玩转Jetson Nano(三):安装Pytorch GPU版
- 前言
- 安装Pytorch GPU版
- 查看CUDA版本号
- 下载Pytorch对应的wheel文件
- 测试是否安装成功
- 常见问题
- OSError: libmpi_cxx.so.20
-
- ImportError: libopenblas.so.0
-
- Illegal instruction(cpre dumped)
-
- 参考文献
前言
- 本文是个人使用Jetson Nano的电子笔记,由于水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入
玩转Jetson Nano专栏或我的个人主页查看
安装Pytorch GPU版
查看CUDA版本号
nvcc -V
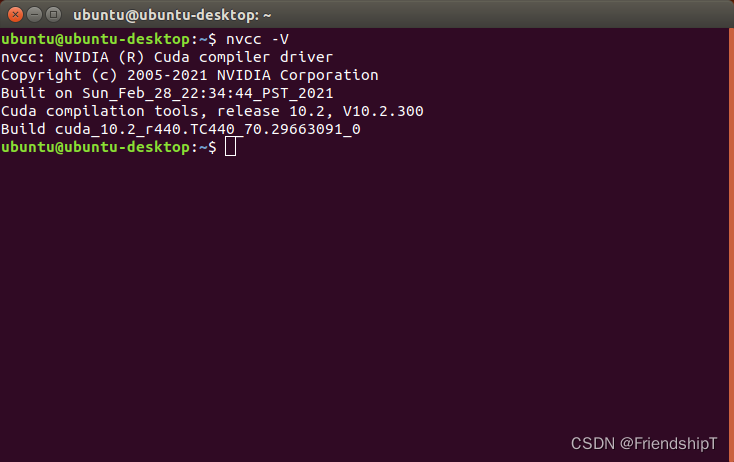
如果nvcc -v 提示未找到命令,可能是环境变量问题,则需要按如下操作:
sudo gedit ~/.bashrc
在/.bashrc中配置LD_LIBRARY_PATH路径、配置PATH路径,完整配置如下:
export LD_LIBRARY_PATH=/usr/local/cuda/lib
export PATH=$PATH:/usr/local/cuda/bin
关闭文件,并使之生效
source ~/.bashrc
即可!
下载Pytorch对应的wheel文件
https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-11-now-available/72048
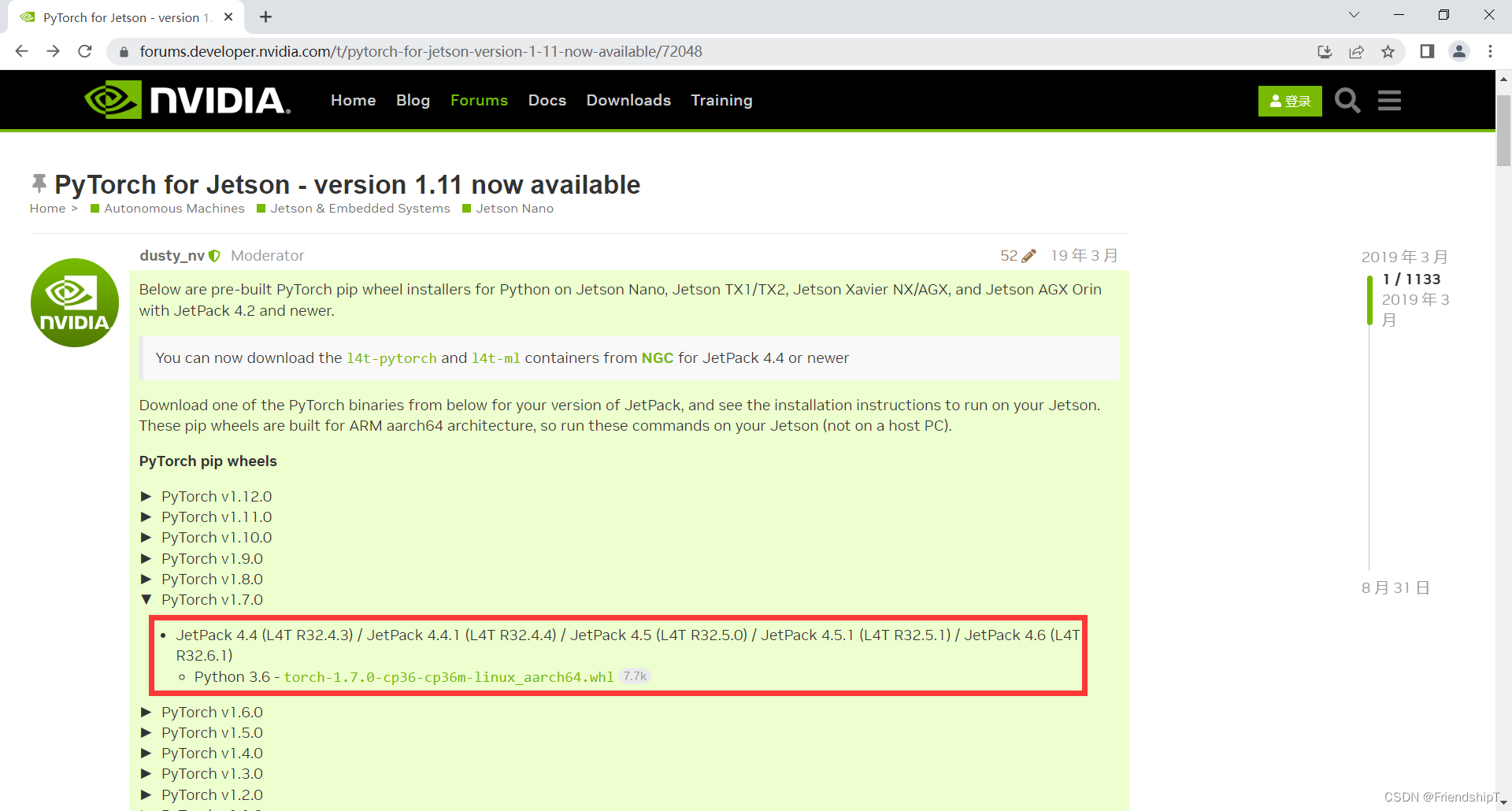
找到torch-1.7.0-cp36-cp36m-linux_aarch64.whl所在的目录
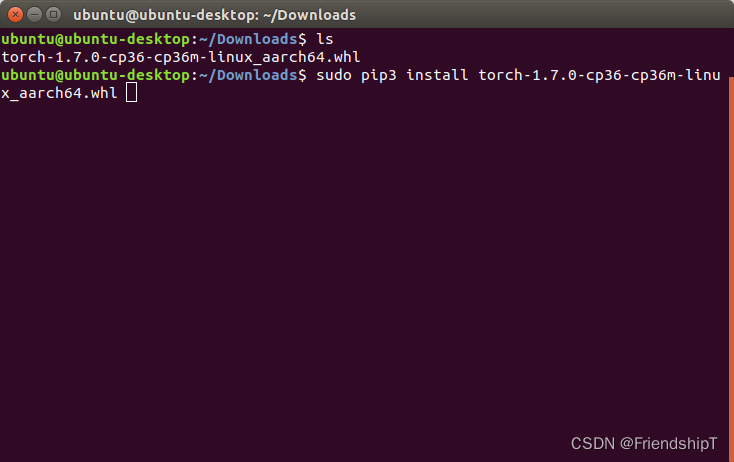
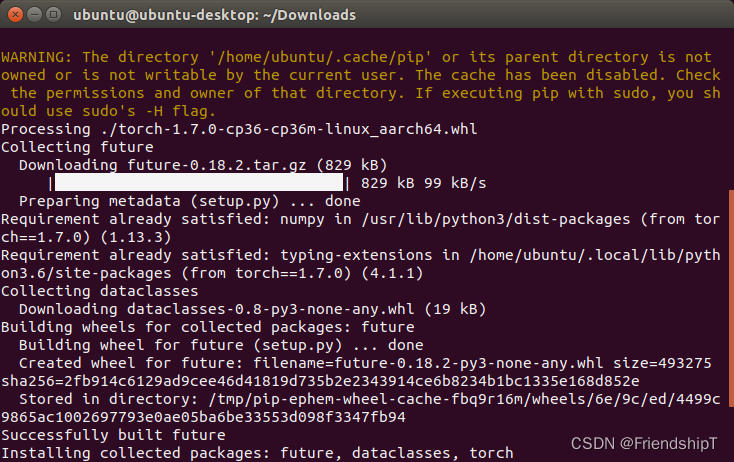
sudo pip3 install torch-1.7.0-cp36-cp36m-linux_aarch64.whl
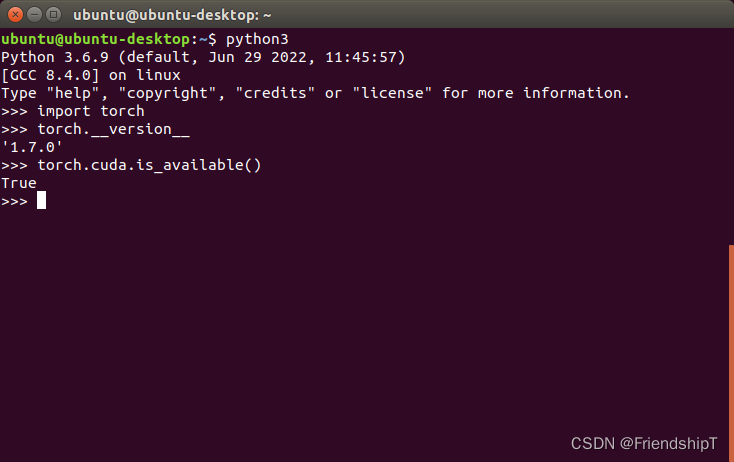
测试是否安装成功
import torch
print(torch.__version__)
print(torch.cuda.is_available())
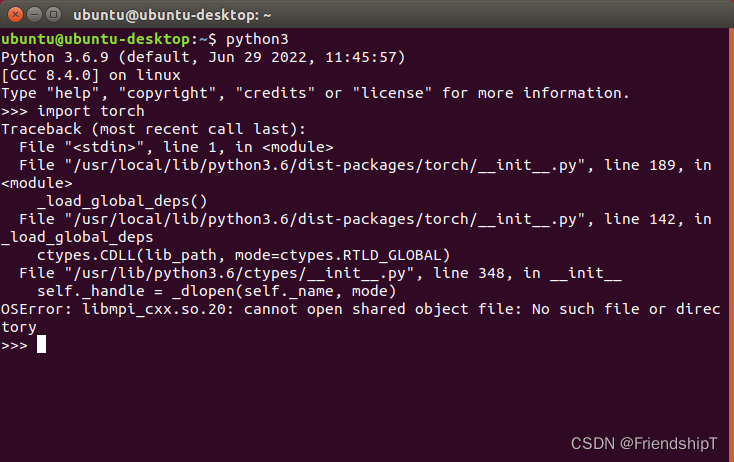
常见问题
OSError: libmpi_cxx.so.20
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/dist-packages/torch/__init__.py", line 189, in <module>
_load_global_deps()
File "/usr/local/lib/python3.6/dist-packages/torch/__init__.py", line 142, in _load_global_deps
ctypes.CDLL(lib_path, mode=ctypes.RTLD_GLOBAL)
File "/usr/lib/python3.6/ctypes/__init__.py", line 348, in __init__
self._handle = _dlopen(self._name, mode)
OSError: libmpi_cxx.so.20: cannot open shared object file: No such file or directory
解决方法
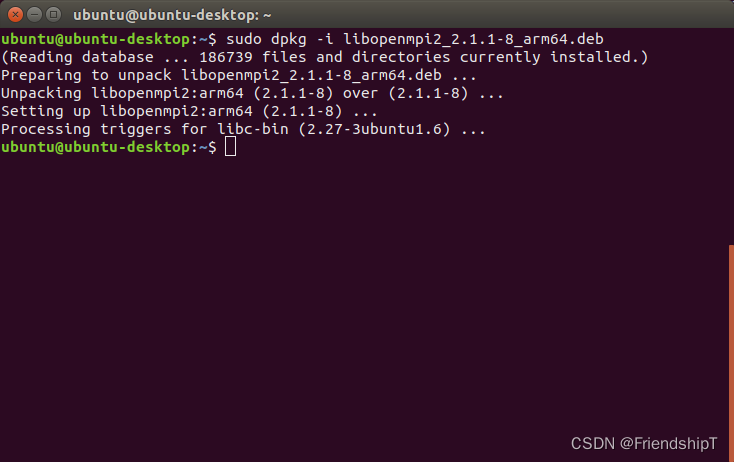
进入https://pkgs.org/网站,搜索libopenmpi,下载libopenmpi2_2.1.1-8_arm64.deb
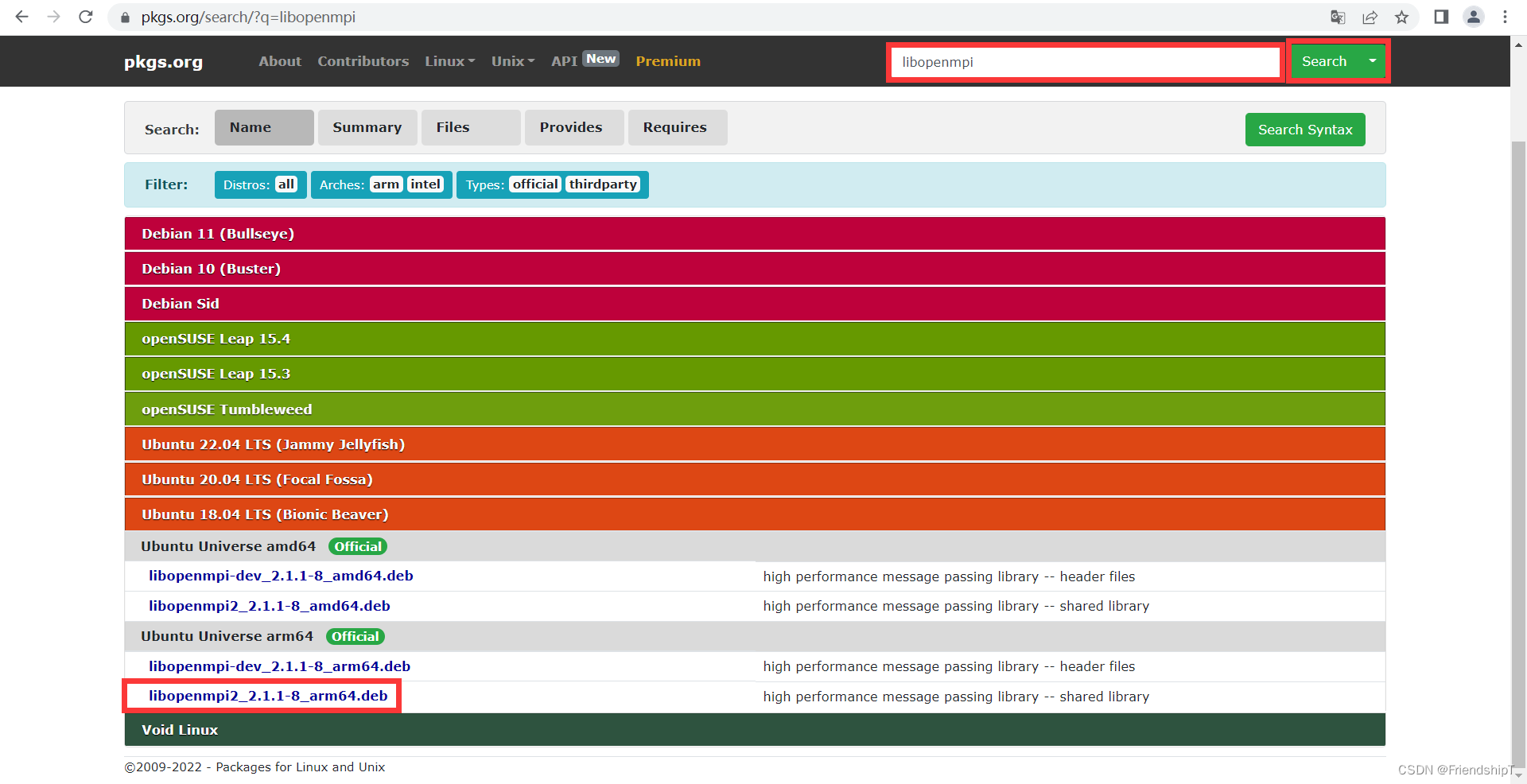
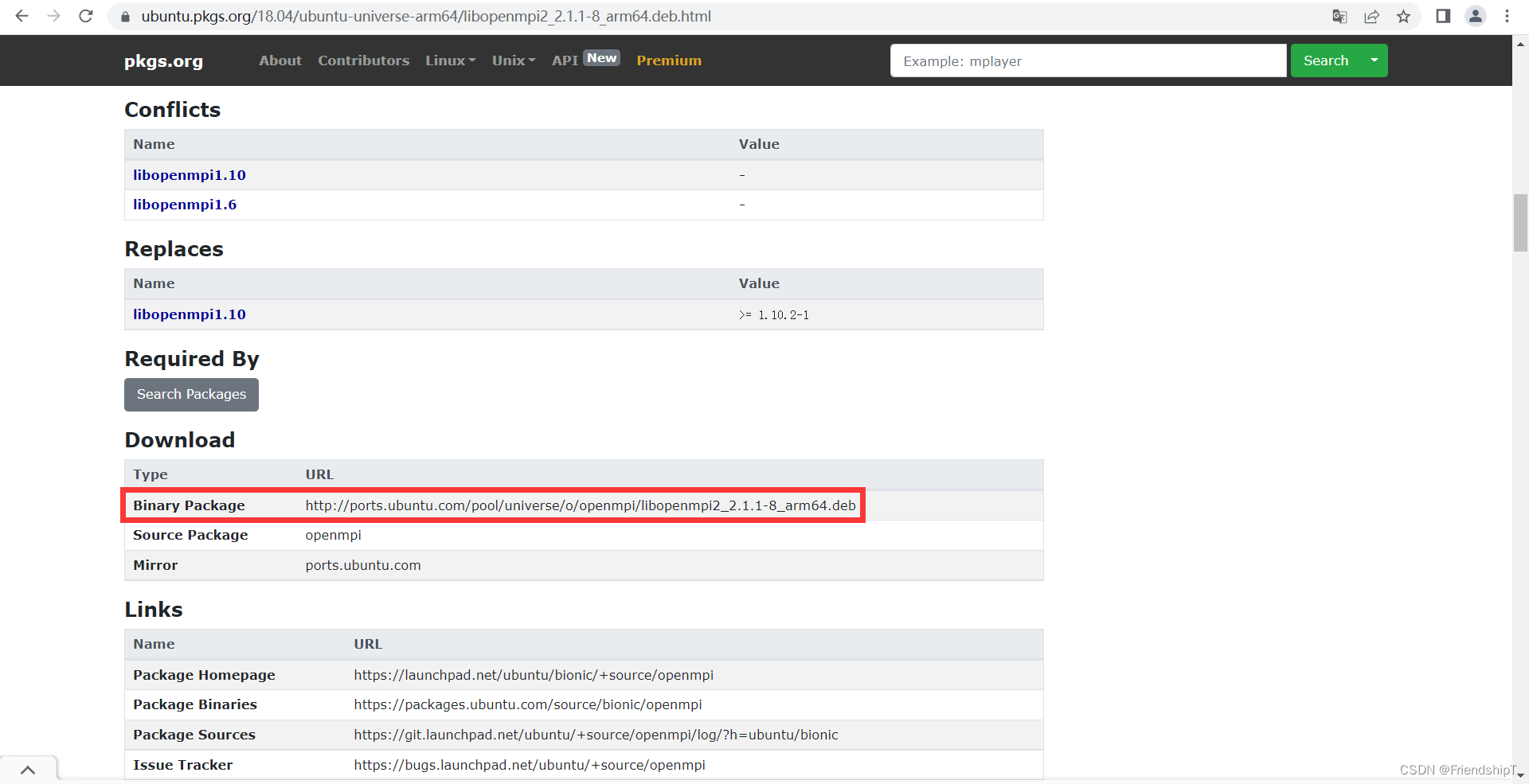
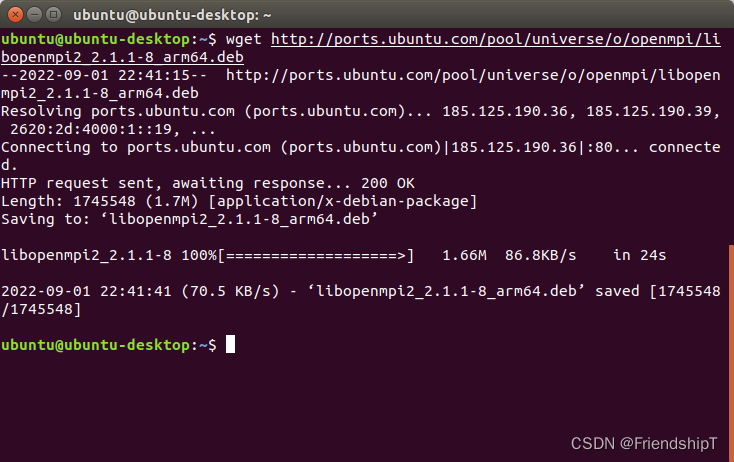
wget http://ports.ubuntu.com/pool/universe/o/openmpi/libopenmpi2_2.1.1-8_arm64.deb
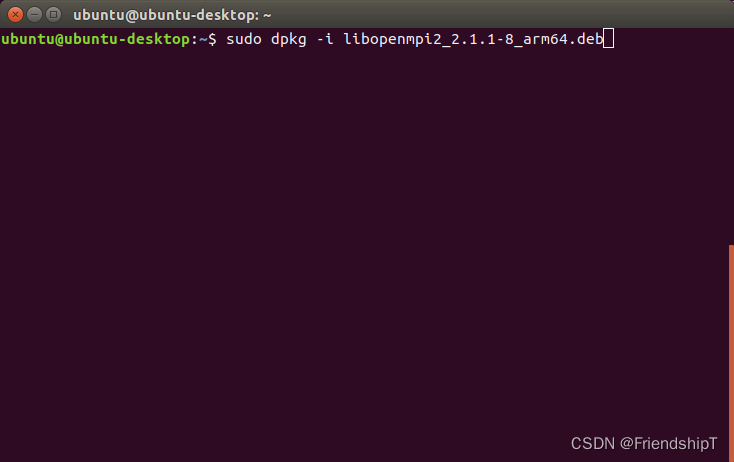
sudo dpkg -i libopenmpi2_2.1.1-8_arm64.deb
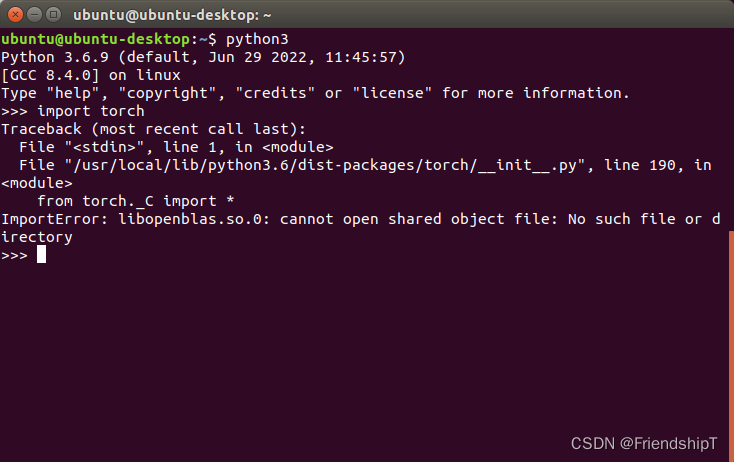
ImportError: libopenblas.so.0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/dist-packages/torch/__init__.py", line 190, in <module>
from torch._C import *
ImportError: libopenblas.so.0: cannot open shared object file: No such file or directory
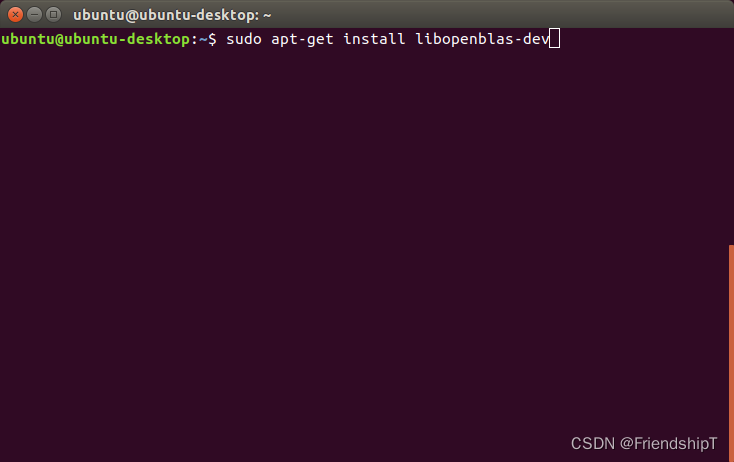
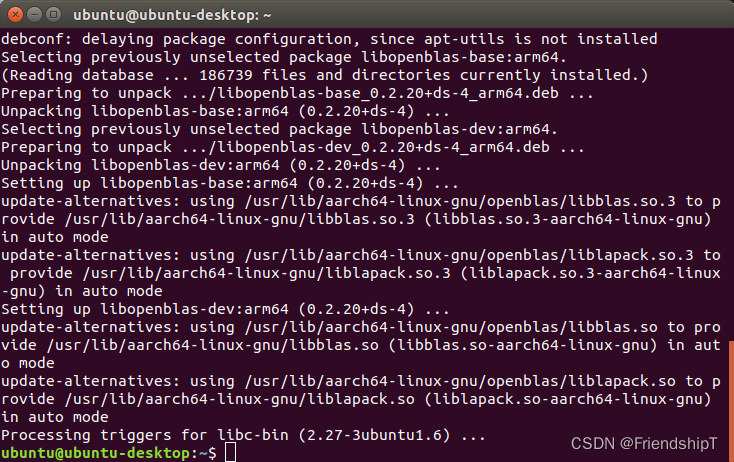
解决方法
sudo apt-get install libopenblas-dev
Illegal instruction(cpre dumped)
>>>import torch
Illegal instruction(cpre dumped)
解决方法
具体解决方法,请点击查阅解决:Jetson系列 python3 import 报错 Illegal instruction (core dumped)
参考文献
[1] Jetson Nano Developer Kit User Guide
[2] https://docs.nvidia.com/deeplearning/frameworks/install-pytorch-jetson-platform-release-notes/index.html
[3] https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-11-now-available/72048
- 更多精彩内容,可点击进入
玩转Jetson Nano专栏或我的个人主页查看
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)