文章目录
- 1. 语法更正
- 2. 文本翻译
- 3. 语言转换
- 4. 代码解释
- 5. 修复代码错误
- 6. 作为百科全书
- 7. 信息提取
- 8. 好友聊天
- 9. 创意生成器
- 10. 采访问题
- 11. 论文大纲
- 12. 故事创作
- 13. 问题类比
- 14. 创建 SQL 需求
- 15. 情感分析
- 16. 将产品描述转变为广告
- 17. 关键字提取
- 18. 闲聊机器人
- 总结
**来自:**CSDN,**作者:**ㄣ知冷煖★
原文链接:
https://blog.csdn.net/weixin_42475060/article/details/129399125
**版权声明:**本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。你确定,你会使用 ChatGPT 了吗?
今天给大家整理了 18 种 ChatGPT 的用法,看看有哪些方法是你能得上的。
- \1. 语法更正
- \2. 文本翻译
- \3. 语言转换
- \4. 代码解释
- \5. 修复代码错误
- \6. 作为百科全书
- \7. 信息提取
- \8. 好友聊天
- \9. 创意生成器
- \10. 采访问题
- \11. 论文大纲
- \12. 故事创作
- \13. 问题类比
- \14. 创建 SQL 需求
- \15. 情感分析
- \16. 将产品描述转变为广告
- \17. 关键字提取
- \18. 闲聊机器人
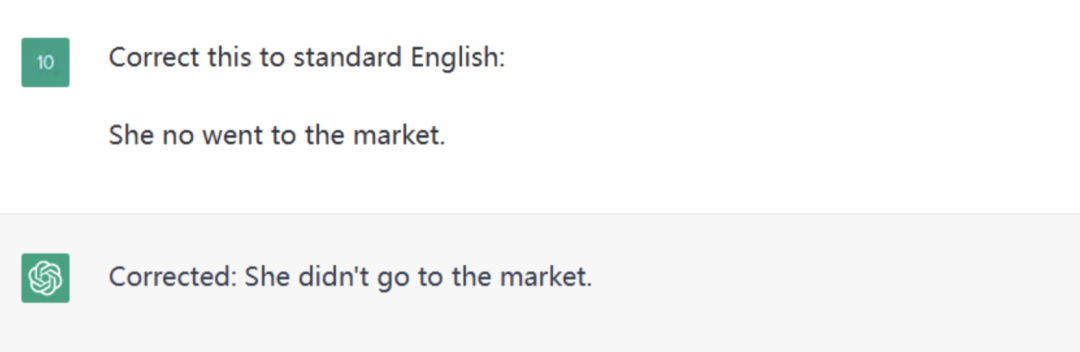
1. 语法更正
用途:文章、论文等润色。
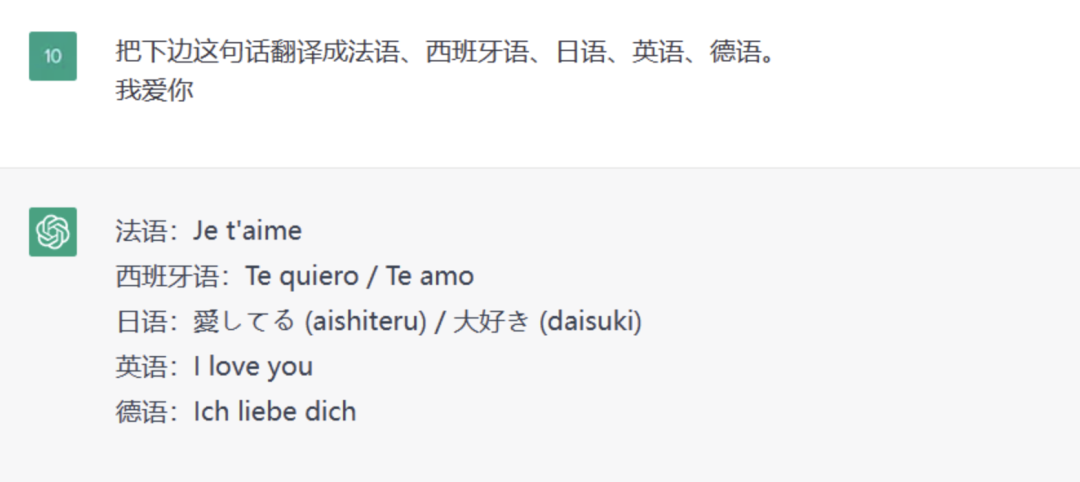
2. 文本翻译
用途:日常学习、商务翻译等。
3. 语言转换
Python–>JAVA
用途:工作用途,不同语言工程师之间的合作,更加方便。
import numpy as np
import plotly.express as px
def thresholding_algo(y, lag, threshold):
"""
:param y: 输入列表
:param lag: 滑动窗口大小
:param threshold: 调节系数,用于调节容忍范围的大小。
:return:
"""
# signals:信号列表
signals = np.zeros(len(y))
avgFilter = np.zeros(len(y))
# 初始化平均值列表、差值列表
avgFilter[lag - 1] = np.mean(y[0:lag])
dif_li = [0] * len(y)
for i in range(lag, len(y)):
if i < len(y) - lag - 30:
for j in range(i + 11, len(y)):
if y[j] >= y[i - 1]:
break
if j >= len(y) - 30:
back = y[i - 1]
else:
back = np.mean(y[j + 11:j + 20 + lag])
else:
back = y[i - 1]
# 前后均值差值计算
tmp = abs(back - avgFilter[i - 1])
dif = (tmp if tmp > 1 else 1)
if abs(y[i] - avgFilter[i - 1]) > dif * threshold:
signals[i] = (1 if y[i] > avgFilter[i - 1] else -1)
avgFilter[i] = np.mean(y[(i - lag):i])
y[i] = avgFilter[i - 1]
else:
signals[i] = 0
avgFilter[i] = np.mean(y[(i - lag):i])
dif_li[i] = dif
return dict(signals=np.asarray(signals),
avgFilter=np.asarray(avgFilter),
y=np.asarray(y),
dif=np.asarray(dif_li),
)
public static Map<String, double[]> thresholding_algo(double[] y, int lag, double threshold) {
double[] signals = new double[y.length];
double[] avgFilter = new double[y.length];
Arrays.fill(avgFilter, 0.0);
avgFilter[lag - 1] = mean(Arrays.copyOfRange(y, 0, lag));
double[] dif_li = new double[y.length];
Arrays.fill(dif_li, 0.0);
for (int i = lag; i < y.length; i++) {
int j;
if (i < y.length - lag - 30) {
for (j = i + 11; j < y.length; j++) {
if (y[j] >= y[i - 1]) {
break;
}
}
double back;
if (j >= y.length - 30) {
back = y[i - 1];
} else {
back = mean(Arrays.copyOfRange(y, j + 11, j + 20 + lag));
}
} else {
back = y[i - 1];
}
double tmp = Math.abs(back - avgFilter[i - 1]);
double dif = tmp > 1 ? tmp : 1;
if (Math.abs(y[i] - avgFilter[i - 1]) > dif * threshold) {
signals[i] = y[i] > avgFilter[i - 1] ? 1 : -1;
avgFilter[i] = mean(Arrays.copyOfRange(y, i - lag, i));
y[i] = avgFilter[i - 1];
} else {
signals[i] = 0;
avgFilter[i] = mean(Arrays.copyOfRange(y, i - lag, i));
}
dif_li[i] = dif;
}
Map<String, double[]> result = new HashMap<>();
result.put("signals", signals);
result.put("avgFilter", avgFilter);
result.put("y", y);
result.put("dif", dif_li);
return result;
}
private static double mean(double[] array) {
double sum = 0.0;
for (double d : array) {
sum += d;
}
return sum / array.length;
}
4. 代码解释
用途:当我们来到一家新的公司,发现前任工程师留下了一摊谁都看不懂的代码,这时候,如果有个人能帮我们解释一下这些代码是什么意思,那简直不要太开心。

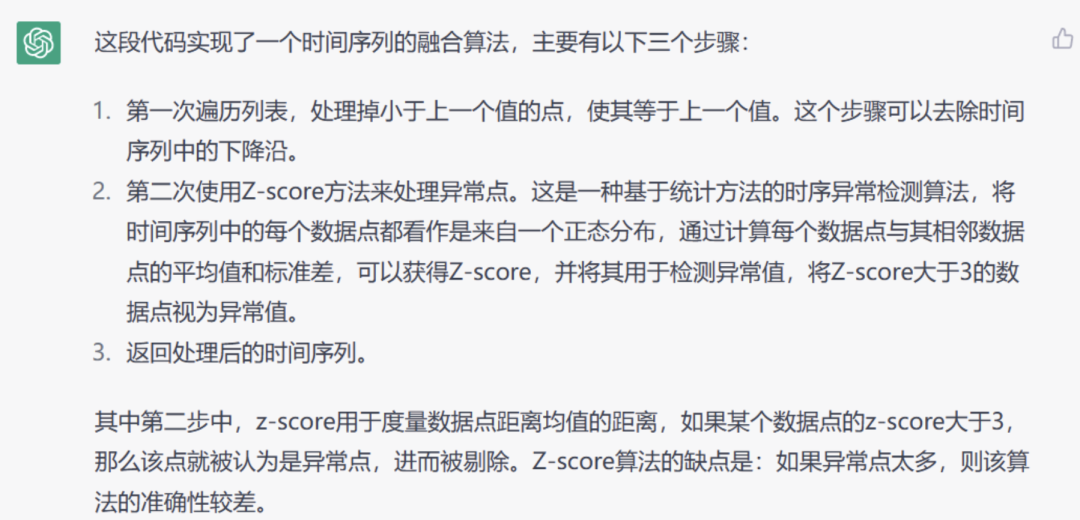
def Fusion_algorithm(y_list):
"""
最终的融合算法
1、第一次遍历列表: 处理掉小于上一个值的点,使其等于上一个值。
2、第二次使用z-score来处理异常点:一种基于统计方法的时序异常检测算法借鉴了一些经典的统计方法,比如Z-score和移动平均线
该算法将时间序列中的每个数据点都看作是来自一个正态分布,通过计算每个数据点与其临接数据点的平均值和标准差,可以获得Z-score
并将其用于检测异常值,将z-score大于3的数据点视为异常值,缺点:如果异常点太多,则该算法的准确性较差。
3、
:param y_list: 传入需要处理的时间序列
:return:
"""
# 第一次处理
for i in range(1, len(y_list)):
difference = y_list[i] - y_list[i - 1]
if difference <= 0:
y_list[i] = y_list[i - 1]
# 基于突变检测的方法:如果一个数据点的值与前一个数据点的值之间的差异超过某个阈值,
# 则该数据点可能是一个突变的异常点。这种方法需要使用一些突变检测算法,如Z-score突变检测、CUSUM(Cumulative Sum)
# else:
# if abs(difference) > 2 * np.mean(y_list[:i]):
# y_list[i] = y_list[i - 1]
# 第二次处理
# 计算每个点的移动平均值和标准差
ma = np.mean(y_list)
# std = np.std(np.array(y_list))
std = np.std(y_list)
# 计算Z-score
z_score = [(x - ma) / std for x in y_list]
# 检测异常值
for i in range(len(y_list)):
# 如果z-score大于3,则为异常点,去除
if z_score[i] > 3:
print(y_list[i])
y_list[i] = y_list[i - 1]
return y_list
备注:上一个代码解释,我们可以看到,答案或许受到了代码中注释的影响,我们删掉注释,再来一次。对于解释中一些不懂的点,我们可以连续追问!

import numpy as np
from sklearn.ensemble import IsolationForest
import plotly.express as px
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import json
def Fusion_algorithm(y_list):
for i in range(1, len(y_list)):
difference = y_list[i] - y_list[i - 1]
if difference <= 0:
y_list[i] = y_list[i - 1]
# else:
# if abs(difference) > 2 * np.mean(y_list[:i]):
# y_list[i] = y_list[i - 1]
ma = np.mean(y_list)
std = np.std(y_list)
z_score = [(x - ma) / std for x in y_list]
for i in range(len(y_list)):
if z_score[i] > 3:
print(y_list[i])
y_list[i] = y_list[i - 1]
return y_list
5. 修复代码错误
用途:写完一段代码后发现有错误?让 ChatGPT 来帮你!
### Buggy Python
import Random
a = random.randint(1,12)
b = random.randint(1,12)
for i in range(10):
question = "What is "+a+" x "+b+"? "
answer = input(question)
if answer = a*b
print (Well done!)
else:
print("No.")
6. 作为百科全书
用途:ChatGPT 可以解释你所有的问题!但是列出小说这个功能有些拉胯,经过测试只有科幻小说列得还可以,其他类型不太行,可能 ChatGPT 训练工程师是个科幻迷!
7. 信息提取
用途:作为自然语言处理界的大模型,怎么能少得了信息提取呢?
8. 好友聊天
用途:输入对方性格模拟聊天,这方面功能不太完善,可能有新鲜玩法我还没有挖掘出来。
9. 创意生成器
用途:是不是常常会在创新上遇到思维瓶颈不知道怎么做?不要担心,让 ChatGPT 帮你生成创意!
VR 和密室结合
再结合 AR
10. 采访问题
用途:可能您是一个媒体工作者,采访问题不知道怎么写?ChatGPT 可以帮您解决。
采访问题清单
采访问题清单并给出相应答案
11. 论文大纲
用途:这个功能对于研究生简直不要太爽了,一直在郁闷大纲怎么写,直接列出来大纲简直帮了我天大的忙!对于大纲中不理解的点,直接要求 ChatGPT 给出进一步解释。代码也可以有!哪一章的内容不太会写,直接让 ChatGPT 安排,这样,一篇论文很快就写出来啦!
创建论文大纲
解释大纲内容
class PBA(nn.Module):
def __init__(self, PerformanceThreshold, DistributionType, AttentionWeightRange):
super(PBA, self).__init__()
self.PerformanceThreshold = PerformanceThreshold
self.DistributionType = DistributionType
self.AttentionWeightRange = AttentionWeightRange
def forward(self, input, performance_scores):
# 计算注意力分数
attention_scores = []
for i in range(len(input)):
if performance_scores[i] > self.PerformanceThreshold:
attention_scores.append(performance_scores[i])
else:
attention_scores.append(0.0)
# 将性能分数映射到注意力权重
if self.DistributionType == "softmax":
attention_weights = F.softmax(torch.tensor(attention_scores), dim=0)
elif self.DistributionType == "sigmoid":
attention_weights = torch.sigmoid(torch.tensor(attention_scores))
else:
raise ValueError("Unknown distribution type: {}".format(self.DistributionType))
# 缩放注意力权重到指定范围
attention_weights = attention_weights * (self.AttentionWeightRange[1] - self.AttentionWeightRange[0]) + self.AttentionWeightRange[0]
# 计算加权输入
weighted_input = torch.mul(input, attention_weights.unsqueeze(1).expand_as(input))
output = torch.sum(weighted_input, dim=0)
return output
12. 故事创作
用途:这个功能真的太太太棒了,以后我自己列提纲出来就可以写小说啦!
爱情故事
恐怖故事
13. 问题类比
用途:当你想要做一个比喻时,这是一个很棒的功能。
14. 创建 SQL 需求
用途:写 SQL 有时候挺头疼的,想好久想不起来。
15. 情感分析
用途:这个功能让我想起来在之前公司做的情感分析任务了。
16. 将产品描述转变为广告
用途:这个功能对于商家来说太棒了。
17. 关键字提取
用途:NLP 任务的重要作用,关键字提取!
18. 闲聊机器人
用途:这个不多说了,用来闲聊体验感真的很不错。
总结
我觉得角色扮演挺有意思的,对话前加一句:假如你是 xxx。
现在有一些小程序,让 AI 扮演一些角色对话,就是用这种方法实现的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)