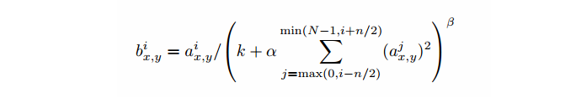文章目录
一、归一化的含义 二、归一化的作用 三、归一化的类型 1、线性归一化 2、零-均值规范化(z-score标准化 3、小数定标规范化 4、非线性归一化 四、归一化理解 1、归一化能提高求解最优解速度 2、3D 图解未归一化 五、局部响应归一化 六、批归一化(BatchNormalization) 1、引入 2、BN算法的优点 3、批归一化(BN)算法流程
数据归一化是深度学习数据预处理非常关键的步骤,可以起到统一量纲,防止小数据被吞噬等作用。
归一化 :把所有数据都转化为[0,1]或者[-1,1]之间的数,其目的是取消各维数据间数量级差别,避免因为输入输出数据数量级差别较大而造成网络预测误差较大。
归一化的具体作用是归纳统一样本的统计分布性。归一化在
0
−
1
0-1
0 − 1
归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,且 sigmoid 函数的取值是 0 到 1 之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。
归一化是统一在
0
−
1
0-1
0 − 1
1、为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。 2、为了程序运行时收敛加快。 3、同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。 4、避免神经元饱和。什么意思?就是当神经元的激活在接近 0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近 0,这会有效地“杀死” 梯度。 5、保证输出数据中数值小的不被吞食。
1、线性归一化
也称为最小-最大规范化 、离散标准化 ,是对原始数据的线性变换,将数据值映射到
[
0
,
1
]
[0, 1]
[ 0 , 1 ]
x
′
=
x
−
m
i
n
(
x
)
m
a
x
(
x
)
−
m
i
n
(
x
)
x'=\frac{x-min(x)}{max(x)-min(x)}
x ′ = m a x ( x ) − m i n ( x ) x − m i n ( x )
离差标准化保留了原来数据中存在的关系,是消除量纲和数据取值范围影响的最简单方法。
适用范围 :比较适用在数值比较集中的情况。
缺点 :
1)如果 max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。如遇到超过目前属性
[
m
i
n
,
m
a
x
]
[min,max]
[ m i n , m a x ] 2)如果数值集中且某个数值很大,则规范化后各值接近于0,并且将会相差不大。(如 1, 1.2, 1.3, 1.4, 1.5, 1.6,10)这组数据。 2、零-均值规范化(z-score标准化
零-均值规范化也称标准差标准化,经过处理的数据的均值为0,标准差为1。转化公式为:
x
′
=
x
−
μ
δ
x'=\frac{x-\mu}{\delta}
x ′ = δ x − μ
其中
μ
\mu
μ
δ
\delta
δ
标准差分数可以回答这样一个问题:"给定数据距离其均值多少个标准差"的问题,在均值之上的数据会得到一个正的标准化分数,反之会得到一个负的标准化分数。
3、小数定标规范化
通过移动属性值的小数位数,将属性值映射到[-1, 1]之间,移动的小数位数取决于属性值绝对值的最大值。转化公式为:
x
′
=
x
1
0
k
x'=\frac{x}{10^k}
x ′ = 1 0 k x
4、非线性归一化
该方法包括 log、指数,正切等。
适用范围 :经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函 数,将原始值进行映射。
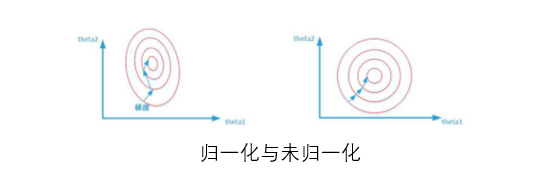
1、归一化能提高求解最优解速度
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆, 在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收 敛甚至不能收敛。
2、3D 图解未归一化
例子:
假设
w
1
w_1
w 1
[
−
10
,
10
]
[-10,10]
[ − 1 0 , 1 0 ]
w
2
w_2
w 2
[
−
100
,
100
]
[-100,100]
[ − 1 0 0 , 1 0 0 ]
w
1
w_1
w 1
1
/
20
1/20
1 / 2 0
w
2
w_2
w 2
w
2
w_2
w 2
w
1
w_1
w 1
w
2
w_2
w 2
这样会导致,在搜索过程中更偏向于
w
1
w_1
w 1
局部响应归一化LRN 是一种提高深度学习准确度的技术方法。LRN 一般是在激活、池化函数后的一种方法。该方法是由AlexNet网络提出,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN层模仿了生物神经系统的“侧抑制”机制,对局部神经元的活动创建竞争环境,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强模型的泛化能力。
LRN对于ReLU这种没有上限边界的激活函数会比较有用,因为它会从附近的多个卷积核的响应中挑选比较大的反馈,但不适合Sigmoid之中有固定边界并且能抑制过大值的激活函数。
公式如下:
a:表示卷积层(包括卷积操作和池化操作)后的输出结果,是一个四维数组[batch,height,width,channel]。
batch:批次数(每一批为一张图片)。
b
x
,
y
i
b_{x,y}^i
b x , y i
a
x
,
y
i
a_{x,y}^i
a x , y i
该层还需要参数:
n: 临近的feature map 数目,用于表示局部区域的大小,注意,这里的区域指的是一维区域,区别于图像中某像素点的临近像素。 N:通道(featrure map)总数(这里的通道不是图像的通道,而是指不同的kernal生成的featuremap) α : 缩放因子 β :指数项 ∑:∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着 a 中的第 3 维 channel 方向的,也就是一个点同方向的前面
n
/
2
n/2
n / 2
n
/
2
n/2
n / 2
d
−
1
d-1
d − 1
n
+
1
n+1
n + 1
d
d
d 例如:
i
=
10
,
N
=
96
,
n
=
4
i = 10, N= 96, n = 4
i = 1 0 , N = 9 6 , n = 4
x
,
y
x,y
x , y
a
a
a
x
,
y
x,y
x , y
tesorflow代码 :
import tensorflow as tf
import numpy as np
x = np.array([i for i in range(1,33)]).reshape([2,2,2,4])
y = tf.nn.lrn(input=x,depth_radius=2,bias=0,alpha=1,beta=1)
with tf.Session() as sess:
print(x)
print('#############')
print(y.eval())
运行结果如下:
26
/
(
0
+
1
∗
(
2
5
2
+
2
6
2
+
2
7
2
+
2
8
2
)
)
1
26/(0+1*(25^2+26^2+27^2+28^2))^1
2 6 / ( 0 + 1 ∗ ( 2 5 2 + 2 6 2 + 2 7 2 + 2 8 2 ) ) 1
1、引入
以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过
δ
\delta
δ
这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化 Batch Normalization(BN)。
2、BN算法的优点
a) 减少了人为选择参数。在某些情况下可以取消 dropout 和 L2 正则项参数,或者采取更小的 L2 正则项约束参数; b)减少了对学习率的要求。现在我们可以使用初始很大的学习率或者选择了较小的学习率,算法也能够快速训练收敛; c)可以不再使用局部响应归一化。BN 本身就是归一化网络(局部响应归一化在 AlexNet 网络中存在) d)破坏原来的数据分布,一定程度上缓解过拟合(防止每批训练中某一个样本经常被挑选到,文献说这个可以提高 1%的精度); e)减少梯度消失,加快收敛速度,提高训练精度。 3、批归一化(BN)算法流程
输入 :上一层输出结果
X
=
{
x
1
,
x
2
,
…
,
x
m
}
X=\{x_1,x_2,…,x_m\}
X = { x 1 , x 2 , … , x m }
γ
\gamma
γ
β
\beta
β
算法流程 :
(1)计算上一层输出数据的均值:
μ
β
=
1
m
∑
i
=
1
m
x
i
\mu_{\beta}=\frac{1}{m}\sum_{i=1}^{m}x_i
μ β = m 1 i = 1 ∑ m x i
其中,m 是此次训练样本 batch 的大小。
(2)计算上一层输出数据的标准差:
δ
β
2
=
1
m
∑
i
=
1
m
(
x
i
−
μ
β
)
2
\delta_{\beta}^2=\frac{1}{m}\sum_{i=1}^m(x_i-\mu_{\beta})^2
δ β 2 = m 1 i = 1 ∑ m ( x i − μ β ) 2
(3)归一化处理,得到:
x
i
^
=
x
i
+
μ
β
δ
β
2
+
ε
\hat{x_i}=\frac{x_i+\mu_{\beta}}{\sqrt{\delta_\beta^2}+\varepsilon }
x i ^ = δ β 2
+ ε x i + μ β
其中
ε
\varepsilon
ε
(4)重构,对经过上面归一化处理得到的数据进行重构,得到 :
y
i
=
γ
x
i
^
+
β
y_i=\gamma\hat{x_i}+\beta
y i = γ x i ^ + β
其中,
γ
\gamma
γ
β
\beta
β
注:上述是 BN 训练时的过程,但是当在投入使用时,往往只是输入一个样本,没有所谓的均值
μ
β
\mu_\beta
μ β
δ
β
2
\delta_\beta^2
δ β 2
μ
β
\mu_\beta
μ β
μ
β
\mu_\beta
μ β
δ
β
2
\delta_\beta^2
δ β 2
δ
β
2
\delta_\beta^2
δ β 2
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)