前言:
Ceph作为开源的分布式文件系统,可以轻松地将存储容量扩展到PB以上并拥有不错的性能。Ceph提供对象存储、块存储和文件系统三种存储方式,如果不想花时间安装ceph,可以通过ceph-docker来部署Ceph集群,使用容器部署Ceph集群的一大好处就是不用为升级而烦恼,本篇文章将手把手带你快速在单节点上部署Ceph集群。
本教程采用的Linux及相关软件版本如下:
CentOS Linux release 7.8.2003版本
Docker的版本是20.10.10
Ceph的版本是nautilus-latest 14.2.22
机器初始化
部署Ceph之前我们需要对自身机器的环境做初始化。主要涉及到防火墙,主机名等设置。
1. 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
2.关闭selinux(linux的安全子系统)
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
PS: 正式环境实际部署时,最好通过加入IP白名单的方式来操作,而不是直接关闭防火墙。
3. 设置主机名,把虚拟机的主机名设置成ceph
hostnamectl set-hostname ceph
在节点上执行下列命令配置host。
cat >> /etc/hosts <<EOF
192.168.129.16 ceph
EOF
4.设置时间同步
chronyd服务的作用是用于同步不同机器的时间。如果不打开时间同步服务,则有可能会出现 clock skew detected on mon问题。
timedatectl set-timezone Asia/Shanghai
date
yum -y install chrony
systemctl enable chronyd
systemctl start chronyd.service
sed -i -e '/^server/s/^/#/' -e '1a server ntp.aliyun.com iburst' /etc/chrony.conf
systemctl restart chronyd.service
sleep 10
timedatectl
5.其他配置 把容器内的 ceph 命令 alias 到本地,方便使用,其他 ceph 相关命令也可以参考添加:
echo 'alias ceph="docker exec mon ceph"' >> /etc/profile
source /etc/profile
6. 创建Ceph目录 在宿主机上创建Ceph目录与容器建立映射,便于直接操纵管理Ceph配置文件,以root身份在节点ceph上创建这四个文件夹,命令如下:
mkdir -p /usr/local/ceph/{admin,etc,lib,logs}
该命令会一次创建4个指定的目录,注意逗号分隔,不能有空格。其中:
- admin文件夹下用于存储启动脚本。
- etc文件夹下存放了ceph.conf等配置文件。
- lib文件夹下存放了各组件的密钥文件。
- logs文件夹下存放了ceph的日志文件。
7. 对文件夹进行docker内用户授权
chown -R 167:167 /usr/local/ceph/ #docker内用户id是167,这里进行授权
chmod 777 -R /usr/local/ceph
上面的初始化做完之后,下面我们就开始具体的部署。
部署ceph集群
安装ceph集群的基础组件 mon,osd,mgr,rgw ,mds
1. 创建OSD磁盘
创建OSD磁盘 OSD服务是对象存储守护进程,负责把对象存储到本地文件系统,必须要有一块独立的磁盘作为存储。
lsblk
fdisk /dev/vdb 创建出三个分区。/dev/vdb1 /dev/vdb2 /dev/vdb3
操作方法可以参考:https://jingyan.baidu.com/article/cbf0e500a9731e2eab289371.html
格式化并挂在磁盘
mkfs.xfs -f /dev/vdb1;mkfs.xfs -f /dev/vdb2;mkfs.xfs -f /dev/vdb3
mkdir -p /dev/osd1 ;mount /dev/vdb1 /dev/osd1
mkdir -p /dev/osd2 ;mount /dev/vdb2 /dev/osd2
mkdir -p /dev/osd3 ;mount /dev/vdb3 /dev/osd3
创建后的效果
[root@ceph ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 50G 0 disk
├─vda1 252:1 0 2M 0 part
├─vda2 252:2 0 256M 0 part /boot
└─vda3 252:3 0 49.8G 0 part
└─centos-root 253:0 0 49.8G 0 lvm /
vdb 252:16 0 300G 0 disk
├─vdb1 252:17 0 100G 0 part /dev/osd1
├─vdb2 252:18 0 100G 0 part /dev/osd2
└─vdb3 252:19 0 100G 0 part /dev/osd3
2. 安装docker并获取ceph镜像
安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
#添加docker软件包的yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
直接安装Docker CE最新版
yum install docker-ce -y
systemctl restart docker && systemctl enable docker
#配置docker 使用阿里云加速
mkdir -p /etc/docker/
touch /etc/docker/daemon.json
> /etc/docker/daemon.json
cat <<EOF >> /etc/docker/daemon.json
{
"registry-mirrors":["https://q2hy3fzi.mirror.aliyuncs.com"]
}
EOF
systemctl daemon-reload && systemctl restart docker
docker info
拉取ceph镜像
这里用到了 dockerhub 上最流行的 ceph/daemon 镜像(这里需要拉取nautilus版本的ceph,latest-nautilus)
docker pull ceph/daemon:latest-nautilus
3. 编写启动脚本开始部署。(脚本都放在admin文件夹下)
(1) 创建并启动mon组件
vi /usr/local/ceph/admin/start_mon.sh
#!/bin/bash
docker run -d --net=host \
--name=mon \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-e MON_IP=192.168.129.16 \
-e CEPH_PUBLIC_NETWORK=192.168.128.0/20 \
ceph/daemon:latest-nautilus mon
这个脚本是为了启动监视器,监视器的作用是维护整个Ceph集群的全局状态。一个集群至少要有一个监视器,最好要有奇数个监视器。方便当一个监视器挂了之后可以选举出其他可用的监视器。启动脚本说明:
- name参数,指定节点名称,这里设为mon
- -v xxx:xxx 是建立宿主机与容器的目录映射关系,包含 etc、lib、logs目录。
- MON_IP是Docker运行的IP地址(通过ifconfig来查询,取eth0里的inet那个IP),这里我们有3台服务器,那么MAN_IP需要写上3个IP,如果IP是跨网段的CEPH_PUBLIC_NETWORK必须写上所有网段。
- CEPH_PUBLIC_NETWORK配置了运行Docker主机所有网段 这里必须指定nautilus版本,不然会默认操作最新版本ceph,mon必须与前面定义的name保持一致。
启动MON 在节点ceph上执行
bash /usr/local/ceph/admin/start_mon.sh
启动后通过docker ps -a|grep mon查看启动结果,启动成功之后生成配置数据,在ceph主配置文件中,追加如下内容:
cat >>/usr/local/ceph/etc/ceph.conf <<EOF
# 容忍更多的时钟误差
mon clock drift allowed = 2
mon clock drift warn backoff = 30
# 允许删除pool
mon_allow_pool_delete = true
mon_warn_on_pool_no_redundancy = false
osd_pool_default_size = 1
osd_pool_default_min_size = 1
osd crush chooseleaf type = 0
[mgr]
# 开启WEB仪表盘
mgr modules = dashboard
[client.rgw.ceph1]
# 设置rgw网关的web访问端口
rgw_frontends = "civetweb port=20003"
EOF
启动后通过 ceph -s查看集群状态,此时的状态应该是HEALTH_OK状态。
若遇到health: HEALTH_WARN mon is allowing insecure global_id reclaim
可以如下命令执行:
ceph config set mon auth_allow_insecure_global_id_reclaim false
(2) 创建并启动osd组件
vi /usr/local/ceph/admin/start_osd.sh
#!/bin/bash
docker run -d \
--name=osd1 \
--net=host \
--restart=always \
--privileged=true \
--pid=host \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-v /dev/osd1:/var/lib/ceph/osd \
ceph/daemon:latest-nautilus osd_directory
docker run -d \
--name=osd2 \
--net=host \
--restart=always \
--privileged=true \
--pid=host \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-v /dev/osd2:/var/lib/ceph/osd \
ceph/daemon:latest-nautilus osd_directory
docker run -d \
--name=osd3 \
--net=host \
--restart=always \
--privileged=true \
--pid=host \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-v /dev/osd3:/var/lib/ceph/osd \
ceph/daemon:latest-nautilus osd_directory
这个脚本是用于启动OSD组件的,OSD(Object Storage Device)是RADOS组件,其作用是用于存储资源。脚本说明:
- name 是用于指定OSD容器的名称
- net 是用于指定host,就是前面我们配置host
- restart指定为always,使osd组件可以在down时重启。
- privileged是用于指定该osd是专用的。这里我们采用的是osd_directory 镜像模式
PS: osd的个数最好维持在奇数个.
启动OSD 在节点ceph上执行 在执行start_osd.sh脚本之前,首先需要在mon节点生成osd的密钥信息,不然直接启动会报错。命令如下:
docker exec -it mon ceph auth get client.bootstrap-osd -o /var/lib/ceph/bootstrap-osd/ceph.keyring
接着在节点上执行如下命令:
bash /usr/local/ceph/admin/start_osd.sh
全部osd都启动之后,稍等片刻后,执行ceph -s查看状态,应该可以看到多了3个osd
(3) 创建并启动mgr组件
vi /usr/local/ceph/admin/start_mgr.sh
#!/bin/bash
docker run -d --net=host \
--name=mgr \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
ceph/daemon:latest-nautilus mgr
这个脚本是用于启动mgr组件,它的主要作用是分担和扩展monitor的部分功能,提供图形化的管理界面以便我们更好的管理ceph存储系统。其启动脚本比较简单,在此不再赘述。
启动MGR 直接在节点ceph上执行如下命令:
bash /usr/local/ceph/admin/start_mgr.sh
mgr启动之后,稍等片刻后,执行ceph -s查看状态,应该可以看到多了1个mgr
(4) 创建并启动rgw组件
vi /usr/local/ceph/admin/start_rgw.sh
#!/bin/bash
docker run \
-d --net=host \
--name=rgw \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
ceph/daemon:latest-nautilus rgw
该脚本主要是用于启动rgw组件,rgw(Rados GateWay)作为对象存储网关系统,一方面扮演RADOS集群客户端角色,为对象存储应用提供数据存储,另一方面扮演HTTP服务端角色,接受并解析互联网传送的数据。
启动RGW 同样的我们首先还是需要先在mon节点生成rgw的密钥信息,命令如下:
docker exec mon ceph auth get client.bootstrap-rgw -o /var/lib/ceph/bootstrap-rgw/ceph.keyring
接着在节点ceph上执行如下命令:
bash /usr/local/ceph/admin/start_rgw.sh
rgw启动之后,ceph -s 查看可能会出现Degraded降级的情况,我们需要手动设置rgw pool的size 和 min_size为最小1
ceph osd pool set .rgw.root min_size 1
ceph osd pool set .rgw.root size 1
ceph osd pool set default.rgw.control min_size 1
ceph osd pool set default.rgw.control size 1
ceph osd pool set default.rgw.meta min_size 1
ceph osd pool set default.rgw.meta size 1
ceph osd pool set default.rgw.log min_size 1
ceph osd pool set default.rgw.log size 1
若ceph -s 报错提示pools have not replicas configured 可以暂时忽略 因为在该版本中pool size 设置为1的时候便会触发告警。
Pool size needs to be greater than 1 otherwise HEALTH_WARN is reported. Ceph will issue a health warning if a RADOS pool’s size is set to 1 or if the pool is configured with no redundancy. Ceph will stop issuing the warning if the pool size is set to the minimum recommended value:
可参考:https://documentation.suse.com/ses/6/html/ses-all/bk02apa.html
可使用如下命令禁止发送告警:(若还存在先暂时忽略)
ceph config set global mon_warn_on_pool_no_redundancy false
(5) 创建并启动mds组件
vi /usr/local/ceph/admin/start_mds.sh
#!/bin/bash
docker run -d --net=host \
--name=mds \
--privileged=true \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-e CEPHFS_CREATE=O \
-e CEPHFS_METADATA_POOL_PG=64 \
-e CEPHFS_DATA_POOL_PG=64 \
ceph/daemon:latest-nautilus mds
启动MDS
bash /usr/local/ceph/admin/start_mds.sh
至此所有组件启动完成。
4.创建FS文件系统
在ceph节点执行即可。
创建Data Pool和创建Metadata Pool:
ceph osd pool create cephfs_data 64 64
ceph osd pool create cephfs_metadata 64 64
注意:如果受mon_max_pg_per_osd限制, 不能设为128,可以调小点, 改为64。
创建CephFS:
ceph fs new cephfs cephfs_metadata cephfs_data
将上面的数据池与元数据池关联, 创建cephfs的文件系统并查看FS信息:
ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
或者
ceph fs status cephfs
ceph osd pool set cephfs_data min_size 1
ceph osd pool set cephfs_data size 1
ceph osd pool set cephfs_metadata min_size 1
ceph osd pool set cephfs_metadata size 1
启动完成之后再通过ceph-s查看集群的状态
[root@ceph ~]# ceph -s
cluster:
id: 7a3e7b33-2b71-45ee-bb62-3320fb0e9d51
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph (age 21m)
mgr: ceph(active, since 20m)
mds: cephfs:1 {0=ceph=up:active}
osd: 3 osds: 3 up (since 56m), 3 in (since 56m)
rgw: 1 daemon active (ceph)
task status:
data:
pools: 6 pools, 256 pgs
objects: 209 objects, 3.4 KiB
usage: 3.0 GiB used, 297 GiB / 300 GiB avail
pgs: 256 active+clean
[root@ceph ~]#
5.验证cephfs可用性
在另外一台节点上安装ceph-fuse:
yum -y install epel-release
rpm -Uhv http://download.ceph.com/rpm-jewel/el7/noarch/ceph-release-1-1.el7.noarch.rpm
yum install -y ceph-fuse
mkdir /etc/ceph
在ceph集群里获取admin.key
ceph auth get-key client.admin
配置admin.key
vi /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = xxxxxxxxxxxxxxx
安装成功后使用如下命令进行挂载:
ceph-fuse -m 192.168.129.16:6789 -r / /mnt/ -o nonempty
df -h 查看挂载情况
ceph-fuse 300G 3.1G 297G 2% /mnt
挂载成功。
6.安装ceph的Dashboard管理后台
在ceph节点执行即可。
开启dashboard功能
docker exec mgr ceph mgr module enable dashboard
创建证书
docker exec mgr ceph dashboard create-self-signed-cert
创建登陆用户与密码:
docker exec mgr ceph dashboard set-login-credentials admin admin
设置用户名为admin, 密码为admin。
注意我使用这条命令的时候报错了dashboard set-login-credentials <username> : Set the login credentials. Password read from -i <file>
我手动在mgr容器中创建了/tmp/ceph-password.txt 在里面写入了密码admin
然后执行如下命令就成功了:
docker exec -it mgr bash
vi /tmp/ceph-password.txt
admin
exit
docker exec mgr ceph dashboard ac-user-create admin -i /tmp/ceph-password.txt administrator
配置外部访问端口
docker exec mgr ceph config set mgr mgr/dashboard/server_port 18080
配置外部访问IP
docker exec mgr ceph config set mgr mgr/dashboard/server_addr 192.168.129.16
关闭https(如果没有证书或内网访问, 可以关闭)
docker exec mgr ceph config set mgr mgr/dashboard/ssl false
重启Mgr DashBoard服务
docker restart mgr
查看Mgr DashBoard服务信息
[root@ceph admin]# docker exec mgr ceph mgr services
{
"dashboard": "http://ceph:18080/"
}
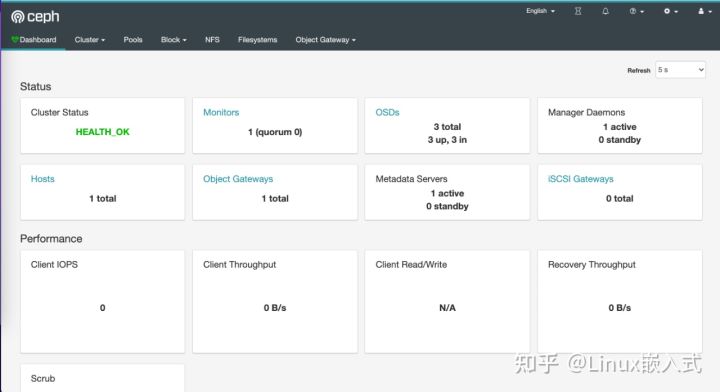
7.访问管理控制台界面:
浏览器中访问:
http://192.168.129.16:18080/#/dashboard
用户名和密码:admin/admin
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)