first_name,last_name,title,publisher
Isaac,Asimov,Foundation,Random House
Pearl,Buck,The Good Earth,Random House
Pearl,Buck,The Good Earth,Simon & Schuster
Tom,Clancy,The Hunt For Red October,Berkley
Tom,Clancy,Patriot Games,Simon & Schuster
Stephen,King,It,Random House
Stephen,King,It,Penguin Random House
Stephen,King,Dead Zone,Random House
Stephen,King,The Shining,Penguin Random House
John,Le Carre,"Tinker, Tailor, Soldier, Spy: A George Smiley Novel",Berkley
Alex,Michaelides,The Silent Patient,Simon & Schuster
Carol,Shaben,Into The Abyss,Simon & Schuster
平面文件示例
示例程序examples/example_1/main.py使用author_book_publisher.csv文件以获取其中的数据和关系。此 CSV 文件维护作者列表、他们出版的书籍以及每本书的出版商。
笔记:示例中使用的数据文件可在project/data目录。里面还有一个程序文件project/build_data生成数据的目录。如果您更改数据并希望恢复到已知状态,则该应用程序非常有用。
要访问本节和整个教程中使用的数据文件,请单击下面的链接:
下载示例代码: 单击此处获取您将使用的代码在本教程中了解如何使用 SQLite 和 SQLAlchemy 进行数据管理。
上面显示的 CSV 文件是一个非常小的数据文件,仅包含少数作者、书籍和出版商。您还应该注意有关数据的一些事情:
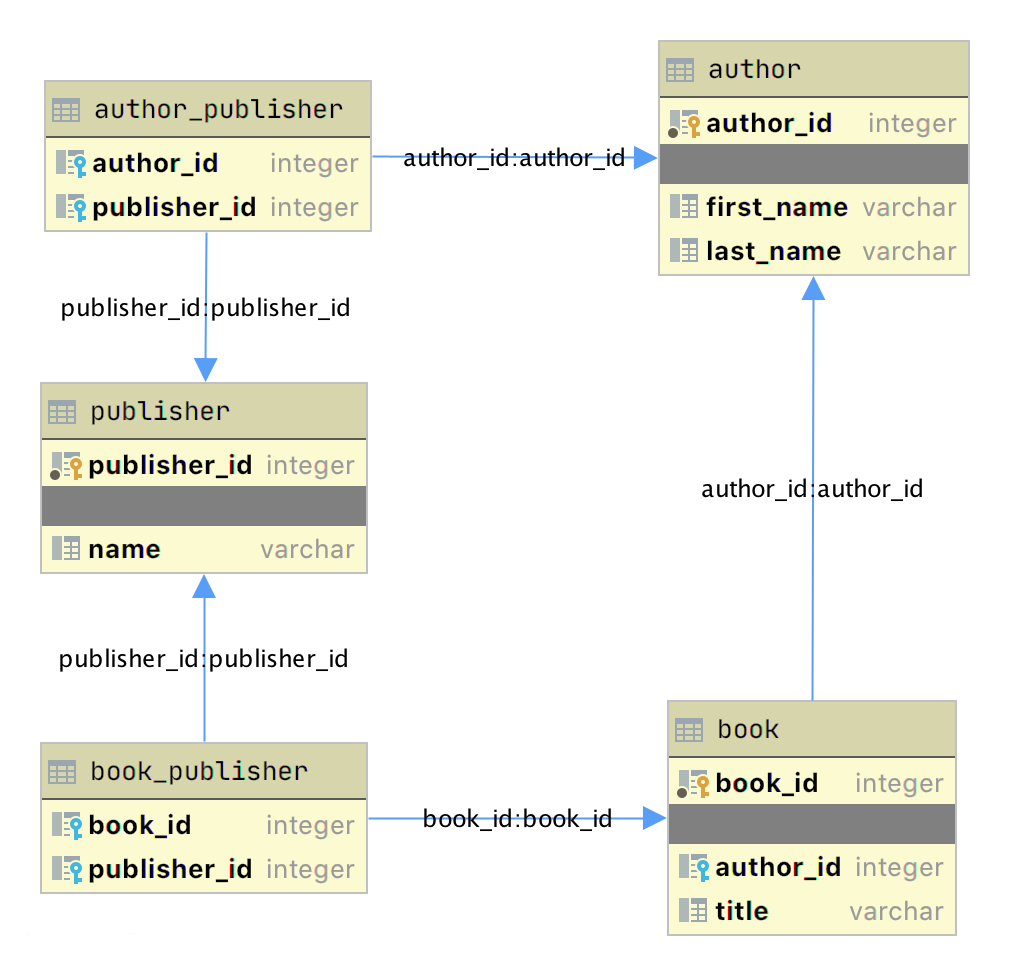
这些重复的数据字段在数据的其他部分之间创建了关系。一位作者可以写多本书,一位出版商可以与多位作者合作。作者和出版商与单本书共享关系。
中的关系author_book_publisher.csv文件由在数据文件的不同行中多次出现的字段表示。由于这种数据冗余,数据代表的不仅仅是一个二维表。当您使用该文件创建 SQLite 数据库文件时,您会看到更多内容。
示例程序examples/example_1/main.py使用嵌入的关系author_book_publisher.csv文件来生成一些数据。它首先列出作者列表以及每位作者撰写的书籍数量。然后,它显示出版商列表以及每个出版商出版书籍的作者数量。
它还使用树库模块显示作者、书籍和出版商的树状层次结构。
最后,它向数据添加一本新书,并重新显示新书所在位置的树层次结构。这是主要的()该程序的入口点函数:
1def main():
2 """The main entry point of the program"""
3 # Get the resources for the program
4 with resources.path(
5 "project.data", "author_book_publisher.csv"
6 ) as filepath:
7 data = get_data(filepath)
8
9 # Get the number of books printed by each publisher
10 books_by_publisher = get_books_by_publisher(data, ascending=False)
11 for publisher, total_books in books_by_publisher.items():
12 print(f"Publisher: {publisher}, total books: {total_books}")
13 print()
14
15 # Get the number of authors each publisher publishes
16 authors_by_publisher = get_authors_by_publisher(data, ascending=False)
17 for publisher, total_authors in authors_by_publisher.items():
18 print(f"Publisher: {publisher}, total authors: {total_authors}")
19 print()
20
21 # Output hierarchical authors data
22 output_author_hierarchy(data)
23
24 # Add a new book to the data structure
25 data = add_new_book(
26 data,
27 author_name="Stephen King",
28 book_title="The Stand",
29 publisher_name="Random House",
30 )
31
32 # Output the updated hierarchical authors data
33 output_author_hierarchy(data)
上面的Python代码执行以下步骤:
-
4 至 7 号线阅读
author_book_publisher.csv文件到 pandas DataFrame 中。
-
第 10 至 13 行打印每个出版商出版的书籍数量。
-
第 16 至 19 行打印与每个出版商相关的作者数量。
-
22号线将图书数据输出为按作者排序的层次结构。
-
第 25 至 30 行将一本新书添加到内存结构中。
-
33号线将图书数据输出为按作者排序的层次结构,包括新添加的图书。
运行该程序会生成以下输出:
$ python main.py
Publisher: Simon & Schuster, total books: 4
Publisher: Random House, total books: 4
Publisher: Penguin Random House, total books: 2
Publisher: Berkley, total books: 2
Publisher: Simon & Schuster, total authors: 4
Publisher: Random House, total authors: 3
Publisher: Berkley, total authors: 2
Publisher: Penguin Random House, total authors: 1
Authors
├── Alex Michaelides
│ └── The Silent Patient
│ └── Simon & Schuster
├── Carol Shaben
│ └── Into The Abyss
│ └── Simon & Schuster
├── Isaac Asimov
│ └── Foundation
│ └── Random House
├── John Le Carre
│ └── Tinker, Tailor, Soldier, Spy: A George Smiley Novel
│ └── Berkley
├── Pearl Buck
│ └── The Good Earth
│ ├── Random House
│ └── Simon & Schuster
├── Stephen King
│ ├── Dead Zone
│ │ └── Random House
│ ├── It
│ │ ├── Penguin Random House
│ │ └── Random House
│ └── The Shining
│ └── Penguin Random House
└── Tom Clancy
├── Patriot Games
│ └── Simon & Schuster
└── The Hunt For Red October
└── Berkley
上面的作者层次结构在输出中出现了两次,并添加了 Stephen King 的展台,由兰登书屋出版。上面的实际输出已被编辑,并且仅显示第一个层次结构输出以节省空间。
main()调用其他函数来执行大部分工作。它调用的第一个函数是get_data():
def get_data(filepath):
"""Get book data from the csv file"""
return pd.read_csv(filepath)
该函数获取 CSV 文件的文件路径,并使用 pandas 将其读入熊猫数据框,然后将其传递回调用者。该函数的返回值成为传递给组成程序的其他函数的数据结构。
get_books_by_publisher()计算每个出版商出版的书籍数量。由此产生的熊猫系列使用熊猫通过...分组按发布者分组的功能,然后种类基于ascending旗帜:
def get_books_by_publisher(data, ascending=True):
"""Return the number of books by each publisher as a pandas series"""
return data.groupby("publisher").size().sort_values(ascending=ascending)
get_authors_by_publisher()本质上与之前的函数执行相同的操作,但对于作者来说:
def get_authors_by_publisher(data, ascending=True):
"""Returns the number of authors by each publisher as a pandas series"""
return (
data.assign(name=data.first_name.str.cat(data.last_name, sep=" "))
.groupby("publisher")
.nunique()
.loc[:, "name"]
.sort_values(ascending=ascending)
)
add_new_book()在 pandas DataFrame 中创建一本新书。该代码检查作者、书籍或出版商是否已存在。如果没有,那么它会创建一本新书并将其附加到 pandas DataFrame 中:
def add_new_book(data, author_name, book_title, publisher_name):
"""Adds a new book to the system"""
# Does the book exist?
first_name, _, last_name = author_name.partition(" ")
if any(
(data.first_name == first_name)
& (data.last_name == last_name)
& (data.title == book_title)
& (data.publisher == publisher_name)
):
return data
# Add the new book
return data.append(
{
"first_name": first_name,
"last_name": last_name,
"title": book_title,
"publisher": publisher_name,
},
ignore_index=True,
)
output_author_hierarchy()使用嵌套for 循环迭代数据结构的各个级别。然后它使用treelib模块输出作者、他们出版的书籍以及出版这些书籍的出版商的分层列表:
def output_author_hierarchy(data):
"""Output the data as a hierarchy list of authors"""
authors = data.assign(
name=data.first_name.str.cat(data.last_name, sep=" ")
)
authors_tree = Tree()
authors_tree.create_node("Authors", "authors")
for author, books in authors.groupby("name"):
authors_tree.create_node(author, author, parent="authors")
for book, publishers in books.groupby("title")["publisher"]:
book_id = f"{author}:{book}"
authors_tree.create_node(book, book_id, parent=author)
for publisher in publishers:
authors_tree.create_node(publisher, parent=book_id)
# Output the hierarchical authors data
authors_tree.show()
该应用程序运行良好,并说明了 pandas 模块的可用功能。该模块提供了读取 CSV 文件和与数据交互的出色功能。
让我们继续使用 Python、作者和出版物数据的 SQLite 数据库版本以及 SQLAlchemy 来创建一个功能相同的程序来与该数据进行交互。