一、前因
在项目开发遇到一个问题:读取flash的所有数据到文件,然后用烧录器去烧写到新的flash,烧录后机子起不来。后面发现是从flash读出的数据需要经过字节序转换之后才能用烧录器烧录。于是,自己便写了一个转换的程序。并不是所有从flash读出的数据都需要转换的,是否需要转换取决于开发板数据存放方式和烧录器对数据的处理这两个因素。
二、字节序概述
字节序是指多字节数据在计算机内存中存储或者网络传输时各字节的存储顺序。
分为以下两种:
Little endian:将低序字节存储在起始地址
Big endian:将高序字节存储在起始地址
如下,一个判断大小端的一个小程序:
typedef union {
int i;
char c;
}my_union;
int isLittleEndian(void)
{
my_union u;
u.i = 1;
return (u.i == u.c);
}
int main()
{
//系统大小端测试
if (isLittleEndian())
printf("is Little Endian!\n");
else
printf("is big endian!\n");
return 0;
}
在编译工具中查看数据在内存中的存储方式,就可以知道是大端还是小端。如下:
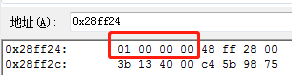
从左到右,内存地址是不断增大的。0x28ff24 地址是&u 。红色方框中,整型 i 低字节存放的是起始地址,所以数据存放方式是小端。如果是大端系统,测试的结果红色方框的数据依次为:00 00 00 01。也就是说大小端,四字节的存放顺序是反着的。这将是下面实现大小端转换的一个基准。
三、字节序大小端转换程序
//turnEndian.c
#include
#include
#include
#include
#define BUFFER_SIZE 1024*8
int changeEndian(char *cFileTurnBefore,char *cFileTurnAfter)
{
FILE *fd_before = NULL;
FILE *fd_after = NULL;
int i = 0, ret = 0;
fd_before= fopen(cFileTurnBefore,"rb");
if(fd_before == NULL)
{
printf("%s is not exist!\n",cFileTurnBefore);
return -1;
}
fd_after = fopen(cFileTurnAfter,"wb+");
if(fd_after == NULL)
{
printf("%s is not exist!\n",cFileTurnAfter);
ret = -1;
}
unsigned char *pBuf = (unsigned char *)calloc(BUFFER_SIZE,1);
if (pBuf == NULL)
{
printf("calloc memery failed!\n");
ret = -1;
}
unsigned char *pTmp = (unsigned char *)calloc(BUFFER_SIZE,1);
if (pTmp == NULL)
{
printf("calloc memery failed!\n");
ret = -1;
}
while(1)
{
int writeLen = 0, bytes_write = 0;
if (ret == -1)
{
perror("error.............\n");
break;
}
int readLen = fread(pBuf,1,BUFFER_SIZE,fd_before);
if (readLen == 0) //如果不成功或读到文件末尾返回 0
{
printf("read %s end!\n",cFileTurnBefore);
break;
}
for(i = 0;i < readLen;i ++)
{
pTmp[i] = pBuf[i/4 * 4 + 3 - i%4];
}
while (bytes_write < readLen)
{
writeLen = fwrite(pTmp + bytes_write,1,(readLen - bytes_write),fd_after);
if (writeLen == 0)
{
ret = -1;
break;
}
bytes_write += writeLen;
}
bzero(pBuf,BUFFER_SIZE);
}
if (ret != -1)
{
//转换前后文件大小必须是一样的
fseek(fd_before,0,SEEK_END);
fflush(fd_after);//确保将缓存区的数据写到文件
fseek(fd_after,0,SEEK_END);
if (ftell (fd_before) != ftell (fd_after))
{
printf("turn endian failed , now detele the cFileTurnAfter!\n");
fclose(fd_after);
fd_after = NULL;
remove(cFileTurnAfter); //也可在调用该函数之后处理
ret = -1;
}
printf("before:%ld,after:%ld\n",ftell(fd_before),ftell(fd_after));
}
else
{
if(0 == access(cFileTurnAfter, F_OK))
{
fclose(fd_after);
fd_after = NULL;
remove(cFileTurnAfter); //也可在调用该函数之后处理
}
}
if (pTmp != NULL)
{
free(pTmp);
pTmp = NULL;
}
if (pBuf != NULL)
{
free(pBuf);
pBuf = NULL;
}
if (fd_before != NULL)
{
fclose(fd_before);
fd_before = NULL;
}
if (fd_after != NULL)
{
fclose(fd_after);
fd_after = NULL;
}
return ret;
}
typedef union {
int i;
char c;
}my_union;
int isLittleEndian(void)
{
my_union u;
u.i = 1;
return (u.i == u.c);
}
int main(int argc,char *argv[])
{
if (argc != 3)
{
printf("please run eg: ./turnEndian srcFile destFile\n");
return 0;
}
//系统大小端测试
if (isLittleEndian())
printf("is Little Endian!\n");
else
printf("is big endian!\n");
char *fileTurnBefore = argv[1];
char *fileTurnAfter = argv[2];
if (changeEndian(fileTurnBefore,fileTurnAfter) < 0)
perror("changeEndian!\n");
printf("changeEndian success");
}
以上程序,用的是带缓冲的读写函数fread和fwrite。大量数据可以存放在缓冲区,再写入文件中,效率比read和write函数高了许多。changeEndian函数是可以直接放在项目中使用的,总体来说是比较健壮的,体现在如下几个方面:
调用库函数的时候都有对函数的返回值做处理,如果出错,则不进行转换。
转换输出的文件会跟转换之前的文件做长度比较,如果不一致,则把转换之后的文件删除,并返回-1。
无论转换是否成功,都有进行文件关闭和内存释放。
有考虑到fread一次不能全部读完和fwrite一次不能全部写完的情况,程序适应性更广。
可以修改 BUFFER_SIZE 的值,适应不同嵌入式内存使用率不同情况。
字节序转换的技巧依靠如下,可以手动列出规律,然后推导出来。
for(i = 0;i < readLen;i ++)
{
pTmp[i] = pBuf[i/4 * 4 + 3 - i%4];
}
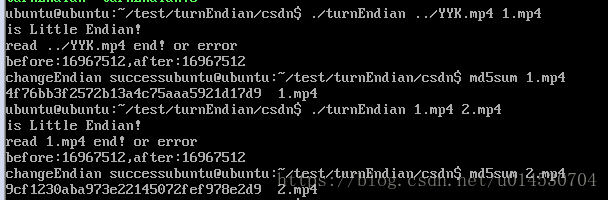
程序是比较简单,但需要考虑健壮性。实验一下结果,发现转换两次之后,用md5校验是一致的,从以下结果可以看出程序是正确的。