DDPG算法的tensorflow2.0实现
算法的详细解析可以看DDPG解析
import tensorflow as tf
import numpy as np
import pandas as pd
import gym
from matplotlib import pyplot as plt
import os
SEED = 65535
ENV = gym.make('Pendulum-v1')
action_dim = ENV.action_space.shape[0]
observation_dim = ENV.observation_space.shape[0]
action_span = ENV.action_space.high
class DDPG:
def __init__(self,
n_features,
n_actions_dim,
gamma=0.9,
mode='train',
update_param_n=1,
actor_learning_rate=0.001,
critic_learning_rate=0.001,
soft_tau=0.1,
explore_span=3,
learning_rate=0.001,
experience_pool_size=1000,
batch_size=64,
):
np.random.seed(SEED)
tf.random.set_seed(SEED)
self.gamma = gamma
self.explore_span = explore_span
self.n_features = n_features
self.n_actions_dim = n_actions_dim
self.actor_learning_rate = actor_learning_rate
self.critic_learning_rate = critic_learning_rate
self.learning_rate = learning_rate
self.soft_tau = soft_tau
self.learn_time = 0
self.update_param_n = update_param_n
self.mode = mode
self.critic_pred_model = self.critic_init(critic_trainable=True, name='pred')
self.critic_target_model = self.critic_init(critic_trainable=False, name='target')
self.critic_param_replace()
self.actor_pred_model = self.actor_init(actor_trainable=True, name='pred')
self.actor_target_model = self.actor_init(actor_trainable=False, name='target')
self.actor_param_replace()
self.opt = tf.keras.optimizers.Adam(self.learning_rate)
self.experience_pool_size = experience_pool_size
self.experience_length = self.n_features * 2 + self.n_actions_dim + 1 + 1
self.experience_pool_is_full = False
self.experience_pool_can_learn = False
self.experience_pool = pd.DataFrame(np.zeros([self.experience_pool_size, self.experience_length]))
self.experience_pool_index = 0
self.batch_size = batch_size
def experience_pool_store(self, s, a, r, s_, done):
"""
存储经验
:param s: 状态
:param a: 动作
:param r: 回报
:param s_: 下一个状态
:param done: 是否完成游戏
:return:
"""
experience = []
for i in range(self.experience_length):
if i < self.n_features:
experience.append(s[i])
elif self.n_features <= i < self.n_features + self.n_actions_dim:
experience.append(a[i - self.n_features])
elif self.n_features + 1 <= i < self.n_features + self.n_actions_dim + 1:
experience.append(r)
elif self.n_features + 2 <= i < self.n_features * 2 + self.n_actions_dim + 1:
experience.append(s_[i - self.n_features - self.n_actions_dim - 1])
else:
experience.append(done)
self.experience_pool.loc[self.experience_pool_index] = experience
self.experience_pool_index += 1
if self.experience_pool_index >= self.batch_size:
self.experience_pool_can_learn = True
if self.experience_pool_index == self.experience_pool_size:
self.experience_pool_is_full = True
self.experience_pool_index = 0
def critic_init(self, critic_trainable, name):
"""
critic 网络定义,s,a 输入,Q(s,a)输出。这里与AC网络不同,AC网络输出的是V(s)
:param name: 网络名称
:param critic_trainable: 是否可以被训练,target网络是不能被训练的,设置False,预测网络设置为True
:return: critic 网络模型
"""
input_s = tf.keras.Input(shape=(self.n_features,))
input_a = tf.keras.Input(shape=(self.n_actions_dim,))
inputs = tf.concat([input_s, input_a], axis=-1)
dense1 = tf.keras.layers.Dense(32, activation='relu')(inputs)
out_put = tf.keras.layers.Dense(1)(dense1)
critic_model = tf.keras.Model(inputs=[input_s, input_a],
outputs=out_put,
trainable=critic_trainable,
name='critic_' + name)
return critic_model
def actor_init(self, actor_trainable, name):
"""
actor 网络定义,输入s,输出动作a
:param name: 网络名称
:param actor_trainable: 是否可以被训练,target网络是不能被训练的,设置False,预测网络设置为True
:return: actor 网络模型
"""
input_s = tf.keras.Input(shape=(self.n_features,))
dense1 = tf.keras.layers.Dense(32, activation='relu')(input_s)
out_put = tf.keras.layers.Dense(1, activation='tanh')(dense1)
out_put = tf.keras.layers.Lambda(lambda x: x * np.array(action_span))(out_put)
actor_model = tf.keras.Model(inputs=input_s, outputs=out_put, trainable=actor_trainable, name='actor_' + name)
return actor_model
def choose_action(self, s):
s = s.reshape(1, self.n_features)
a = self.actor_pred_model.predict(np.array(s))
if self.mode == 'train':
action = np.clip(np.random.normal(a[0], self.explore_span), -action_span, action_span)
return action
elif self.mode == 'test':
return a[0]
def DDPG_learn(self):
"""
在这里进行两个网络的更新
:return:
"""
if not self.experience_pool_can_learn:
return
elif not self.experience_pool_is_full:
data_pool = self.experience_pool.loc[:self.experience_pool_index - 1, :].sample(self.batch_size)
else:
data_pool = self.experience_pool.sample(self.batch_size)
exp_s = np.array(data_pool.loc[:, :self.n_features - 1])
exp_a = np.array(data_pool.loc[:, self.n_features - 1 + self.n_actions_dim]).reshape(self.batch_size, 1)
exp_r = np.array(data_pool.loc[:, self.n_features - 1 + self.n_actions_dim + 1]).reshape(self.batch_size, 1)
exp_s_ = np.array(
data_pool.loc[:, self.n_features + self.n_actions_dim + 1:self.n_features * 2 + self.n_actions_dim])
exp_done = np.array(data_pool.loc[:, self.n_features * 2 + self.n_actions_dim + 1]).reshape(self.batch_size, 1)
with tf.GradientTape() as Tape:
a = self.actor_pred_model(exp_s)
Q_pred = self.critic_pred_model([exp_s, a])
loss_actor = - tf.reduce_mean(Q_pred)
actor_gradients = Tape.gradient(loss_actor, self.actor_pred_model.trainable_variables)
self.opt.apply_gradients(zip(actor_gradients, self.actor_pred_model.trainable_variables))
with tf.GradientTape() as Tape:
a_ = self.actor_target_model(exp_s_)
Q_pred_critic = self.critic_pred_model([exp_s, exp_a])
Q_target_critic = exp_r + self.gamma * self.critic_target_model([exp_s_, a_])
loss_critic = tf.keras.losses.mse(Q_target_critic, Q_pred_critic)
critic_gradients = Tape.gradient(loss_critic, self.critic_pred_model.trainable_variables)
self.opt.apply_gradients(zip(critic_gradients, self.critic_pred_model.trainable_variables))
self.learn_time += 1
if self.learn_time == self.update_param_n:
self.soft_param_update(self.critic_target_model, self.critic_pred_model)
self.soft_param_update(self.actor_target_model, self.actor_pred_model)
self.learn_time = 0
def soft_param_update(self, target_model, pred_model):
"""
采用软更新的方式进行参数的更新,不采用DQN中的直接赋值操作,也可以采用别的软更新方式来实现。
:param pred_model: 预测网络
:param target_model: 目标网络
"""
param_target = target_model.get_weights()
param_pred = pred_model.get_weights()
for i in range(len(param_target)):
param_target[i] = param_target[i] * (1 - self.soft_tau)
param_pred[i] = param_pred[i] * self.soft_tau
param = np.add(param_pred, param_target)
target_model.set_weights(param)
def critic_param_replace(self):
"""
替换critic网络的参数
"""
self.critic_target_model.set_weights(self.critic_pred_model.get_weights())
def actor_param_replace(self):
"""
替换actor网络的参数
"""
self.actor_target_model.set_weights(self.actor_pred_model.get_weights())
def save_model(self, episode):
"""
save trained weights
:return: None
"""
if not os.path.exists('model'):
os.makedirs('model')
self.actor_pred_model.save(f'model/ddpg_actor_pred_model_{episode}_episode.h5')
self.actor_target_model.save(f'model/ddpg_actor_target_model_{episode}_episode.h5')
self.critic_pred_model.save(f'model/ddpg_critic_pred_model_{episode}_episode.h5')
self.critic_target_model.save(f'model/ddpg_critic_target_model_{episode}_episode.h5')
def load_model(self, episode):
"""
load trained weights
:return: None
"""
self.actor_pred_model = tf.keras.models.load_model(f'model/ddpg_actor_pred_model_{episode}_episode.h5')
self.actor_target_model = tf.keras.models.load_model(f'model/ddpg_actor_target_model_{episode}_episode.h5')
self.critic_pred_model = tf.keras.models.load_model(f'model/ddpg_critic_pred_model_{episode}_episode.h5')
self.critic_target_model = tf.keras.models.load_model(f'model/ddpg_critic_target_model_{episode}_episode.h5')
def DDPG_train(episode=300):
DDPG_agent = DDPG(n_features=observation_dim,
n_actions_dim=action_dim,
batch_size=64,
mode='train',
experience_pool_size=640)
ENV.seed(SEED)
score = []
if not os.path.exists('img'):
os.makedirs('img')
for i_episode in range(episode):
observation = ENV.reset()
score_one_episode = 0
for t in range(500):
ENV.render()
action = DDPG_agent.choose_action(observation)
observation_, reward, done, info = ENV.step(action)
DDPG_agent.experience_pool_store(s=observation, a=action, r=reward, s_=observation_, done=done)
DDPG_agent.DDPG_learn()
observation = observation_
score_one_episode += reward
if done:
score.append(score_one_episode)
print(f"the game is finished,episode is {i_episode}, the score is {score_one_episode}")
break
if (i_episode + 1) % 100 == 0:
plt.plot(score)
DDPG_agent.explore_span = DDPG_agent.explore_span / 2
DDPG_agent.save_model(i_episode + 1)
plt.savefig(
f"img/DDPG_score_train_episode:{i_episode + 1}.png")
def DDPG_test(episode=300):
DDPG_agent = DDPG(n_features=observation_dim,
n_actions_dim=action_dim,
batch_size=64,
mode='test',
experience_pool_size=640)
DDPG_agent.load_model(episode=300)
ENV.seed(SEED)
score = []
for i_episode in range(episode):
observation = ENV.reset()
score_one_episode = 0
for t in range(500):
ENV.render()
action = DDPG_agent.choose_action(observation)
observation_, reward, done, info = ENV.step(action)
observation = observation_
score_one_episode += reward
if done:
score.append(score_one_episode)
print(f"the game is finished,episode is {i_episode}, the score is {score_one_episode}")
break
if (i_episode + 1) % 100 == 0:
plt.plot(score)
DDPG_agent.save_model(i_episode + 1)
plt.savefig(
f"img/DDPG_score_test:{i_episode + 1}.png")
if __name__ == '__main__':
DDPG_train(episode=300)
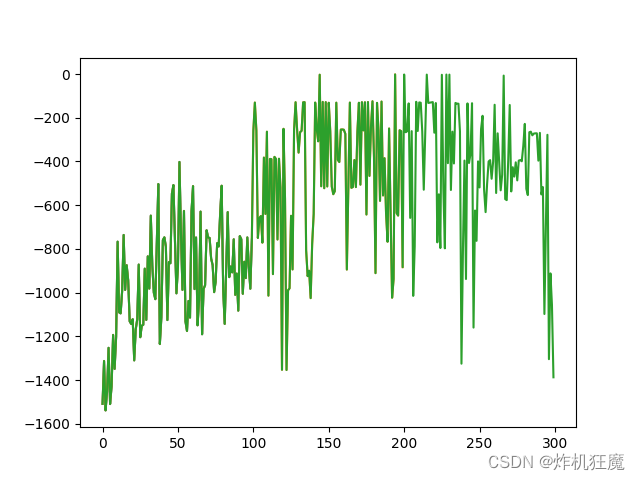
训练结果如下:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)