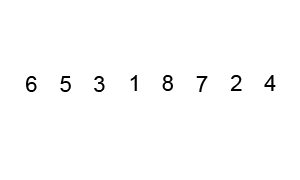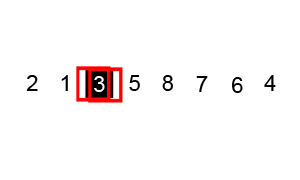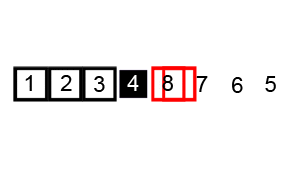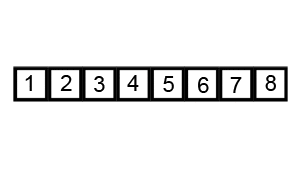1. PARTITION (array A, start, end)
2. {
3. pivot = A[(start+end)//2]
4. i = start
5. j = end
6. while (True)
7. {
8. do i =i + 1 while A[i]<pivot
9. do j =j - 1 while A[j]>pivot
10. if i>=j then return j
11. swap A[i] with A[j]
12. }
13. }
在分区函数中,我们首先将数组的一个元素(此处为中间元素)分配给主元变量。 变量 i 和 j 用作左指针和右指针,它们迭代数组并用于在需要时交换值。 我们使用 while 循环以及 return 语句来确保整个数组
def partition(A, start, end):
i = start-1 #left pointer
pivot = A[(start+end)//2] # pivot
print(f"Pivot = {pivot}")
j = end+1 #right pointer
while True:
i+=1
while (A[i] < pivot):
i+=1 #move left pointer to right
j-=1
while (A[j]> pivot):
j-=1 #move right pointer to left
if i>=j:
return j #stop, pivot moved to its correct position
A[i], A[j] = A[j], A[i]
a = [3,7,8,5,2,4]
print(f"Input array: {a}")
p = partition(a,0,len(a)-1)
print(f"Array after partitioning:{a}")
def quickSort(A, start, end):
if start < end:
p = partition(A, start, end) # p is pivot, it is now at its correct position
# sort elements to left and right of pivot separately
quickSort(A, start, p)
quickSort(A, p+1, end)
A = [24, 10, 30, 13, 20, 27]
print(f"Original array A: {A}")
quickSort(A, 0, len(A)-1)
print(f"Array A after quicksort: {A}")
Output:
快速排序时间复杂度
对于大小为 n 的输入,每一步都会将其分为 k 部分和 n-k 部分。 因此,n 个元素的时间复杂度 = k 个元素的时间复杂度 + n-k 个元素的时间复杂度 + 选择主元的时间复杂度 即 T(n)=T(k)+T(n-k)+M(n)
最佳案例
当选择中间元素作为每个递归循环中的枢轴时,会出现最佳情况的复杂性。 每次迭代时,数组都会被分成大小相等的列表,并且随着重复此过程,排序会以尽可能少的步骤完成。 执行的递归次数将为 log(n),每一步执行 n 次操作。 因此,可得时间复杂度为O(n(log(n)).
最坏的情况下
In the worst-case scenario, n number of recursion operations are performed and the time complexity is O(n2).
This can occur under the following conditions:
def partition_desc(A, start, end):
i = start-1 #left pointer
pivot = A[(start+end)//2] # pivot
j = end+1 #right pointer
while True:
i+=1
while (A[i] > pivot):
i+=1 #move left pointer to right
j-=1
while (A[j]< pivot):
j-=1 #move right pointer to left
if i>=j:
return j #stop, pivot moved to its correct position
A[i], A[j] = A[j], A[i]
a = [3,7,8,5,2,4]
print(f"Input array: {a}")
p = partition_desc(a,0,len(a)-1)
print(f"Array after partitioning:{a}")
def quickSort_desc(A, start, end):
if len(A) == 1:
return A
if start < end:
p = partition_desc(A, start, end) # p is pivot, it is now at its correct position
# sort elements to left and right of pivot separately
quickSort_desc(A, start, p-1)
quickSort_desc(A, p+1, end)
A = [24, 10, 30, 13, 20, 27]
print(f"Original array A: {A}")
quickSort_desc(A, 0, len(A)-1)
print(f"Array A after quicksort: {A}")
def quickSortIterative(A, start, end):
# Create and initialize the stack, the last filled index represents top of stack
size = end - start + 1
stack = [0] * (size)
top = -1
# push initial values to stack
top = top + 1
stack[top] = start
top = top + 1
stack[top] = end
# Keep popping from stack while it is not empty
while top >= 0:
# Pop start and end
end = stack[top]
top = top - 1
start = stack[top]
top = top - 1
# Call the partition step as before
p = partition( A, start, end )
# If the left of pivot is not empty,
# then push left side indices to stack
if p-1 > start:
top = top + 1
stack[top] = start
top = top + 1
stack[top] = p - 1
# If the right of pivot is not empty,
# then push the right side indices to stack
if p + 1 < end:
top = top + 1
stack[top] = p + 1
top = top + 1
stack[top] = end
A = [9,1,9,2,6,0,8,7,5]
print(f"Input array: {A}")
n = len(A)
quickSortIterative(A, 0, n-1)
print (f"Sorted array:{A}")
Output:
当堆栈不为空时,元素将从堆栈中弹出。 在这个 while 循环中,枢轴元素在分区函数的帮助下移动到正确的位置。 堆栈用于借助第一个和最后一个元素的索引来跟踪低列表和高列表。 从堆栈顶部弹出的两个元素表示子列表的开始索引和结束索引。 对形成的列表迭代执行快速排序,直到堆栈为空并获得排序列表。