6.2 代码解析
 这部分代码在estimator::processImage()最后面。初始化部分的代码虽然生命周期比较短,但是,代码量巨大!主要分成2部分,第一部分是纯视觉SfM优化滑窗内的位姿,然后在融合IMU信息,按照理论部分优化各个状态量。
这部分代码在estimator::processImage()最后面。初始化部分的代码虽然生命周期比较短,但是,代码量巨大!主要分成2部分,第一部分是纯视觉SfM优化滑窗内的位姿,然后在融合IMU信息,按照理论部分优化各个状态量。
if (solver_flag == INITIAL)
{
if (frame_count == WINDOW_SIZE)
{
bool result = false;
if( ESTIMATE_EXTRINSIC != 2 && (header.stamp.toSec() - initial_timestamp) > 0.1)
{
result = initialStructure();
initial_timestamp = header.stamp.toSec();
}
if(result)
{
solver_flag = NON_LINEAR;
solveOdometry();
slideWindow();
f_manager.removeFailures();
ROS_INFO("Initialization finish!");
last_R = Rs[WINDOW_SIZE];
last_P = Ps[WINDOW_SIZE];
last_R0 = Rs[0];
last_P0 = Ps[0];
}
else
slideWindow();
}
else
;
}
6.3 initialStructure()
这是一个相当大的函数,而且多层套娃。而且原理上讲的初始化,包括纯视觉SfM,视觉和IMU的松耦合,都是在这个部分里面。

6.3.1 确保IMU有足够的excitation(可选)
这一部分的思想就是通过计算滑窗内所有帧的线加速度的标准差,判断IMU是否有充分运动激励,以判断是否进行初始化。
一上来就出现all_image_frame这个数据结构,见5.2-2,它包含了滑窗内所有帧的视觉和IMU信息,它是一个hash,以时间戳为索引。
(1)第一次循环,求出滑窗内的平均线加速度
Vector3d sum_g;
for (frame_it = all_image_frame.begin(), frame_it++; frame_it != all_image_frame.end(); frame_it++)
{
double dt = frame_it->second.pre_integration->sum_dt;
Vector3d tmp_g = frame_it->second.pre_integration->delta_v / dt;
sum_g += tmp_g;
}
Vector3d aver_g;
aver_g = sum_g * 1.0 / ((int)all_image_frame.size() - 1);
(2)第二次循环,求出滑窗内的线加速度的标准差
double var = 0;
for (frame_it = all_image_frame.begin(), frame_it++; frame_it != all_image_frame.end(); frame_it++)
{
double dt = frame_it->second.pre_integration->sum_dt;
Vector3d tmp_g = frame_it->second.pre_integration->delta_v / dt;
var += (tmp_g - aver_g).transpose() * (tmp_g - aver_g);
}
var = sqrt(var / ((int)all_image_frame.size() - 1));
if(var < 0.25)
{
ROS_INFO("IMU excitation not enouth!");
}
6.3.2 将f_manager中的所有feature在所有帧的归一化坐标保存到vector sfm_f中(辅助)
(1)一上来就定义了几个容器,分别是:
Quaterniond Q[frame_count + 1];
Vector3d T[frame_count + 1];
map<int, Vector3d> sfm_tracked_points;
vector<SFMFeature> sfm_f;
这块有2个需要注意的地方,
就是为什么容量是frame_count + 1?因为滑窗的容量是10,再加上当前最新帧,所以需要储存11帧的值!
然后出现了一个新的数据结构,我们看一下:
数据结构: vector<SFMFeature> sfm_f
它定义在initial/initial_sfm.h中,
struct SFMFeature
{
bool state;
int id;
vector<pair<int,Vector2d>> observation;
double position[3];
double depth;
};
可以发现,它存放着一个特征点的所有信息。容器定义完了,接下来就是往容器里放数据。
(2) 往容器里放数据
for (auto &it_per_id : f_manager.feature)
{
int imu_j = it_per_id.start_frame - 1;
SFMFeature tmp_feature;
tmp_feature.state = false;
tmp_feature.id = it_per_id.feature_id;
for (auto &it_per_frame : it_per_id.feature_per_frame)
{
imu_j++;
Vector3d pts_j = it_per_frame.point;
tmp_feature.observation.push_back(make_pair(imu_j, Eigen::Vector2d{pts_j.x(), pts_j.y()}));
}
sfm_f.push_back(tmp_feature);
}
在这里,为什么要多此一举构造一个sfm_f而不是直接使用f_manager呢?
我的理解,是因为f_manager的信息量大于SfM所需的信息量(f_manager包含了大量的像素信息),而且不同的数据结构是为了不同的业务服务的,所以在这里作者专门为SfM设计了一个全新的数据结构sfm_f,专业化服务。
6.3.3 在滑窗(0-9)中找到第一个满足要求的帧(第l帧),它与最新一帧(frame_count=10)有足够的共视点和平行度,并求出这两帧之间的相对位置变化关系
(1)定义容器
Matrix3d relative_R;
Vector3d relative_T;
int l;
(2)两帧之间的视差判断,并得到两帧之间的相对位姿变化关系
if (!relativePose(relative_R, relative_T, l))
{
ROS_INFO("Not enough features or parallax; Move device around");
return false;
}
这里,又出现了个新的函数relativePose(),这个函数也是6.3.3的主要功能,进去看一下:
首先,搞清楚这个函数是要干什么事情?
a.计算滑窗内的每一帧(0-9)与最新一帧(10)之间的视差,直到找出第一个满足要求的帧,作为我们的第l帧;
Estimator::relativePose(Matrix3d &relative_R, Vector3d &relative_T, int &l)
{
for (int i = 0; i < WINDOW_SIZE; i++)
{
vector<pair<Vector3d, Vector3d>> corres;
corres = f_manager.getCorresponding(i, WINDOW_SIZE);
if (corres.size() > 20)
{
double sum_parallax = 0;
double average_parallax;
for (int j = 0; j < int(corres.size()); j++)
{
Vector2d pts_0(corres[j].first(0), corres[j].first(1));
Vector2d pts_1(corres[j].second(0), corres[j].second(1));
double parallax = (pts_0 - pts_1).norm();
sum_parallax = sum_parallax + parallax;
}
average_parallax = 1.0 * sum_parallax / int(corres.size());
getCorresponding()的作用就是找到当前帧与最新一帧所有特征点在对应2帧下分别的归一化坐标,并配对,以供求出相对位姿时使用。
b.计算l帧与最新一帧的相对位姿关系
if(average_parallax * 460 > 30 && m_estimator.solveRelativeRT(corres, relative_R, relative_T))
{
l = i;
ROS_DEBUG("average_parallax %f choose l %d and newest frame to triangulate the whole structure", average_parallax * 460, l);
return true;
}
这里最核心的公式就是m_estimator.solveRelativeRT(),这部分非常地关键。这里面代码很简单,就是把对应的点传进入,然后套cv的公式,但是求出来的R和T是谁转向谁的比较容易迷糊。
根据对以前学习内容和回忆和对后面公式的阅读,这个relative_R和relative_T是把最新一帧旋转到第l帧的旋转平移!
bool MotionEstimator::solveRelativeRT(const vector<pair<Vector3d, Vector3d>> &corres, Matrix3d &Rotation, Vector3d &Translation)
{
if (corres.size() >= 15)
{
vector<cv::Point2f> ll, rr;
for (int i = 0; i < int(corres.size()); i++)
{
ll.push_back(cv::Point2f(corres[i].first(0), corres[i].first(1)));
rr.push_back(cv::Point2f(corres[i].second(0), corres[i].second(1)));
}
cv::Mat mask;
cv::Mat E = cv::findFundamentalMat(ll, rr, cv::FM_RANSAC, 0.3 / 460, 0.99, mask);
cv::Mat cameraMatrix = (cv::Mat_<double>(3, 3) << 1, 0, 0, 0, 1, 0, 0, 0, 1);
cv::Mat rot, trans;
int inlier_cnt = cv::recoverPose(E, ll, rr, cameraMatrix, rot, trans, mask);
Eigen::Matrix3d R;
Eigen::Vector3d T;
for (int i = 0; i < 3; i++)
{
T(i) = trans.at<double>(i, 0);
for (int j = 0; j < 3; j++)
R(i, j) = rot.at<double>(i, j);
}
Rotation = R.transpose();
Translation = -R.transpose() * T;
if(inlier_cnt > 12)
return true;
else
return false;
}
return false;
}
而且这里出现了个新的数据结构m_estimator,分析一下。
数据结构: MotionEstimator m_estimator
它定义在initial/solve_5pts.h中,这个类没有数据成员,只有函数功能。所以说,TODO 把这个h文件干掉,融到estimator.cpp里面去!
class MotionEstimator
{
public:
bool solveRelativeRT(const vector<pair<Vector3d, Vector3d>> &corres, Matrix3d &R, Vector3d &T);
private:
double testTriangulation(const vector<cv::Point2f> &l,
const vector<cv::Point2f> &r,
cv::Mat_<double> R, cv::Mat_<double> t);
void decomposeE(cv::Mat E,
cv::Mat_<double> &R1, cv::Mat_<double> &R2,
cv::Mat_<double> &t1, cv::Mat_<double> &t2);
};
这一部分的原理对应如下,

Assuming P =[X, Y, Z]T is the 3D coordinates of one feature in camera coordinate system at time bk. K is the intrinsic parameter matrix of camera. p1 and p2 are pixel coordinates of the feature on image bk and bk+1. Then it is,
s1p1 = KP, s2x2 = K (RP + t).
At normalized plane, the coordinates are,
x1 = K-1p1, x2 = K-1p2.
Then they can get,
s2x2 = s1Rx1 + t.
The equation left multiplies t^ which is,
t^s2x2 = s1t^Rx1.
Then left multiplies x2T then gets,
0 = x2T (t^R) x1, or 0 = p2T (K-Tt^RK-1) p1,
c.没有满足要求的帧,整个初始化initialStructure()失败。
return false
6.3.4 construct():对窗口中每个图像帧求解sfm问题
得到所有图像帧相对于参考帧的旋转四元数Q、平移向量T和特征点坐标(核心!)
首先,还是定义了一个容器,看一下这个容器的数据结构。
GlobalSFM sfm;
数据结构: GlobalSFM sfm
它定义在initial/initial_sfm.h中,
class GlobalSFM
{
public:
GlobalSFM();
bool construct(int frame_num, Quaterniond* q, Vector3d* T, int l,
const Matrix3d relative_R, const Vector3d relative_T,
vector<SFMFeature> &sfm_f, map<int, Vector3d> &sfm_tracked_points);
private:
bool solveFrameByPnP(Matrix3d &R_initial, Vector3d &P_initial, int i, vector<SFMFeature> &sfm_f);
void triangulatePoint(Eigen::Matrix<double, 3, 4> &Pose0, Eigen::Matrix<double, 3, 4> &Pose1 ,Vector2d &point0, Vector2d &point1, Vector3d &point_3d);
void triangulateTwoFrames(int frame0, Eigen::Matrix<double, 3, 4> &Pose0,
int frame1, Eigen::Matrix<double, 3, 4> &Pose1,
vector<SFMFeature> &sfm_f);
int feature_num;
};
所以说这个数据结构和MotionEstimator是类似的,主要是实现函数功能,他只有一个数据成员feature_num。
if(!sfm.construct(frame_count + 1, Q, T, l, //Q ck->c0?
relative_R, relative_T,
sfm_f, sfm_tracked_points))
{
ROS_DEBUG("global SFM failed!");
marginalization_flag = MARGIN_OLD;
return false;
}
这里主要干了2件事,首先SfM,传入了frame_count + 1,l, relative_R, relative_T, sfm_f这几个参数,得到了Q, T, sfm_tracked_points,这三个量的都是基于l帧上表示的!
第二件事就是marginalization_flag = MARGIN_OLD。这说明了在初始化后期的第一次slidingwindow() marg掉的是old帧。
看一下*construct()*里面干了什么。见initial/initial_sfm.cpp文件。
(1)把第l帧作为参考坐标系,获得最新一帧在参考坐标系下的位姿
feature_num = sfm_f.size();
q[l].w() = 1;
q[l].x() = 0;
q[l].y() = 0;
q[l].z() = 0;
T[l].setZero();
q[frame_num - 1] = q[l] * Quaterniond(relative_R);
T[frame_num - 1] = relative_T;
(2)构造容器,存储滑窗内 第l帧 相对于 其它帧 和 最新一帧 的位姿
Matrix3d c_Rotation[frame_num];
Vector3d c_Translation[frame_num];
Quaterniond c_Quat[frame_num];
double c_rotation[frame_num][4];
double c_translation[frame_num][3];
Eigen::Matrix<double, 3, 4> Pose[frame_num];
注意,这些容器存储的都是相对运动,大写的容器对应的是l帧旋转到各个帧。
小写的容器是用于全局BA时使用的,也同样是l帧旋转到各个帧。之所以在这两个地方要保存这种相反的旋转,是因为三角化求深度的时候需要这个相反旋转的矩阵!
为了表示区别,称这两类容器叫 坐标系变换矩阵,而不能叫 位姿 !
(3)对于第l帧和最新一帧,它们的相对运动是已知的,可以直接放入容器
c_Quat[l] = q[l].inverse();
c_Rotation[l] = c_Quat[l].toRotationMatrix();
c_Translation[l] = -1 * (c_Rotation[l] * T[l]);
Pose[l].block<3, 3>(0, 0) = c_Rotation[l];
Pose[l].block<3, 1>(0, 3) = c_Translation[l];
c_Quat[frame_num - 1] = q[frame_num - 1].inverse();
c_Rotation[frame_num - 1] = c_Quat[frame_num - 1].toRotationMatrix();
c_Translation[frame_num - 1] = 1 * (c_Rotation[frame_num - 1] * T[frame_num - 1]);
Pose[frame_num - 1].block<3, 3>(0, 0) = c_Rotation[frame_num - 1];
Pose[frame_num - 1].block<3, 1>(0, 3) = c_Translation[frame_num - 1];
注意,这块有一个取相反旋转的操作,因为三角化的时候需要这个相反的旋转!
(4)三角化l帧和最新帧,获得他们的共视点在l帧上的空间坐标
注意,三角化的前提有1个:两帧的(相对)位姿已知。这样才能把他们的共视点的三维坐标还原出来。
triangulateTwoFrames(l, Pose[l], frame_num - 1, Pose[frame_num - 1], sfm_f);
我们看一下这个函数的内容。
void GlobalSFM::triangulateTwoFrames(int frame0, Eigen::Matrix<double, 3, 4> &Pose0,
int frame1, Eigen::Matrix<double, 3, 4> &Pose1,
vector<SFMFeature> &sfm_f)
{
assert(frame0 != frame1);
for (int j = 0; j < feature_num; j++)
{
if (sfm_f[j].state == true)
continue;
bool has_0 = false, has_1 = false;
Vector2d point0;
Vector2d point1;
for (int k = 0; k < (int)sfm_f[j].observation.size(); k++)
{
if (sfm_f[j].observation[k].first == frame0)
{
point0 = sfm_f[j].observation[k].second;
has_0 = true;
}
if (sfm_f[j].observation[k].first == frame1)
{
point1 = sfm_f[j].observation[k].second;
has_1 = true;
}
}
if (has_0 && has_1)
{
Vector3d point_3d;
triangulatePoint(Pose0, Pose1, point0, point1, point_3d);
sfm_f[j].state = true;
sfm_f[j].position[0] = point_3d(0);
sfm_f[j].position[1] = point_3d(1);
sfm_f[j].position[2] = point_3d(2);
}
}
}
这个函数的核心还是triangulatePoint(Pose0, Pose1, point0, point1, point_3d)。
首先他把sfm_f的特征点取出来,一个个地检查看看这个特征点是不是被2帧都观测到了,如果被观测到了,再执行三角化操作。那么再看看triangulatePoint()是怎么写的。
void GlobalSFM::triangulatePoint(Eigen::Matrix<double, 3, 4> &Pose0, Eigen::Matrix<double, 3, 4> &Pose1,
Vector2d &point0, Vector2d &point1, Vector3d &point_3d)
{
Matrix4d design_matrix = Matrix4d::Zero();
design_matrix.row(0) = point0[0] * Pose0.row(2) - Pose0.row(0);
design_matrix.row(1) = point0[1] * Pose0.row(2) - Pose0.row(1);
design_matrix.row(2) = point1[0] * Pose1.row(2) - Pose1.row(0);
design_matrix.row(3) = point1[1] * Pose1.row(2) - Pose1.row(1);
Vector4d triangulated_point;
triangulated_point =
design_matrix.jacobiSvd(Eigen::ComputeFullV).matrixV().rightCols<1>();
point_3d(0) = triangulated_point(0) / triangulated_point(3);
point_3d(1) = triangulated_point(1) / triangulated_point(3);
point_3d(2) = triangulated_point(2) / triangulated_point(3);
}
这一部分代码涉及到了三角化求深度,对应《SLAM14讲》7.5部分,对应《手写VIO》第6章。
原理如下,对于我们要求的3D坐标,可以表示成齐次形式,
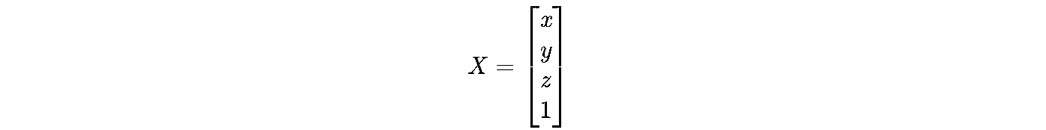
世界坐标系到相机坐标系的变换矩阵,在这里,是l帧到各个帧的转换(因为所有位姿和特征点目前都是在l帧表示的),注意,这块的表示方法和我们习惯的表示方法(一般都是相机到世界的转换)是相反的!
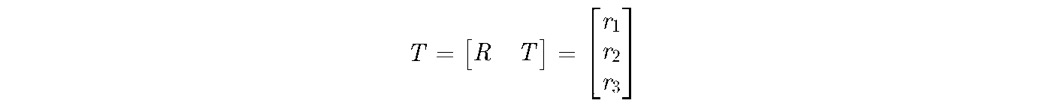
x为相机归一化平面坐标:

λ为深度值,已知以上条件有:
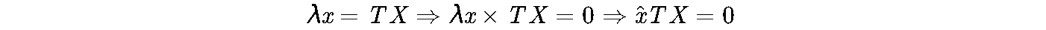
展开上式得:
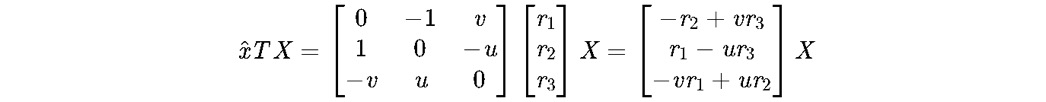
对于等号右边的那个矩阵,它的第一行 ×(−u)第二行 ×(−v),再相加,即可得到第三行,因此,其线性相关,保留前两行即可,有,
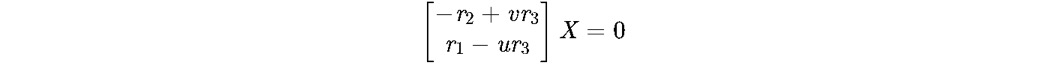
因此,已知一个归一化平面坐标x和变换矩阵T可以构建两个关于X的线性方程组。有两个以上的图像观测即可求出X,
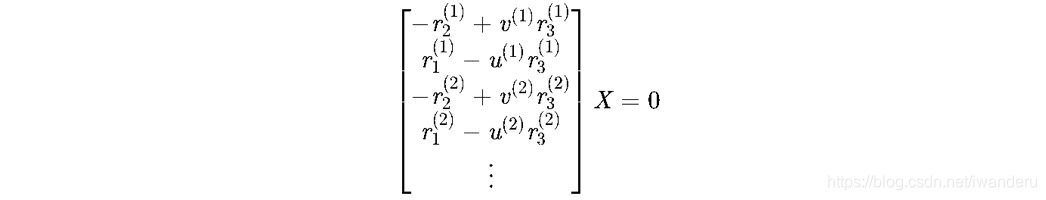
由于得到矩阵的秩大于未知量的数,所以上式方程没有非零解,使用SVD求最小二乘解,最小奇异值对应的向量即为所需的解。这个思路和IMU外参在线标定的方法很像。注意,x向量是四维了,解出来的值最后一个数需要确保它是1,所以,
(5)对于在sliding window里在第l帧之后的每一帧,分别都和前一帧用PnP求它的位姿,得到位姿后再和最新一帧三角化得到它们共视点的3D坐标
for (int i = l; i < frame_num - 1 ; i++)
{
Matrix3d R_initial = c_Rotation[i - 1];
Vector3d P_initial = c_Translation[i - 1];
if(!solveFrameByPnP(R_initial, P_initial, i, sfm_f))
return false;
c_Rotation[i] = R_initial;
c_Translation[i] = P_initial;
c_Quat[i] = c_Rotation[i];
Pose[i].block<3, 3>(0, 0) = c_Rotation[i];
Pose[i].block<3, 1>(0, 3) = c_Translation[i];
triangulateTwoFrames(i, Pose[i], frame_num - 1, Pose[frame_num - 1], sfm_f);
}
在这里,我修改了源码的结构,使得逻辑上更通畅一些。triangulateTwoFrames()之前讲过了,现在专门注意solveFrameByPnP()函数。
PnP在《SLAM14讲》的7.7部分,一般来讲,求位姿,2D-2D对极几何只是在第一次使用,也就是没有3D特征点坐标的时候使用,一旦有了特征点,之后都会用3D-2D的方式求位姿。然后会进入PnP求新位姿,然后三角化求新3D坐标的循环中。
solveFrameByPnP()代码逻辑可以分成4部分,
a.第一次筛选:把滑窗的所有特征点中,那些没有3D坐标的点pass掉。
bool GlobalSFM::solveFrameByPnP(Matrix3d &R_initial, Vector3d &P_initial, int i, vector<SFMFeature> &sfm_f)
{
vector<cv::Point2f> pts_2_vector;
vector<cv::Point3f> pts_3_vector;
for (int j = 0; j < feature_num; j++)
{
if (sfm_f[j].state != true)
continue;
b.因为是对当前帧和上一帧进行PnP,所以这些有3D坐标的特征点,不仅得在当前帧被观测到,还得在上一帧被观测到。
Vector2d point2d;
for (int k=0; k < (int)sfm_f[j].observation.size(); k++)
{
if (sfm_f[j].observation[k].first == i)
{
Vector2d img_pts = sfm_f[j].observation[k].second;
cv::Point2f pts_2(img_pts(0), img_pts(1));
pts_2_vector.push_back(pts_2);
cv::Point3f pts_3(sfm_f[j].position[0], sfm_f[j].position[1], sfm_f[j].position[2]);
pts_3_vector.push_back(pts_3);
break;
}
}
}
c.如果这些有3D坐标的特征点,并且在当前帧和上一帧都出现了,数量却少于15,那么整个初始化全部失败。因为它的是层层往上传递。
if (int(pts_2_vector.size()) < 15)
{
printf("unstable features tracking, please slowly move you device!\n");
if (int(pts_2_vector.size()) < 10)
return false;
}
d.套用openCV的公式,进行PnP求解。
cv::Mat r, rvec, t, D, tmp_r;
cv::eigen2cv(R_initial, tmp_r);
cv::Rodrigues(tmp_r, rvec);
cv::eigen2cv(P_initial, t);
cv::Mat K = (cv::Mat_<double>(3, 3) << 1, 0, 0, 0, 1, 0, 0, 0, 1);
bool pnp_succ;
pnp_succ = cv::solvePnP(pts_3_vector, pts_2_vector, K, D, rvec, t, 1);
if(!pnp_succ)
{
return false;
}
cv::Rodrigues(rvec, r);
MatrixXd R_pnp;
cv::cv2eigen(r, R_pnp);
MatrixXd T_pnp;
cv::cv2eigen(t, T_pnp);
R_initial = R_pnp;
P_initial = T_pnp;
return true;
}
(6)从第l+1帧到滑窗的最后的每一帧再与第l帧进行三角化补充3D坐标
现在回到construct()函数,在上一步,求出了l帧后面的每一帧的位姿,也求出了它们相对于最后一帧的共视点的3D坐标,但是这是不够的,现在继续补充3D坐标,那么就和第l帧进行三角化。
for (int i = l + 1; i < frame_num - 1; i++)
triangulateTwoFrames(l, Pose[l], i, Pose[i], sfm_f);
(7)对于在sliding window里在第l帧之前的每一帧,分别都和后一帧用PnP求它的位姿,得到位姿后再和第l帧三角化得到它们共视点的3D坐标
for (int i = l - 1; i >= 0; i--)
{
Matrix3d R_initial = c_Rotation[i + 1];
Vector3d P_initial = c_Translation[i + 1];
if(!solveFrameByPnP(R_initial, P_initial, i, sfm_f))
return false;
c_Rotation[i] = R_initial;
c_Translation[i] = P_initial;
c_Quat[i] = c_Rotation[i];
Pose[i].block<3, 3>(0, 0) = c_Rotation[i];
Pose[i].block<3, 1>(0, 3) = c_Translation[i];
triangulateTwoFrames(i, Pose[i], l, Pose[l], sfm_f);
}
l帧之后的帧都有着落了,现在解决之前的帧。这个过程和(5)完全一样。
(8) 三角化其他未恢复的特征点
至此得到了滑动窗口中所有图像帧的位姿以及特征点的3D坐标。
for (int j = 0; j < feature_num; j++)
{
if (sfm_f[j].state == true)
continue;
if ((int)sfm_f[j].observation.size() >= 2)
{
Vector2d point0, point1;
int frame_0 = sfm_f[j].observation[0].first;
point0 = sfm_f[j].observation[0].second;
int frame_1 = sfm_f[j].observation.back().first;
point1 = sfm_f[j].observation.back().second;
Vector3d point_3d;
triangulatePoint(Pose[frame_0], Pose[frame_1], point0, point1, point_3d);
sfm_f[j].state = true;
sfm_f[j].position[0] = point_3d(0);
sfm_f[j].position[1] = point_3d(1);
sfm_f[j].position[2] = point_3d(2);
}
}
(9)采用ceres进行全局BA
a.声明problem
注意,因为四元数是四维的,但是自由度是3维的,因此需要引入LocalParameterization。
ceres::Problem problem;
ceres::LocalParameterization* local_parameterization = new ceres::QuaternionParameterization();
b.加入待优化量:全局位姿
for (int i = 0; i < frame_num; i++)
{
c_translation[i][0] = c_Translation[i].x();
c_translation[i][1] = c_Translation[i].y();
c_translation[i][2] = c_Translation[i].z();
c_rotation[i][0] = c_Quat[i].w();
c_rotation[i][1] = c_Quat[i].x();
c_rotation[i][2] = c_Quat[i].y();
c_rotation[i][3] = c_Quat[i].z();
problem.AddParameterBlock(c_rotation[i], 4, local_parameterization);
problem.AddParameterBlock(c_translation[i], 3);
在这里,可以发现,仅仅是位姿被优化了,特征点的3D坐标没有被优化!
c.固定先验值
因为l帧是参考系,最新帧的平移也是先验,如果不固定住,原本可观的量会变的不可观。
if (i == l)
{
problem.SetParameterBlockConstant(c_rotation[i]);
}
if (i == l || i == frame_num - 1)
{
problem.SetParameterBlockConstant(c_translation[i]);
}
}
d.加入残差块
这里采用的仍然是最小化重投影误差的方式,所以需要2D-3D信息,注意这块没有加loss function。
for (int i = 0; i < feature_num; i++)
{
if (sfm_f[i].state != true)
continue;
for (int j = 0; j < int(sfm_f[i].observation.size()); j++)
{
int l = sfm_f[i].observation[j].first;
ceres::CostFunction* cost_function = ReprojectionError3D::Create(
sfm_f[i].observation[j].second.x(),
sfm_f[i].observation[j].second.y());
problem.AddResidualBlock(cost_function, NULL, c_rotation[l], c_translation[l],
sfm_f[i].position);
}
}
e.shur消元求解
ceres::Solver::Options options;
options.linear_solver_type = ceres::DENSE_SCHUR;
options.max_solver_time_in_seconds = 0.2;
ceres::Solver::Summary summary;
ceres::Solve(options, &problem, &summary);
if (!(summary.termination_type == ceres::CONVERGENCE && summary.final_cost < 5e-03))
{
return false;
}
这块出现了shur消元知识点,复习一下。shur消元有2大作用,一个是在最小二乘中利用H矩阵稀疏的性质进行加速求解,另一个是在sliding window时求解marg掉老帧后的先验信息矩阵。这块是shur消元的第一个用法。
d.返回特征点l系下3D坐标和优化后的全局位姿
for (int i = 0; i < frame_num; i++)
{
q[i].w() = c_rotation[i][0];
q[i].x() = c_rotation[i][1];
q[i].y() = c_rotation[i][2];
q[i].z() = c_rotation[i][3];
q[i] = q[i].inverse();
}
for (int i = 0; i < frame_num; i++)
{
T[i] = -1 * (q[i] * Vector3d(c_translation[i][0], c_translation[i][1], c_translation[i][2]));
}
for (int i = 0; i < (int)sfm_f.size(); i++)
{
if(sfm_f[i].state)
sfm_tracked_points[sfm_f[i].id] = Vector3d(sfm_f[i].position[0], sfm_f[i].position[1], sfm_f[i].position[2]);
}
return true;
}
优化完成后,需要获得各帧在帧l系下的位姿(也就是各帧到l帧的旋转平移),所以需要inverse操作,然后把特征点在帧l系下的3D坐标传递出来。
至此,construct()函数全部完成!
6.3.5 给滑窗外的图像帧提供初始的RT估计,然后solvePnP进行优化
目的:求出所有帧对应的IMU坐标系bk到l帧的旋转和ck到l帧的平移,和论文中初始化部分头两个公式对应上!
现在再次回到estimator.cpp文件,看下一步流程。在之前的流程里,求出了滑窗内所有帧和对应特征点在l帧下的状态,现在要求出所有帧,也就是滑窗外的,也求解出来。
这部分代码最外层有一个for循环,也就是遍历所有的图像帧:
map<double, ImageFrame>::iterator frame_it;
map<int, Vector3d>::iterator it;
frame_it = all_image_frame.begin( );
for (int i = 0; frame_it != all_image_frame.end( ); frame_it++)
{
cv::Mat r, rvec, t, D, tmp_r;
...
}
TODO 我感到费解的是,这部分为什么没有对i<WINDOW_SIZE+1这个判断呢?
a.边界判断:对于滑窗内的帧,把它们设为关键帧,并获得它们对应的IMU坐标系到l系的旋转平移
if((frame_it->first) == Headers[i].stamp.toSec())
{
frame_it->second.is_key_frame = true;
frame_it->second.R = Q[i].toRotationMatrix() * RIC[0].transpose();
frame_it->second.T = T[i];
i++;
continue;
}
这部分代码虽然看起来简单,实际上有点绕,涉及到的数据结构很多。这里,要注意一下,Headers,Q和T,它们的size都是WINDOW_SIZE+1!它们存储的信息都是滑窗内的,尤其是Q和T,它们都是当前视觉帧到l帧(也是视觉帧)系到旋转平移。
所以一开始,通过时间戳判断是不是滑窗内的帧;
如果是,那么设置为关键帧;
接下来的两行,非常重要,注意一下ImageFrame这个数据结构,见5.2-2,它不仅包括了图像信息,还包括了对应的IMU的位姿信息和IMU预积分信息,而这里,是这些帧第一次获得它们对应的IMU的位姿信息的位置!也就是bk->l帧的旋转平移!
b.边界判断:如果当前帧的时间戳大于滑窗内第i帧的时间戳,那么i++
if((frame_it->first) > Headers[i].stamp.toSec())
i++;
代码好懂,但是不明白为什么这样写?这一部分有点像kmp算法中的2把尺子,一把大一点的尺子是all_image_frame,另一把小尺子是Headers,分别对应着所有帧的长度和滑窗长度;
小尺子固定,大尺子在上面滑动;
每次循环,大尺子滑动一格;
因为小尺子比较靠后,所以开始的时候只有大尺子在动,小尺子不动;
如果大尺子和小尺子刻度一样的时候,小尺子也走一格;
如果大尺子的刻度比小尺子大,小尺子走一格;
但是问题是,我觉得小尺子的刻度,对应在大尺子的最后面!TODO把这一部分注释掉,看看效果!
c.对滑窗外的所有帧,求出它们对应的IMU坐标系到l帧的旋转平移
Matrix3d R_inital = (Q[i].inverse()).toRotationMatrix();
Vector3d P_inital = - R_inital * T[i];
cv::eigen2cv(R_inital, tmp_r);
cv::Rodrigues(tmp_r, rvec);
cv::eigen2cv(P_inital, t);
frame_it->second.is_key_frame = false;
vector<cv::Point3f> pts_3_vector;
vector<cv::Point2f> pts_2_vector;
for (auto &id_pts : frame_it->second.points)
{
int feature_id = id_pts.first;
for (auto &i_p : id_pts.second)
{
it = sfm_tracked_points.find(feature_id);
if(it != sfm_tracked_points.end())
{
Vector3d world_pts = it->second;
cv::Point3f pts_3(world_pts(0), world_pts(1), world_pts(2));
pts_3_vector.push_back(pts_3);
Vector2d img_pts = i_p.second.head<2>();
cv::Point2f pts_2(img_pts(0), img_pts(1));
pts_2_vector.push_back(pts_2);
}
}
}
cv::Mat K = (cv::Mat_<double>(3, 3) << 1, 0, 0, 0, 1, 0, 0, 0, 1);
if(pts_3_vector.size() < 6)
{
cout << "pts_3_vector size " << pts_3_vector.size() << endl;
ROS_DEBUG("Not enough points for solve pnp !");
return false;
}
if (! cv::solvePnP(pts_3_vector, pts_2_vector, K, D, rvec, t, 1))
{
ROS_DEBUG("solve pnp fail!");
return false;
}
cv::Rodrigues(rvec, r);
MatrixXd R_pnp,tmp_R_pnp;
cv::cv2eigen(r, tmp_R_pnp);
R_pnp = tmp_R_pnp.transpose();
MatrixXd T_pnp;
cv::cv2eigen(t, T_pnp);
T_pnp = R_pnp * (-T_pnp);
frame_it->second.R = R_pnp * RIC[0].transpose();
frame_it->second.T = T_pnp;
}
这部分和之前讲的的部分思路一样,唯一需要注意的是最后两行,这块明显是告诉我们传入的是bk->l的旋转平移。
6.3.6 visualInitialAlign() (核心!)
if (visualInitialAlign())
return true;
else
return false;
}
6.4 visualInitialAlign()
基本上,初始化的理论部分都在visualInitialAlign()函数里。
6.4.1计算陀螺仪偏置,尺度,重力加速度和速度
TicToc t_g;
VectorXd x;
if(!VisualIMUAlignment(all_image_frame, Bgs, g, x))
return false;
进去看一下VisualIMUAlignment()的具体内容,它在initial/initial_alignment.h里面。
bool VisualIMUAlignment(map<double, ImageFrame> &all_image_frame, Vector3d* Bgs, Vector3d &g, VectorXd &x)
{
solveGyroscopeBias(all_image_frame, Bgs);
if(LinearAlignment(all_image_frame, g, x))
return true;
else
return false;
}
solveGyroscopeBias()对应在6.1.3部分。
LinearAlignment()对应在6.1.4和6.1.5部分。
6.4.2 传递所有图像帧的位姿Ps、Rs,并将其置为关键帧
for (int i = 0; i <= frame_count; i++)
{
Matrix3d Ri = all_image_frame[Headers[i].stamp.toSec()].R;
Vector3d Pi = all_image_frame[Headers[i].stamp.toSec()].T;
Ps[i] = Pi;
Rs[i] = Ri;
all_image_frame[Headers[i].stamp.toSec()].is_key_frame = true;
}
6.4.3重新计算所有f_manager的特征点深度
VectorXd dep = f_manager.getDepthVector();
for (int i = 0; i < dep.size(); i++)
dep[i] = -1;
f_manager.clearDepth(dep);
Vector3d TIC_TMP[NUM_OF_CAM];
for(int i = 0; i < NUM_OF_CAM; i++)
TIC_TMP[i].setZero();
ric[0] = RIC[0];
f_manager.setRic(ric);
f_manager.triangulate(Ps, &(TIC_TMP[0]), &(RIC[0]));
这里有2个ric,小ric是vins自己计算得到的,大RIC是从yaml读取的,我觉得没什么区别。
这里需要注意一下,这个triangulate()和之前出现的并不是同一个函数。
它是定义在feature_manager.cpp里的,之前的是在initial_sfm.cpp里面。它们服务的对象是不同的数据结构!
6.4.4 IMU的bias改变,重新计算滑窗内的预积分
for (int i = 0; i <= WINDOW_SIZE; i++)
{
pre_integrations[i]->repropagate(Vector3d::Zero(), Bgs[i]);
}
TODO 我觉得这块操作在6.4.1的solveGyroscopeBias()部分重复了,注释掉看看
现在又想了一下,感觉并不是重复了,因为6.4.1是更新完角速度bias后重新算了一下提升了精度,现在再算一下,又提升了一次精度,就算是注释掉,也是注释掉6.4.1里面的那个?试一下。
6.4.5 将Ps、Vs、depth尺度s缩放后从l帧转变为相对于c0帧图像坐标系下
double s = (x.tail<1>())(0);
for (int i = frame_count; i >= 0; i--)
Ps[i] = s * Ps[i] - Rs[i] * TIC[0] - (s * Ps[0] - Rs[0] * TIC[0]);
int kv = -1;
map<double, ImageFrame>::iterator frame_i;
for (frame_i = all_image_frame.begin(); frame_i != all_image_frame.end(); frame_i++)
{
if(frame_i->second.is_key_frame)
{
kv++;
Vs[kv] = frame_i->second.R * x.segment<3>(kv * 3);
}
}
for (auto &it_per_id : f_manager.feature)
{
it_per_id.used_num = it_per_id.feature_per_frame.size();
if (!(it_per_id.used_num >= 2 && it_per_id.start_frame < WINDOW_SIZE - 2))
continue;
it_per_id.estimated_depth *= s;
}
6.4.6 通过将重力旋转到z轴上,得到世界坐标系与摄像机坐标系c0之间的旋转矩阵rot_diff
Matrix3d R0 = Utility::g2R(g);
double yaw = Utility::R2ypr(R0 * Rs[0]).x();
R0 = Utility::ypr2R(Eigen::Vector3d{-yaw, 0, 0}) * R0;
g = R0 * g;
Matrix3d rot_diff = R0;
6.4.7 所有变量从参考坐标系c0旋转到世界坐标系w
for (int i = 0; i <= frame_count; i++)
{
Ps[i] = rot_diff * Ps[i];
Rs[i] = rot_diff * Rs[i];
Vs[i] = rot_diff * Vs[i];
}
return true;
}
至此,初始化的工作全部完成!!
代码量巨长,一半的工作在于视觉SfM(这部分作用仅仅负责求相机pose),另一半才是论文里说的松耦合初始化!在initialStructure()的前半部分里,新建了一组sfm_f这样一批特征点,虽然和f_manager有数据重复,但它们的作用仅仅是用来配合求pose的,而且这个数据结构是建在栈区的,函数结束后统统销毁。而且找l帧这个操作很巧妙。
后半部分,就是论文里的内容。见初始化(理论部分)。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)