真的是很久没有更新我的博客了,刚开始,我还真的不知道爬虫是什么东西,但是由于项目需要,老板要我做个简单的爬虫,就是去人家的微信公众号去把里面的文章动态的抓取下来,当听到这个事情的时候,我是激动的,因为要我接触一个未知的领域,这是一个很值得装逼的是!!!!
好了屁话就不多逼逼了。首先呢,我是通过搜狗来找到微信公众号的,因为搜狗那边比较容易入手,可以绕过校验。但是我估计也是时日不长。在这之前,我们需要用到htmlparser这个类来操作,可以在maven里面配置:
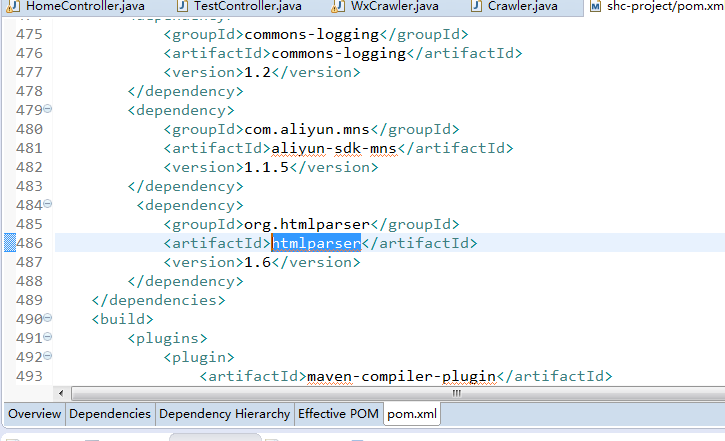
也可以通过去下载jar包
我们现在抓取这个公众号:http://weixin.sogou.com/weixin?type=1&query=%E5%B0%9A%E6%B1%87%E5%9F%8E&ie=utf8&_sug_=n&_sug_type_=,然后用浏览器打开打开源代码来产看进入这个公众号文章的那个连接,然后进行分析:
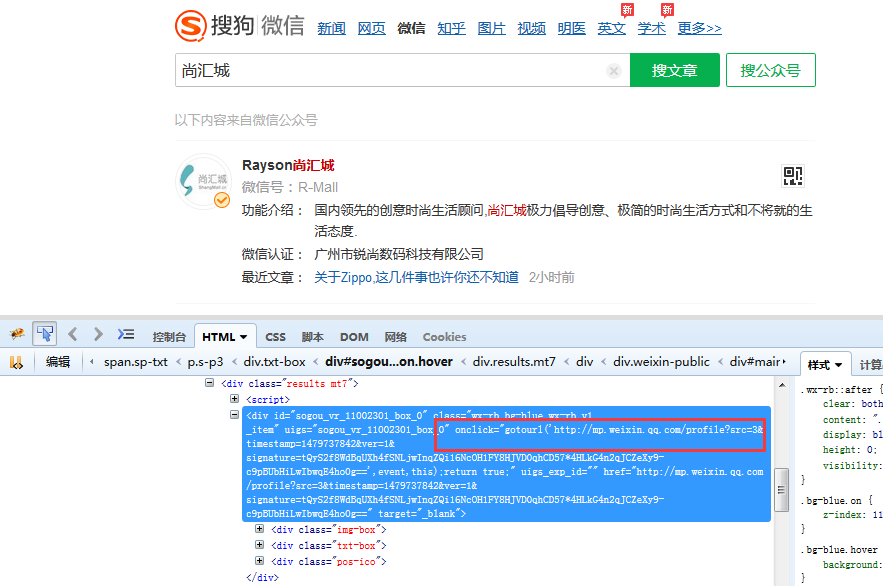
我们可以看到它的onclick事件之后是跳转到一个文章列表,所以我们要首先拿到那个连接,进入连接后是文章列表:
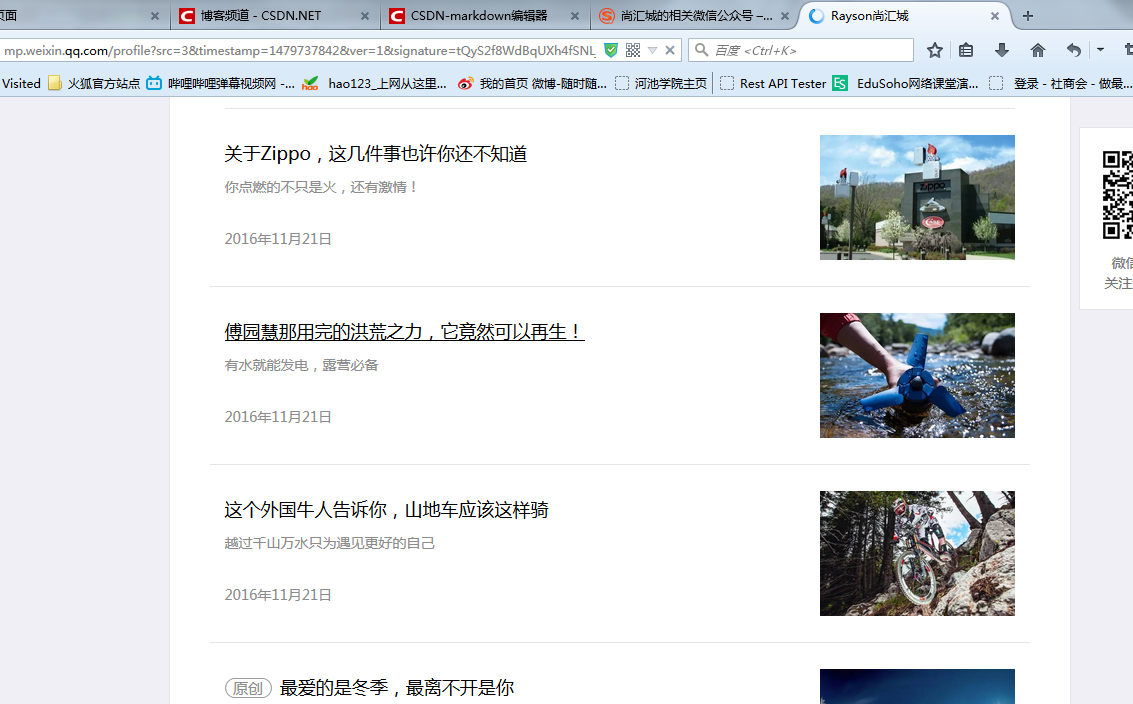
接下来就像上一步一样打开源代码分析:每一篇文章都有一个连接,只要截取到这个连接即可:
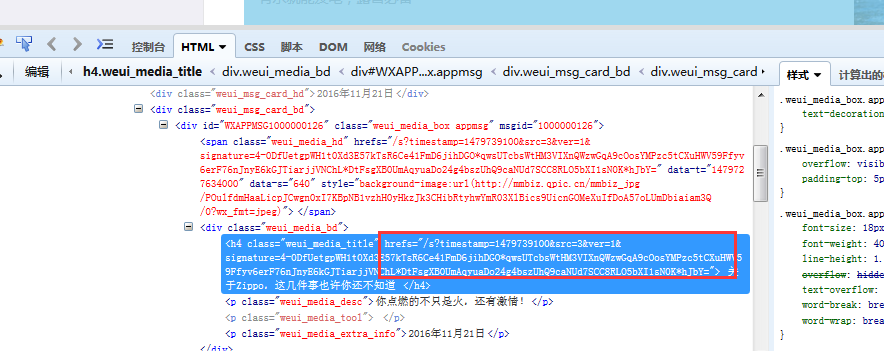
接下来就是点击其中一篇文章进去,然后在进行分析,可以看到文章的详情都有一个id = js_content的一个div,接下来就是根据这个id来获取文章内容
所有代码如下:
private List fetchArticles(String url) throws Exception {
List ats = new ArrayList();
String h1 = getHtml(url);
Parser parser = new Parser(h1, null);
NodeList nl = parser.extractAllNodesThatMatch(new NodeFilter() {
@Override
public boolean accept(Node node) {
// TODO Auto-generated method stub
if (node instanceof Div) {
Div shc = (Div) node;
String onclick = shc.getAttribute("onclick");
if (onclick != null && onclick.contains("gotourl(")) {
return true;
}
}
return false;
}
});
//获取文章列表
if (nl != null && nl.size() > 0) {
Div shc = (Div) nl.elementAt(0);
String urlL1 = shc.getAttribute("href");
if (StringUtil.isNotEmpty(urlL1)) {
urlL1 = decode(urlL1);
System.out.println("goto:" + urlL1);
String html = getHtml(urlL1);
if (StringUtil.isNotEmpty(html)) {
String[] arr = html.split("\\\\/s\\?timestamp=");
if (arr.length > 1) {
for (int i = 1; i < arr.length; i++) {
// for (int i = 1; i < 5; i++) {
String s2 = arr[i];
String[] arr3 = s2.split("","source_url");
if (arr3.length == 2) {
String urlL3 = ("http://mp.weixin.qq.com/s?timestamp=" + decode(arr3[0].trim()));
System.out.println("goto:" + urlL3);
//获取文章的详情
At at = getArticleByUrl(urlL3);
if (at != null) {
ats.add(at);
}
}
}
}
}
// System.out.println(arr.length);
}
}
return ats;
}
以下是上面方法调用到的方法:
//获取html源码
public static String getHtml(String url) {
try {
HttpClient httpclient = new HttpClient();
GetMethod method = new GetMethod(url);
httpclient.executeMethod(method);
return method.getResponseBodyAsString();
} catch(Exception ex) {
ex.printStackTrace();
}
return null;
}
获取文章详情方法:
@Override
public At getArticleByUrl(String url) {
// TODO Auto-generated method stub
String s3 = getHtml(url);
try {
Parser parser = new Parser(s3, null);
NodeList titles = parser.extractAllNodesThatMatch(new NodeFilter() {
@Override
public boolean accept(Node node) {
if (node instanceof TitleTag) {
return true;
}
return false;
}
});
if (titles != null && titles.size() > 0) {
String title = titles.elementAt(0).toPlainTextString();
At at = new At();
at.setTitle(title);
parser = new Parser(s3, null);
NodeList contents = parser.extractAllNodesThatMatch(new NodeFilter() {
@Override
public boolean accept(Node node) {
// TODO Auto-generated method stub
if (node instanceof Div && "js_content".equals(((Div) node).getAttribute("id"))) {
return true;
}
return false;
}
});
if (contents != null && contents.size() > 0) {
String body = contents.elementAt(0).toHtml();
at.setContent(body);
}
if(StringUtil.isNotEmpty(at.getContent())) {
parser = new Parser(at.getContent(), null);
NodeList imgs = parser.extractAllNodesThatMatch(new NodeFilter() {
@Override
public boolean accept(Node node) {
// TODO Auto-generated method stub
if (node instanceof ImageTag) {
return true;
}
return false;
}
});
if (imgs != null && imgs.size() > 0) {
int start = 0;
if(imgs.size() > 1) {
start = 1;
}
for(int i=start; i
ImageTag img = ((ImageTag)imgs.elementAt(i));
if(StringUtil.isNotEmpty(img.getAttribute("data-src"))) {
at.setThumb(img.getAttribute("data-src"));
break;
}
}
}
}
return at;
}
} catch(Exception ex) {
log.error(ex.getMessage(), ex);
}
return null;
}
有时候当点击那个公众号进去之后是一个验证页面:
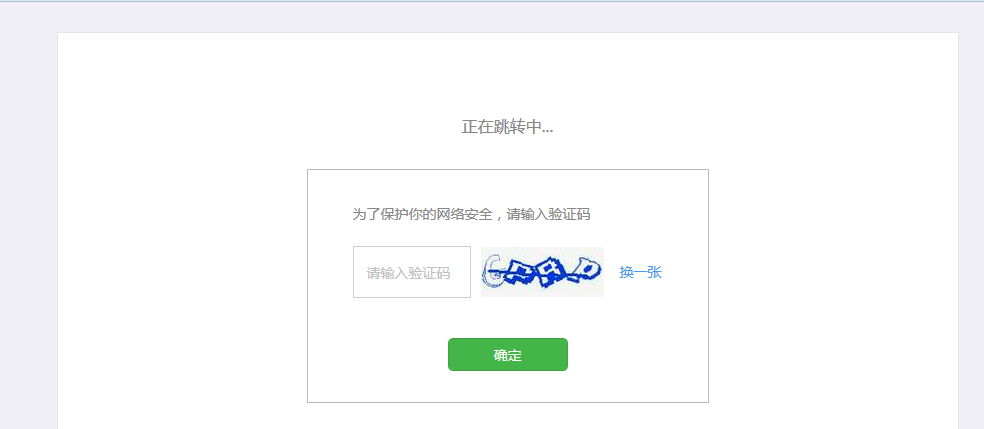
这个不要紧的,点多几次就可以了。
这是调用:
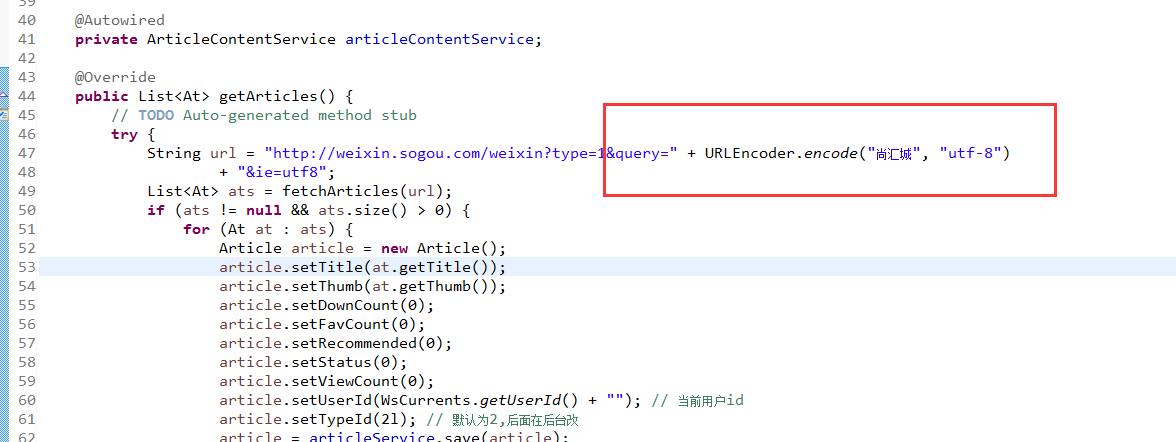
要注意框框的那个代码,如果不要的话好像会不行,应该是因为tomcat里面不能直接翻译中文,所以要进行转码。