引言
在科研中,有时需要爬取网站上的文本数据,用于统计分析,或是制作机器学习所用的数据集。
举个例子,假如我们需要在世界野生鸟类声音网XenoCanto中,爬取网站上的鸟类声音标签信息,如下图所示:
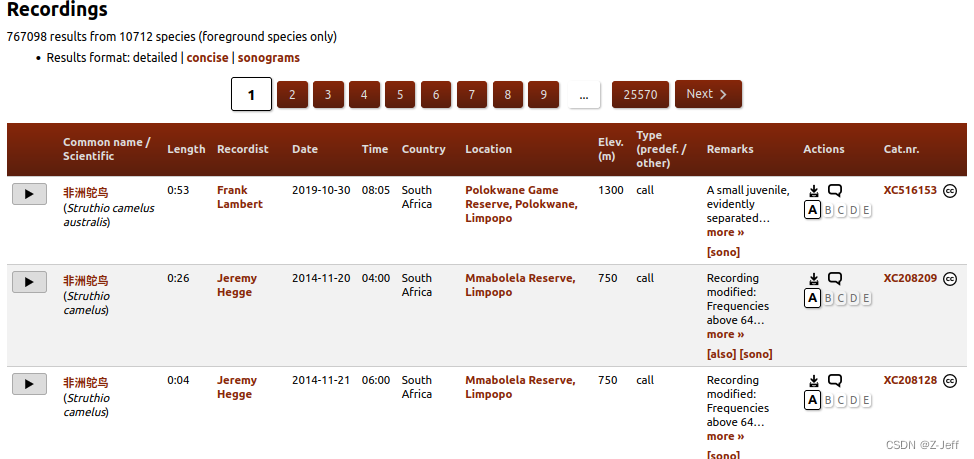
该网站上的数据量非常大,有67万条数据,手动复制这么大的数据是不现实的。此时,可利用爬虫程序自动获取网页上的数据,保存为表格,便于科研分析。
本博客将以该网站为例,介绍如何利用爬虫代码搜集我们需要的信息。
1. 对网页的理解
网页是由HTML语言(Hyper Text Markup Language,超文本标记语言)进行描述的。
HTML由成对的开始标签和结束标签组成,其中符号< >表示开始标签,</ >表示结束标签。
标签之间可以嵌套,组成不同层级的标签内容。标签开头的空格数越多,代表其嵌套层数越多。
以下代码是一个简单的HTML内容,其中<html>和</html>是文件开头和结尾的格式,<p>和</p>表示一个段落,中间文本就是该段落的内容。
<html>
<p> 一个简单的HTML </p>
</html>
可以新建一个test.html文件,用记事本打开,输入该代码,保存后用浏览器打开,就可看到网页结果:

接下来稍微复杂一点,我们在网页中添加一个表格,用<table>和</table>表示。
表格中的每行用<tr>和</tr>表示,tr的含义为table row。
每行中的每列数据用<td>和</td>表示,td的含义为table data。
一个包含表格的网页代码如下:
<html>
<table>
<tr>
<td> 第一列 </td>
<td> 第二列 </td>
<td> 第三列 </td>
</tr>
<tr>
<td> 1 </td>
<td> 2 </td>
<td> 3 </td>
</tr>
</table>
</html>
其网页结果:

不同于以上两个简单的示例,实际网页中的标签种类更多,更复杂。
接下来,让我们看看目标网站的HTML代码。
在浏览器页面中,同时按下Ctrl+Shift+C键,进入开发者模式,其中以<!DOCTYPE html>开头的窗口,就是HTML代码窗口啦。将鼠标放置在HTML标签上,网页上对应的内容就会出现蓝色遮罩。点击三角箭头,可以展开或者隐藏某一级标签。

通过人工观察,确定目标数据在<table class="results">标签中,一行数据在一个<tr>标签中,一列数据在一个<td>标签中。其中,class="results"是<table>标签的属性,当网页中存在多个<table>时,可利用属性来定位目标表格。
忽略掉网页内其他数据,该网页HTML进行简化为:
<!DOCTYPE html>
<html>
...
<table class="results">
...
<tr> <!-- 第一行数据 -->
<td> </td>
<td> </td>
...
</tr>
<tr> <!-- 第二行数据 -->
<td> </td>
<td> </td>
...
</tr>
...
</table>
...
</html>
到此,对目标网页结构的理解已经足够,接下来就是编写爬虫代码,获取目标数据啦。
2. 爬取单个网页
编程语言使用python3,需要三个软件包:requests、BeautifulSoup、csv
安装命令:
pip3 install requests
pip3 install bs4
# bs4的意思是BeautifulSoup-version4
# csv是python3默认安装,无需额外安装
requests包模拟客户端发送网络请求,接受响应,并获取网页内容。
BeautifulSoup包可作为HTML解析库,从网页内容中提取数据。
csv包用于保存表格数据。
接下来编写爬虫代码,仅需要简单的三步:
(1)请求网页内容
# 从给定链接中,获取网页内容
html = requests.get("https://xeno-canto.org/explore")
(2)提取网页内容
# 按协议解析网页
soup = BeautifulSoup(html.text, 'lxml')
# 从网页内容中,定位目标表格
table = soup.find('table', attrs={'class': 'results'})
# print(table.text) # 表格文本内容
# 获取网格中所有行
trs = table.find_all('tr')
data = []
# 遍历每一行
for tr in trs:
# 获取一行中的所有列
tds = tr.find_all('td')
row = []
# 遍历每一列
for td in tds:
row.append(td.text)
data.append(row)
这里爬虫的核心是两个函数:find()和find_all()
其相同点:
1. 主参数为标签名,也可输入参数attrs={'属性名', '属性值'},返回满足条件的对象。
2. 返回对象可继续提取子对象。
3. 可通过.text成员变量,获取对象的文本内容。
不同点:
1. find()返回满足条件的第一个对象。
2. find_all()返回满足条件的所有对象,可理解返回一个对象列表。
由此可以抽象出三种代码组织方式,如以下代码所示。使用哪种方式,看具体需求而定。
soup = BeautifulSoup(html.text, 'lxml')
# 第一种方式:嵌套find()
a = find('标签名1')
b = a.find('标签名2')
print(b.text)
# 第二种方式:嵌套find_all()
aa = find_all('标签名1')
for a in aa:
bb = a.find_all('标签名2')
for b in bb:
print(b.text)
# 第三种方式:嵌套find()和find_all()
a = find('标签名1')
bb = a.find_all('标签名2')
for b in bb:
print(b.text)
(3)保存爬取数据
with open('data.csv', 'w') as f:
# 用逗号分割表格
csv_writer = csv.writer(f, delimiter=',')
for row in data:
# 向csv文件中写入一行
csv_writer.writerow(row)
爬取单个网页内容的完整代码如下:
import requests
from bs4 import BeautifulSoup
import csv
# Step1: 请求网页内容
html = requests.get("https://xeno-canto.org/explore?query=since%3A31&dir=0&order=xc")
# Step2: 提取网页内容
soup = BeautifulSoup(html.text, 'lxml')
table = soup.find('table', attrs={'class': 'results'})
trs = table.find_all('tr')
data = []
for tr in trs:
tds = tr.find_all('td')
row = []
for td in tds:
row.append(td.text)
data.append(row)
# Step3: 保存爬取数据
with open('data.csv', 'w') as f:
csv_writer = csv.writer(f, delimiter=',')
for row in data:
csv_writer.writerow(row)
可以直接复制粘贴代码,运行一下,看看保存的表格内容。
到这里,恭喜你,你已经会简单的爬虫了!
3. 爬取多个有序网页
接下来,让我们把需求稍微变得复杂一点。
在目标网站中,数据是分页的,有226页!
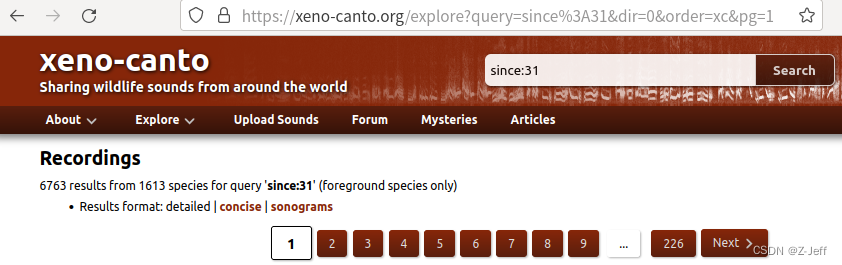
如果爬取一页,就手动更换requests.get()中的网址,显然是不现实的。
幸运的是,这种分页的网址是有序的。
# 第一页网址:
https://xeno-canto.org/explore?query=since%3A31&dir=0&order=xc&pg=1
# 第二页网址:
https://xeno-canto.org/explore?query=since%3A31&dir=0&order=xc&pg=2
...
# 最后一页网址:
https://xeno-canto.org/explore?query=since%3A31&dir=0&order=xc&pg=25583
观察不同页码的网址,可以看出规律:网址末尾的最后一个数字为页数。
按照找到的规律,在代码上加一点逻辑,就可以爬取多个网页啦:
import requests
from bs4 import BeautifulSoup
import csv
page_num = 226
url_prefix = 'https://xeno-canto.org/explore?query=since%3A31&dir=0&order=xc&pg='
file_name = 'data.csv'
f = open(file_name, 'w')
csv_writer = csv.writer(f, delimiter=',')
count = 0
for idx in range(1, page_num+1):
url = url_prefix + str(idx)
html = requests.get(url)
soup = BeautifulSoup(html.text, 'lxml')
table = soup.find('table', attrs={'class': 'results'})
trs = table.find_all('tr')
# 跳过第一行表头
for tr in trs[1:]:
tds = tr.find_all('td')
row = []
for td in tds:
row.append(td.text)
csv_writer.writerow(row)
count += 1
print('爬取页数:', idx, '数据个数:', count, '当前网址:', url)
print('所有网页爬取完成!')
总结
本博客介绍了基于requests、BeautifulSoup、csv三个库实现的爬虫代码。
对目标网页结构有了基本认识后,编写爬虫代码并不复杂。
但在实际项目中,目标网站可能有反爬机制,或者验证码机制,本文方法将无法工作。对于这种情况,可利用Selenium包编写爬虫。
希望本博客能帮助广大科研党入门爬虫。
参考文献
HTML 简介 | 菜鸟教程
通用爬虫模块+requests包的5种作用_request包的作用_-随_风-的博客-CSDN博客
python中beautifulsoup的作用_Python3中BeautifulSoup的使用方法_Screwberry的博客-CSDN博客
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)