文章目录
- 1.采集
- 2.连接
- 3.训练
- 复制API KEY
- 上传照片
- 模型创建
- 生成神经网络
- 训练神经网络
- 测试神经网络
- 备份保存
- 4.下载
- 代码分析
注意: 只有
OpenMV4 Plus可以自己训练神经网络,其他版本的性能不够
本节讲解如何使用edgeimpulse.com网站来自行训练神经网络模型,进而实现机器学习的功能
edgeimpulse.com是一个在线网站,是一个为嵌入式产品非常快速地生成嵌入式上面使用的神经网络的模型,非常地易用且快速,大概只需要5min左右就可以训练出一个OpenMV4 Plus上使用的模型
机器学习有什么用? 利用机器学习我们可以知道OpenMV里面的图像是什么,比如图像里有没有人(进行人检测),或者是知道我们图像里的人是否有戴口罩(进行口罩识别),也可以利用机器学习来分辨一些其他物品和图片(是水杯还是矿泉水拼,电池还是烟头…),可以分辨一切你想要的东西,但是前提是训练好一个合适的模型
看完了上述部分,那么我们到底该如何使用OpenMV来训练神经网络模型呢
- 采集: 我们需要利用OpenMV的IDE来采集我们的数据集,根据经验,每一个分类至少需要100张左右的数据集进行训练
- 上传: 将我们在OpenMV的IDE中采集到的图像上传到
edgeimpulse的在线网站上 - 训练: 在
edgeimpulse的网站上进行在线训练模型 - 下载: 将我们训练好的模型和生产的代码下载到OpenMV中,直接运行即可
以 “口罩识别” 为例
1.采集
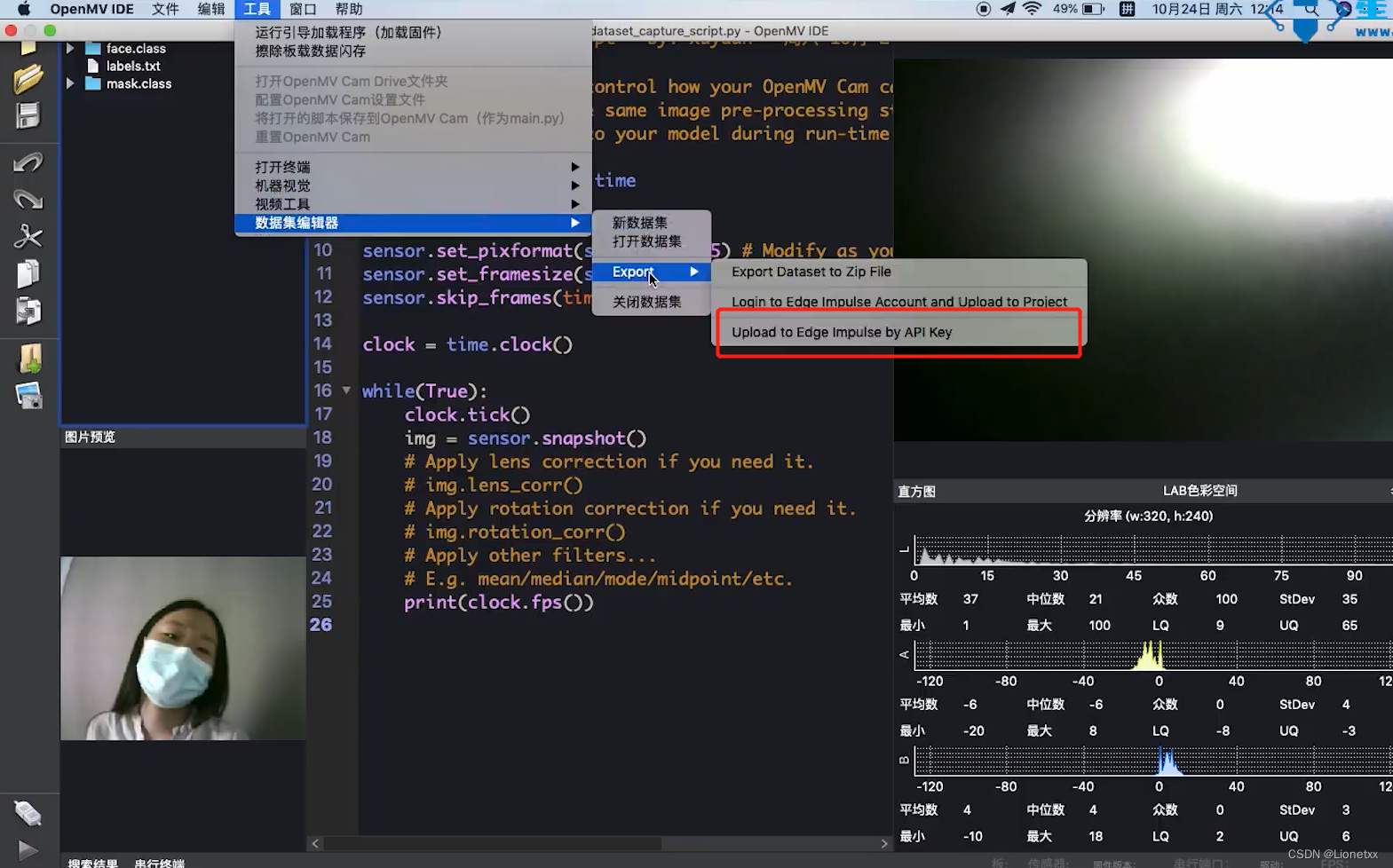
打开OpenMV的IDE——>菜单栏——>工具——>数据集编辑器——>新数据集
新建一个文件夹并命名,再打开即可
在数据集编辑器中新建文件夹,我们新建两个文件夹并且分类
- 人戴口罩
mask.class,存储100-200张戴口罩的人脸照片 - 人不戴口罩
face.class,存储100-200张不戴口罩的人脸照片
2.连接
- 连接OpenMV
- 点击IDE中的
连接 - 然后
运行 - 点击OpenMV的左侧菜单栏中的"
数据采集"按钮(按钮图标是个照片),点一下就会保存一张图片,会按顺序依次命名 - 我们可以保存多个角度,戴眼镜或不戴眼镜等多种照片
- 可以男女都采集一次,让男女都可以识别到,保证训练集的多样化
- 如果发现采集过程中人脸跑出了图像外,可以
对该张图像右键——>删除 - **采集图像时人物的背景最好是纯色的!**这样训练出的模型特征会比较明显,准确率会高一点
3.训练
将我们的数据集上传到edgeimpulse的网站上进行在线训练
复制API KEY
- 更改项目名称
- 在上方菜单栏找到
钥匙keys
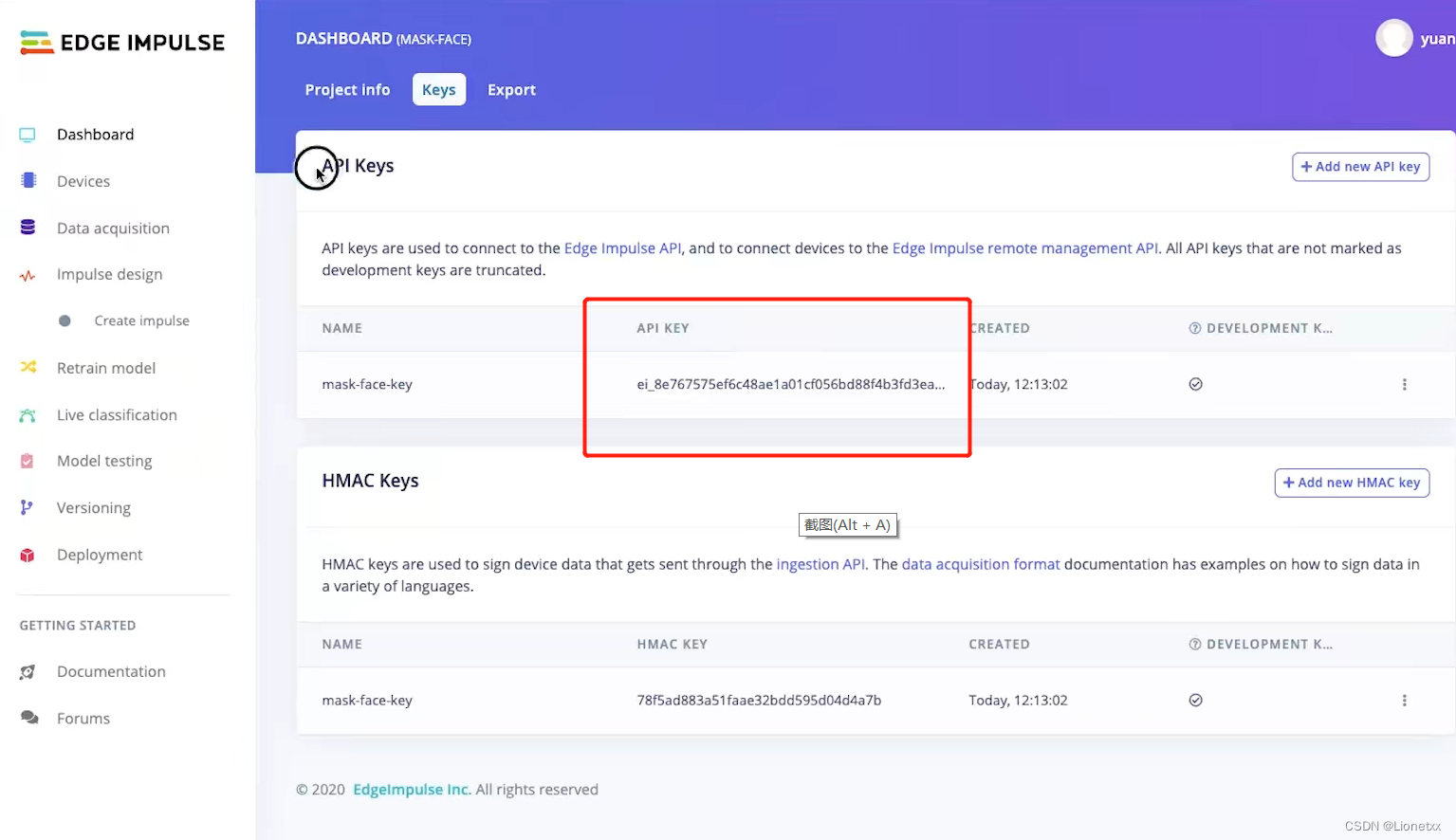
- 进入
钥匙keys,复制API KEY(注意:如果显示不全就对页面进行缩放处理!) - 也可以
右键——>检查来复制
上传照片
注意!!!
我们用星瞳科技的方法上传API可能输出现创建SSL上下文错误的问题,因此我们直接自行上传文件夹即可
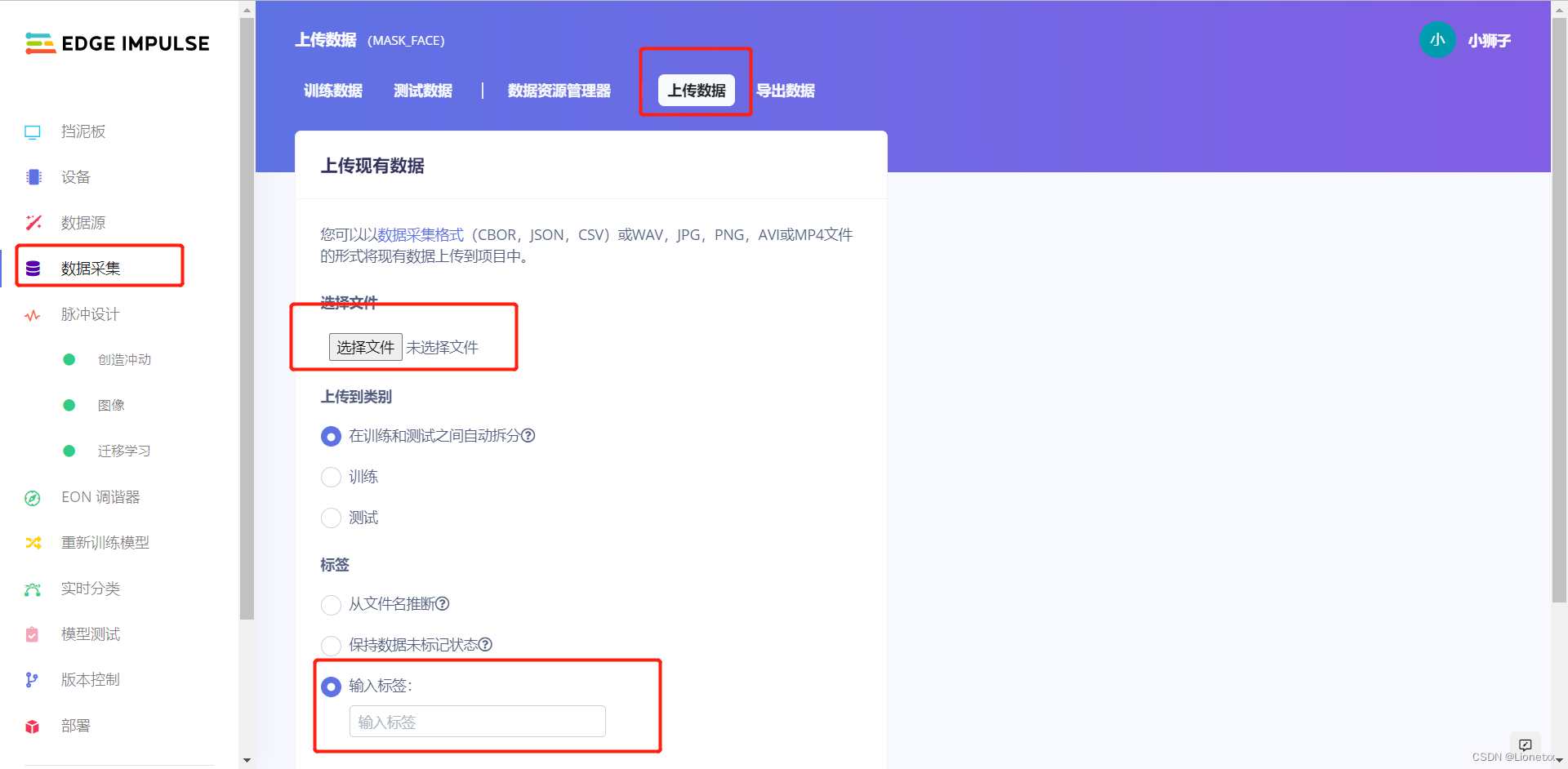
有几个标签文件夹就分几次上传,记得要自己输入标签!
- 在左侧的菜单栏选择
Data acquisition数据采集
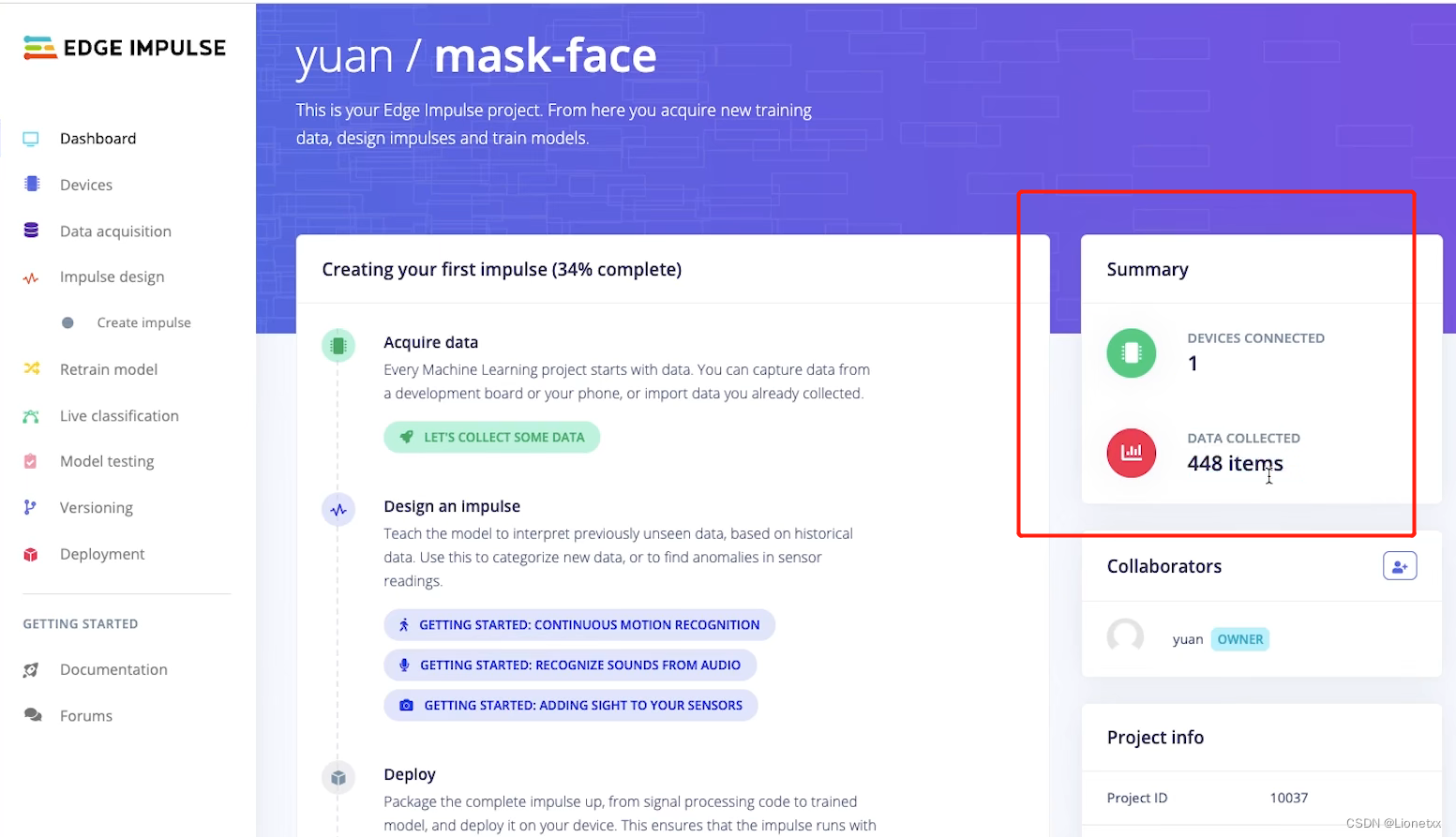
可以看到已经收集了410份数据,一共有两个分类LABELS = 2
点开其中的一个数据就可以看到我们保存的图像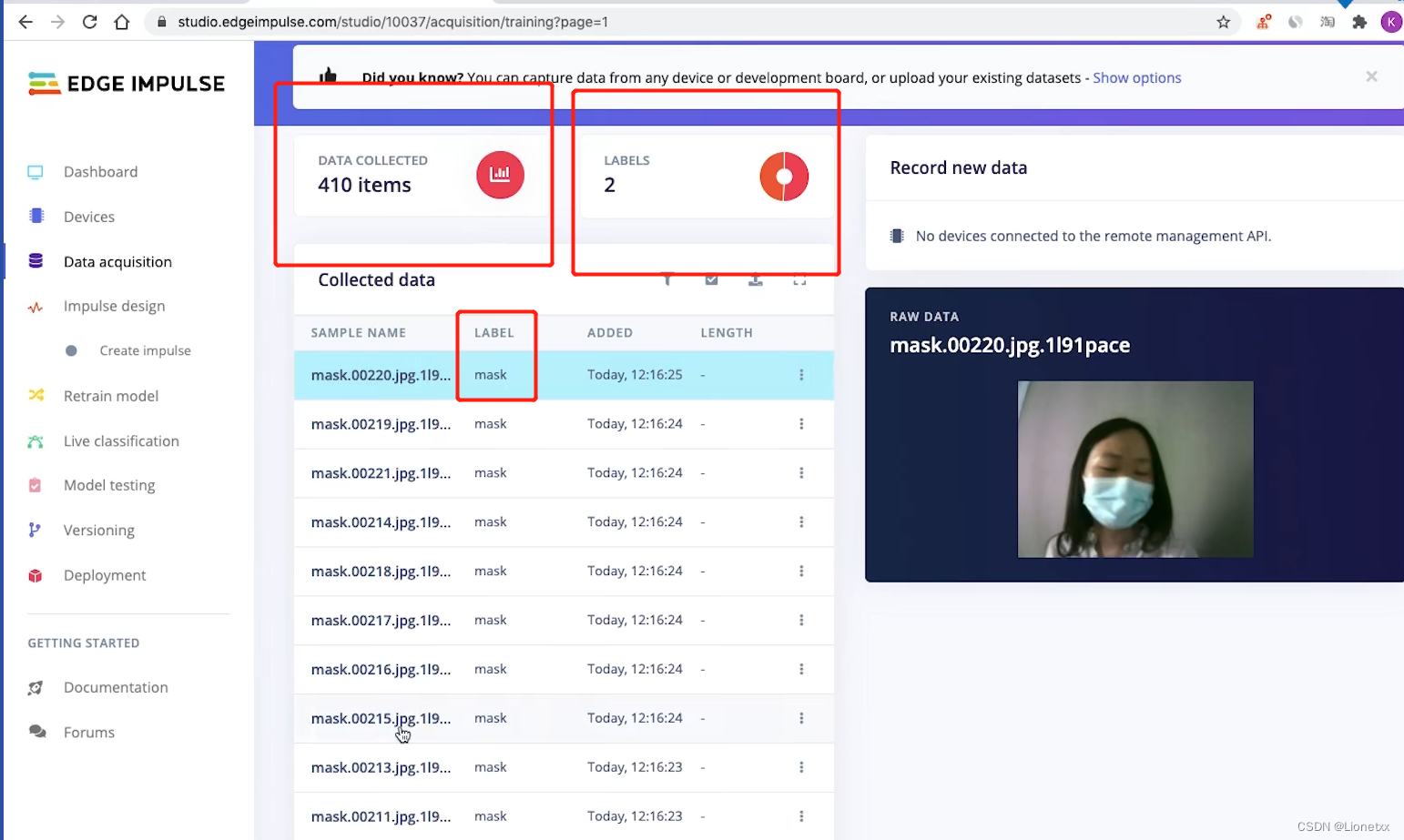
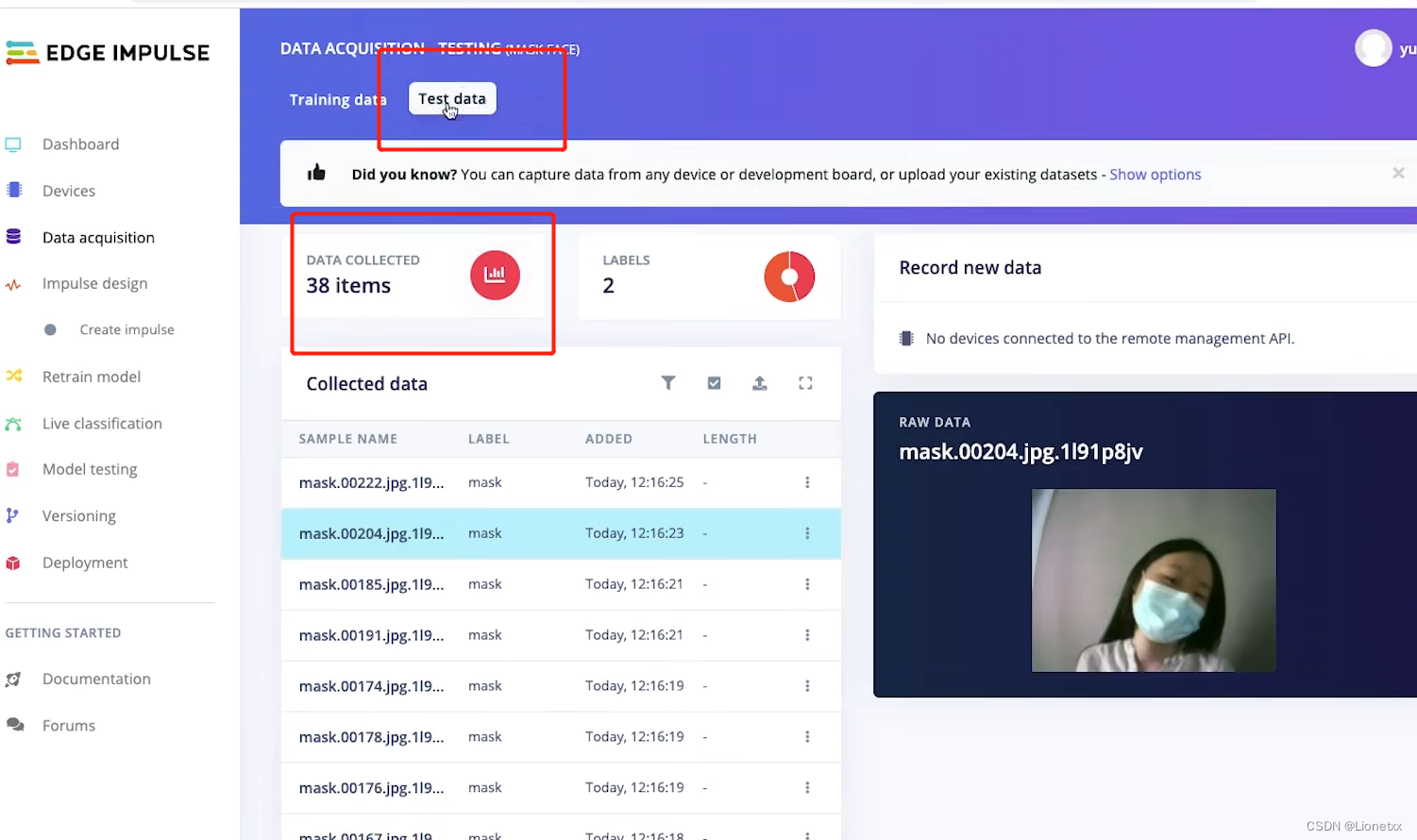
另外的Test Data测试数据是我们用来测试的数据集,只有20%的照片,因此只有38份数据
这部分数据是不参与模型的训练的,是在模型训练完成后用于测试模型准确率的(20%的数据由系统随机选择)
模型创建
-
进行模型的创建——>在左侧菜单栏选择Impulse design脉冲设计
-
首先进行图像的处理,我们选择默认大小即可,系统训练时会将图像变成长宽等比例的图像,我们选择默认值即可

-
创建模块Add a processing block,我们的OpenMV默认的是图像,因此选择image图像即可

-
添加下一个模块,我们一般默认选择后面带⭐的Transfer Learning迁移学习,训练会快一些
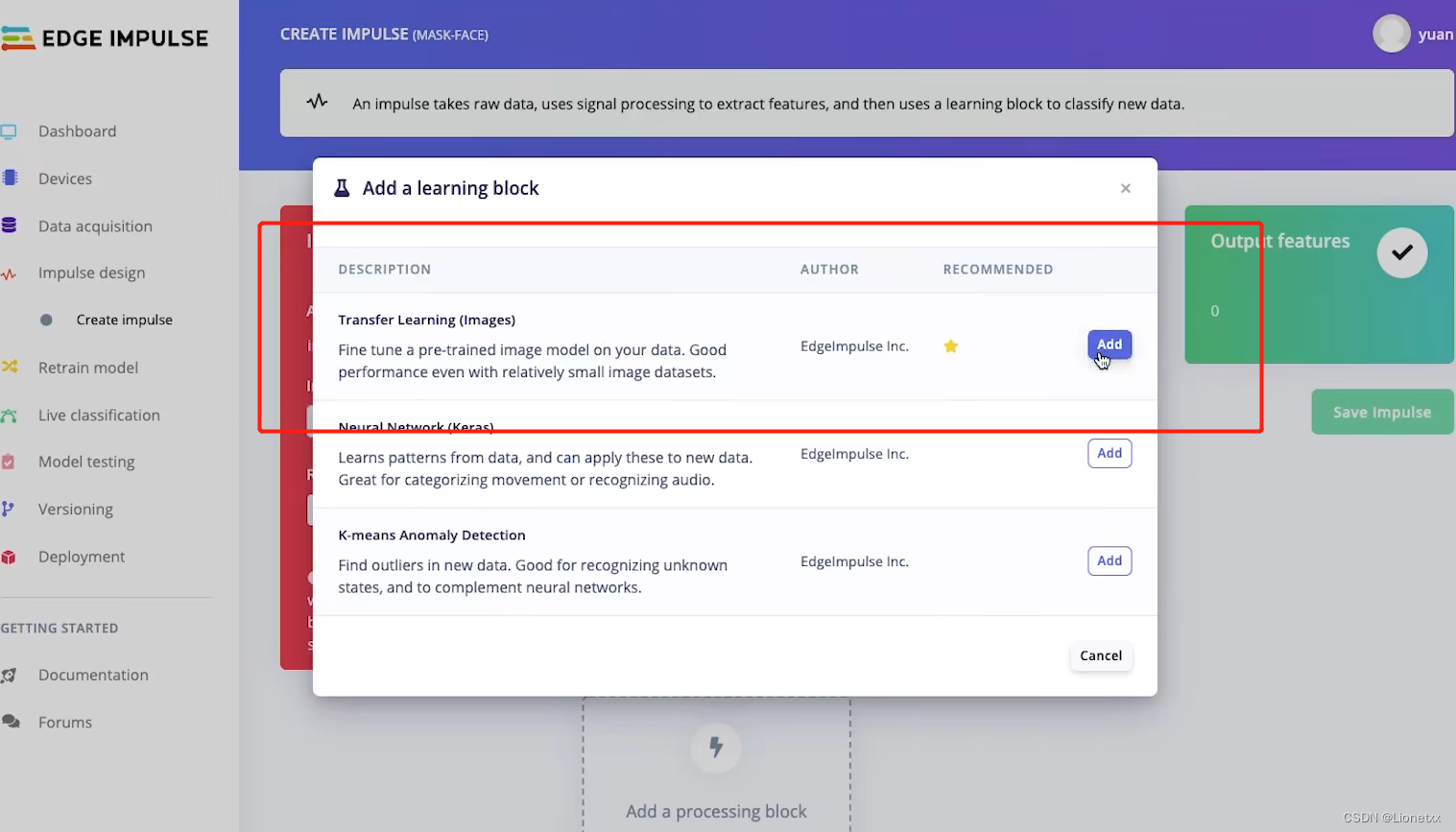
-
训练结束后会生成Output features
此处有两个,一个是戴口罩的mask,另一个是不戴口罩的face
-
选择Save Impulse保存,上方会显示保存成功

生成神经网络
-
选择左侧菜单栏Impulse design脉冲设计——>image图像进行图像的DSP预处理
Raw data中的图像是OpenMV的IDE原生采集的图像
DSP result中是DSP预处理后的图像
Parameters中可以修改图像的格式是RGB565彩图还是GREYSTYLE灰度图

-
在Generate features中生成features
-
显示Job complete完成后可以观察生成的数据集!
我们可以看出face和mask这两种颜色基本上是分开的,而不是混乱地混合在一起地,就证明我们地数据集采集地不错
如果出现全部颜色都特别混乱,交叉混合在一起那么说明我们前期数据集的采集特征不够明显(可能是背景环境太复杂或者是人脸图片种类不够丰富,比如表情单一)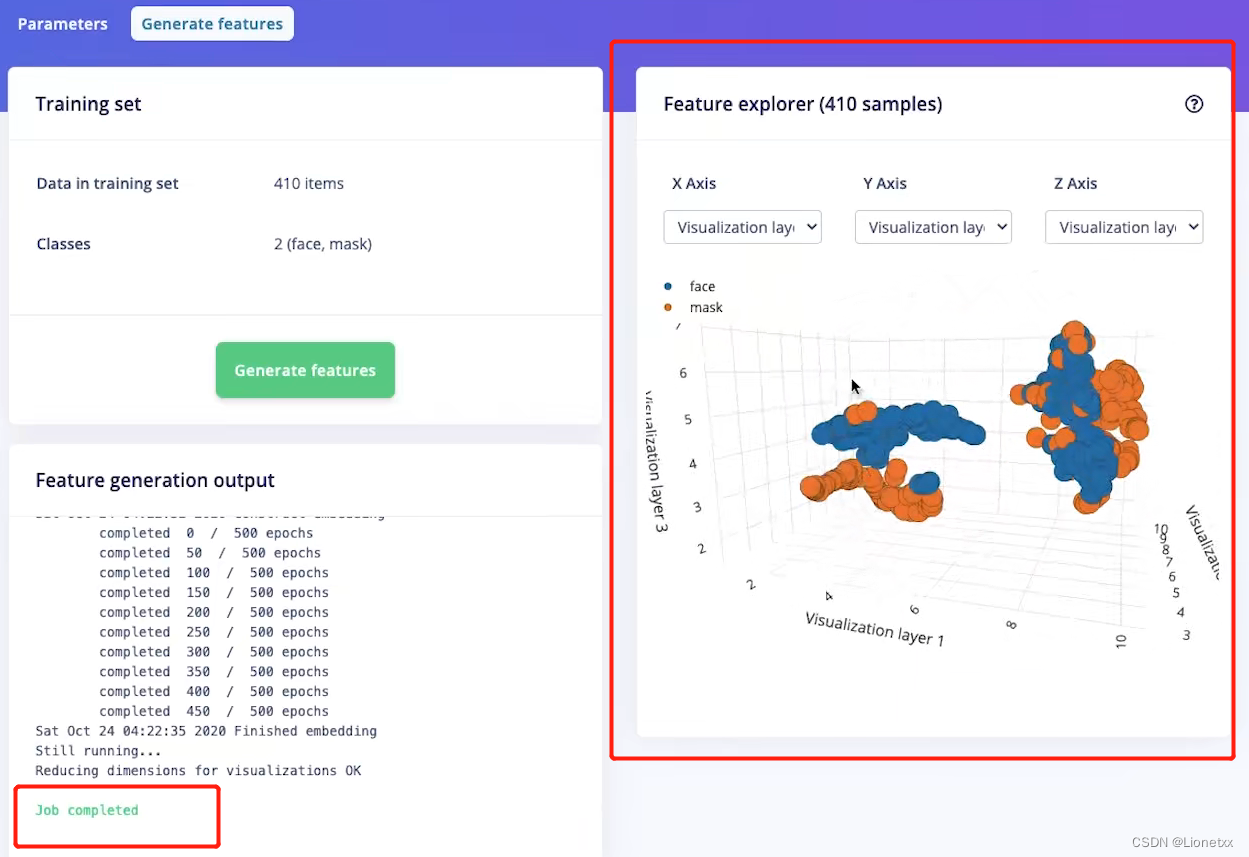
当前我们的数据特征还是比较分明的,因此可以进行下一步
训练神经网络
-
选择左侧菜单栏Impulse design脉冲设计——>Transfer learning进行迁移学习
所有机器学习的参数选择默认均可
-
Number of training cycles设置学习的轮数
-
Learning rate设置学习率,Learning如果设置得大可以提高学习得速度,小了速度会变慢,但过大过小都会导致无法完成学习目标
-
Data augmentation设置数据增强,我们可以勾选也可以不勾选,它可以在训练的过程中随机变换数据,让你训练更多的轮数并且不会过拟合,用来提高训练的准确度
-
Minimum confidence rating设置置信度,默认为0.8
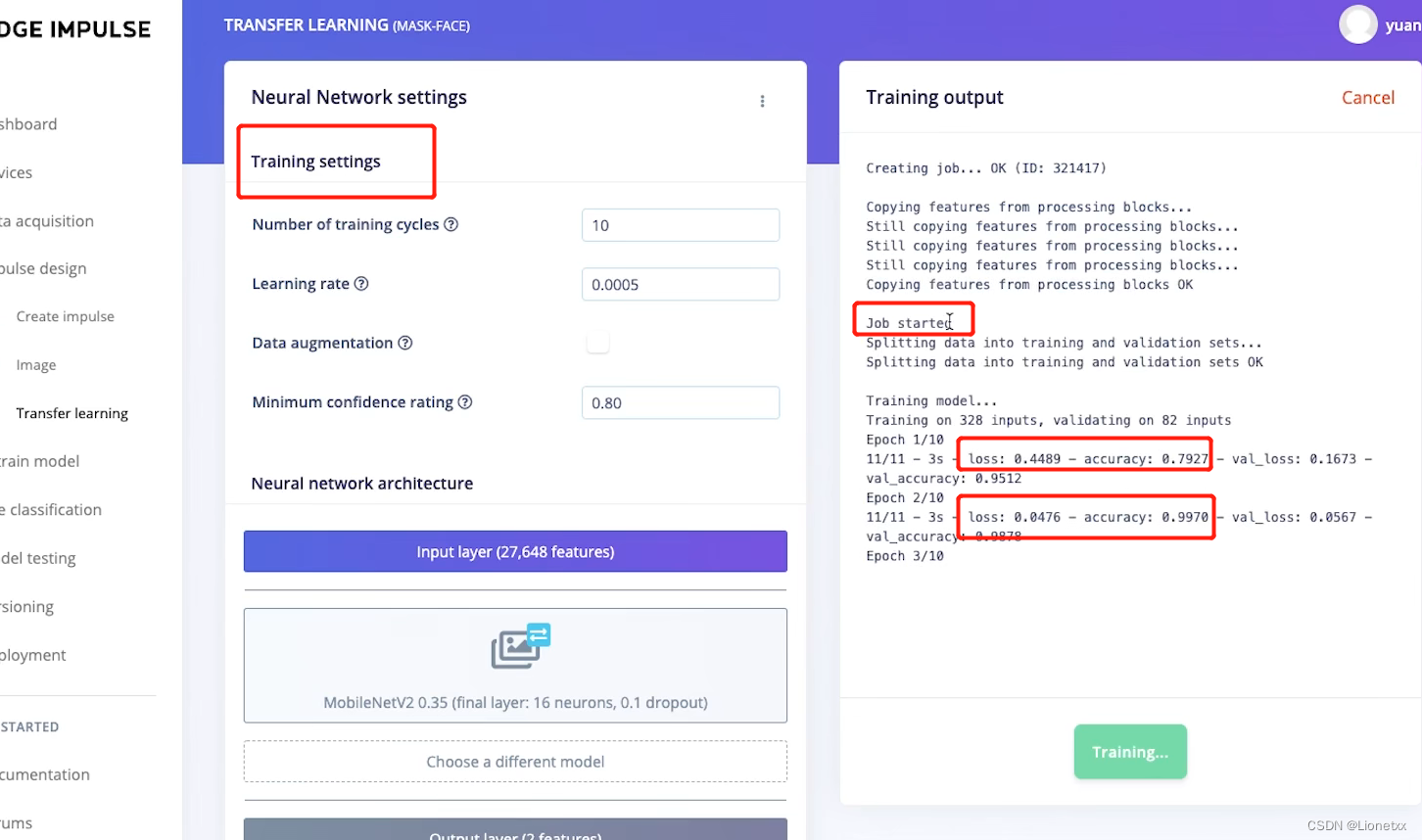
右边会显示工作的进度
Job started表示训练开始- 正常情况下
loss的值是越来越低的,准确度accuracy的值是越来越高的
这个网站是比较智能的,在训练的过程中不一定会达到你设置训练的轮数,如果在中间运行时系统发现结果已经足够准确,那么就会停止训练,防止过拟合
-
显示Job completed后即我们基本的模型已经训练完成,在训练结束后我们可以把页面滑到下面,可以看到训练后得出的数据
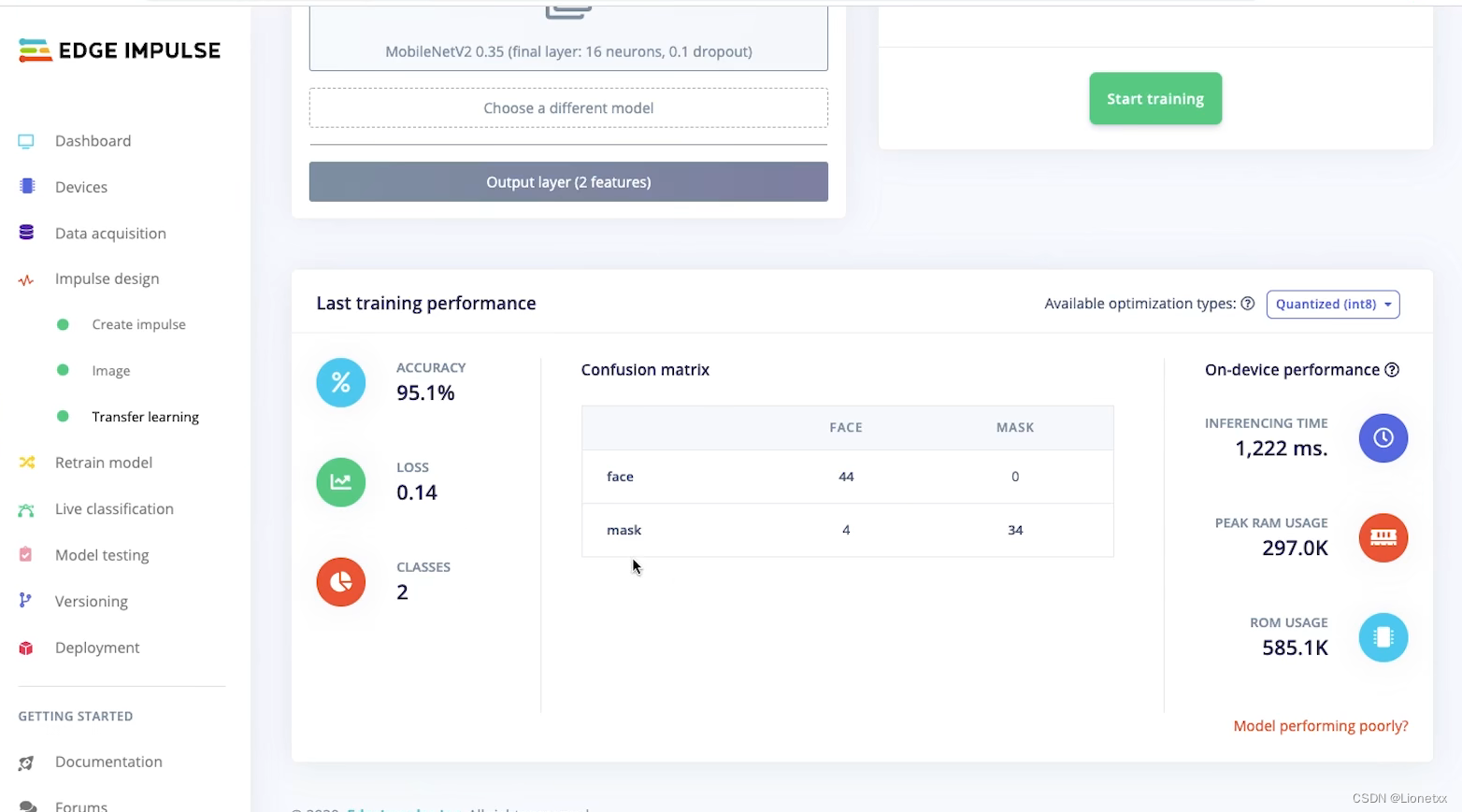
-
左边的三项分别代表准确率accuracy、误差loss、类型classes
-
中间代表confusion matrix代表混淆的元素:如图有4个戴口罩的数据被识别成了没带口罩
-
右边代表了“预估”神经网络在设备上运行的性能表现:需要1.2ms占用RAM297K、占用ROM585.1K
- 左侧菜单栏
Retrain model重新训练模型对我们的神经网络进行重新的训练 - 左侧菜单栏
Live classification实时分类进行单独某张图片的测试
测试神经网络
我们先进行Model testing,下方的文件都是我们的测试集(最开始被分出来的20%),我们利用我们刚刚训练出的模型来对测试集进行测试
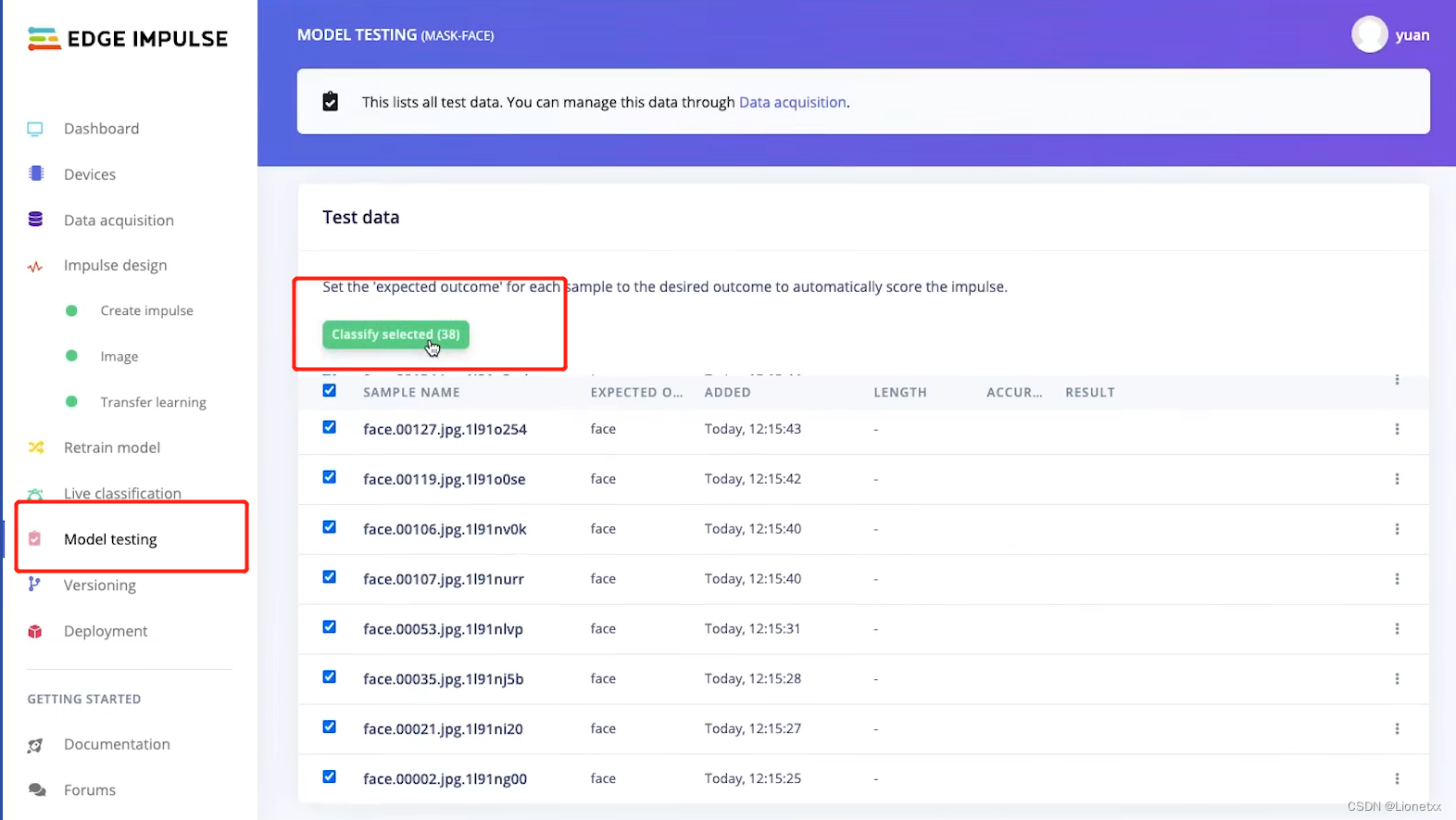
此处我们发现有一张图片是不确定的,我们可以找到这张图片:右键——>show classification查看训练结果
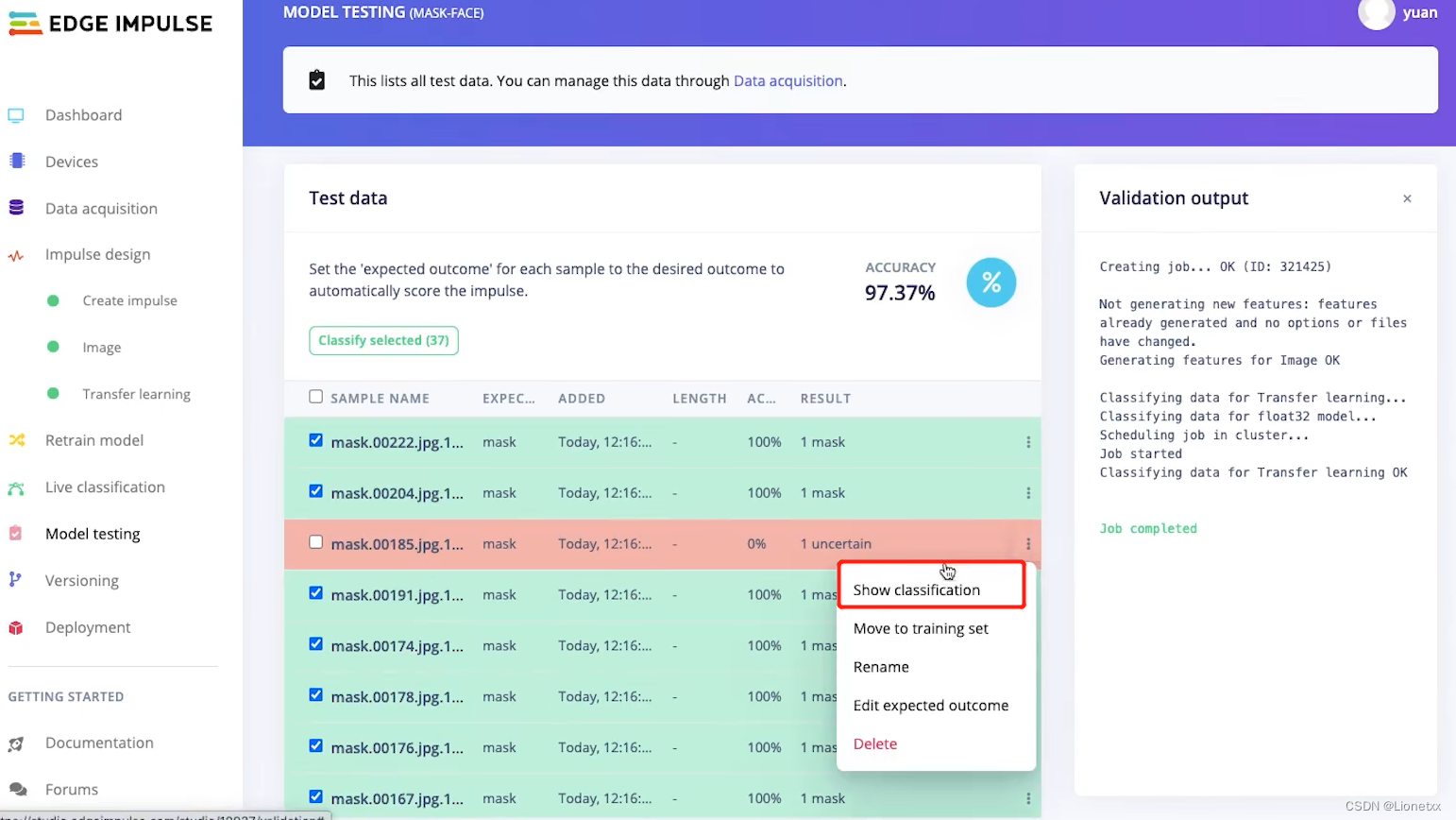
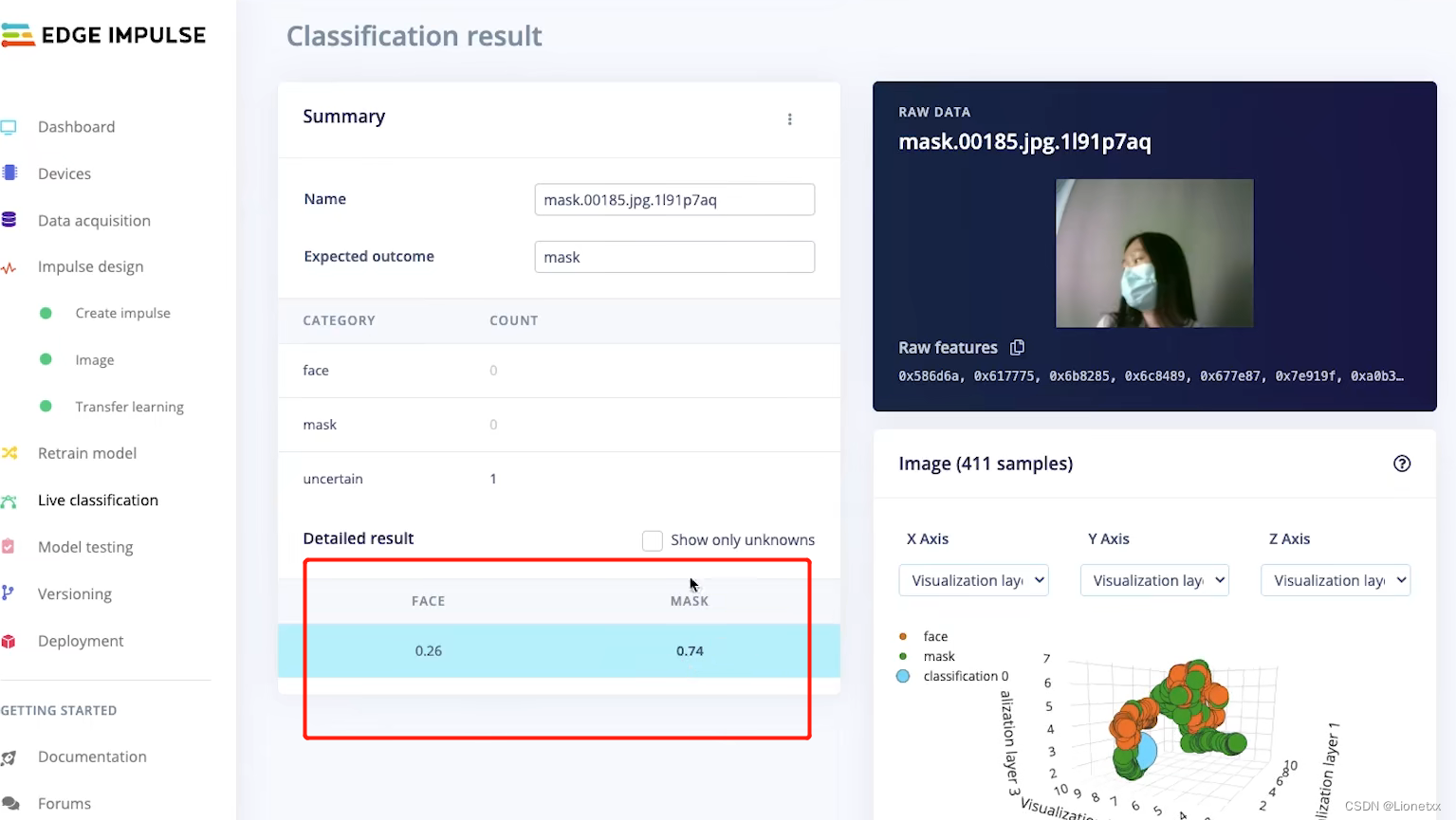
我们发现跳回了刚刚说的Live classification实时分类!其实就是这个意思啦,这张有0.74认为是戴口罩,有0.26认为是不戴口罩(因为头发都遮住了大半张脸)
备份保存
通过Versioning设置版本
可以在这里进行版本的保存,可以在以后的工作直接回来使用这个
不保存的话,下次训练出来的模型就会覆盖当前模型!

4.下载
利用Deployment对训练好的模型进行导出
选择OpenMV——>Bulid,生成后会自动地下载下来
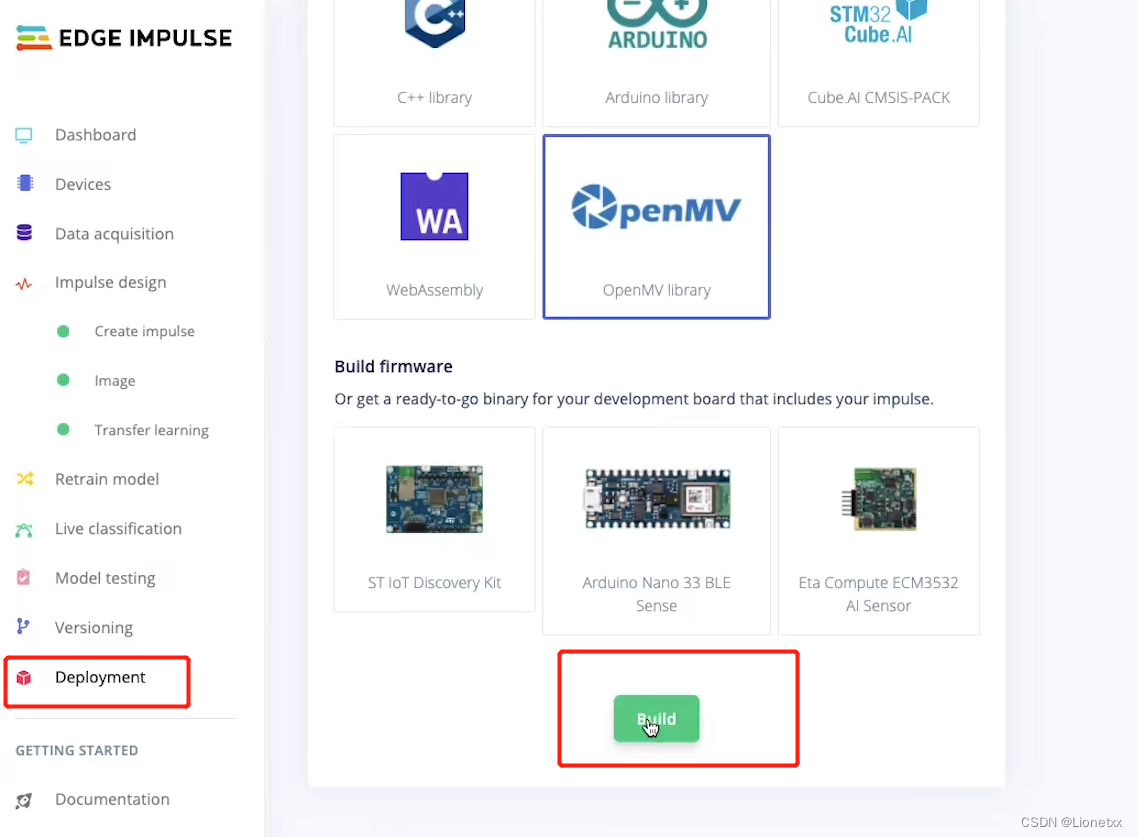
下载后我们发现它生成了三个文件
trained.tfilite是我们生成的模型labels.txt是我们的两个分类:face+mask.py文件是我们在OpenMV上运行的代码

将三个文件拷贝到OpenMV内置的flash中
将.py文件在IDE中打开
代码分析
import sensor, image, time, os, tf
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((240, 240))
sensor.skip_frames(time=2000)
net = "trained.tflite"
labels = [line.rstrip('\n') for line in open("labels.txt")]
clock = time.clock()
while(True):
clock.tick()
img = sensor.snapshot()
for obj in tf.classify(net, img, min_scale=1.0, scale_mul=0.8, x_overlap=0.5, y_overlap=0.5):
print("**********\nPredictions at [x=%d,y=%d,w=%d,h=%d]" % obj.rect())
img.draw_rectangle(obj.rect())
print(obj.output())
predictions_list = list(zip(labels, obj.output()))
for i in range(len(predictions_list)):
print("%s = %f" % (predictions_list[i][0], predictions_list[i][1]))
if predictions_list[0][1]>0.8:
img.draw_string(0,0, 'face')
else:
img.draw_string(0,0, 'mask')
print(clock.fps(), "fps")
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)