补充一句
只是做深度学习跑模型的话,装完驱动后就可以了,不需要额外按照NVIDIA官网的教程配置CUDA和CUDNN!!
我们的代码实际用到的是python环境下的包。比如我用anaconda配置环境,直接在python环境下安装pytorch cudatoolkit就好了。
目前网上的教程提到配环境,几乎都是装完驱动再装cuda和cudnn,实际上后面两个步骤对AI研究者来说,并不必要!
直接在anaconda里配置环境就好了!
按照官网教程安装pytoch cudatoolkit等,cudnn 已经内置在pytorch 中。
conda list
cudatoolkit 11.3.1 h2bc3f7f_2 defaults
pytorch 1.10.0 py3.7_cuda11.3_cudnn8.2.0_0 file:///home/xiu/Downloads/packages
使用 PyTorch 查看 CUDA 和 cuDNN 版本:
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
conda安装pytorch后没有找到cudnn
安装CUDA,自动安装驱动
网上一大堆通过runfile来安装的范例,但个人尝试后all not work,最后通过官网教程得以成功安装,并意外发现直接安装cuda是会自动安装显卡驱动的!!(deb文件会自动安装,网上其他案例里选择runflie的话好像是可以选择是否要安装驱动)
以下是一些成功安装的经历。
直接从官网找对应的CUDA Toolkit,点击进行下载。
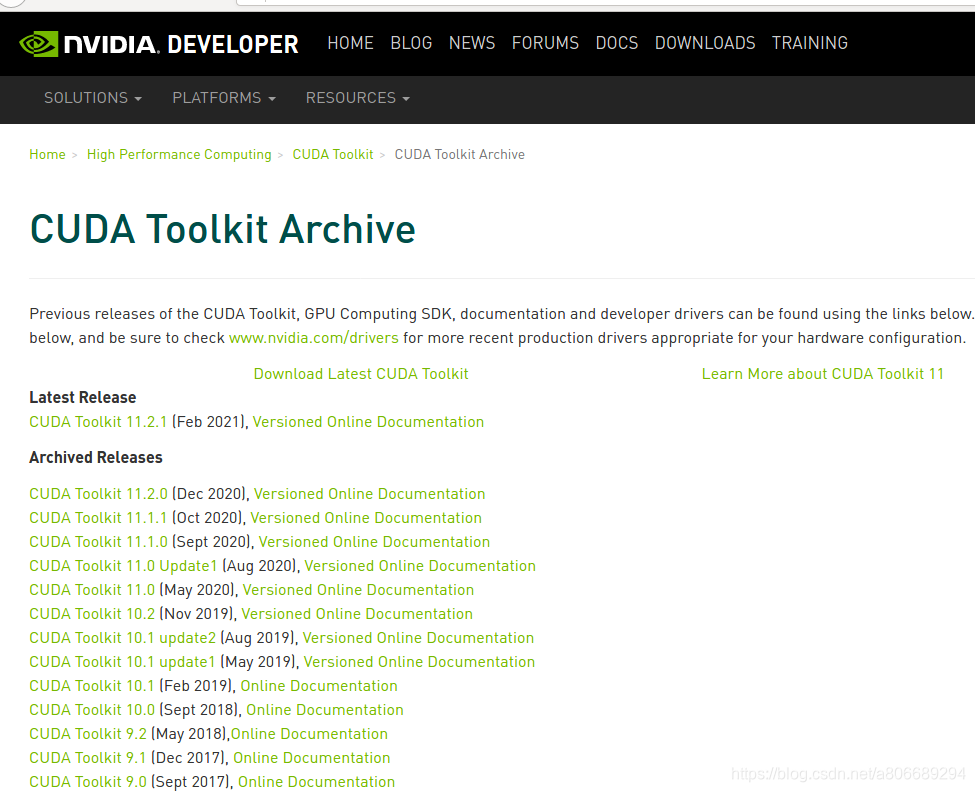
根据自己电脑配置对应选择,安装类型我选择了deb(local)。按照官方给出的指令进行下载。

按照官方给出的指令执行后,在安装过程中自动安装了对应的显卡驱动!!!早知道就不折腾上网找驱动的安装教程了,直接安装cuda,自动安装驱动的方式不好吗!!
(
安装NVIDIA驱动教程,试了一圈都没用:
https://tensorflow-notes.readthedocs.io/zh_CN/latest/nv-driver.html
Ubuntu16.04下安装cuda和cudnn的三种方法(亲测全部有效
)
安装完成后reboot,独显可以正常显示了!!
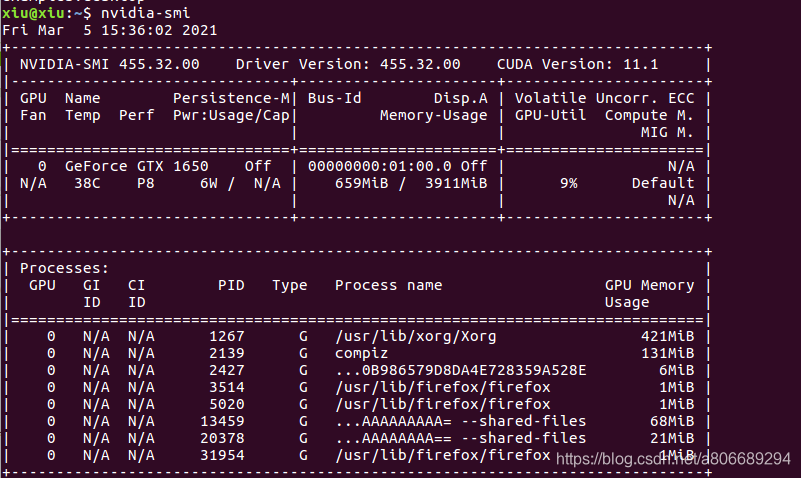
内心沸腾!!!
nvcc -V不显示问题
但此时输入 nvcc -V显示没用安装,
xiu@xiu:~$ nvcc -V
The program 'nvcc' is currently not installed. You can install it by typing:
sudo apt install nvidia-cuda-toolkit
网上搜索,原来是环境变量没有设置,
打开~/.bashrc ,添加环境变量export PATH=$PATH:/usr/local/cuda/bin
重新执行nvcc -V,输出显示cuda版本为11.1.
(参考:解决nvcc找不到的问题)
xiu@xiu:~$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Mon_Oct_12_20:09:46_PDT_2020
Cuda compilation tools, release 11.1, V11.1.105
Build cuda_11.1.TC455_06.29190527_0
大功告成!
安装cudnn
参考:
cuDNN的安装(版本选择, Runtime 还是 Developer)
Ubuntu16.04下安装cuda和cudnn的三种方法(亲测全部有效
官方教程
官方下载地址:https://developer.nvidia.com/rdp/cudnn-archive
文件选择cuDNN Library for Linux 即可。
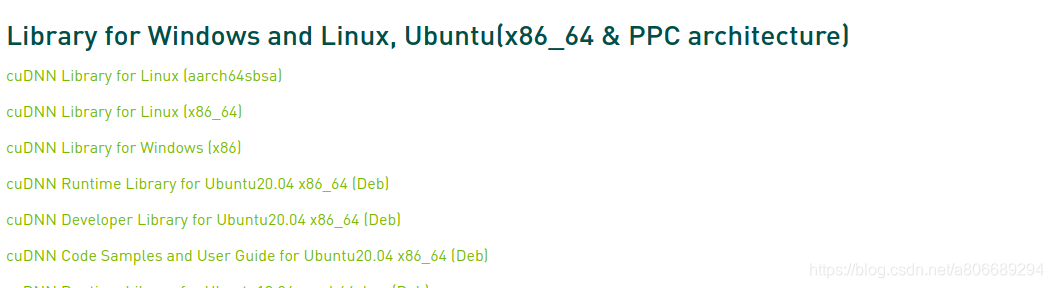
安装cudnn:
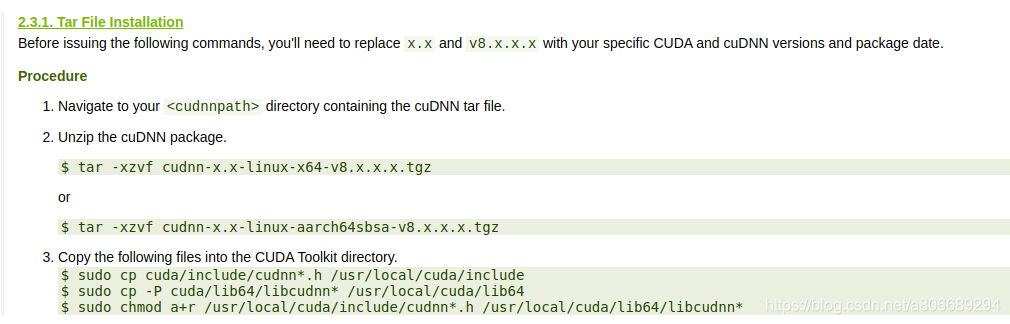
sudo cp cuda/include/cudnn*.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
查看cudnn版本:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)