迭代器iterator
- 迭代器iterator
- 1、定义
- 2、iterator中typedef的型别(iter_traits)
- 3、iterator的五种类型
- 3.1、Output iteator(只写)
- 3.2、Input iteator(只读)
- 3.3、Forward iterator
- 3.4、Bidrectional iterator
- 3.5、Random access iterator
- 4、iterator_category 对算法的影响
- 5、迭代器失效
- 5.1、定义
- 5.2、序列式容器迭代器失效
- 5.2.1、vector迭代器失效
-
- 5.2.2、list迭代器失效
- 5.3、关联式容器迭代器失效
-
- 5.4、总结
- 参考
迭代器iterator
1、定义
Iterator(迭代器)模式又称Cursor(游标)模式,用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。或者这样说可能更容易理解:Iterator模式是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。
作用:
- 1、将数据容器和算法分开,彼此独立设计,最后再用桥梁将它们联系在一起,这个桥梁就是迭代器。
- 2、算法运用迭代器的时候,可能会用到其相应的型别,例如返回值为容器中元素的型别
- 3、它支持以不同的方式遍历一个聚合.复杂的聚合可用多种方式进行遍历,如二叉树的遍历,可以采用前序、中序或后序遍历。迭代器模式使得改变遍历算法变得很容易: 仅需用一个不同的迭代器的实例代替原先的实例即可,你也可以自己定义迭代器的子类以支持新的遍历,或者可以在遍历中增加一些逻辑,如有条件的遍历等。
- 4、Iterator模式可以为遍历不同的聚合结构(需拥有相同的基类)提供一个统一的接口,即支持多态迭代。(下面会说明不同迭代器的继承关系)
2、iterator中typedef的型别(iter_traits)
#ifdef __STL_USE_NAMESPACES
template <class _Category, class _Tp, class _Distance = ptrdiff_t,
class _Pointer = _Tp*, class _Reference = _Tp&>
struct iterator {
typedef _Category iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Pointer pointer;
typedef _Reference reference;
};
#endif
#ifdef __STL_CLASS_PARTIAL_SPECIALIZATION
template <class _Iterator>
struct iterator_traits {
typedef typename _Iterator::iterator_category iterator_category;
typedef typename _Iterator::value_type value_type;
typedef typename _Iterator::difference_type difference_type;
typedef typename _Iterator::pointer pointer;
typedef typename _Iterator::reference reference;
};
template <class _Tp>
struct iterator_traits<_Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};
template <class _Tp>
struct iterator_traits<const _Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef const _Tp* pointer;
typedef const _Tp& reference;
};
见traits
3、iterator的五种类型

迭代器共分为五种,分别为:
- 1、输入迭代器(Input iterator)、
- 此迭代器不允许修改所指的对象,即是只读的。支持==、!=、++、*、->等操作。
- 2、输出迭代器(Output iterator)、
- 允许算法在这种迭代器所形成的区间上进行只写操作。支持++、*等操作。
- 3、前向迭代器(Forward iterator)、
- 允许算法在这种迭代器所形成的区间上进行读写操作,但只能单向移动,每次只能移动一步。支持Input Iterator和Output Iterator的所有操作。
- 4、双向迭代器(Bidirectional iterator)、
- 允许算法在这种迭代器所形成的区间上进行读写操作,可双向移动,每次只能移动一步。支持Forward Iterator的所有操作,并另外支持–操作。
- 5、随机存取迭代器(Random access iterator)
- 包含指针的所有操作,可进行随机访问,随意移动指定的步数。支持前面四种Iterator的所有操作,并另外支持it + n、it - n、it += n、 it -= n、it1 - it2和it[n]等操作。
继承关系如上图:
1、随机存取迭代器 继承 双向迭代器
2、双向迭代器 继承 单向迭代器
3、单向继承输入
struct input_iterator_tag { };
struct output_iterator_tag { };
struct forward_iterator_tag : public input_iterator_tag
{ };
struct bidirectional_iterator_tag : public forward_iterator_tag
{ };
struct random_access_iterator_tag : public bidirectional_iterator_tag
{ };
注意:为什么要有这些分类?
位置继承体系越后的类,功能越强大,但是考虑的东西也会越多,体型也会越臃肿。为了提供最大化的执行效率,STL在设计算法时,会尽量提供一个最明确最合适的迭代器,在完成任务的同时,也尽量提高算法的效率。假设有个算法可接受Forward Iterator,此时,你可以传入一个Random Access Iterator,因为Random Access Iterator也是一种Forward Iterator,但是可用并不代表最合适,我们只需要Forward Iterator的功能。
template <class _Tp, class _Distance> struct input_iterator {
typedef input_iterator_tag iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};
struct output_iterator {
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
};
template <class _Tp, class _Distance> struct forward_iterator {
typedef forward_iterator_tag iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};
template <class _Tp, class _Distance> struct bidirectional_iterator {
typedef bidirectional_iterator_tag iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};
template <class _Tp, class _Distance> struct random_access_iterator {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};
template <class _Iter>
inline typename iterator_traits<_Iter>::iterator_category
__iterator_category(const _Iter&)
{
typedef typename iterator_traits<_Iter>::iterator_category _Category;
return _Category();
}
3.1、Output iteator(只写)
- (1)可以复制和赋值: Type(iter), copy constructor
- (2)**可以写值: iter = val,但是不能读:val = *iter,val = iter->member;
- (3)可以累加:++iter, iter++。
- (4)类似Input iterator,同一时间不能有两个不同的Output
iterator指向同一个区间内的不同地点。移动中的指针进行写入,一旦写完遍继续移动。 - (5)适用于单回(single-pass)算法,如:copy。
注意:不支持 ==, !=, 唯一不支持的iterator。
Output Iterator 所形成的区间都是以单独一个Iterator再加上一个计量值来决定的。如copy: 输出区间以result开头,再以[first, last)的元素个数作为区间的长度。
template <typename InputIterator, typename OutputIterator>
OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result)
{
for ( ; first != last; ++result, ++first) {
*result = *first;
}
return result;
}
3.2、Input iteator(只读)
特点:
-
1、Input iterator用来指向某对象,但不需要提供任何更改该对象的方法, 就是只读的。你可以*或->,但是不能对结果赋值,即:*iter; iter->member可以,*iter = val(要求写)不一定可以。
-
2、Input iterator可以累加,但是不可以递减。可以++iter; iter++, 这是Input iterator唯一需要的运算形式。 不可以–iter; iter–。
-
3、Input iterator支持有限的比较形式,可以测试iter1 = iter2; iter1 != iter2;但是不可以比较谁在谁前面。
-
4、Input iterator 是 single pass的,你有且只能遍历range(beg, end)一次。不能重复遍历。
-
5、Input iterator可以copy,支持copy constructor: TYPE(iter)。

input iterator和output iterator的不足:
-
1、 input iterator具只读性, output iterator 具只写性。意味着: 需要读取并更改的某一区间的算法,无法单就这些concept来运作。可以利用input iterator写出某种查找算法,但是无法写出查找并置换的算法。
-
2、 运用input iterator和output iterator的算法,只能是single
pass算法,使得算法的复杂度O(N)。
-
3、任何时刻,区间内只能有一个有效的input iterator或output
iterator。使得算法在同一时刻只能对单一元素做动作。对于行为取决于两个或多个不同元素
之间的关系的算法无能为力。
3.3、Forward iterator
Fordward iterator就不会有input iterator和output iterator的限制。一个Forward iterator model必须是input iterator model和output iterator model。因此,可以写出一种算法在同一区间内做读取动作和更新动作。
template <class ForwardIterator, class T>
void replace(ForwardIterator first, ForwardIterator last,
const T &old_value, const T &new_value)
{
for ( ; first != last; ++first) {
if (*first == old_value) {
*first = new_valude;
}
}
Forward iterator也适用于在同一区间使用一个以上的iterator,是multipass的。
template <class ForwardIterator>
ForwardIterator adjacent_find(ForwardIterator first, ForwardIterator last)
{
if (first == last) {
return last;
}
ForwardIterator next = first;
while (++next != last) {
if (*first == *next) {
return first;
}
first = next;
}
return last;
}
3.4、Bidrectional iterator
- 类似于Forward Iterator,Bidirection iterator允许multipass,也可以是const或mutable。
- 支持双向移动,因此相对于Forward_iterator支持–iter和iter–,如遍历单项链表用Forward Iterator,遍历双向链表用Bidirectiorn iterator。
template <class BidrectionalIteartaor, class OutputIterator>
OutputIterator reverse_copy(BidirctionalIterator first, Bidirctional last, OutputIterator result)
{
while (first != last) {
--last;
*result = *last;
++result;
}
return result;
}
3.5、Random access iterator
- 1、提供了算术运算能力:iter + n, iter -n, iter[n], iter - iter2, iter < iter2,这些都是特有的。
- 2、排序算法需要用到这个iterator,需要对比并交换相隔甚远的元素,而非只是相邻元素。
- 3、Random Access Iterator主要是考虑到复杂度:
- 例如:advance(), Forward Iterator是O(N), 而随机Iterator为O(1);
- 所以:Random Access iterator正真独特的性质为:在固定时间随机访问任意元素。
- 4、相关容器: array, vector, deque, string, wstring, C-style
arrays(pointers)。
4、iterator_category 对算法的影响

1、distance()为例,它的目的是得到迭代器直接的距离。
template <class _InputIterator>
inline typename iterator_traits<_InputIterator>::difference_type
__distance(_InputIterator __first, _InputIterator __last, input_iterator_tag)
{
typename iterator_traits<_InputIterator>::difference_type __n = 0;
while (__first != __last) {
++__first; ++__n;
}
return __n;
}
template <class _RandomAccessIterator>
inline typename iterator_traits<_RandomAccessIterator>::difference_type
__distance(_RandomAccessIterator __first, _RandomAccessIterator __last,
random_access_iterator_tag) {
__STL_REQUIRES(_RandomAccessIterator, _RandomAccessIterator);
return __last - __first;
}
template <class _InputIterator>
inline typename iterator_traits<_InputIterator>::difference_type
distance(_InputIterator __first, _InputIterator __last) {
typedef typename iterator_traits<_InputIterator>::iterator_category
_Category;
__STL_REQUIRES(_InputIterator, _InputIterator);
return __distance(__first, __last, _Category());
}
在distance()中,通过判断不同迭代器类型来调用不同的函数以达到最大的效率。
int main(){
int a[] = { 1, 2, 3, 4 };
std::vector<int> vec{ 1, 2, 3, 4 };
std::list<int> lis{ 1, 2, 3, 4 };
std::cout<<"vec distance:"<<WT::distance(vec.begin(), vec.end())<<std::endl;
std::cout << "list distance:" << WT::distance(lis.begin(), lis.end())<<std::endl;
std::cout << "c-array distance:" << WT::distance(a,a + sizeof(a) / sizeof(*a)) << std::endl;
}
2、再以advanced() 为例,它的目的是使迭代器向前移动n步。利用函数重载,我们可以事先标记不同迭代器类型,并将其作为第3个参数传给advanced。

template <typename InputIterator, typename Distance>
inline void advance(InputIterator &iter, Distance n)
{
typedef typename iterator_traits<InputIterator>::iterator_category category;
__advance(iter, n, category());
}
template <typename RandomAccessIterator, typename Distance>
void __advance(RandomAccessIterator iter, Distance n, random_access_iterator_tag)
{
iter += n;
}
template <typename InputIterator, typename Distance>
void __advance(InputIterator iter, Distance n, input_iterator_tag)
{
while(n--)
iter++;
}
template <typename BidirectionalIterator, typename Distance>
void __advance(BidirectionalIterator iter, Distance n, bidirectional_iterator_tag)
{
if (n >= 0)
while(n--)
iter++;
else
while(n++)
iter--;
}
__advanced中的第三个参数仅仅是激活重载。但我们还需要一个提供上层统一的接口,在这一层中通过traits机制,将迭代器类型推导出来。
5、迭代器失效
5.1、定义
当使用一个容器的insert或者erase函数通过迭代器插入或删除元素"可能"会导致迭代器失效:
- 1、如果插入操作引起了空间重新配置,(申请新空间,赋旧空间的值到新空间,释放旧空间),那么在插入操作执行后,之前声明的所有迭代器都将失效
- 2、如果没有引起空间配置,那么会导致插入位置之后的迭代器失效。
- 3、由于删除元素使得某些元素次序发生变化使得原本指向某元素的迭代器不再指向希望指向的元素。
5.2、序列式容器迭代器失效
- 1、vector(数组式容器)
- 删除当前的iterator会使后面所有元素的iterator都失效。这是因为vetor,deque使用了连续分配的内存,删除一个元素导致后面所有的元素会向前移动一个位置。所以不能使用erase(iter++)的方式。
- 2、list
- 在开头、末尾和中间任何地方增加或删除元素所需时间都为常量。
- 可动态增加或减少元素,内存管理自动完成。
- 增加任何元素都不会使迭代器失效。删除元素时,除了指向当前被删除元素的迭代器外,其它迭代器都不会失效。
- 3、deque(数组式容器)
- 在deque容器首部或者尾部插入元素不会使得任何迭代器失效。
- 在其首部或尾部删除元素则只会使指向被删除元素的迭代器失效。
- 在deque容器的任何其他位置的插入和删除操作将使指向该容器元素的所有迭代器失效。
5.2.1、vector迭代器失效
失效操作:
- (1)执行erase方法时,指向删除节点及其之后的全部迭代器均失效;
- (2)执行push_back方法时,end操作返回的迭代器失效;
- (3)扩容产生,此时begin和end操作返回的迭代器都会失效;
- (4)插入一个元素后,没有扩容,指向插入位置之前的元素的迭代器仍然有效。
实验1:
#include <iostream>
#include <stdio.h>
#include <vector>
#include <algorithm>
#include <string>
void del_elem(vector<string> &vec, const char * elem)
{
vector<string>::iterator itor = vec.begin();
for (; itor != vec.end(); itor++)
{
if (*itor == elem)
{
vec.erase(itor);
}
}
}
template <class InputIterator>
void show_vec(InputIterator first, InputIterator last)
{
while(first != last)
{
std::cout << *first << " ";
first++;
}
std::cout << " " << std::endl;
}
int main(void)
{
string arr[] = {"php", "c#", "java", "js", "lua"};
vector<string> vec(arr, arr+(sizeof(arr)/sizeof(arr[0])));
std::cout << "before del: " << std::endl;
show_vec(vec.begin(), vec.end());
del_elem(vec, "php");
std::cout << "after del: " << std::endl;
show_vec(vec.begin(), vec.end());
return 0;
}
VS2015编译结果:

代码在处理Iterator的earse的时候有点问题。当一个Container执行了一次earse操作之后,原来用来遍历的iterator就失效了,其行为是不可预测的,具体情况由实现决定。同时earse操作会返回一个指向container下一个元素的iterator,如果想继续遍历,就得用返回的iterator继续操作。(解决方法后面介绍)
ubuntu18.04环境g++编译结果
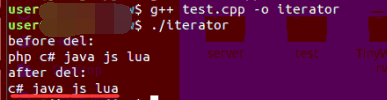
运行结果是正确的啊。 找到 “php” ,然后删除,剩下四个元素。
但是实际上 del_elem 的过程是和我们想象的不一样的,在 del_elem中打印下每一步的 itor 的值,就会发现蛛丝马迹。
void del_elem(vector<string> &vec, const char * elem)
{
std::cout << "----------------------------" << std::endl;
vector<string>::iterator itor = vec.begin();
for (; itor != vec.end(); itor++)
{
std::cout << *itor << std::endl;
if (*itor == elem)
{
vec.erase(itor);
}
}
std::cout << "----------------------------" << std::endl;
}
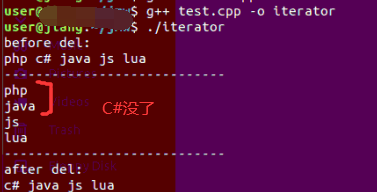
在做 del_elem操作时,少打印了一个 “c#”, 也就是在打印完"php",然后删除php以后,接下来打印的不是 “c#”, 而直接打印了 “java” 。
erase的实现方法(仅分析删除单个元素的情况)
iterator erase(iterator position)
{
if(position + 1 != end())
copy(position + 1, finish, position);
--finish;
destroy(finish);
return position;
}
iterator begin() { return start; }
iterator end() { return finish; }
- 1、先判断 待删除的迭代器是否为 finish 的前一个元素,也就是vector中的最后一个元素;
- 2、如果不是最后一个元素,就将待删除迭代器的后边所有元素往前移动一个slot, 然后 --finish 重新定位finish指针;
- 3、此时finish指针指向的是没删除之前的最后一个元素地址,本例中就是 lua的地址,但是当前的finish指针处的值已经没用了,于是调用destroy。
- 4、如果待删除迭代器是finish的前一个元素的话,那么就直接移动finish指针,调用destroy销毁该位置处的元素对象。
- 5、erase函数传进来的迭代器,只起到了一个位置定位判断的作用,erase本身没有对该迭代器有任何操作,该迭代器的值所在地址仍然有效,但是由于进行了copy操作,position处的值已经变成了"c#"。
再回过头来看一下我们的 del_elem 函数:
- 1、当删除第一个元素php之后,在执行 itor++之前,php之后的所有元素都前移了一个slot导致此时 itor存放的元素已经是 c#
- 2、于是继续执行itor++后,此时itor又向后移动,itor中的值已经是java,c#就是这样被漏掉的。
实验2:删除多个相同元素时
将 string arr[] = {“php”, “c#”, “java”, “js”, “lua”}; 改为 string arr[] = {“php”, “php”, “php”, “php”, “c#”, “java”, “js”, “lua”};
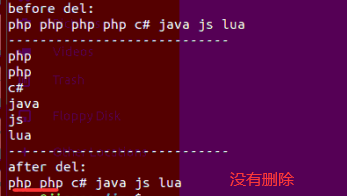
del_elem函数 是不能删除掉所有的php元素,因为当删除第一个php以后,用当前 del_elem 方法,总是会漏掉删除的php之后的元素,如果这个元素恰好是 “php”,便会出现bug。
实验3:删除的元素时最后一个元素
将最后一个元素改为 “php”; string arr[] = {“php”, “php”, “php”, “php”, “c#”, “java”, “js”, “php”};
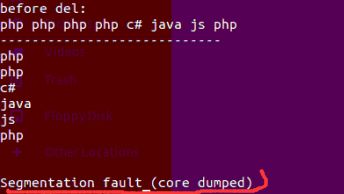
将php放到最后slot,即finish之前的slot中,当删除最后一个php后,finish会指向删除的php的地址,然后php的地方会被销毁,然后又执行 itor++,于是此时的itor指向到finish的后边,当 判断 itor != vec.end() 时,这个式子是成立的,于是继续执行,但是当对迭代器解引用时,最终会由于是非法。
5.2.1.1、如何删除vector元素
#include <iostream>
#include <stdio.h>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
void del_elem(vector<string> &vec, const char *elem)
{
vector<string>::iterator itor = vec.begin();
for (; itor != vec.end();)
{
std::cout << *itor << " " << &(*itor) << std::endl;
if (*itor == elem)
itor = vec.erase(itor);
else
itor++;
}
}
template <class InputIterator>
void show_vec(InputIterator first, InputIterator last)
{
while (first != last)
{
cout << *first << " ";
first++;
}
cout << " " << endl;
}
int main(void)
{
string arr[] = {"php", "php", "php", "php", "c#", "java", "js", "php"};
vector<string> vec(arr, arr + (sizeof(arr) / sizeof(arr[0])));
cout << "before del: " << endl;
show_vec(vec.begin(), vec.end());
del_elem(vec, "php");
cout << "after del: " << endl;
show_vec(vec.begin(), vec.end());
return 0;
}

5.2.2、list迭代器失效
对于链表式容器(如list),
- 删除当前的iterator,仅仅会使当前的iterator失效,
- 因为list之类的容器,使用了链表来实现,插入、删除一个结点不会对其他结点造成影响。
- 只要在erase时,递增当前iterator即可,并且erase方法可以返回下一个有效的iterator。
#include <iostream>
#include <list>
using namespace std;
void TestListIterator1()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
list<int> l(arr, arr + sizeof(arr) / sizeof(arr[0]));
list<int>::iterator it = l.begin();
for (; it != l.end(); it++)
{
l.erase(it);
}
}
void TestListIterator2()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
list<int> l(arr, arr + sizeof(arr) / sizeof(arr[0]));
list<int>::iterator it = l.begin();
for (; it != l.end();)
{
l.erase(it++);
}
}
int main()
{
TestListIterator2();
system("pause");
return 0;
}
5.3、关联式容器迭代器失效
对于关联容器(如map, set,multimap,multiset),
- 删除当前的iterator,仅仅会使当前的iterator失效
- 只要在erase时,递增当前iterator即可。
- 因为map之类的容器,使用了红黑树来实现,插入、删除一个结点不会对其他结点造成影响。单个节点在内存中的地址没有变化,变化的是各节点之间的指向关系
- erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
5.3.1、map容器迭代器失效
map是关联容器,以红黑树或者平衡二叉树组织数据,虽然删除了一个元素,整棵树也会调整,以符合红黑树或者二叉树的规范,但是单个节点在内存中的地址没有变化,变化的是各节点之间的指向关系。
#include <map>
#include <iostream>
#include <stdio.h>
#include <string>
#include <map>
using namespace std;
int main()
{
map<int, int> _map;
for (int i = 0; i < 10; i++)
{
_map.insert(make_pair(i, i + 1));
}
for (map<int, int>::iterator iter = _map.begin(); iter != _map.end(); iter++)
{
if (iter->first % 3 == 0)
{
_map.erase(iter);
}
}
for (map<int, int>::iterator iter = _map.begin(); iter != _map.end(); ++iter)
{
cout << iter->first << endl;
}
return 0;
}

erase(iter)之后,iter就已经失效了,所以iter无法自增
解决办法
#include <map>
#include <iostream>
#include <stdio.h>
#include <string>
#include <map>
using namespace std;
int main()
{
map<int, int> _map;
for (int i = 0; i < 10; i++)
{
_map.insert(make_pair(i, i + 1));
}
for (map<int, int>::iterator iter = _map.begin(); iter != _map.end(); )
{
if (iter->first % 3 == 0)
{
_map.erase(iter++);
}
else
{
iter++;
}
}
for (map<int, int>::iterator iter = _map.begin(); iter != _map.end(); ++iter)
{
cout << iter->first << " ";
}
cout << endl;
return 0;
}
erase(iter++);这句话分三步走,先把iter传值到erase里面,然后iter自增,然后执行erase,所以iter在失效前已经自增了。
5.4、总结
迭代器失效分三种情况考虑,也是分三种数据结构考虑,分别为数组型,链表型,树型数据结构。
1、数组型数据结构: 该数据结构的元素是分配在连续的内存中,insert和erase操作,都会使得删除点和插入点之后的元素挪位置,所以,插入点和删除掉之后的迭代器全部失效,也就是说insert(*iter)(或erase(*iter)),然后在iter++,是没有意义的。解决方法:erase(*iter)的返回值是下一个有效迭代器的值。 iter =cont.erase(iter);
2、链表型数据结构: 对于list型的数据结构,使用了不连续分配的内存,删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.解决办法两种,erase(*iter)会返回下一个有效迭代器的值,或者erase(iter++).
3、树形数据结构: 使用红黑树来存储数据,插入不会使得任何迭代器失效;删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
*注意:经过erase(iter)之后的迭代器完全失效,该迭代器iter不能参与任何运算,包括iter++,ite
参考
1、https://blog.csdn.net/shudou/article/details/11099931
2、https://www.jianshu.com/p/c7ef6a3efeb9
3、https://www.cnblogs.com/hancm/p/3811038.html
4、https://www.cnblogs.com/blueoverflow/p/4923523.html#_lab2_2_0
5、https://www.cnblogs.com/newbeeyu/p/6883122.html
6、https://www.cnblogs.com/fnlingnzb-learner/p/9300073.html
7、《STL的源码剖析》
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)