数字图像处理课程论文
题目:数字图像识别
摘要
模式识别(PatternRecognition)是一项借助计算机,就人类对外部世界某一特定环境中的客体、过程和现象的识别功能(包括视觉、听觉、触觉、判断等)进行自动模拟的科学技术,也是指对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是信息科学和人工智能的重要组成部分。
本文针对手写数字图像识别问题,采用了图像预处理与k近邻算法进行识别。本文的图像训练集约有2000张数字0~9的手写数字图片,测试集共有约1000张数字0~9的手写数字图片。
在预处理阶段,使用matlab软件进行操作。首先通过大小变换将训练集、测试集所有图片统一转化为32像素*32像素大小的图像,然后对图像进行中值滤波,滤出噪声。对去噪后的图像进行二值化处理,将所有图像转化为只包含0或1的矩阵。并用文本文件存储,为文本文件进行科学的命名。
在k近邻算法中,采用欧氏距离度量图像间距离大小。采用多数表决法进行分类判别。通过比较不同的k值影响,发现当k=3时对本文采用的数据集具有最好的识别结果,946张测试集图片中仅识别错误11张图片,正确率高达98.84%。在运算速度方面,平均识别出一个数字只需0.037秒。对此结果进行科学的推算,预计从一个汽车车牌号中识别出所有数字与字母需约0.79秒。具有速度较快、精确率高、易于实现的特点。
关键词:K近邻法 中值滤波 二值化图像 手写数字图像识别
一、问题重述
随着当今社会的日新月异及信息化进程的快速发展,我们如今正被数字化时代笼罩着,数字正朝着庖代我们对话语和文字的语言表达、记忆的方向进展。对于生活中的数字,人脑可以快速地识别出是哪个数字,但是计算机不能直接直观地识别出数字。因此,需利用数字图像处理与机器学习相关知识让计算机识别出图像里的字符。
二、问题分析
从现实中获取的图像大小不一、包含大量与分类器无关的多余信息,且存在一定噪声等,故需对图像进行预处理。在进行识别之前,需将图像统一为大小相同、适合分类器操作的形式。
机器学习分为有监督学习与无监督学习两种,其可以完成分类、回归等功能。对于识别手写数字图像,我们应采用有监督学习来完成分类判决。有监督学习方法在图像识别中主要有基于决策理论方法的识别,如k近邻法、决策树等,基于概率理论方法的识别,如贝叶斯分类器等。本文采用基于决策理论方法的k近邻法对图像进行识别。
三、模型建立
3.1 图像预处理
数据预处理包括统一大小、进行二值化处理、数字滤波进行平滑去噪处理及规范化处理等。
3.1.1 图像大小变换
输入图像大小不一,需将每张图片统一为32像素*32像素大小的图像。
3.2.2 中值滤波
图像中往往因现实因素含有一定噪声,故采用中值滤波器对图像进行滤波,以使图像可以更加正确地被二值化处理。
中值滤波法是一种非线性平滑技术,它将每一像素点的灰度值设置为该点某邻域窗口内的所有像素点灰度值的中值。
中值滤波是基于排序统计理论的一种能有效抑制噪声的非线性信号处理技术,中值滤波的基本原理是把数字图像或数字序列中一点的值用该点的一个邻域中各点值的中值代替,让周围的像素值接近的真实值,从而消除孤立的噪声点。方法是用某种结构的二维滑动模板,将板内像素按照像素值的大小进行排序,生成单调上升(或下降)的为二维数据序列。二维中值滤波输出为g(x,y)=med{f(x-k,y-l),(k,l∈W)},其中,f(x,y),g(x,y)分别为原始图像和处理后图像。W为二维模板,通常为3*3,5*5区域,也可以是不同的的形状,如线状,圆形,十字形,圆环形等。
3.2.3 二值化处理
对于数字的识别数据获取可以有很多方法,输入的彩色图像包含大量颜色信息,会占用较多的存储空间,且处理时也会降低系统的执行速度,因此对图像进行识别等处理时,常将彩色图像转换为灰度图像,以加快处理速度。输入图像为黑底白字的手写数字图像。为了更加便利的开展图像处理操作,需要对图像做一个二值化处理。设置一个阈值threshold,将灰度图中值大于threshold的像素点置为1,小于等于threshold的像素点置为0,完成二值化处理。
3.2 k近邻法
k近邻法使用的模型实际上对应于特征空间的划分。模型由三个基本要素——距离度量、k值选择和分类决策规则决定。
3.2.1 模型简介
k近邻法中,当训练集、距离度量(如欧氏距离)、k值及分类决策规则(如多数表决)确定后,对于任何一个新的输入实例,它所属的类唯一地确定。这相当于根据上述要素将特征空间划分为一些子空间,确定子空间里的每个点所属的类。这一事实要从最近邻算法中可以看得很清楚。
特征空间中,对每个训练实例点xi,距离该点比其他点更近的所有点组成一个区域,叫做单元。每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分。最近邻法将实例xi的类yi作为其单元中所有点的类标记。这样,每个单元的实例点的类别是确定的。
3.2.2 距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映。k近邻模型的特征空间一般是n维实数向量空间Rn。
设特征空间X是n维实数向量空间Rn,xi,xj∈X,xi=(xi(1),xi(2),...,xi(n))T,xj=(xj(1),xj(2),...,xj(n))T,xi,xj的Lp距离定义为
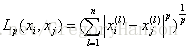
这里p≥1.当p=2时,称为欧氏距离,即
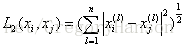
当p=1时,称为曼哈顿距离,即

当p=∞时,它是各个坐标距离的最大值,即

在本文中,选取欧氏距离作为距离度量。
3.2.3 分类决策规则
k近邻法中的分类决策规则往往是多数表决,即由输入实例的k个临近的训练实例中的多数表决决定输入实例的类。
多数表决规则有如下解释:如果分类的损失函数为0-1损失函数,分类函数为
f:Rn→{c1,c2,...,ck}
那么误分类的概率为
P(Y≠f(X))=1−P(Y=f(X))
对于给定的实例x∈χ, 其最近邻的k个训练实例点构成集合Nk(x). 如果涵盖Nk(x) 的区域的类别cj, 那么误分类率是
1k∑xi∈Nk(x)I(yi≠cj)=1−1k∑xi∈Nk(x)I(yi=cj)
要使误分类率最小即经验风险最小,就要使∑xi∈Nk(x)I(yi=cj) 最大。所以多数表决制对应于经验风险最小化。
四、模型求解
4.1 图像预处理
matlab可以快速、有效的对图像进行预处理,其自带的imresize、rgb2gray等函数可以有效的完成大小变换、灰度图转换等功能,故图像预处理部分采用matlab软件进行处理。
4.1.1 收集数据
下载约3000张符合要求的不重复的手写数字图片。其中0~9十个数字各约300张。每个数字的300张图片中,随机选择约200张作为训练集,100张作为测试集。
以数字‘0’为例,图一至图三展示数字0训练集188张图片中的前3张。

图一数字‘0’在训练集中的第一张图

图二数字‘0’在训练集中的第二张图

图三数字‘0’在训练集中的第三张图
4.1.2 准备数据
(1)中值滤波
用matlab批量读取图像,对图像进行中值滤波。以数字0在训练集中的第一幅图为例,结果如图四所示。
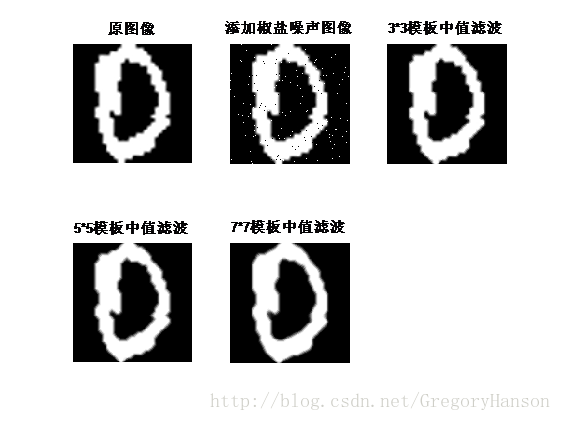
图四含有椒盐噪声的数字图像中值滤波结果
由结果可见,中值滤波在手写数字图像中可以有效的消除椒盐噪声,方便图像进行进一步处理,其中3*3模板下的中值滤波效果最好,故本文采用3*3模板的中值滤波进行图像滤波的预处理。
(2)二值化处理
将滤波后的图像转化为灰度图。经实验验证,将阈值threshold设为128的时候,可以完成正确的图像二值化处理。将处理后的图像以二进制文本文件存储。
以图一展示的手写数字图片为例,图五为存储图一的二进制文本文件。

图五 存储图一的手写数字图片的二进制文本文件
4.1.3 分析数据
读取在准备数据阶段存储的二进制文本并进行图像显示,确保符合要求。
4.2 k近邻法
Python语言非常适用于数据处理、机器学习等方面的操作。NumPy是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多。其运算速度与matlab不相上下的同时,具有更强的可移植性。故在此采用Python语言与它的科学计算包NumPy完成程序。
测试集中共有946个测试手写数字的数字图像处理后的文本文件。取k值为3时,程序返回部分结果如图六:
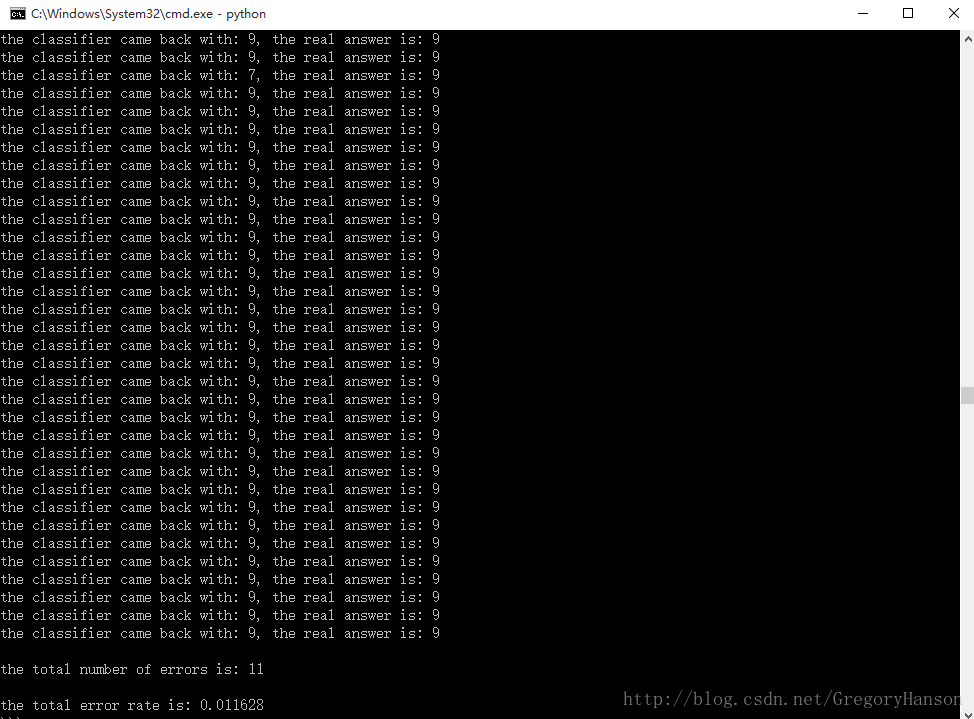
图六 k=3时测试集测试部分结果
由图可见,对于大多数手写数字的图像,k近邻法分类器均能返回正确的结果。在946个测试集中,判断错误的图像只有11个,错误率约为1.16%。由此可见,k近邻法对于进行预处理后的手写数字图像的识别具有较高的识别正确率。
五、结果分析
5.1 图像预处理部分分析
中值滤波法对消除椒盐噪声非常有效,在光学测量条纹图象的相位分析处理方法中有特殊作用,但在条纹中心分析方法中作用不大。本文中3*3模板下的中值滤波可以较好地完成去噪声功能。
中值滤波在图像处理中,常用于保护边缘信息,是经典的平滑噪声的方法。
5.2 k近邻算法部分分析
现研究k值,即多数表决规则中训练集里得分最高的参与表决的训练样本数量,对测试结果的影响。现分别取k为1到10的整数,进行观察分析比较,结果如表一:
表一 相同训练集测试集,不同k值下的识别结果比较
| K值 | 1 | 2 | 3 | 4 | 5 |
| 测试集错误数量 | 13 | 13 | 11 | 14 | 17 |
| 错误率 | 1.37% | 1.37% | 1.16% | 1.48% | 1.80% |
| K值 | 6 | 7 | 8 | 9 | 10 |
| 测试集错误数量 | 19 | 21 | 21 | 22 | 20 |
| 错误率 | 2.01% | 2.22% | 2.22% | 2.33% | 2.11% |
为了更直观的分析,将测试结果绘制成图七:

图七 不同k值下的测试判断错误关系
由图表所示的实验结果可见,k值在k近邻法分类器中对结果存在着一定的影响,且并非k值越大越好或越小越好。当k值较小时,如k=1时,k近邻又叫最近邻法,此时更易受训练集中某一个意外的巧合下发生错误的训练数据影响。当k值较大时,结果易受一些符合度相对较小的训练集中的结果影响。因此,应取k值为一个偏小的、且又不是非常小的数。如本例中,k取3时结果最佳。
本例中,k近邻法通过约2000组训练集判断约1000组数据,共需约37秒。平均判断出一个数字需要0.037秒。即一秒钟约能识别出27个手写数字图像中的数字。若训练集中不止包含手写数字,还包含字母,按照此训练集规模来计算,则需要一个约7200组数据文件的训练集。若将此方法应用在识别汽车牌照上的数字与字母(共6位),理论计算识别出一个车牌上的所有英文与字母需约6*(26+10)/10*0.037=0.79秒。此速度对应约98.7%的识别正确率尚能接受。但仍然在速度上可以改进。在实现算法时,可采用构造kd树等方法,可以加快模型判决速度,在此不赘述。
六、评价与改进
k近邻算法是分类数据最简单最有效的算法。它是基于实例的学习,使用算法时必须有接近实际数据的训练样本数据。k近邻算法必须保存全部数据集,如果训练数据集很大,必须使用大量的存储空间。此外,必须对数据集中的每个数据计算距离值,实际使用时可能会非常耗时。通过上文实验结果与计算,识别出一个车牌上的所有字母、数字需要约0.79秒。在算法实现上,可通过构建kd树来加快k近邻法的判决速度。
k近邻算法的另一个缺点是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均实例样本和典型实例样本具有什么特征。对此,我们可以尝试用概率测量方法处理分类问题,如朴素贝叶斯等。然而,在实际应用过程中,繁琐的系统分部密度求取经常给人们带来很多的不方便,且很多时候,参数或概率密度函数未知,因此贝叶斯分类器经常无法广泛使用,相比之下,非参数模式识别分类方法如k近邻算法的适用范围更广。
七、参考文献
[1]. 刘玲丽,基于PCA变换和k近邻法的印刷体数字图像识别.计算机光盘软件与应用,2013(08):第137+139页.
[2]. 韦根原与沈桐,基于最小距离法和近邻法的数字图像识别.仪器仪表用户,2012(05):第53-55页.
[3]. 张旭等,基于朴素贝叶斯K近邻的快速图像分类算法.北京航空航天大学学报,2015(02):第302-310页.
[4]. 王楠,一种基于K近邻的图像去噪方法.软件导刊,2015(10): 第155-157页.
[5] 李航,《统计学习方法》,清华大学出版社,2012。
[6] Peter Harrington,《机器学习实战》,人民邮电出版社,2013。
[7] (美)冈萨雷斯(Gonzalez.R.C.) . (美)伍兹 (Woods.R.E.),《数字图像处理(第三版)》,电子工业出版社,2011。
[8] 姚敏,《数字图像处理(第二版)》,机械工业出版社,2012。
八、附录
8.1 图像预处理代码(matlab)
clear;clc; %清空变量
I=imread('0_0.txt');
% 中值滤波
J= imnoise(I,'salt & pepper',0.02);%添加椒盐噪声
k1=medfilt2(J); %进行3*3模板中值滤波
k2=medfilt2(J,[5 5]); %进行5*5模板中值滤波
k3=medfilt2(J,[7 7]); %进行7*7模板中值滤波
figure,subplot(231),imshow(I);title('原图像'); %以下均为显示图像
subplot(2,3,2),imshow(J);title('添加椒盐噪声图像');
subplot(2,3,3),imshow(k1);title('3*3模板中值滤波');
subplot(2,3,4),imshow(k2);title('5*5模板中值滤波');
subplot(2,3,5),imshow(k3);title('7*7模板中值滤波');
% 二值化处理
picSize=size(k1); %读取图片大小
throeshold=128; %设置阈值大小
for i=1:picSize(1) %二值化处理
for j=1:picSize(2)
if k1(i,j)>128
k1(i,j)=1;
else
k1(i,j)=0;
end
end
end
8.2 k近邻法判决器代码(python)
# 导入numpy库为矩阵运算等做准备,listdir库为读取文件等做准备
from numpyimport *
importoperator
from osimport listdir
# 判决器函数,在手写数字识别函数中被调用,输入分别为测试数据、训练数据、标签、k近邻算法的k值。输出返回值为判决器判决的数字结果。
defclassify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) -dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) # 欧式距离
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() # 对训练结果中的欧式距
# 离大小排序
classCount={}
for i in range(k): # 由距离最小的k个点通过多数表决法判别出结果
voteIlabel =labels[sortedDistIndicies[i]]
classCount[voteIlabel] =classCount.get(voteIlabel,0) + 1
sortedClassCount =sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 该函数将图像转化成程序中的矩阵变量
defimg2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32): # 经过预处理,读取图像大小均为
lineStr = fr.readline() # 32像素*32像素,依次读取这1024
for j in range(32): # 像素点
returnVect[0,32*i+j] =int(lineStr[j])
return returnVect
# 手写数字识别函数(运行时运行此函数即可得出结果)
# 训练集与测试集中文件命名方法为a_b.txt,a为该文件存储的数字,b为
# 该数字下的文件编号,如:2_4.txt代表存储数字‘2’的第四个文件
defhandwritingClassTest(k):
hwLabels = []
trainingFileList = listdir('trainingDigits') # 加载训练集中的文件
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #去掉文件名中的.txt
classNumStr =int(fileStr.split('_')[0]) # 从文件名中提取该文件
hwLabels.append(classNumStr) # 代表数字的正确答案
trainingMat[i,:] =img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') # 测试集的迭代器准备
errorCount = 0.0 # 记录错误个数
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] # 去掉文件名中的.txt,
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest =img2vector('testDigits/%s' % fileNameStr)
classifierResult =classify0(vectorUnderTest, trainingMat, hwLabels, k) # 调用k近邻法的分类器函数,进行判决
print ("the classifier came back with:%d, the real answer is: %d" % (classifierResult, classNumStr)) # 输出结果
if (classifierResult != classNumStr):errorCount += 1.0
print ("\nthe total number of errorsis: %d" % errorCount)
print ("\nthe total error rate is:%f" % (errorCount/float(mTest)))
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)