面试官:你知道C语言的结构体对齐吗?
应聘者:听说过……平时很少关注
……
面试官:好吧,那回去等通知吧
C语言结构体对齐问题,是面试必备问题。
本文,除了用图解的方式讲清楚结构体知识点外,还将为你解答以下问题:
-
为什么会有结构体内存对齐?
-
结构体怎么对齐?
-
学习结构体对齐有什么用?
-
结构体对齐有没有实际应用?
▍结构体内存对齐的原因
一句话,为了提高效率,这个跟芯片设计有关。
自从我们刚学习编程开始,就会接触到例如字、双字、四字等概念这里涉及到内存边界问题,它们的地址分别是可被2/4/8整除的。另外,在汇编中,不同长度的内存访问会用到不同的汇编指令。
如果,一块内存在地址上随便放的,CPU有可能就会用到多条指令来访问,这就会降低效率。
对于32位系统,如下图的A可能需要2条指令访问,而B只需1条指令。

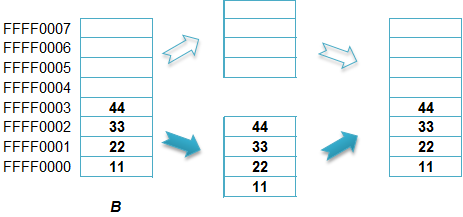
▍结构体内存对齐的规则
1. C语言基本类型的大小
不要瞎猜,直接上代码。每个平台都不一样,请读者自行测试,以下我是基于Windows上MinGW的GCC测的。
#define BASE_TYPE_SIZE(t) printf("%12s : %2d Byte%s\n", #t, sizeof(t), (sizeof(t))>1?"s":"")void base_type_size(void){ BASE_TYPE_SIZE(void); BASE_TYPE_SIZE(char); BASE_TYPE_SIZE(short); BASE_TYPE_SIZE(int); BASE_TYPE_SIZE(long); BASE_TYPE_SIZE(long long); BASE_TYPE_SIZE(float); BASE_TYPE_SIZE(double); BASE_TYPE_SIZE(long double); BASE_TYPE_SIZE(void*); BASE_TYPE_SIZE(char*); BASE_TYPE_SIZE(int*); typedef struct { }StructNull; BASE_TYPE_SIZE(StructNull); BASE_TYPE_SIZE(StructNull*);}
结果是:
void : 1 Byte char : 1 Byte short : 2 Bytes int : 4 Bytes long : 4 Bytes long long : 8 Bytes float : 4 Bytes double : 8 Bytes long double : 12 Bytes void* : 4 Bytes char* : 4 Bytes int* : 4 Bytes StructNull : 0 Byte StructNull* : 4 Bytes
这些内容不用记住,不同平台是不一样的,使用之前,一定要亲自测试验证下,但是可以总结出以下信息:
-
void类型不是空的,占一个字节
-
long不一定比int大
-
C语言空结构体的大小为0(注意:C++的为1)
-
不管什么类型,指针都是相同大小的
2. C语言结构体的内存对齐
我先看个例子:
#define offset(type, member) (size_t)&(((type *)0)->member)
#define STRUCT_E_ADDR(s,e) printf("%5s size = %2d %16s addr: %p\n", #s, sizeof(s), #s"."#e, &s.e)
#define STRUCT_E_OFFSET(s,e) printf("%5s size = %2d %16s offset: %2d\n", #s, sizeof(s), #s"."#e, offset(__typeof__(s),e))
#define STRUCT_E_ADDR_OFFSET(s,e) printf("%5s size = %2d %16s addr: %p, offset: %2d\n", #s, sizeof(s), #s"."#e, &s.e, offset(__typeof__(s),e))
typedef struct
{
int e_int;
char e_char;
}S1;
S1 s1;
STRUCT_E_ADDR_OFFSET(s1, e_int);
STRUCT_E_ADDR_OFFSET(s1, e_char);
typedef struct
{
int e_int;
double e_double;
}S11;
S11 s11;
STRUCT_E_ADDR_OFFSET(s11, e_int);
STRUCT_E_ADDR_OFFSET(s11, e_double);
咦……这宏定义是啥意思?传送门:《基于C99规范,最全C语言预处理知识总结》
输出结果:
s1 size = 8 s1.e_int addr: 0028FF28, offset: 0 s1 size = 8 s1.e_char addr: 0028FF2C, offset: 4 s11 size = 16 s11.e_int addr: 0028FF18, offset: 0 s11 size = 16 s11.e_double addr: 0028FF20, offset: 8
结论1:一般情况下,结构体所占的内存大小并非元素本身大小之和。
结论2:不严谨地,结构体内存的大小按最大元素大小对齐。
继续看例子:
typedef struct { int e_int; long double e_ld; }S12;
typedef struct { long long e_ll; long double e_ld; }S13;
typedef struct { char e_char; long double e_ld; }S14;
S12 s12; S13 s13; S14 s14; STRUCT_E_ADDR_OFFSET(s12, e_int); STRUCT_E_ADDR_OFFSET(s12, e_ld); STRUCT_E_ADDR_OFFSET(s13, e_ll); STRUCT_E_ADDR_OFFSET(s13, e_ld); STRUCT_E_ADDR_OFFSET(s14, e_char); STRUCT_E_ADDR_OFFSET(s14, e_ld);
输出结果:
s12 size = 16 s12.e_int addr: 0028FF08, offset: 0 s12 size = 16 s12.e_ld addr: 0028FF0C, offset: 4 s13 size = 24 s13.e_ll addr: 0028FEF0, offset: 0 s13 size = 24 s13.e_ld addr: 0028FEF8, offset: 8 s14 size = 16 s14.e_char addr: 0028FEE0, offset: 0 s14 size = 16 s14.e_ld addr: 0028FEE4, offset: 4
出现问题了,你看s12和s14,sizeof(long long)应该是12,按结论而推断sizeof(s12)和sizeof(s13)应该都是24。
这里跟平台和编译器的一个模数有关。
对结论2修正:结构体内存大小应按最大元素大小对齐,如果最大元素大小超过模数,应按模数大小对齐。
额外再送一条结论:如果结构体的最大元素大小超过模数,结构体的起始地址是可以被模数整除的。如果,最大元素大小没有超过模数大小,那它的起始地址是可以被最大元素大小整除。
那么,这个模数是什么?
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。
网上流传一个表:
| 平台 | 长度/模数 | char | short | int | long | float | double | long long | long double |
| Win-32 | 长度 | 1 | 2 | 4 | 4 | 4 | 8 | 8 | 8 |
| 模数 | 1 | 2 | 4 | 4 | 4 | 8 | 8 | 8 |
| Linux-32 | 长度 | 1 | 2 | 4 | 4 | 4 | 8 | 8 | 12 |
| 模数 | 1 | 2 | 4 | 4 | 4 | 4 | 4 | 4 |
| Linux-64 | 长度 | 1 | 2 | 4 | 8 | 4 | 8 | 8 | 16 |
| 模数 | 1 | 2 | 4 | 8 | 4 | 8 | 8 | 16 |
本文的的例子我用的是MinGW32的GCC来测试,你猜符合上表的哪一项?
别急,再看一个例子:
typedef struct { int e_int; double e_double; }S11; S11 s11; STRUCT_E_ADDR_OFFSET(s11, e_int); STRUCT_E_ADDR_OFFSET(s11, e_double);
结果是:
s11 size = 16 s11.e_int addr: 0028FF18, offset: 0 s11 size = 16 s11.e_double addr: 0028FF20, offset: 8
很明显,上表没有一项完全对应得上的。简单汇总以下我测试的结果:
| 长度/模数 | char | short | int | long | float | double | long long | long double |
| 长度 | 1 | 2 | 4 | 4 | 4 | 8 | 8 | 12 |
| 模数 | 1 | 2 | 4 | 4 | 4 | 8 | 8 | 8 |
所以,再强调一下:因为环境的差异,在你参考使用之前,请自行测试一下。
另外,提一下:这个模数是可以改变的,可以用预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
例如
#pragma pack(1)typedef struct { char e_char; long double e_ld;}S14;#pragma pack()
#pragma是啥玩意?有兴趣可以看看:《基于C99规范,最全C语言预处理知识总结》
好了,我们继续,这似乎没啥技术含量,我们提升下难度:
typedef struct { int e_int; char e_char1; char e_char2; }S2;
typedef struct { char e_char1; int e_int; char e_char2; }S3; S2 s2; S3 s3;
你觉得这俩结构体所占内存是一样大吗?那你就错了:
s2 size = 8 s2.e_int addr: 0028FED4, offset: 0 s2 size = 8 s2.e_char1 addr: 0028FED8, offset: 4 s2 size = 8 s2.e_char2 addr: 0028FED9, offset: 5 s3 size = 12 s3.e_char1 addr: 0028FEC4, offset: 0 s3 size = 12 s3.e_int addr: 0028FEC8, offset: 4 s3 size = 12 s3.e_char2 addr: 0028FECC, offset: 8
why?
上个图先看看,它们内存是怎么对齐的:
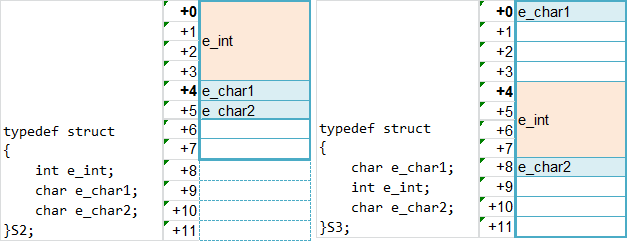
我们套一遍那几条结论就可以知道:
理解按最大元素大小或模数对齐,就可以看到S2的内存分布;
对于S3,e_int的位置地址,肯定是要按int的大小对齐的(地址可被int大小整除),这样才能提高访问效率。同时,这导致了很大的内存浪费。
以上例子,我们看到挨在一起的两个char会放在同一个对齐单元,如果挨在一起的short和char会不会放一起?
typedef struct { char e_char1; short e_short; char e_char2; int e_int; char e_char3; }S4; S4 s4; STRUCT_E_ADDR_OFFSET(s4, e_char1); STRUCT_E_ADDR_OFFSET(s4, e_short); STRUCT_E_ADDR_OFFSET(s4, e_char2); STRUCT_E_ADDR_OFFSET(s4, e_int); STRUCT_E_ADDR_OFFSET(s4, e_char3);
输出结果:
s4 size = 16 s4.e_char1 addr: 0028FEB4, offset: 0 s4 size = 16 s4.e_short addr: 0028FEB6, offset: 2 s4 size = 16 s4.e_char2 addr: 0028FEB8, offset: 4 s4 size = 16 s4.e_int addr: 0028FEBC, offset: 8 s4 size = 16 s4.e_char3 addr: 0028FEC0, offset: 12

得出一个经验:
我们在定义结构体的时候,尽量把大小相同或相近的元素放一起,以减少结构体占用的内存空间。
再来一个问题:
结构体套着另一个结构体怎么计算?
typedef struct
{
int e_int;
char e_char;
}S1;
typedef struct
{
S1 e_s;
char e_char;
}SS1;
typedef struct
{
short e_short;
char e_char;
}S6;
typedef struct
{
S6 e_s;
char e_char;
}SS2;
SS1 ss1;
STRUCT_E_ADDR_OFFSET(ss1, e_s);
STRUCT_E_ADDR_OFFSET(ss1, e_char);
SS2 ss2;
STRUCT_E_ADDR_OFFSET(ss2, e_s);
STRUCT_E_ADDR_OFFSET(ss2, e_char);
输出结果:
ss1 size = 12 ss1.e_s addr: 0028FE94, offset: 0 ss1 size = 12 ss1.e_char addr: 0028FE9C, offset: 8 ss2 size = 6 ss2.e_s addr: 0028FE8E, offset: 0 ss2 size = 6 ss2.e_char addr: 0028FE92, offset: 4

得出结论:结构体内的结构体,结构体内的元素并不会和结构体外的元素合并占一个对齐单元。
温馨提示:大家不要刻意去记这些结论,动手去试试并思考下效果会更好。
3. 联合体union的内存对齐
直接上代码:
typedef union
{
char e_char;
int e_int;
}U1;
U1 u1;
STRUCT_E_ADDR(u1, e_char);
STRUCT_E_ADDR(u1, e_int);
输出结果:
u1 size = 4 u1.e_char addr: 0028FF2C u1 size = 4 u1.e_int addr: 0028FF2C
从教科书上,我都可以理解,联合体里面的元素,实际上共享同一个空间。

那么,union跟struct结合呢?
typedef struct
{
int e_int1;
union
{
char ue_chars[9];
int ue_int;
}u;
double e_double;
int e_int2;
}SU2;
SU2 su2;
STRUCT_E_ADDR_OFFSET(su2, e_int1);
STRUCT_E_ADDR_OFFSET(su2, u.ue_chars);
STRUCT_E_ADDR_OFFSET(su2, u.ue_int);
STRUCT_E_ADDR_OFFSET(su2, e_double);
STRUCT_E_ADDR_OFFSET(su2, e_int2)
输出:
su2 size = 32 su2.e_int1 addr: 0028FEF8, offset: 0 su2 size = 32 su2.u.ue_chars addr: 0028FEFC, offset: 4 su2 size = 32 su2.u.ue_int addr: 0028FEFC, offset: 4 su2 size = 32 su2.e_double addr: 0028FF08, offset: 16 su2 size = 32 su2.e_int2 addr: 0028FF10, offset: 24

实际上跟结构体类似,也没有特别的规则。
顺便提一下,使用union时,要留意平台的大小端问题。
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
百度百科——大小端模式
怎么获知自己使用的平台的大小端?Linux有个方法
static union {
char c[4];
unsigned long l;
} endian_test = { { 'l', '?', '?', 'b' } };
#define ENDIANNESS ((char)endian_test.l)
printf("ENDIANNESS: %c\n", ENDIANNESS);
4. 位域(Bitfield)的相关
位域在本文没什么好探讨的,在结构体对齐方面没什么特别的地方。
直接看个测试代码,就可以明白:
void bitfield_type_size(void)
{
typedef struct
{
char bf1:1;
char bf2:1;
char bf3:1;
char bf4:3;
}SB1;
typedef struct
{
char bf1:1;
char bf2:1;
char bf3:1;
char bf4:7;
}SB2;
typedef struct
{
char bf1:1;
char bf2:1;
char bf3:1;
int bfint:1;
}SB3;
typedef struct
{
char bf1:1;
char bf2:1;
int bfint:1;
char bf3:1;
}SB4;
SB1 sb1;
SB2 sb2;
SB3 sb3;
SB4 sb4;
VAR_ADDR(sb1);
VAR_ADDR(sb2);
VAR_ADDR(sb3);
VAR_ADDR(sb4);
typedef struct
{
unsigned char bf1:1;
unsigned char bf2:1;
unsigned char bf3:1;
unsigned char bf4:3;
}SB11;
typedef union
{
SB11 sb1;
unsigned char e_char;
}UB1;
UB1 ub1;
STRUCT_E_ADDR_OFFSET(ub1, sb1);
STRUCT_E_ADDR_OFFSET(ub1, e_char);
ub1.e_char = 0xF5;
BITFIELD_VAL(ub1, e_char);
BITFIELD_VAL(ub1, sb1.bf1);
BITFIELD_VAL(ub1, sb1.bf2);
BITFIELD_VAL(ub1, sb1.bf3);
BITFIELD_VAL(ub1, sb1.bf4);
}
输出结果是:
sb1 size = 1 sb1 addr: 0028FF2F sb2 size = 2 sb2 addr: 0028FF2D sb3 size = 8 sb3 addr: 0028FF24 sb4 size = 12 sb4 addr: 0028FF18 ub1 size = 1 ub1.sb1 addr: 0028FF17, offset: 0 ub1 size = 1 ub1.e_char addr: 0028FF17, offset: 0 ub1 : 1 Byte, ub1.e_char=0xF5 ub1 : 1 Byte, ub1.sb1.bf1=0x1 ub1 : 1 Byte, ub1.sb1.bf2=0x0 ub1 : 1 Byte, ub1.sb1.bf3=0x1 ub1 : 1 Byte, ub1.sb1.bf4=0x6
有几个点需要注意下:
-
内存的计算单位是byte,不是bit
-
结构体内即使有bitfield元素,其对齐规则还是按照基本类型来
-
bitfield元素不能获得其地址(即程序中不能通过&取址)
5. 规则总结
首先,不推荐记忆这些条条框框的文字,以下内容仅供参考:
-
结构体的内存大小,并非其内部元素大小之和;
-
结构体变量的起始地址,可以被最大元素基本类型大小或者模数整除;
-
结构体的内存对齐,按照其内部最大元素基本类型或者模数大小对齐;
-
模数在不同平台值不一样,也可通过#pragma pack(n)方式去改变;
-
如果空间地址允许,结构体内部元素会拼凑一起放在同一个对齐空间;
-
结构体内有结构体变量元素,其结构体并非展开后再对齐;
-
union和bitfield变量也遵循结构体内存对齐原则。
▍编程为什么要关注结构体内存对齐
也许你会问,结构体爱怎么对齐就怎么对齐,我管它干嘛!
1. 节省内存
在嵌入式软件开发中,特别是内存资源匮乏的小MCU,这个尤为重要。如果优化程序内存,使得MCU可以选更小的型号,对于大批量出货的产品,可以带来更高利润。
也许你还还感觉不到,上段代码:
typedef struct
{
int e_int;
char e_char1;
char e_char2;
}S2;
typedef struct
{
char e_char1;
int e_int;
char e_char2;
}S3;
S2 s2[1024] = {0};
S3 s3[1024] = {0};
s2的大小为8K,而s3的大小为12K,一放大,就有很明显的区别了。
2. union的内存对齐需要
对于同一个内存,有时为了满足不同的访问形式,定义一个联合体变量,或者一个结构体和联合体组合的变量。此时就要知道其内存结构是怎么分布的。
3. 内存拷贝
有时候,我们在通信数据接收处理时候,往往遇到,数组和结构体的搭配。
即,通信时候,通常使用数组参数形式接收,而处理的时候,按照预定义格式去访问处理。例如:
U8 comm_data[10];
typedef struct
{
U8 id;
U16 len;
U8 data[6];
}FRAME;
FRAME* pFram = (FRAME*)comm_data;
此处,必须要理解这个FRAM的内存结构是怎么样的对齐规则。
4. 调试仿真时看压栈数据
在调试某些奇葩问题时,迫不得已,我们会研究函数跳转或者线程切换时的栈数据,遇到结构体内容,肯定要懂得其内存对齐方式才能更好地获得栈内信息。
当然,还有其他方面的原因,在此就不一一列举了。
▍结构体内存对齐实际应用
上面一个章节已经部分讲到这个结构体内存对齐的应用了,例如通信数据的处理等。另外,再举两个例子:
1. 内存的mapping
假设你要做一个烧录文件,你想往文件头空间128个字节内放一段项目信息(例如程序大小、CRC校验码、其他项目信息等)。第一反应,你会考虑用一个结构体,定义一段这样的数据,程序运行的时候也定义同样的结构体去读取这个内存。但是你需要知道结构体大小啊,这个结构体内存对齐的规则还是需要了解的。
2. 单片机寄存器的mapping
在写MCU驱动的时候,访问寄存器的方式有很多种,但是做到清晰明了,适配性好的,往往需要诸多考量。
直接通过整型指针指到特定地址去访问,是没有问题的,但是对于某一类型的寄存器,往往不是一个固定地址,其后面还有一堆子寄存器属性需要配置。每个地址都通过整型指针访问,那就很多很凌乱。
我们可以通过定义一个特定的结构体,用其指针直接mapping到寄存器的base地址。但是遇到有些地址是空的怎么办?甚至有些寄存器是32位的,有些16位,甚至8位的,各种参差不齐都在里面。
那就要考虑结构体内存对齐了,特别是结构体内有不同类型的元素。

这里只探讨应用场景,具体实现还要根据实际情况来定义。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)