基本思想:简单记录一下训练过程,数据集在coco基础上进行,进行筛选出杯子的数据集,然后进行训练,比较简单, 从coco数据集中筛选出杯子的数据集,然后在labelme数据集的基础上,转成paddleseg数据集,然后训练即可,生成的标签在代码中添加相应的数据格式,贴到txt即可
实验模型链接: https://pan.baidu.com/s/1w50vkX1kLfEhj2labK1xuQ?pwd=79qk 提取码: 79qk
一、数据集准备45、实例分割的labelme数据集转coco数据集以及coco数据集转labelme数据集、转paddleSeg数据集_sxj731533730的博客-CSDN博客_实例分割labelme
得到杯子数据集:链接: https://pan.baidu.com/s/1DWf7d1xWAscAKmIvNYJ9Rw?pwd=n2vs 提取码: n2vs
二、配置文件使用修改pp_liteseg_stdc1_camvid_960x720_10k.yml
ubuntu@ubuntu:~/PaddleSeg/configs/pp_liteseg$ cp pp_liteseg_stdc1_camvid_960x720_10k.yml pp_liteseg_stdc1_camvid_300x300_10k.yml
文件内容
batch_size: 6 # total: 4*6
iters: 100000
train_dataset:
type: Dataset
dataset_root: /home/ubuntu/PaddleSeg/paddleSegCup/datasets/train
num_classes: 2 #backgroud+cup
mode: train
train_path: /home/ubuntu/PaddleSeg/paddleSegCup/datasets/train/train.txt
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.5
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [300, 300]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize
val_dataset:
type: Dataset
dataset_root: /home/ubuntu/PaddleSeg/paddleSegCup/datasets/val
num_classes: 2
mode: val
val_path: /home/ubuntu/PaddleSeg/paddleSegCup/datasets/val/val.txt
transforms:
- type: Normalize
optimizer:
type: sgd
momentum: 0.9
weight_decay: 5.0e-4
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0
power: 0.9
warmup_iters: 200
warmup_start_lr: 1.0e-5
loss:
types:
- type: OhemCrossEntropyLoss
min_kept: 250000 # batch_size * 300 * 300 // 16
- type: OhemCrossEntropyLoss
min_kept: 250000
- type: OhemCrossEntropyLoss
min_kept: 250000
coef: [1, 1, 1]
model:
type: PPLiteSeg
backbone:
type: STDC1
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
arm_out_chs: [32, 64, 128]
seg_head_inter_chs: [32, 64, 64]
训练起来了
ubuntu@ubuntu:~/PaddleSeg$ ubuntu@ubuntu:~/PaddleSeg$ python3 train.py --config configs/pp_liteseg/pp_liteseg_stdc1_camvid_300x300_10k.yml --do_eval
2022-11-25 16:46:23 [INFO]
------------Environment Information-------------
platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.29
Python: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0]
Paddle compiled with cuda: True
NVCC: Build cuda_11.1.TC455_06.29069683_0
cudnn: 8.2
GPUs used: 1
CUDA_VISIBLE_DEVICES: None
GPU: ['GPU 0: NVIDIA GeForce']
GCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
PaddleSeg: 2.6.0
PaddlePaddle: 2.3.2
OpenCV: 4.6.0
------------------------------------------------
2022-11-25 16:46:23 [INFO]
---------------Config Information---------------
batch_size: 6
iters: 10000
loss:
coef:
- 1
- 1
- 1
types:
2022-11-25 16:54:19 [INFO] [TRAIN] epoch: 1, iter: 10/10000, loss: 2.7239, lr: 0.000460, batch_cost: 0.2893, reader_cost: 0.01094, ips: 20.7363 samples/sec | ETA 00:48:10
2022-11-25 16:54:19 [INFO] [TRAIN] epoch: 1, iter: 20/10000, loss: 2.3742, lr: 0.000959, batch_cost: 0.0511, reader_cost: 0.00009, ips: 117.4557 samples/sec | ETA 00:08:29
2022-11-25 16:54:20 [INFO] [TRAIN] epoch: 1, iter: 30/10000, loss: 1.9726, lr: 0.001459, batch_cost: 0.0536, reader_cost: 0.00026, ips: 111.8903 samples/sec | ETA 00:08:54
2022-11-25 16:54:20 [INFO] [TRAIN] epoch: 2, iter: 40/10000, loss: 1.7898, lr: 0.001958, batch_cost: 0.0576, reader_cost: 0.00709, ips: 104.1587 samples/sec | ETA 00:09:33
2022-11-25 16:54:21 [INFO] [TRAIN] epoch: 2, iter: 50/10000, loss: 2.6318, lr: 0.002458, batch_cost: 0.0550, reader_cost: 0.00426, ips: 109.1434 samples/sec | ETA 00:09:06
2022-11-25 16:54:21 [INFO] [TRAIN] epoch: 2, iter: 60/10000, loss: 2.1906, lr: 0.002957, batch_cost: 0.0566, reader_cost: 0.00435, ips: 106.0024 samples/sec | ETA 00:09:22
2022-11-25 16:54:22 [INFO] [TRAIN] epoch: 2, iter: 70/10000, loss: 1.9887, lr: 0.003457, batch_cost: 0.0567, reader_cost: 0.00542, ips: 105.8548 samples/sec | ETA 00:09:22
2022-11-25 16:54:23 [INFO] [TRAIN] epoch: 3, iter: 80/10000, loss: 2.3479, lr: 0.003956, batch_cost: 0.0611, reader_cost: 0.01129, ips: 98.2484 samples/sec | ETA 00:10:05
2022-11-25 16:54:23 [INFO] [TRAIN] epoch: 3, iter: 90/10000, loss: 2.0537, lr: 0.004456, batch_cost: 0.0551, reader_cost: 0.00373, ips: 108.8724 samples/sec | ETA 00:09:06
2022-11-25 16:54:24 [INFO] [TRAIN] epoch: 3, iter: 100/10000, loss: 2.0187, lr: 0.004955, batch_cost: 0.0539, reader_cost: 0.00411, ips: 111.2684 samples/sec | ETA 00:08:53
2022-11-25 16:54:24 [INFO] [TRAIN] epoch: 3, iter: 110/10000, loss: 2.1657, lr: 0.005455, batch_cost: 0.0508, reader_cost: 0.00069, ips: 118.2217 samples/sec | ETA 00:08:21
训练完成和测试
ubuntu@ubuntu:~/PaddleSeg/output$ ls
iter_10000 iter_6000 iter_7000 iter_8000 iter_9000
三、测试
ubuntu@ubuntu:~/PaddleSeg$ python3 predict.py --config /home/ubuntu/PaddleSeg/configs/pp_liteseg/pp_liteseg_stdc1_camvid_300x300_10k.yml --model_path /home/ubuntu/PaddleSeg/output/best_model/model.pdparams --image_path /home/ubuntu/PaddleSeg/paddleSegCup/datasets/val/JPEGImages/000000002157.jpg
测试结果


三、转模型,从modelparam到onnx,然后到openvino,最后到blob
1)onnx转换,
model = SavedSegmentationNet(model) # add argmax to the last layer
后续错误不用在意,这里测试以427 640 图片为例子,还是建议统一图片尺寸在训练,因为voc数据集大小不统一,所以,我只生成了一个427 640 的数据集
ubuntu@ubuntu:~/PaddleSeg$ python3 deploy/python/infer_onnx_trt.py --config /home/ubuntu/PaddleSeg/configs/pp_liteseg/pp_liteseg_stdc1_camvid_300x300_10k.yml --model_path /home/ubuntu/PaddleSeg/output/best_model/model.pdparams --save_dir ./saved --width 640 --height 427
W1126 10:34:49.439234 19118 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 11.7, Runtime API Version: 11.1
W1126 10:34:49.441439 19118 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
2022-11-26 10:34:50 [INFO] Loading pretrained model from https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
2022-11-26 10:34:50 [INFO] There are 145/145 variables loaded into STDCNet.
2022-11-26 10:34:50 [INFO] Loading pretrained model from /home/ubuntu/PaddleSeg/output/best_model/model.pdparams
2022-11-26 10:34:50 [INFO] There are 247/247 variables loaded into PPLiteSeg.
2022-11-26 10:34:50 [INFO] Loaded trained params of model successfully
input shape: [1, 3, 427, 640]
out shape: (1, 1, 427, 640)
2022-11-26 09:15:33 [INFO] Static PaddlePaddle model saved in ./saved/paddle_model_static_onnx_temp_dir.
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: ./saved/paddle_model_static_onnx_temp_dir/model.pdmodel
[Paddle2ONNX] Paramters file path: ./saved/paddle_model_static_onnx_temp_dir/model.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2022-11-26 09:15:33 [INFO] ONNX model saved in ./saved/pp_liteseg_stdc1_camvid_300x300_10k_model.onnx.
Completed export onnx model.
2)转openvino
ubuntu@ubuntu:~/PaddleSeg$ python3 /opt/intel/openvino_2021/deployment_tools/model_optimizer/mo.py --input_model /home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_300x300_10k_model.onnx --output_dir /home/ubuntu/PaddleSeg/saved/FP16 --input_shape [1,3,427,640] --data_type FP16 --scale_values [127.5,127.5,127.5] --mean_values [127.5,127.5,127.5
cmakelist.txt
cmake_minimum_required(VERSION 3.4.1)
set(CMAKE_CXX_STANDARD 14)
project(nanodet_demo)
find_package(OpenCV REQUIRED)
find_package(ngraph REQUIRED)
find_package(InferenceEngine REQUIRED)
include_directories(
${OpenCV_INCLUDE_DIRS}
${CMAKE_CURRENT_SOURCE_DIR}
${CMAKE_CURRENT_BINARY_DIR}
)
add_executable(nanodet_demo main.cpp )
target_link_libraries(
nanodet_demo
${InferenceEngine_LIBRARIES}
${NGRAPH_LIBRARIES}
${OpenCV_LIBS}
)
main.cpp
#include <inference_engine.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
#include <vector>
#include <chrono>
#include <iomanip> // Header file needed to use setprecision
using namespace std;
using namespace cv;
void preprocess(cv::Mat image, InferenceEngine::Blob::Ptr &blob) {
int img_w = image.cols;
int img_h = image.rows;
int channels = 3;
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
float *blob_data = mblobHolder.as<float *>();
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < img_h; h++) {
for (size_t w = 0; w < img_w; w++) {
blob_data[c * img_w * img_h + h * img_w + w] =
(float) image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
int main(int argc, char **argv) {
cv::Mat bgr = cv::imread("/home/ubuntu/PaddleSeg/paddleSegCup/datasets/val/JPEGImages/000000002157.jpg");
int orignal_width = bgr.cols;
int orignal_height = bgr.rows;
int target_width = 640;
int target_height = 427;
cv::Mat resize_img;
cv::resize(bgr, resize_img, cv::Size(target_width, target_height));
cv::Mat rgb;
cv::cvtColor(resize_img, rgb, cv::COLOR_BGR2RGB);
// resize_img.convertTo(resize_img, CV_32FC1, 1.0 / 255, 0);
//resize_img = (resize_img - 0.5) / 0.5;
auto start = chrono::high_resolution_clock::now(); //开始时间
std::string input_name_ = "x";
std::string output_name_ = "argmax_0.tmp_0";
std::string model_path = "/home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_300x300_10k_model.xml";
InferenceEngine::Core ie;
InferenceEngine::CNNNetwork model = ie.ReadNetwork(model_path);
// prepare input settings
InferenceEngine::InputsDataMap inputs_map(model.getInputsInfo());
input_name_ = inputs_map.begin()->first;
InferenceEngine::InputInfo::Ptr input_info = inputs_map.begin()->second;
//input_info->setPrecision(InferenceEngine::Precision::FP32);
//input_info->setLayout(InferenceEngine::Layout::NCHW);
//prepare output settings
InferenceEngine::OutputsDataMap outputs_map(model.getOutputsInfo());
for (auto &output_info : outputs_map) {
std::cout << "Output:" << output_info.first << std::endl;
output_info.second->setPrecision(InferenceEngine::Precision::FP32);
}
//get network
InferenceEngine::ExecutableNetwork network_ = ie.LoadNetwork(model, "CPU");
InferenceEngine::InferRequest infer_request_ = network_.CreateInferRequest();
InferenceEngine::Blob::Ptr input_blob = infer_request_.GetBlob(input_name_);
preprocess(rgb, input_blob);
// do inference
infer_request_.Infer();
const InferenceEngine::Blob::Ptr pred_blob = infer_request_.GetBlob(output_name_);
auto m_pred = InferenceEngine::as<InferenceEngine::MemoryBlob>(pred_blob);
auto m_pred_holder = m_pred->rmap();
const float *pred = m_pred_holder.as<const float *>();
auto end = chrono::high_resolution_clock::now(); //结束时间
auto duration = (end - start).count();
cout << "程序运行时间:" << std::setprecision(10) << duration / 1000000000.0 << "s"
<< "; " << duration / 1000000.0 << "ms"
<< "; " << duration / 1000.0 << "us"
<< endl;
int w = target_height;
int h = target_width;
std::vector<int> vec_host_scores;
for (int i = 0; i < w * h; i++) {
vec_host_scores.emplace_back(pred[i]);
}
int num_class = 1;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r * h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::Mat result;
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
cv::imshow("pseudo_img", pseudo_img);
cv::imwrite("pseudo_img.jpg", pseudo_img);
cv::imshow("bgr", bgr);
cv::imwrite("resize_img.jpg", resize_img);
cv::imshow("result", result);
cv::imwrite("result.jpg", result);
cv::waitKey(0);
return 0;
}
测试结果


3)转OAK模型
ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools$ sudo chmod 777 compile_tool/
ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools$ cd compile_tool/
ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools/compile_tool$ ./compile_tool -m /home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_300x300_10k_model.xml -ip U8 -d MYRIAD -VPU_NUMBER_OF_SHAVES 4 -VPU_NUMBER_OF_CMX_SLICES 4
Inference Engine:
IE version ......... 2021.4.1
Build ........... 2021.4.1-3926-14e67d86634-releases/2021/4
Network inputs:
x : U8 / NCHW
Network outputs:
bilinear_interp_v2_13.tmp_0 : FP16 / NCHW
[Warning][VPU][Config] Deprecated option was used : VPU_MYRIAD_PLATFORM
Done. LoadNetwork time elapsed: 5132 ms
ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools/compile_tool$ cp pp_liteseg_stdc1_camvid_300x300_10k_model.blob /home/ubuntu/PaddleSeg/saved/FP16
cmakelist.txt 测试图片的
cmake_minimum_required(VERSION 3.16)
project(untitled15)
set(CMAKE_CXX_STANDARD 11)
find_package(OpenCV REQUIRED)
#message(STATUS ${OpenCV_INCLUDE_DIRS})
#添加头文件
include_directories(${OpenCV_INCLUDE_DIRS})
include_directories(${CMAKE_SOURCE_DIR}/include)
include_directories(${CMAKE_SOURCE_DIR}/include/utility)
#链接Opencv库
find_package(depthai CONFIG REQUIRED)
add_executable(untitled15 main.cpp include/utility/utility.cpp)
target_link_libraries(untitled15 ${OpenCV_LIBS} depthai::opencv )
main.cpp
#include <stdio.h>
#include <string>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "utility.hpp"
#include <vector>
#include "depthai/depthai.hpp"
using namespace std;
using namespace std::chrono;
using namespace cv;
int post_process(std::vector<int> vec_host_scores,cv::Mat resize_img,cv::Mat &result, vector<int> color_map,int w,int h){
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r*h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
//cv::imshow("pseudo_img", pseudo_img);
cv::imwrite(".pseudo_img.jpg", pseudo_img);
// cv::imshow("bgr", resize_img);
cv::imwrite("resize_img.jpg", resize_img);
//cv::imshow("result", result);
cv::imwrite("result.jpg", result);
//cv::waitKey(0);
return 0;
}
int main(int argc, char **argv) {
int num_class = 256;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
int target_width=427;
int target_height=640;
dai::Pipeline pipeline;
//定义
auto cam = pipeline.create<dai::node::XLinkIn>();
cam->setStreamName("inFrame");
auto net = pipeline.create<dai::node::NeuralNetwork>();
dai::OpenVINO::Blob blob("/opt/intel/openvino_2021.4.689/deployment_tools/tools/compile_tool/pp_liteseg_stdc1_camvid_300x300_10k_model.blob");
net->setBlob(blob);
net->input.setBlocking(false);
//基本熟练明白oak的函数使用了
cam->out.link(net->input);
//定义输出
auto xlinkParserOut = pipeline.create<dai::node::XLinkOut>();
xlinkParserOut->setStreamName("parseOut");
auto xlinkoutOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutOut->setStreamName("out");
auto xlinkoutpassthroughOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutpassthroughOut->setStreamName("passthrough");
net->out.link(xlinkParserOut->input);
net->passthrough.link(xlinkoutpassthroughOut->input);
//结构推送相机
dai::Device device(pipeline);
//取帧显示
auto inqueue = device.getInputQueue("inFrame");//maxsize 代表缓冲数据
auto detqueue = device.getOutputQueue("parseOut", 8, false);//maxsize 代表缓冲数据
bool printOutputLayersOnce=true;
cv::Mat frame=cv::imread("/home/ubuntu/PaddleSeg/paddleSegCup/datasets/val/JPEGImages/000000002157.jpg");
while(true) {
if(frame.empty()) break;
auto img = std::make_shared<dai::ImgFrame>();
frame = resizeKeepAspectRatio(frame, cv::Size(target_height, target_width), cv::Scalar(0));
toPlanar(frame, img->getData());
img->setTimestamp(steady_clock::now());
img->setWidth(target_height);
img->setHeight(target_width);
inqueue->send(img);
auto inNN = detqueue->get<dai::NNData>();
if( printOutputLayersOnce&&inNN) {
std::cout << "Output layer names: ";
for(const auto& ten : inNN->getAllLayerNames()) {
std::cout << ten << ", ";
}
std::cout << std::endl;
printOutputLayersOnce = false;
}
cv::Mat result;
auto pred=inNN->getLayerInt32(inNN->getAllLayerNames()[0]);
post_process(pred,frame,result,color_map,target_width,target_height);
cv::imshow("demo", frame);
cv::imshow("result", result);
cv::imwrite("result.jpg",result);
int key = cv::waitKey(1);
if(key == 'q' || key == 'Q') return 0;
}
// while (true) {
//
//
// auto ImgFrame = outqueue->get<dai::ImgFrame>();
// auto frame = ImgFrame->getCvFrame();
//
// auto inNN = detqueue->get<dai::NNData>();
// if( printOutputLayersOnce&&inNN) {
// std::cout << "Output layer names: ";
// for(const auto& ten : inNN->getAllLayerNames()) {
// std::cout << ten << ", ";
// }
// std::cout << std::endl;
// printOutputLayersOnce = false;
// }
// cv::Mat result;
// auto pred=inNN->getLayerInt32(inNN->getAllLayerNames()[0]);
//
// post_process(pred,frame,result,color_map,target_width,target_height);
// cv::imshow("demo", frame);
// cv::imshow("result", result);
// cv::imwrite("result.jpg",result);
// cv::waitKey(1);
//
//
// }
return 0;
}
测试结果


实际测试视频472 640 的帧率在16fps左右
#include <stdio.h>
#include <string>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "utility.hpp"
#include <vector>
#include "depthai/depthai.hpp"
using namespace std;
using namespace std::chrono;
using namespace cv;
int post_process(std::vector<int> vec_host_scores, cv::Mat resize_img, cv::Mat &result, vector<int> color_map, int w,
int h) {
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r * h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
//cv::imshow("pseudo_img", pseudo_img);
cv::imwrite(".pseudo_img.jpg", pseudo_img);
// cv::imshow("bgr", resize_img);
cv::imwrite("resize_img.jpg", resize_img);
//cv::imshow("result", result);
cv::imwrite("result.jpg", result);
//cv::waitKey(0);
return 0;
}
int main(int argc, char **argv) {
int num_class = 256;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
int target_width = 427;
int target_height = 640;
dai::Pipeline pipeline;
//定义
auto cam = pipeline.create<dai::node::ColorCamera>();
cam->setBoardSocket(dai::CameraBoardSocket::RGB);
cam->setResolution(dai::ColorCameraProperties::SensorResolution::THE_1080_P);
cam->setPreviewSize(target_height, target_width); // NN input
cam->setInterleaved(false);
auto net = pipeline.create<dai::node::NeuralNetwork>();
dai::OpenVINO::Blob blob("/home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_300x300_10k_model.blob");
net->setBlob(blob);
net->input.setBlocking(false);
//基本熟练明白oak的函数使用了
cam->preview.link(net->input);
//定义输出
auto xlinkParserOut = pipeline.create<dai::node::XLinkOut>();
xlinkParserOut->setStreamName("parseOut");
auto xlinkoutOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutOut->setStreamName("out");
auto xlinkoutpassthroughOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutpassthroughOut->setStreamName("passthrough");
net->out.link(xlinkParserOut->input);
net->passthrough.link(xlinkoutpassthroughOut->input);
//结构推送相机
dai::Device device(pipeline);
//取帧显示
auto outqueue = device.getOutputQueue("passthrough", 8, false);//maxsize 代表缓冲数据
auto detqueue = device.getOutputQueue("parseOut", 8, false);//maxsize 代表缓冲数据
bool printOutputLayersOnce = true;
auto startTime = steady_clock::now();
int counter = 0;
float fps = 0;
while (true) {
auto ImgFrame = outqueue->get<dai::ImgFrame>();
auto frame = ImgFrame->getCvFrame();
auto inNN = detqueue->get<dai::NNData>();
if (printOutputLayersOnce && inNN) {
std::cout << "Output layer names: ";
for (const auto &ten : inNN->getAllLayerNames()) {
std::cout << ten << ", ";
}
std::cout << std::endl;
printOutputLayersOnce = false;
}
cv::Mat result;
auto pred = inNN->getLayerInt32(inNN->getAllLayerNames()[0]);
post_process(pred, frame, result, color_map, target_width, target_height);
counter++;
auto currentTime = steady_clock::now();
auto elapsed = duration_cast<duration<float>>(currentTime - startTime);
if (elapsed > seconds(1)) {
fps = counter / elapsed.count();
counter = 0;
startTime = currentTime;
}
std::stringstream fpsStr;
fpsStr << "NN fps: " << std::fixed << std::setprecision(2) << fps;
cv::putText(result, fpsStr.str(), cv::Point(2, result.rows - 4), cv::FONT_HERSHEY_TRIPLEX, 0.4, cv::Scalar(0,255,0));
//cv::imshow("demo", frame);
cv::imshow("result", result);
//cv::imwrite("result.jpg", result);
cv::waitKey(1);
}
return 0;
}
测试数据
/home/ubuntu/CLionProjects/untitled5/cmake-build-debug/untitled15
[19443010C130FF1200] [1.5] [1.155] [NeuralNetwork(1)] [warning] Network compiled for 4 shaves, maximum available 13, compiling for 6 shaves likely will yield in better performance
Output layer names: argmax_0.tmp_0,
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 0.00
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 10.58
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.26
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 15.65
NN fps: 14.99
NN fps: 14.99
NN fps: 14.99
NN fps: 14.99
NN fps: 14.99
NN fps: 14.99
NN fps: 14.99
测试图片

有时候识别效果还是差,数据集可能太少了。。毕竟才150张。。。
补充一个代码含有测据 链接: https://pan.baidu.com/s/1Top8jspCXskIyfi-9QLvcg?pwd=x4fj 提取码: x4fj
#include <stdio.h>
#include <string>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "utility.hpp"
#include <vector>
#include "depthai/depthai.hpp"
using namespace std;
using namespace std::chrono;
using namespace cv;
static std::atomic<bool> newConfig{false};
int find_bound(cv::Mat gray_img, cv::Mat resize_img, vector<Rect> &ploy_rects_) {
cvtColor(gray_img, gray_img, cv::COLOR_BGR2GRAY);
std::vector<std::vector<cv::Point>> contours;
findContours(gray_img, contours, cv::RETR_TREE, cv::CHAIN_APPROX_SIMPLE);
vector<vector<Point>> contours_ploy(contours.size()); // 逼近多边形点
vector<Rect> ploy_rects(contours.size()); // 多边形框
for (size_t i = 0; i < contours.size(); i++) {
approxPolyDP(Mat(contours[i]), contours_ploy[i], 3, true);
ploy_rects[i] = boundingRect(contours_ploy[i]);
}
RNG rng(1234);
Point2f pts[4];
for (size_t t = 0; t < contours.size(); t++) {
Scalar color = Scalar(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255));
rectangle(resize_img, ploy_rects[t], color, 2, 8);
if (contours_ploy[t].size() > 5) {
for (int r = 0; r < 4; r++) {
line(resize_img, pts[r], pts[(r + 1) % 4], color, 2, 8);
}
}
}
cv::drawContours(resize_img, contours, -1, (255, 0, 0), 2);
ploy_rects_ = ploy_rects;
imshow("drawImg", resize_img);
cv::imwrite("dram.jpg",resize_img);
}
int post_process(std::vector<int> vec_host_scores, cv::Mat resize_img, cv::Mat &result, vector<int> color_map, int w,
int h, std::vector<Rect> &ploy_rects_) {
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r * h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
find_bound(pseudo_img, resize_img, ploy_rects_);
//cv::imshow("pseudo_img", pseudo_img);
//cv::imwrite(".pseudo_img.jpg", pseudo_img);
// cv::imshow("bgr", resize_img);
//cv::imwrite("resize_img.jpg", resize_img);
// cv::imshow("result", result);
// cv::imwrite("result.jpg", result);
//cv::waitKey(0);
return 0;
}
int main(int argc, char **argv) {
int num_class = 1;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
float target_width = 300;
float target_height = 300;
dai::Pipeline pipeline;
dai::Device device;
//定义
auto cam = pipeline.create<dai::node::ColorCamera>();
cam->setBoardSocket(dai::CameraBoardSocket::RGB);
cam->setResolution(dai::ColorCameraProperties::SensorResolution::THE_1080_P);
cam->setPreviewSize((int) target_height, (int) target_width); // NN input
cam->setInterleaved(false);
cam->setPreviewKeepAspectRatio(false);
try {
auto calibData = device.readCalibration2();
auto lensPosition = calibData.getLensPosition(dai::CameraBoardSocket::RGB);
if (lensPosition) {
cam->initialControl.setManualFocus(lensPosition);
}
} catch (const std::exception &ex) {
std::cout << ex.what() << std::endl;
return 1;
}
auto net = pipeline.create<dai::node::NeuralNetwork>();
dai::OpenVINO::Blob blob(
"../model_300_300/pp_liteseg_stdc1_camvid_300x300_10k_model.blob");
net->setBlob(blob);
net->input.setBlocking(false);
//基本熟练明白oak的函数使用了
cam->preview.link(net->input);
auto monoLeft = pipeline.create<dai::node::MonoCamera>();
auto monoRight = pipeline.create<dai::node::MonoCamera>();
auto stereo = pipeline.create<dai::node::StereoDepth>();
auto spatialDataCalculator = pipeline.create<dai::node::SpatialLocationCalculator>();
auto xoutDepth = pipeline.create<dai::node::XLinkOut>();
auto xoutSpatialData = pipeline.create<dai::node::XLinkOut>();
auto xinSpatialCalcConfig = pipeline.create<dai::node::XLinkIn>();
xoutDepth->setStreamName("depth");
xoutSpatialData->setStreamName("spatialData");
xinSpatialCalcConfig->setStreamName("spatialCalcConfig");
monoLeft->setResolution(dai::MonoCameraProperties::SensorResolution::THE_720_P);
monoLeft->setBoardSocket(dai::CameraBoardSocket::LEFT);
monoRight->setResolution(dai::MonoCameraProperties::SensorResolution::THE_720_P);
monoRight->setBoardSocket(dai::CameraBoardSocket::RIGHT);
try {
auto calibData = device.readCalibration2();
auto lensPosition = calibData.getLensPosition(dai::CameraBoardSocket::RGB);
if (lensPosition) {
cam->initialControl.setManualFocus(lensPosition);
}
} catch (const std::exception &ex) {
std::cout << ex.what() << std::endl;
return 1;
}
// stereo->setDefaultProfilePreset(dai::node::StereoDepth::PresetMode::HIGH_DENSITY);
//stereo->setSubpixel(subpixel);
stereo->setLeftRightCheck(true);
stereo->setExtendedDisparity(true);
stereo->setDepthAlign(dai::CameraBoardSocket::RGB);
stereo->setDefaultProfilePreset(dai::node::StereoDepth::PresetMode::HIGH_ACCURACY);
dai::Point2f topLeft(0.4f, 0.4f);
dai::Point2f bottomRight(0.6f, 0.6f);
dai::SpatialLocationCalculatorConfigData config;
config.depthThresholds.lowerThreshold = 100;
config.depthThresholds.upperThreshold = 10000;
config.roi = dai::Rect(topLeft, bottomRight);
spatialDataCalculator->inputConfig.setWaitForMessage(false);
spatialDataCalculator->initialConfig.addROI(config);
// Linking
monoLeft->out.link(stereo->left);
monoRight->out.link(stereo->right);
//定义输出
auto xlinkParserOut = pipeline.create<dai::node::XLinkOut>();
xlinkParserOut->setStreamName("parseOut");
auto xlinkoutOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutOut->setStreamName("out");
auto xlinkoutpassthroughOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutpassthroughOut->setStreamName("passthrough");
spatialDataCalculator->passthroughDepth.link(xoutDepth->input);
stereo->depth.link(spatialDataCalculator->inputDepth);
spatialDataCalculator->out.link(xoutSpatialData->input);
xinSpatialCalcConfig->out.link(spatialDataCalculator->inputConfig);
net->out.link(xlinkParserOut->input);
net->passthrough.link(xlinkoutpassthroughOut->input);
device.startPipeline(pipeline);
device.setIrLaserDotProjectorBrightness(1000);
//结构推送相机
//取帧显示
auto outqueue = device.getOutputQueue("passthrough", 4, false);//maxsize 代表缓冲数据
auto detqueue = device.getOutputQueue("parseOut", 4, false);//maxsize 代表缓冲数据
auto depthQueue = device.getOutputQueue("depth", 4, false);
auto spatialCalcQueue = device.getOutputQueue("spatialData", 4, false);
auto spatialCalcConfigInQueue = device.getInputQueue("spatialCalcConfig");
bool printOutputLayersOnce = true;
auto startTime = steady_clock::now();
int counter = 0;
float fps = 0;
auto color = cv::Scalar(255, 255, 255);
while (true) {
auto inDepth = depthQueue->get<dai::ImgFrame>();
auto ImgFrame = outqueue->get<dai::ImgFrame>();
auto frame = ImgFrame->getCvFrame();
target_width=frame.cols*1.0;
target_height=frame.rows*1.0;
auto inNN = detqueue->get<dai::NNData>();
if (printOutputLayersOnce && inNN) {
std::cout << "Output layer names: ";
for (const auto &ten : inNN->getAllLayerNames()) {
std::cout << ten << ", ";
}
std::cout << std::endl;
printOutputLayersOnce = false;
}
cv::Mat result;
auto pred = inNN->getLayerInt32(inNN->getAllLayerNames()[0]);
std::vector<Rect> ploy_rects_;
post_process(pred, frame, result, color_map, target_width, target_height, ploy_rects_);
for (auto &item:ploy_rects_) {
newConfig = true;
cv::Mat depthFrame = inDepth->getFrame(); // depthFrame values are in millimeters
std::cout << depthFrame.rows << " " << depthFrame.cols << " " << std::endl;
cv::Mat depthFrameColor;
cv::normalize(depthFrame, depthFrameColor, 255, 0, cv::NORM_INF, CV_8UC1);
cv::equalizeHist(depthFrameColor, depthFrameColor);
cv::applyColorMap(depthFrameColor, depthFrameColor, cv::COLORMAP_HOT);
topLeft.x = item.x * depthFrame.cols / target_width / depthFrame.cols;
topLeft.y = item.y * depthFrame.rows / target_height / depthFrame.rows;
bottomRight.x = (item.x * depthFrame.cols / target_width + item.width * depthFrame.cols / target_width) /
depthFrame.cols;
bottomRight.y = (item.y * depthFrame.rows / target_height + item.height * depthFrame.rows / target_height) /
depthFrame.rows;
auto spatialData = spatialCalcQueue->get<dai::SpatialLocationCalculatorData>()->getSpatialLocations();
for (auto depthData : spatialData) {
auto roi = depthData.config.roi;
roi = roi.denormalize(depthFrameColor.cols, depthFrameColor.rows);
auto xmin = (int) roi.topLeft().x;
auto ymin = (int) roi.topLeft().y;
auto xmax = (int) roi.bottomRight().x;
auto ymax = (int) roi.bottomRight().y;
auto depthMin = depthData.depthMin;
auto depthMax = depthData.depthMax;
cv::rectangle(result, cv::Rect(cv::Point((int) item.x, (int) item.y),
cv::Point((int) item.x + (int) item.width,
(int) item.y + (int) item.height)), color,
cv::FONT_HERSHEY_SIMPLEX);
std::stringstream depthX;
depthX << "X: " << (int) depthData.spatialCoordinates.x << " mm";
cv::putText(result, depthX.str(), cv::Point((int) item.x + 10, (int) item.y + 20),
cv::FONT_HERSHEY_TRIPLEX, 0.5, color);
std::stringstream depthY;
depthY << "Y: " << (int) depthData.spatialCoordinates.y << " mm";
cv::putText(result, depthY.str(), cv::Point((int) item.x + 10, (int) item.y + 35),
cv::FONT_HERSHEY_TRIPLEX, 0.5, color);
std::stringstream depthZ;
depthZ << "Z: " << (int) depthData.spatialCoordinates.z << " mm";
cv::putText(result, depthZ.str(), cv::Point((int) item.x + 10, (int) item.y + 50),
cv::FONT_HERSHEY_TRIPLEX, 0.5, color);
cv::rectangle(result, cv::Rect(cv::Point((int) item.x, (int) item.y),
cv::Point((int) item.x + (int) item.width,
(int) item.y + (int) item.height)), color,
cv::FONT_HERSHEY_SIMPLEX);
auto coords = depthData.spatialCoordinates;
auto distance = std::sqrt(coords.x * coords.x + coords.y * coords.y + coords.z * coords.z);
std::stringstream depthDistance;
depthDistance.precision(2);
depthDistance << fixed << static_cast<float>(distance / 1000.0f) << "m";
auto fontType = cv::FONT_HERSHEY_TRIPLEX;
cv::putText(result, depthDistance.str(), cv::Point(xmin + 10, ymin + 70), fontType, 0.5, color);
cv::rectangle(depthFrameColor, cv::Rect(cv::Point(xmin, ymin), cv::Point(xmax, ymax)), color,
cv::FONT_HERSHEY_SIMPLEX);
depthX << "X: " << (int) depthData.spatialCoordinates.x << " mm";
cv::putText(depthFrameColor, depthX.str(), cv::Point(xmin + 10, ymin + 20), cv::FONT_HERSHEY_TRIPLEX,
0.5, color);
depthY << "Y: " << (int) depthData.spatialCoordinates.y << " mm";
cv::putText(depthFrameColor, depthY.str(), cv::Point(xmin + 10, ymin + 35), cv::FONT_HERSHEY_TRIPLEX,
0.5, color);
depthZ << "Z: " << (int) depthData.spatialCoordinates.z << " mm";
cv::putText(depthFrameColor, depthZ.str(), cv::Point(xmin + 10, ymin + 50), cv::FONT_HERSHEY_TRIPLEX,
0.5, color);
cv::imshow("depthFrameColor", depthFrameColor);
}
if (newConfig) {
config.roi = dai::Rect(topLeft, bottomRight);
dai::SpatialLocationCalculatorConfig cfg;
cfg.addROI(config);
spatialCalcConfigInQueue->send(cfg);
newConfig = false;
}
}
counter++;
auto currentTime = steady_clock::now();
auto elapsed = duration_cast<duration<float>>(currentTime - startTime);
if (elapsed > seconds(1)) {
fps = counter / elapsed.count();
counter = 0;
startTime = currentTime;
}
std::stringstream fpsStr;
fpsStr << "NN fps: " << std::fixed << std::setprecision(2) << fps;
cv::putText(result, fpsStr.str(), cv::Point(2, result.rows - 4), cv::FONT_HERSHEY_TRIPLEX, 0.4,
cv::Scalar(0, 255, 0));
cv::imshow("result", result);
cv::waitKey(1);
}
return 0;
}
测试结果


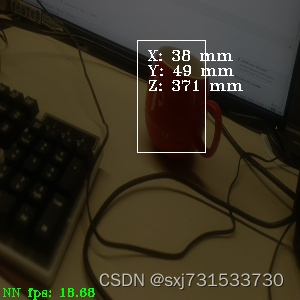

补充一个python版本的代码
#!/usr/bin/env python3
import cv2
import depthai as dai
import numpy as np
import math
import time
import os
def get_color_map_list(num_classes, custom_color=None):
"""
Returns the color map for visualizing the segmentation mask,
which can support arbitrary number of classes.
Args:
num_classes (int): Number of classes.
custom_color (list, optional): Save images with a custom color map. Default: None, use paddleseg's default color map.
Returns:
(list). The color map.
"""
num_classes += 1
color_map = num_classes * [0, 0, 0]
for i in range(0, num_classes):
j = 0
lab = i
while lab:
color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
j += 1
lab >>= 3
color_map = color_map[3:]
if custom_color:
color_map[:len(custom_color)] = custom_color
return color_map
def find_bound(gray_img,resize_img):
cv2.imshow("gray_img", gray_img)
cv2.imwrite("gray_img.jpg",gray_img)
ret, gray_img = cv2.threshold(
cv2.cvtColor(gray_img, cv2.COLOR_BGR2GRAY), # 转换为灰度图像,
60, 205, # 大于130的改为255 否则改为0
cv2.THRESH_BINARY) # 黑白二值化
cv2.imshow("gray_img2", gray_img)
cv2.imwrite("gray_img2.jpg", gray_img)
contours, hierarchy = cv2.findContours(gray_img, cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
rect_list=[]
for c in contours:
x, y, w, h = cv2.boundingRect(c)
rect_list.append([x, y, w, h])
"""
传入一个轮廓图像,返回 x y 是左上角的点, w和h是矩形边框的宽度和高度
"""
cv2.rectangle(resize_img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imwrite("resize_img.jpg", resize_img)
"""
画出矩形
img 是要画出轮廓的原图
(x, y) 是左上角点的坐标
(x+w, y+h) 是右下角的坐标
0,255,0)是画线对应的rgb颜色
2 是画出线的宽度
"""
# 获得最小的矩形轮廓 可能带旋转角度
rect = cv2.minAreaRect(c)
# 计算最小区域的坐标
box = cv2.boxPoints(rect)
# 坐标规范化为整数
box = np.int0(box)
# 画出轮廓
cv2.drawContours(resize_img, [box], 0, (0, 0, 255), 3)
cv2.imwrite("drawContours.jpg", resize_img)
# 计算最小封闭圆形的中心和半径
(x, y), radius = cv2.minEnclosingCircle(c)
# 转换成整数
center = (int(x), int(y))
radius = int(radius)
# 画出圆形
resize_img = cv2.circle(resize_img, center, radius, (0, 255, 0), 2)
cv2.imwrite("circle.jpg", resize_img)
# 画出轮廓
cv2.drawContours(resize_img, contours, -1, (255, 0, 0), 1)
cv2.imshow("contours", resize_img)
cv2.imwrite("contours.jpg",resize_img)
return rect_list
def visualize(image, result, color_map, save_dir=None, weight=0.6):
"""
Convert predict result to color image, and save added image.
Args:
image (str): The path of origin image.
result (np.ndarray): The predict result of image.
color_map (list): The color used to save the prediction results.
save_dir (str): The directory for saving visual image. Default: None.
weight (float): The image weight of visual image, and the result weight is (1 - weight). Default: 0.6
Returns:
vis_result (np.ndarray): If `save_dir` is None, return the visualized result.
"""
color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
color_map = np.array(color_map).astype("uint8")
# Use OpenCV LUT for color mapping
c1 = cv2.LUT(result, color_map[:, 0])
c2 = cv2.LUT(result, color_map[:, 1])
c3 = cv2.LUT(result, color_map[:, 2])
pseudo_img = np.dstack((c3, c2, c1))
im = image
vis_result = cv2.addWeighted(im, weight, pseudo_img, 1 - weight, 0)
rect_list=find_bound(pseudo_img, image)
if save_dir is not None:
if not os.path.exists(save_dir):
os.makedirs(save_dir)
image_name = os.path.split(image)[-1]
out_path = os.path.join(save_dir, image_name)
cv2.imwrite(out_path, vis_result)
else:
return vis_result,rect_list
nn_shape = [300, 300] # width height
target_width=nn_shape[0]*1.0
target_height=nn_shape[1]*1.0
class_num = 256
color_map = get_color_map_list(class_num)
# Start defining a pipeline
pipeline = dai.Pipeline()
pipeline.setOpenVINOVersion(version=dai.OpenVINO.VERSION_2021_4)
# Define a neural network that will make predictions based on the source frames
detection_nn = pipeline.create(dai.node.NeuralNetwork)
detection_nn.setBlobPath("/home/ubuntu/nanodet/oak_detect_head/model_300_300/pp_liteseg_stdc1_camvid_300x300_10k_model.blob")
detection_nn.setNumPoolFrames(4)
detection_nn.input.setBlocking(False)
detection_nn.setNumInferenceThreads(2)
# Define a source - color camera
cam = pipeline.create(dai.node.ColorCamera)
cam.setPreviewSize(nn_shape[1], nn_shape[0])
cam.setInterleaved(False)
cam.setPreviewKeepAspectRatio(False)
cam.preview.link(detection_nn.input)
cam.setFps(60)
monoLeft=pipeline.create(dai.node.MonoCamera)
monoRight=pipeline.create(dai.node.MonoCamera)
stereo=pipeline.create(dai.node.StereoDepth)
spatialLocationCalculator=pipeline.create(dai.node.SpatialLocationCalculator)
xoutDepth = pipeline.create (dai.node.XLinkOut)
xoutSpatialData = pipeline.create (dai.node.XLinkOut)
xinSpatialCalcConfig = pipeline.create (dai.node.XLinkIn)
xoutDepth.setStreamName("depth")
xoutSpatialData.setStreamName("spatialData")
xinSpatialCalcConfig.setStreamName("spatialCalcConfig")
monoLeft.setResolution(dai.MonoCameraProperties.SensorResolution.THE_720_P)
monoLeft.setBoardSocket(dai.CameraBoardSocket.LEFT)
monoRight.setResolution(dai.MonoCameraProperties.SensorResolution.THE_720_P)
monoRight.setBoardSocket(dai.CameraBoardSocket.RIGHT)
stereo.setDefaultProfilePreset(dai.node.StereoDepth.PresetMode.HIGH_DENSITY)
stereo.setLeftRightCheck(True)
stereo.setExtendedDisparity(True)
stereo.setDepthAlign(dai.CameraBoardSocket.RGB)
topLeft = dai.Point2f(0.4, 0.4)
bottomRight = dai.Point2f(0.6, 0.6)
spatialLocationCalculator.setWaitForConfigInput(False)
config = dai.SpatialLocationCalculatorConfigData()
config.depthThresholds.lowerThreshold = 100
config.depthThresholds.upperThreshold = 10000
config.roi = dai.Rect(topLeft, bottomRight)
spatialLocationCalculator.initialConfig.addROI(config)
monoLeft.out.link(stereo.left)
monoRight.out.link(stereo.right)
xlinkParserOut = pipeline.create ( dai.node.XLinkOut )
xlinkParserOut.setStreamName("parseOut")
xlinkoutOut = pipeline.create ( dai.node.XLinkOut )
xlinkoutOut.setStreamName("out")
xlinkoutpassthroughOut = pipeline.create (dai.node.XLinkOut )
xlinkoutpassthroughOut.setStreamName("passthrough")
spatialLocationCalculator.passthroughDepth.link(xoutDepth.input)
stereo.depth.link(spatialLocationCalculator.inputDepth)
spatialLocationCalculator.out.link(xoutSpatialData.input)
xinSpatialCalcConfig.out.link(spatialLocationCalculator.inputConfig)
detection_nn.out.link(xlinkParserOut.input)
detection_nn.passthrough.link(xlinkoutpassthroughOut.input)
# # Create outputs
# xout_rgb = pipeline.create(dai.node.XLinkOut)
# xout_rgb.setStreamName("nn_input")
# xout_rgb.input.setBlocking(False)
#
# detection_nn.passthrough.link(xout_rgb.input)
#
# xout_nn = pipeline.create(dai.node.XLinkOut)
# xout_nn.setStreamName("nn")
# xout_nn.input.setBlocking(False)
#
# detection_nn.out.link(xout_nn.input)
# Pipeline defined, now the device is assigned and pipeline is started
with dai.Device() as device:
cams = device.getConnectedCameras()
device.startPipeline(pipeline);
device.setIrLaserDotProjectorBrightness(1000);
outqueue = device.getOutputQueue("passthrough", 4, False)
detqueue = device.getOutputQueue("parseOut", 4, False)
depthQueue = device.getOutputQueue("depth", 4, False);
spatialCalcQueue = device.getOutputQueue("spatialData", 4, False);
spatialCalcConfigInQueue = device.getInputQueue("spatialCalcConfig");
start_time = time.time()
counter = 0
fps = 0
layer_info_printed = True
while True:
# instead of get (blocking) used tryGet (nonblocking) which will return the available data or None otherwise
inDepth=depthQueue.get()
in_nn_input = outqueue.get()
in_nn = detqueue.get()
frame = in_nn_input.getCvFrame()
layers = in_nn.getAllLayers()
if layer_info_printed:
for item in layers:
print(item.name)
layer_info_printed = False
# get layer1 data
pred = in_nn.getFirstLayerInt32()
pred = np.array(pred).astype('uint8').reshape(nn_shape[0], nn_shape[1])
frame_,rect_list = visualize(frame, pred, color_map, None, weight=0.6)
for item in rect_list:
x,y,w,h=int(item[0]),int(item[1]),int(item[2]),int(item[3])
depthFrame=inDepth.getFrame()
depthFrameColor = cv2.normalize(depthFrame, None, 255, 0, cv2.NORM_INF, cv2.CV_8UC1)
depthFrameColor = cv2.equalizeHist(depthFrameColor)
depthFrameColor = cv2.applyColorMap(depthFrameColor, cv2.COLORMAP_HOT)
topLeft.x = x * depthFrameColor.shape[1]/ target_width / depthFrameColor.shape[1]
topLeft.y =y * depthFrameColor.shape[0] / target_height / depthFrameColor.shape[0]
bottomRight.x = (x * depthFrameColor.shape[1] / target_width + w * depthFrameColor.shape[1] / target_width) /depthFrameColor.shape[1]
bottomRight.y = (y * depthFrameColor.shape[0] / target_height + h * depthFrameColor.shape[0] / target_height) /depthFrameColor.shape[0]
config.roi = dai.Rect(topLeft, bottomRight)
cfg = dai.SpatialLocationCalculatorConfig()
cfg.addROI(config)
spatialCalcConfigInQueue.send(cfg)
spatialData = spatialCalcQueue.get().getSpatialLocations()
for depthData in spatialData:
roi = depthData.config.roi
roi = roi.denormalize(depthFrameColor.shape[1], depthFrameColor.shape[0])
xmin = int(roi.topLeft().x)
ymin = int(roi.topLeft().y)
xmax = int(roi.bottomRight().x)
ymax = int(roi.bottomRight().y)
coords = depthData.spatialCoordinates;
fontType = cv2.FONT_HERSHEY_TRIPLEX
distance = math.sqrt(coords.x * coords.x + coords.y * coords.y + coords.z * coords.z)/1000.0
cv2.putText(depthFrameColor, f"d: { round(distance,2)} mm", (xmin + 10, ymin + 70), fontType, 0.5,(255, 0, 0))
cv2.rectangle(depthFrameColor, (xmin,ymin),(xmax,ymax), (255, 0, 0),cv2.FONT_HERSHEY_SIMPLEX)
cv2.putText(depthFrameColor, f"X: {int(depthData.spatialCoordinates.x)} mm", (xmin + 10, ymin + 20),
fontType, 0.5, (255, 0, 0))
cv2.putText(depthFrameColor, f"Y: {int(depthData.spatialCoordinates.y)} mm", (xmin + 10, ymin + 35),
fontType, 0.5, (255, 0, 0))
cv2.putText(depthFrameColor, f"Z: {int(depthData.spatialCoordinates.z)} mm", (xmin + 10, ymin + 50),
fontType, 0.5, (255, 0, 0))
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), cv2.FONT_HERSHEY_SIMPLEX)
cv2.putText(frame, f"X: {int(depthData.spatialCoordinates.x)} mm", (x + 10, y + 20),
fontType, 0.5, (255, 0, 0))
cv2.putText(frame, f"Y: {int(depthData.spatialCoordinates.y)} mm", (x + 10, y + 35),
fontType, 0.5, (255, 0, 0))
cv2.putText(frame, f"Z: {int(depthData.spatialCoordinates.z)} mm", (x + 10, y + 50),
fontType, 0.5, (255, 0, 0))
cv2.putText(frame, f"d: {round(distance,2)} mm", (x + 10, y + 70), fontType, 0.5, (255, 0, 0))
cv2.imshow("depthFrameColor",depthFrameColor)
cv2.putText(frame, "NN fps: {:.2f}".format(fps), (2, frame.shape[0] - 4), cv2.FONT_HERSHEY_TRIPLEX, 0.4,
(255, 0, 0))
cv2.imshow("nn_input", frame)
cv2.imwrite("nn.jpg",frame)
counter += 1
if (time.time() - start_time) > 1:
fps = counter / (time.time() - start_time)
counter = 0
start_time = time.time()
if cv2.waitKey(1) == ord('q'):
break
测距离





本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)