read mmap 一样的,都是从disk 中读取代码段到 page cache, 然后执行的。
这个过程当然也是 demanding page , 执行到哪里,读到到哪里的过程。所以代码段在内存当中的副本,就是一个page_cache ,也就是可回收的 reclaimable

3、Linux 中 页面的两种类型
一种是有文件背景的,file-backed page , 这种是 可回收的。比如 代码段,比如mmap 一个文件。
另外一种是匿名页。映射的是进程的虚拟地址空间,并没有映射任何文件。比如 堆、栈、写实拷贝的页。这种是不可回收的。匿名页就要 常驻内存。

匿名页就要 常驻内存。但是当内存不足的时候,就会有一个矛盾。这个就是 匿名页 和 swap分区。

比如电脑就有 512M的内存,word 程序有400M匿名页, qq 有200M的匿名页,因为匿名页要常驻内存啊(堆、栈的数据不能丢啊),那512M内存 能同时跑起来 word qq 吗?
Linux 就为 匿名页 伪造了一种文件背景 ,swap 分区。
swap 交换,作为动词,包括 文件背景页面的交换, 匿名页的交换。和 CONFIG_SWAP无关。
swap做名词的时候,通常将的是 匿名页的交换分区。只有使能 CONFIG_SWAP才会交换匿名页。
Linux 也支持一个文件来做交换,而不是非要一个分区

4、LRU 最近最少使用算法
所有的这些页面替换算法,用的都是LRU算法。
- CPU 内部的cache 和 内存直接的页面替换
- 内存和硬盘之间的页面的替换
- 交换分区,匿名页的替换

就是通过局部性原理决定的,你最近访问的东西,就是你马上要访问的东西 ,
你最近访问的东西周围的东西,就是你马上要访问的东西。
一个是时间局部性原理,一个是空间局部性原理。
你昨天再看某一部电视,看的破冰行动第1集,那你今天看破冰行动第2集的可能性就比较大。这是局部性原理
你的书架上有一本 Linux 内核的树,5年前就买了,但是从来都没看过,内心一直催促着今天一定要看,但是对不起,你直接把这本书扔掉,这不符合局部性原理。
局部性原理就是你最近最不常使用的,就是你未来最不常使用的。你过去活跃的,就是你将来活跃的。
当别人问道你,cache 替换算法,就是一个高速的东西和一个慢速的东西,替换数据的时候的算法,一定要在1秒之内回答他,LRU算法。

上面的这个图,访问页面的顺序 1、2、3、4 ,访问到4的时候,显然1是最不活跃的。接着继续访问 1、2 、5,当访问到5的时候,3显然是最不活跃的,
所以把3给替换了。这就是 最近最少使用算法LRU。
内存回收使用的门限。之后再讲。
# meld file1 file2 可以在 Linux下 对比两个文件的改动,比diff好用。

如果系统开启了 swap 匿名页的交换,系统就会没日没夜的去交换。
对于嵌入式系统而言,很少用到 swap 交换匿名页。主要因为两个原因
1、嵌入式系统的存储介质,读写速度比较慢。
2、flash 都是有读写次数,寿命的。
所以一般都不去使能swap 。
后来,有人在 Linux 里面加入了一个非常天才的设计,叫做 zRAM。它的存在,使得嵌入式系统也可以使用 swap 分区来交换匿名页了。
swap 就非常像虚拟内存,可以达到增大你的内存的效果。
5、天才想法 zRAM (CPU算力换取内存)
为什么说 zRAM 的想法很天才呢,这是一种 将CPU的算力 换取 内存 的一种想法,能不牛逼吗?

当你交换匿名页的时候,CPU会将匿名页的数据,透明的压缩,然后存到着预留的100M 空间中,交换回来的时候,再透明的解压。
虽然预留出了100M,但是并不等于系统的内存减少了100M,可能还会多于800M。

所在这种 zRAM在 嵌入式系统 已经非常常用了。配置起来也比较简单。

swapon 是使能交换分区,swapoff -a 是关掉所有的交换匿名页,是关不掉文件背景的交换的。